






Generally speaking, code generation is the process of producing code from some sort of abstract description. Although this is not a very expressive description, almost everyone has some sort of understanding of code generation. For example, in the cloud native ecosystem generating code from Protobuf or OpenAPI descriptors is quite common.
Code generation, however, is much more than that. Besides specific, (very) high-level definition languages, program code is also such abstract description. Generating code based on code is actually what happens when a compiler translates program code written in a high-level programming language into machine code for example. The compiler parses the code, optimizes it and then generates a set of instructions that our computer can understand.
High-level programming languages exist, so that we don’t have to speak to the machine directly. Talking to the machine is tedious, because it works differently than the human brain.
Similarly, we don’t handle repeating things very well either. At least in computer engineering, if something needs to be done more than once, we want to automate it. We’ve invented a lot of tools that help us avoid repeating code, from reusable libraries to parametric polymorphism (commonly known as generics).
What if we can automate writing code as well? In other words: what if we can generate code (in the same language) from code?
In this post, you can read about generating Go code using the same tools as Kubebuilder uses. As an example, we are going to implement a shallow copy generator for structs (which doesn’t make much sense on its own, but serves as an excellent example).
Generating Go code 🔗︎
Generating code (with some simplification) can be split into two phases:
- parsing the input and transforming it into an intermediate representation
- producing the actual code from that representation
The intermediate representation can vary, but it can be as simple as a set of parameters of a function. The important thing is to have an intermediate layer that acts as a “DTO” between the parser and the code generator, so they don’t depend on each other directly.
For the actual code generation, there are several common solutions in Go. They are not actually specific to Go (ie. the same idea can be applied to other languages as well), but I want to show you how you can do it in Go.
The first (and probably the easiest) way is templating. Almost every language has its own templating solution (either builtin or a userland version). Go has a template engine built into its standard library, using its own template language which can be used for generating code:
1package {{ .PackageName }}
2
3func (o {{ .StructName }}) ShallowCopy() {{ .StructName }} {
4 return {{ .StructName }}{
5 {{- range $field := .Fields }}
6 {{ $field }}: o.{{ $field }},
7 {{- end }}
8 }
9}Given the following struct:
1package pkg
2
3type MyStruct struct {
4 Field1 int
5 Field2 string
6}We can create an intermediate representation for our template:
1data := map[string]interface{}{
2 "PackageName": "pkg",
3 "StructName": "MyStruct",
4 "Fields": []string{
5 "Field1",
6 "Field2",
7 },
8}In our case, we can feed that directly into our template to generate our shallow copy function:
1package pkg
2
3func (o MyStruct) ShallowCopy() MyStruct {
4 return MyStruct{
5 Field1: o.Field1,
6 Field2: o.Field2,
7 }
8}See it in action: https://play.golang.org/p/hCRya6l61U8
Using templates has a major downside though: basically you limit yourself to the tools provided by the template engine, which can be hard or tedious to use for code generation purposes. The above example doesn’t use conditionals or loops for instance. Despite you have them in Go’s template language, it can very quickly become complex and hard to maintain. So while templates are usually more readable and using them is easy for simpler use cases, it can quickly get complex and tricky to maintain.
Another approach that doesn’t suffer from those issues is just writing the code to a buffer in plain Go code:
1b := &bytes.Buffer{}
2
3fmt.Fprintf(b, "package %s\n\n", data.PackageName)
4fmt.Fprintf(b, "func (o %[1]s) ShallowCopy() %[1]s {\n", data.StructName)
5fmt.Fprintf(b, "\treturn %s{\n", data.StructName)
6
7for _, field := range data.Fields {
8 fmt.Fprintf(b, "\t\t%[1]s: o.%[1]s,", field)
9}
10
11fmt.Fprint(b, "\t}\n")
12fmt.Fprint(b, "}\n")See it in action: https://play.golang.org/p/UoiVSDbw88b
Comparing this solution to the template shows that there is a serious readability issue with this one, so in simple use cases it’s probably better to use templating.
