






![]()
Update: Logging operator v3 (released March, 2020) 🔗︎
We’re constantly improving the logging-operator based on feature requests of our ops team and our customers. The main features of version 3.0 are:
- Log routing based on namespaces
- Excluding logs
- Select (or exclude) logs based on hosts and container names
- Logging operator documentation is now available on the Banzai Cloud site.
Check The Kubernetes logging operator reloaded post for details.
Logs (one of the three pillars of observability besides metrics and traces) are an indispensable part of any distributed application. Whether we run these applications on Kubernetes or not, logs are one of the best ways to diagnose and verify an application state. One of the key features of our Kubernetes platform, Pipeline, is to provide out-of-the-box metrics, trace support and log collection. This post highlights some of the behind the scenes automation we’ve constructed in order to achieve this.
We’ve been blogging for quite some time about logging on Kubernetes - if you are interested in burshing up on this subject, check out our earlier posts:
- Centralized logging automated on Kubernetes
- Centralized logging under Kubernetes
- Secure logging on Kubernetes with Fluentd and Fluent Bit
- Advanced logging on Kubernetes
The EFK (Elasticsearch-Fluentd-Kibana) stack 🔗︎
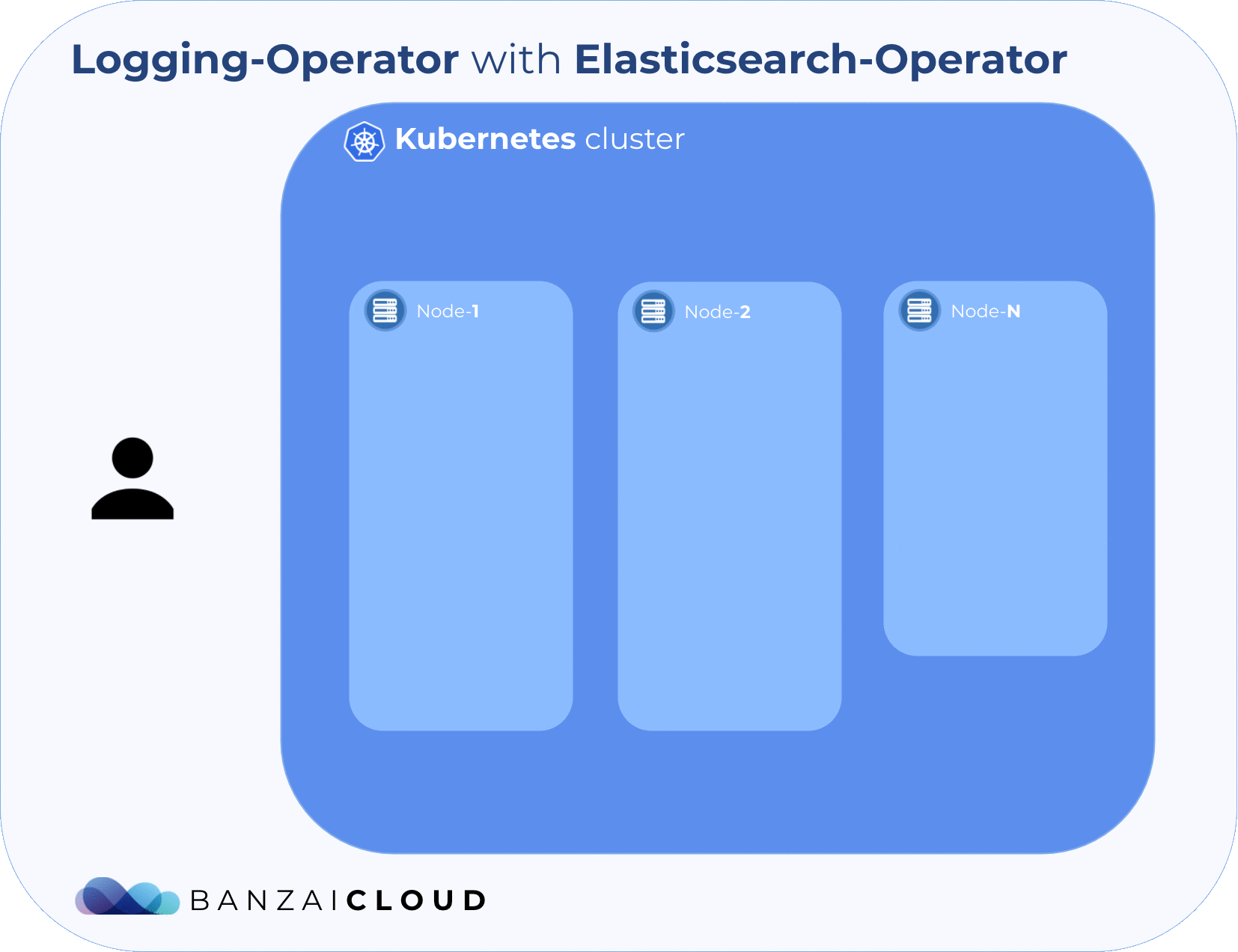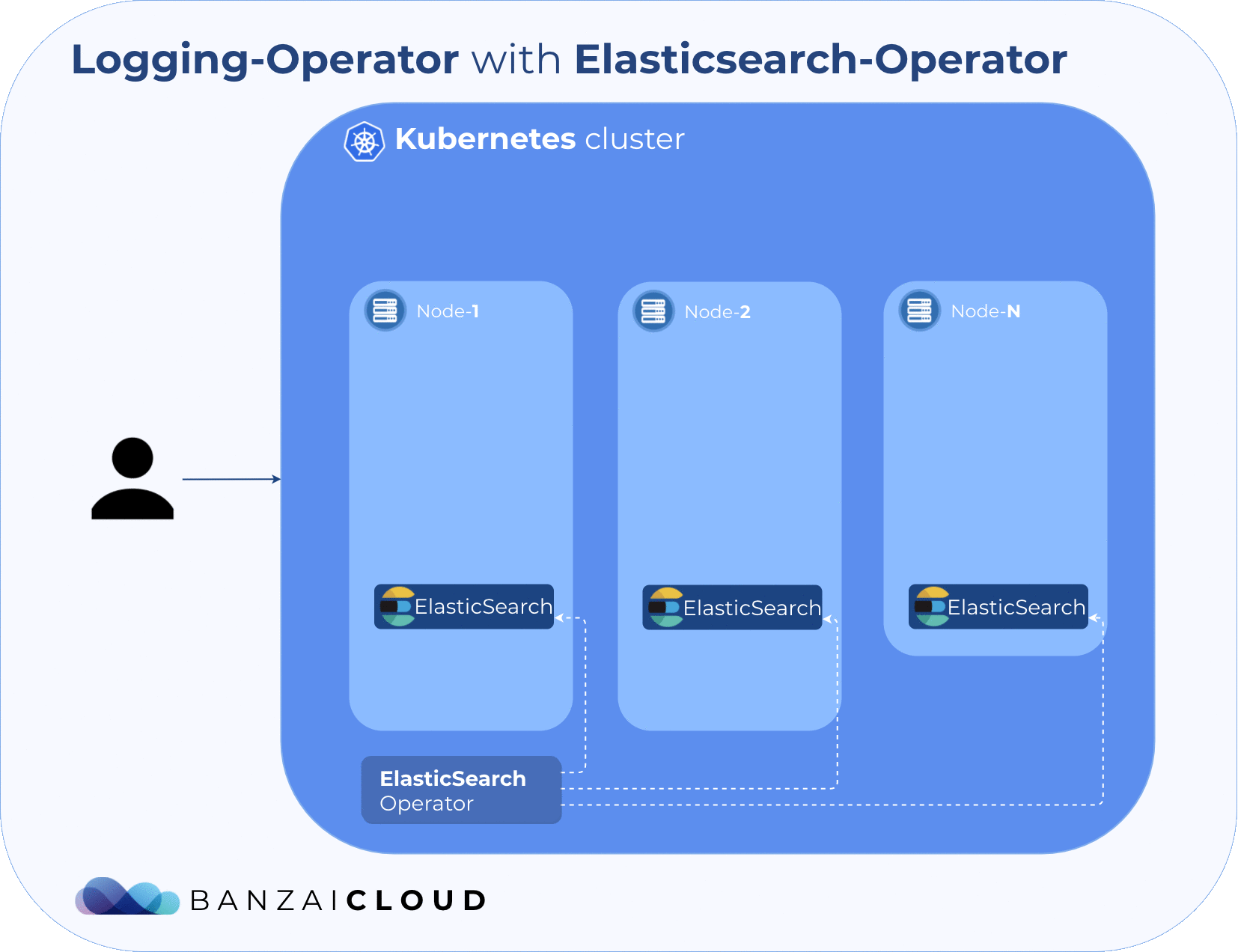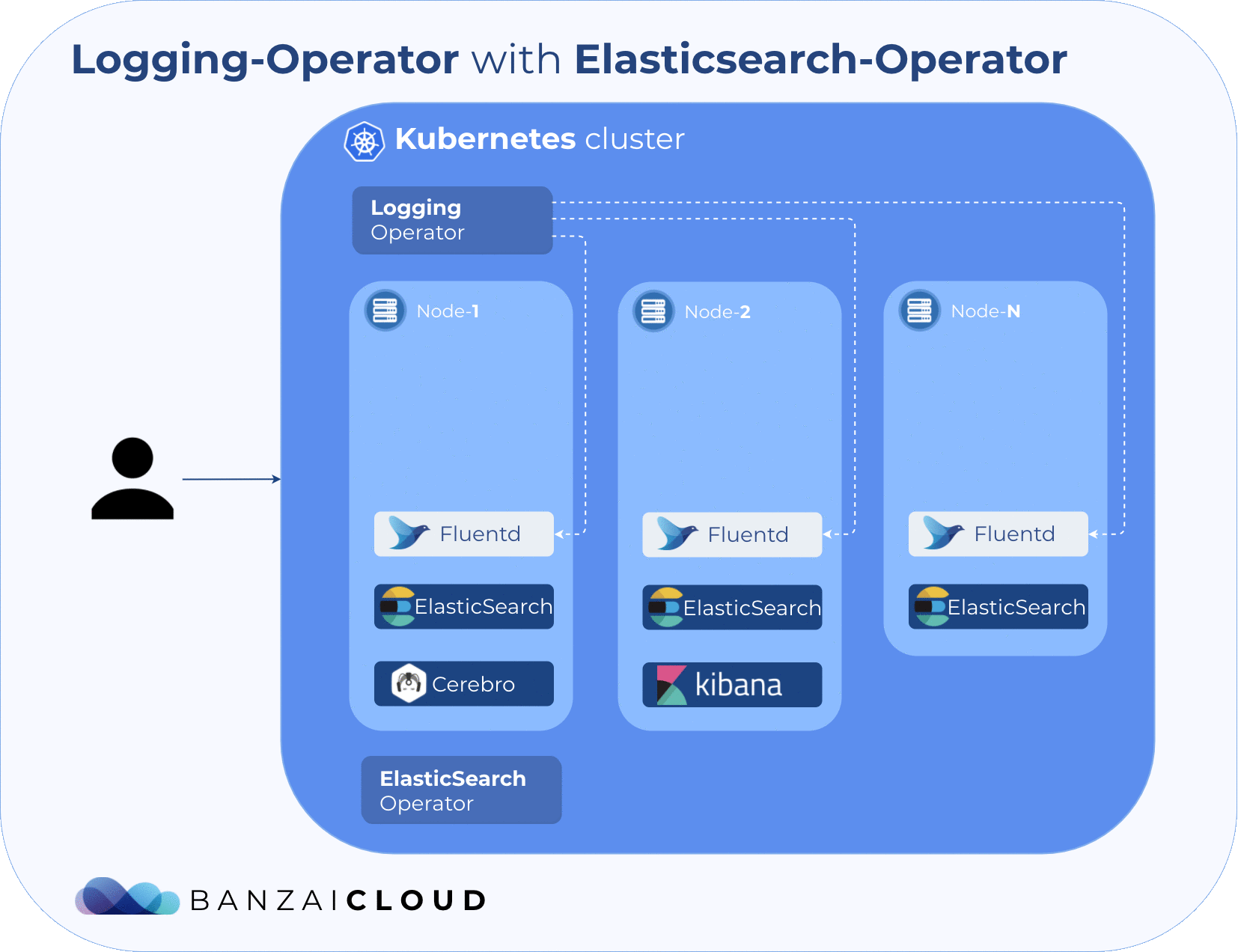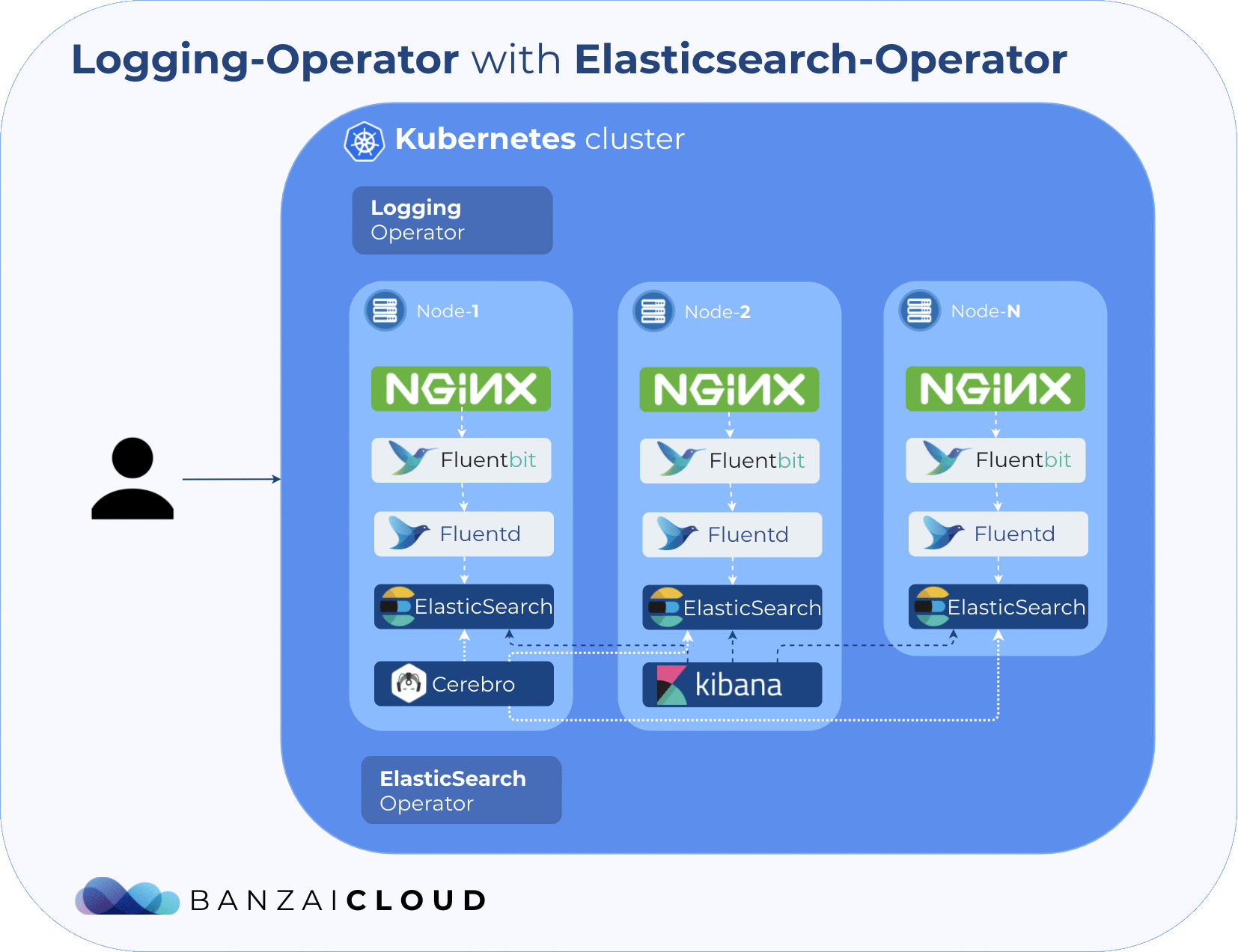
The EFK stack is one of the best-known logging pipelines used in Kubernetes. Usually, such a pipeline consists of collecting the logs, moving them to a centralized location and analyzing them. Generally speaking, the most difficult part of this operation is to collect, sanitize and securely move the logs to a centralized location. That’s what we do with our open source logging-operator, while utilizing the Fluent (fluentd and fluentbit) ecosystem.
