Tracking and enforcing SLOs
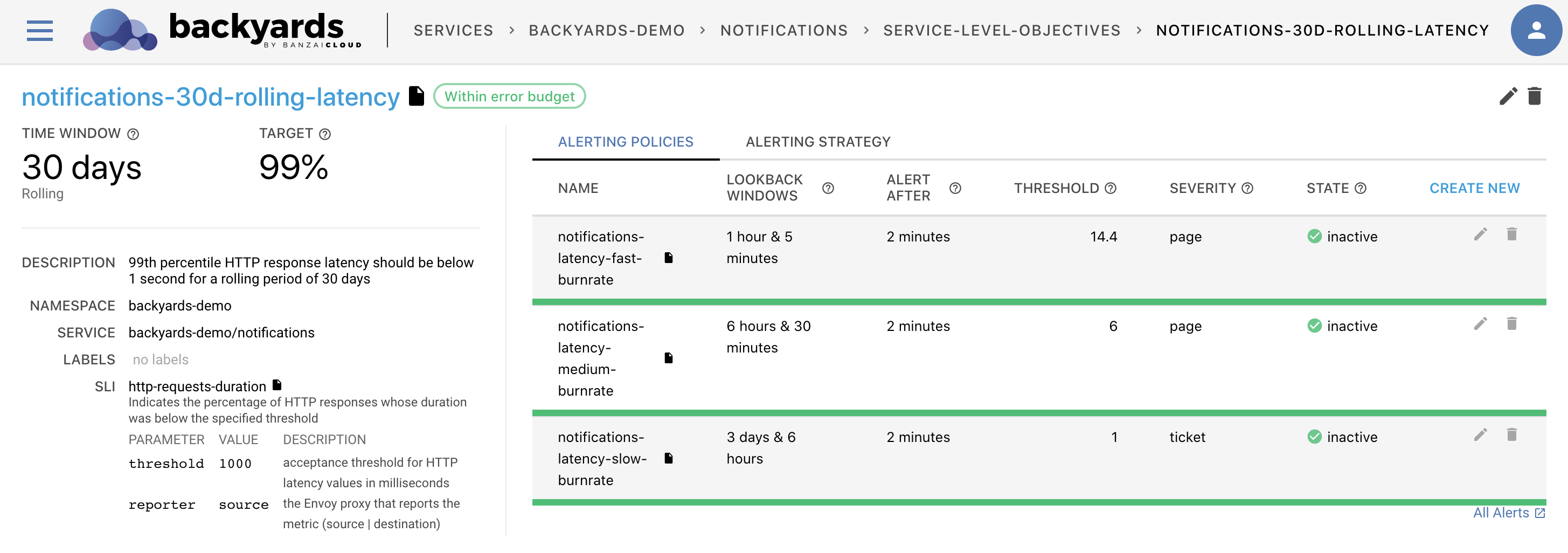
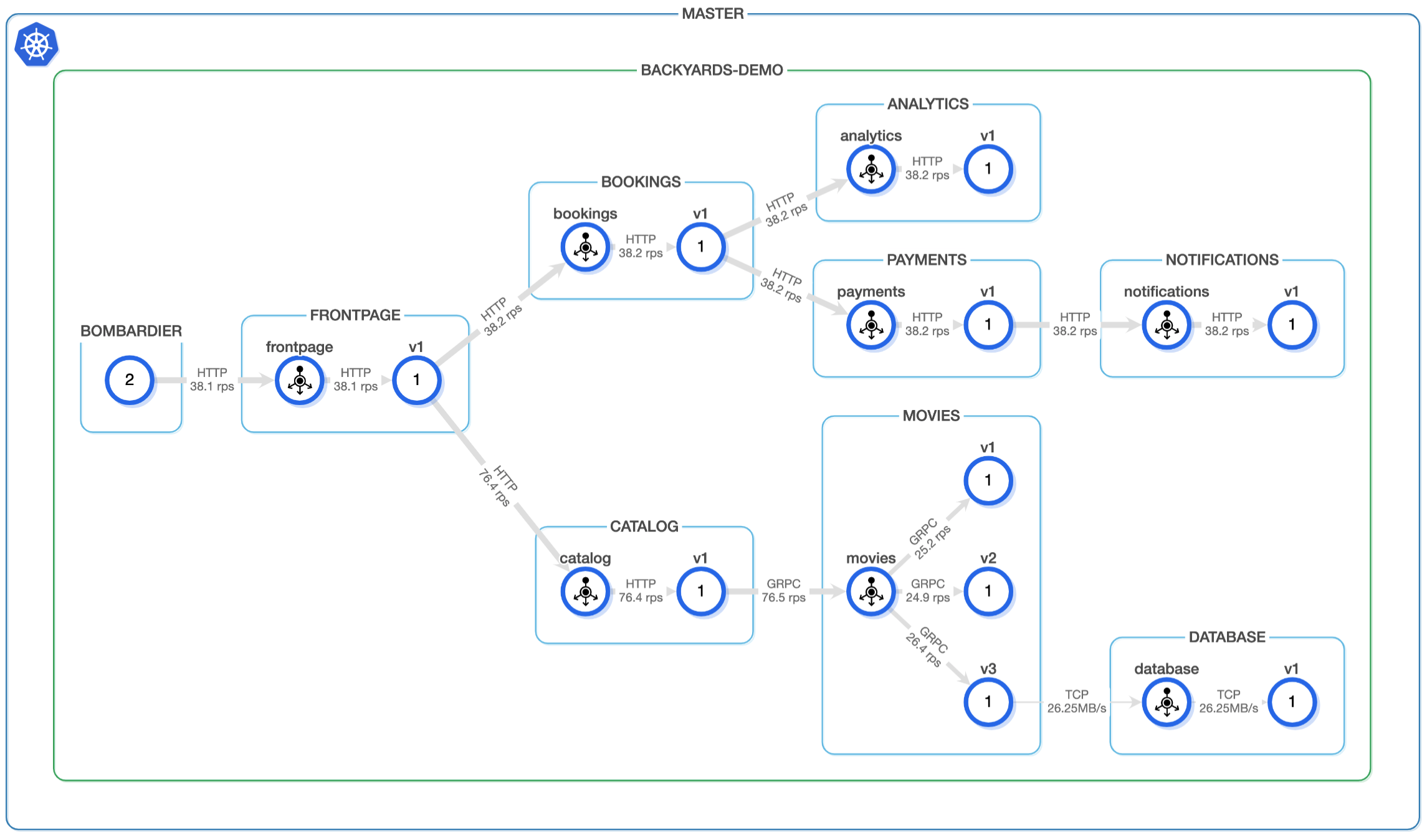
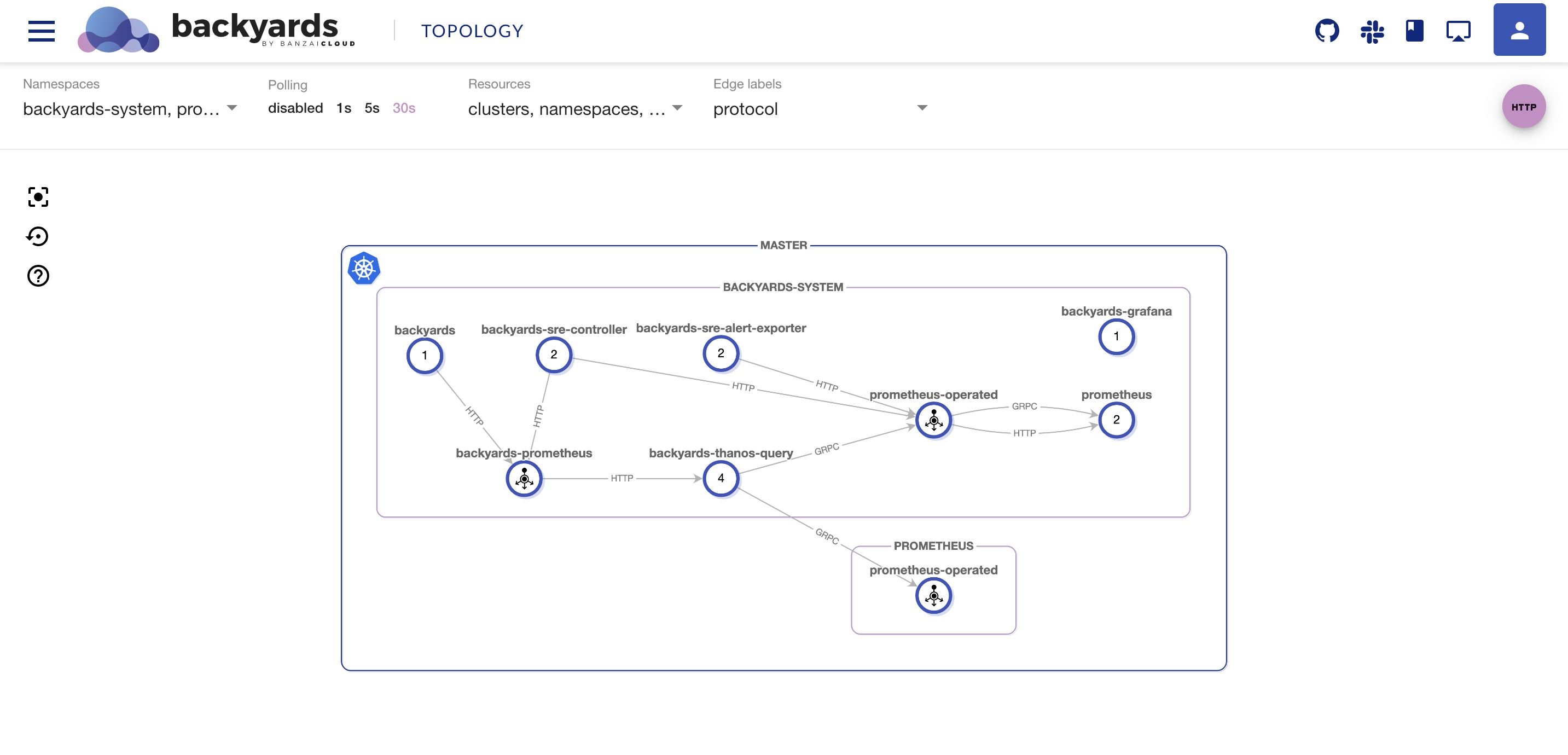
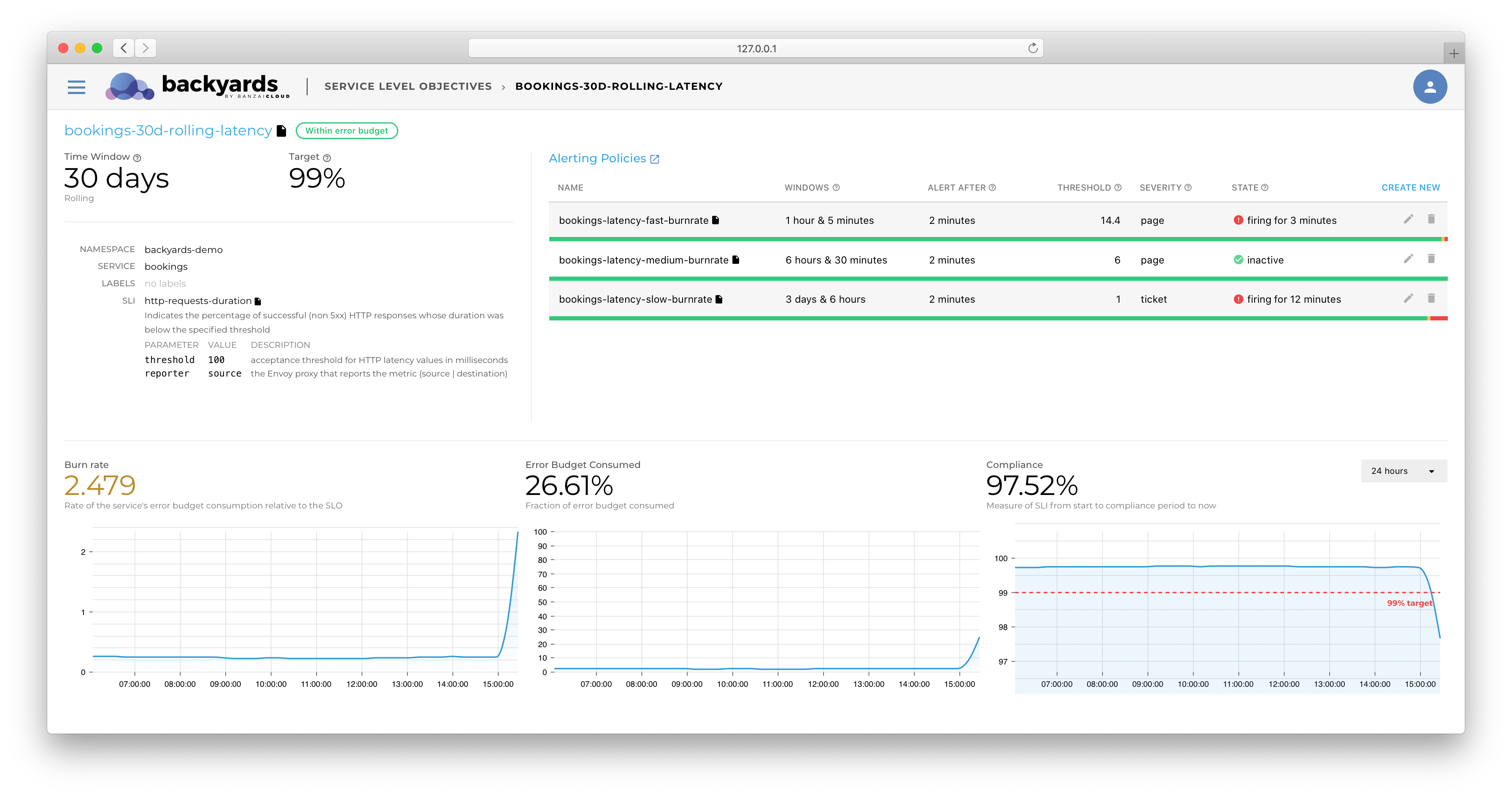
Running a computing system at scale is hard. The goal of the whole Cloud Native transformation is to make it easier, but it still requires a deep expertise in observability and alerting tools to track the state of the infrastructure and the services. And it’s not only the tools, but the questions that arise at scale. Practice shows that running a complex system with a 100% reliability target is unrealistic. But in that case, how do you determine that certain level of errors that you can live with, or when do you need to trigger alerts to possibly wake an engineer up in the middle of the night?
READ ARTICLE


Mon, Aug 17, 2020