As mentioned before, though, templating might not always be the best solution either, so we should try to address the problems of this approach.
One major problem that obscures reading is the API itself. We write lines, but the actual code begins somewhere in the middle of every write operation.
The other problem is indentation: you have to prefix every line with the correct amount of tab characters (technically formatting could be a separate step).
One common solution addressing these issues is a custom writer that exposes a fluent API:
1b := &bytes.Buffer{}
2w := &genWriter{
3 w: b,
4}
5
6w.Wf("package %s\n", data.PackageName)
7w.Wf("func (o %[1]s) ShallowCopy() %[1]s {", data.StructName)
8
9{
10 w := w.Indent()
11
12 w.Wf("return %s{", data.StructName)
13
14 {
15 w := w.Indent()
16
17 for _, field := range data.Fields {
18 w.Wf("%[1]s: o.%[1]s,", field)
19 }
20 }
21
22 w.W("}")
23}
24
25w.W("}")See it in action: https://play.golang.org/p/dS45fgUj2lJ
This is just a very simple (and obviously not the best possible) wrapper around a buffer, but it already improves readability significantly. The Go implementation of Protobuf is a great example for this approach, but under the hood Kubebuilder also uses a similar solution.
Writing to a buffer (even through some sort of wrapper) - though it’s probably the most common solution these days - still has its own issues. It’s still not perfect from a readability perspective, it forces you to linear coding, reusing components is hard (eg. you have to take care of indentations), etc.
Some libraries decided to take this to the next level, and provide a complete (fluent) API for code generation. One such library is jennifer. (Fun fact: code generation libraries are often called Jen, Jenny or Jennifer)
Generating the above code with jennifer looks like this:
1f := jen.NewFile(data.PackageName)
2
3f.Func().
4 Params(jen.Id("o").Id(data.StructName)).
5 Id("ShallowCopy").
6 Params().
7 Params(jen.Id(data.StructName)).
8 Block(jen.Return(
9 jen.Id(data.StructName).Values(jen.DictFunc(func(d jen.Dict) {
10 for _, field := range data.Fields {
11 d[jen.Id(field)] = jen.Id("o").Dot(field)
12 }
13 })),
14 ))See it in action: https://play.golang.org/p/Vg8RxDMX6xm
This approach is not necessarily more readable though, but definitely provides a more structured and more reusable solution. It also gives you more freedom in how you want your code to be built (you are not bound to the linear nature of the buffered writer solution). The library is quite well-documented with lots of examples. Give it a try!
To sum up: there are multiple solutions and tools for producing (Go) code in Go, each has its own issues/limitations. Choose the one that fits your use case better and/or easier to use for you.
Using code as input 🔗︎
So far we focused on how the code is being generated from a custom input definition that looked something like this:
1type inputData struct {
2 PackageName string
3 StructName string
4 Fields []string
5}
6
7// ...
8
9data := inputData{
10 PackageName: "pkg",
11 StructName: "MyStruct",
12 Fields: []string{
13 "Field1",
14 "Field2",
15 },
16}As I mentioned earlier, the input for code generation can basically be anything. Common inputs are IDLs (Interface Definition Language), but source code itself can serve as an input for code generation.
In our example, we want to generate a shallow copy function for a simple struct:
1type MyStruct struct {
2 Field1 int
3 Field2 string
4}For that purpose, we need to parse the Go source code and transform it into the above shown intermediate representation.
Fortunately, Go provides enough tooling for that. The go package in the standard library provides tools to parse the source code into an AST and further examine the code through the go/types package.
There is also golang.org/x/tools/go/packages that helps loading code from packages/modules.
While these tools are sufficient enough to implement a parser for our code generator, presenting them would fill an entire blog post of its own. Instead, I will show you a higher level framework that uses these components under the hood for orchestrating the entire generation process.
Kubebuilder 🔗︎
Kubebuilder is the latest SDK for building so called Operators for Kubernetes. Operators are basically resource orchestrators: you tell the operator the desired state of a resource, and the operator will hammer the target systems until the resource looks exactly like it should.