Before we move on, we’d like to thank @wwojcik (https://github.com/wwojcik) for his pull-request.
Now let’s take a look at the part of this equation Elasticsearch comprises.
There are several ways to install an application like Elasticsearch on Kubernetes. For simple deployments, you can write yaml files, or, if you’re interested in templating and other advanced options, you can use Helm charts. A third alternative is to supercharge deployments with human operational knowledge, using operators. These not only install applications but provide life-cycle management. Elasticsearch is no exception, and can be deployed using any of the methods highlighted above.
- there is both a Helm chart in the upstream Helm repository
- and an official Helm chart from Elastic
But, if you want something more complex, operators are just as readily available. There are a great number of them:
- one from UPMC Enterprises https://github.com/upmc-enterprises/elasticsearch-operator
- Zalando has its own https://github.com/zalando-incubator/es-operator
- and KubeDB offers one, as well https://github.com/kubedb/elasticsearch
The setup in this post (and Banzai Cloud in general) uses the UPMC operator because it offers some extra tools that showcases the power of the EFK stack. The following components will be installed:
- Elasticsearch - an open source distributed, RESTful search and analytics engine
- Cerebro - an elasticsearch web admin tool
- Kibana - to navigate and visualize your Elasticsearch data
Banzai Cloud Logging-Operator and Elasticsearch 🔗︎
The following diagram shows the architecture that we are about to deploy. As you might have noticed, you’ll need a Kubernetes cluster before starting the flow. The Pipeline platform is capable of creating K8s clusters across six different cloud providers, in on-premise or hybrid environments. You might want to try it for free.
Add the operator chart Helm repositories 🔗︎
First, we add those Helm Chart repositories that are required to install the operators.
$ helm repo add es-operator https://raw.githubusercontent.com/upmc-enterprises/elasticsearch-operator/master/charts/
$ helm repo add banzaicloud-stable https://kubernetes-charts.banzaicloud.com
$ helm repo update
Install the operators 🔗︎
Next, we install those operators that manage custom resources. Note that the first command installs the operator itself, which won’t start anything until it receives its CRDs. The second command configures and applies Elasticsearch, Cerebro and Kibana CRDs, while the last instruction deploys the Banzai Cloud logging-operator.
$ helm install --name elasticsearch-operator es-operator/elasticsearch-operator --set rbac.enabled=True
$ helm install --name elasticsearch es-operator/elasticsearch --set kibana.enabled=True --set cerebro.enabled=True
$ helm install --name loggingo banzaicloud-stable/logging-operator
Install the Nginx Demo chart 🔗︎
We have a demo application which, once deployed, kickstarts an automated logging flow. Note, all the steps we’ve done so far, or will do in the future, are automated by Pipeline. Therefore, you will not have to repeat these steps. Also note that Pipeline supports multiple endpoints to store logs (e.g. cloud object storage).
$ helm install banzaicloud-stable/nginx-logging-es-demo
Forward the Cerebro & Kibana dashboards 🔗︎
After the commands have been successfully run we can confirm that our Elasticsearch cluster is up and running.
$ kubectl port-forward svc/cerebro-elasticsearch-cluster 9001:80
$ kubectl port-forward svc/kibana-elasticsearch-cluster 5601:80

That’s pretty much it: you have deployed a fully functional EFK stack, and an application that produces logs.
The Logging-Operator revisited 🔗︎
We opensourced the logging-operator last year, and have been using it internally since, as part of the Pipeline ecosystem and for customer engagement. The project has always been open source, but unlike our Istio or Vault operators it has not been promoted to a wider audience, other than for the use of our customers and Pipeline users. Recently, more and more developers from the Kubernetes ecosystem have discovered the project, noticed its potential, and started to use and contribute to it. They have, however, butted up against some of its limitations. We always listen and try to do our best to take care of our open source users, so we put together a workshop and decided to make a few changes. We’ve decided to discuss some of the topics raised by our users, which were:
- Concerns about the separation of namespaces and other credential related resources
- Cases in which two independent configurations could intefere with each other
We gathered all the feedback about these issues, and worked out a redesigned version of the operator. We are now working hard on the next release, and a new post to highlight some of its features. The new architecture has been redesigned from scratch, and these are just a few of the new concepts we plan on introducing:
Isolating namespaces 🔗︎
This means that, by default, a logging workflow configuration will only affect a specified namespace, preventing conflicts between unrelated settings.
Global vs Scoped definitions 🔗︎
As we still need some resources to be available cluster-wide, we’ll introduce new CRDs to that end.
Using outputs as sharable resources 🔗︎
In several companies, only a handful of restricted users have access to log destinations, and we moved these to independent definitions. This will allow users to not only access these resources, but simultaneously prevent them from changing or deleting them.
Moving from templating to a create model 🔗︎
Before, we used templates exclusively to render Fluentd configurations. From now on, we’ll build a DAG to represent all logging flows. This added step between collecting the CRDs and rendering them into the config will help to identify misconfigurations and provide visual representations for the user.
Okay so what changes will be made to the operator and CRDs? 🔗︎
We decided to use dedicated CRDs for output plugins 🔗︎
This way it will be easier to use references for outputs, which help users to define a single output and reference it as an input.
apiVersion: "logging.banzaicloud.com/v1alpha1"
kind: "Output"
metadata:
name: "my-favourite-es"
namespace: test-namespace
spec:
type: "elasticsearch"
parameters:
- name: host
value: "elasticsearch.monitoring.svc.cluster.local"
- name: port
value: "9200"
- name: scheme
value: "http"
- name: logstashPrefix
value: "my-index"
- name: bufferPath
value: "/buffers/my-index"
and the corresponding input:
apiVersion: "logging.banzaicloud.com/v1alpha1"
kind: "Input"
metadata:
name: nginx-a
namespace: a
spec:
selector:
function: frontend
env: prod
filters:
- type: parser
parameters:
- name: format
value: '/^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)"(?:\s+(?<http_x_forwarded_for>[^ ]+))?)?$/'
- name: timeFormat
value: "%d/%b/%Y:%H:%M:%S %z"
outputRefs:
- "my-favourite-es"
Separated namespaces and cluster wide resources 🔗︎
Because the operator restricts access between different namespaces, we’ll introduce new CRDs with Cluster prefixes. This enables the usage of cluster-wide definitions for users with proper RBAC privileges (In Kubernetes you can limit access to resources by Kind). Without access to these kinds of CRDs, a simple user will be unable to change configurations that affect the whole cluster.
kind: "Output"
kind: "ClusterOutput"
kind: "Input"
kind: "ClusterInput"
This new architecture opens up a lot of possibilities that we’ll be excited to explore and share with you in our coming posts. We are actively working on a cool new feature, real-time log inspection, so keep in touch. As always, these new features will be automated and made available in Pipeline.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.