From our perspective, the desired state is the important bit here. The desired state is described through special, custom Kubernetes manifests (Custom Resources - CRs). Custom resources must follow a strict specification provided by Custom Resource Definitions (CRDs). In an object oriented analogue: CRDs are classes, CRs are objects. Operators watch CRs for changes in the desired state and apply those changes to their managed resources.
Kubebuilder provides various tools for creating Operators and CRDs, keeping the necessary coding at minimum. It does that by providing various code generators for generating boilerplate code for CRDs, CRs and Operators.
For example, the code generation input for CRDs is a plain old struct. This struct is actually used by the operator to do work on the CR. The code generator uses the struct to generate OpenAPI schema, CRD resources, validation and deep copy functions, etc.
Let’s think about this for a minute. Suppose we have the following struct:
1type MyStruct struct {
2 Field1 int
3 Field2 string
4}There is very limited information available in it. We know the name of the fields, we know their type. How are we supposed to derive validation rules from this information only? We obviously need a way to attach custom information to the code in order to do that. Go doesn’t have an annotation system, Kubebuilder uses markers instead.
Markers are special comments attaching metadata to packages, named types and struct fields:
1// +my:marker:generate=true
2type MyStruct struct {
3 // +my:validation:Min=2
4 Field1 int
5
6 Field2 string
7}The attached metadata can be used to:
- filter types subject to code generation (only generate code for the marked types)
- provide additional input for the generator (eg. validation rules for a field)
Markers are registered in a global registry and are processed together with the type information during the code generation.
The code generation framework itself can be broken down into three components:
- inputs
- generators
- outputs
Inputs are input parameters of the whole process or individual generators (a single code generation process can invoke multiple generators), for example the package paths to be loaded.
Generators are implementations of the sigs.k8s.io/controller-tools/pkg/genall.Generator interface.
A generator instance is responsible for two things:
- registering custom markers in a common marker registry
- traversing the type information (with markers) extracted from the loaded packages and generating code
A very basic implementation a generator looks like this:
1type Generator struct{}
2
3func (Generator) RegisterMarkers(into *markers.Registry) error {
4 return nil
5}
6
7func (Generator) Generate(ctx *genall.GenerationContext) error {
8 // loop through the loaded packages
9 for _, root := range ctx.Roots {
10 root.NeedTypesInfo()
11
12 // loop through the types in the package
13 if err := markers.EachType(ctx.Collector, root, func(info *markers.TypeInfo) {
14 // check if the type needs code generation
15 // and extract the necessary information from the type
16 }); err != nil {
17 root.AddError(err)
18 return nil
19 }
20
21 // generate all the code here for a single package
22 // (if there is anything to generate)
23 // invoke the output here
24 }
25
26 return nil
27}Outputs are responsible for writing the generated code to files. There are basic output implementations in the library (stdout, directory, etc), but you can use your own outputs to control where the generated code gets written.
These components (inputs, generators, outputs) can be used on their own, but the library also comes with a facade, that takes them as its input and coordinates the code generation using these components.
Unfortunately going through the entire code, line by line is simply not possible within the scope of this post. The core concepts and some sample codes are explained above, you can find the source code for the complete example here.
Use Cases 🔗︎
Generally, code generation is very useful for generating boilerplate code and automatically creating different representations of the same information (eg. OpenAPI descriptor -> Request/Response objects and client code). Generating default implementations and mocks are also very common, but generating interfaces is also not without precedent.
At Banzai Cloud we have almost all of these use cases in our projects and we use various code generation tools.
Our latest code generation practice is closely related to how we organize our applications:
We follow the elegant monolith concept in most of our projects. To keep the operational overhead of our components at a minimum we ship them in a low number of artifacts (binaries/images), but in the code we keep the different services of a single application strictly separated. We also separate the business logic from the transport layers:
- on the outer layer there is a RESTish HTTP API
- internally the components use gRPC for communication
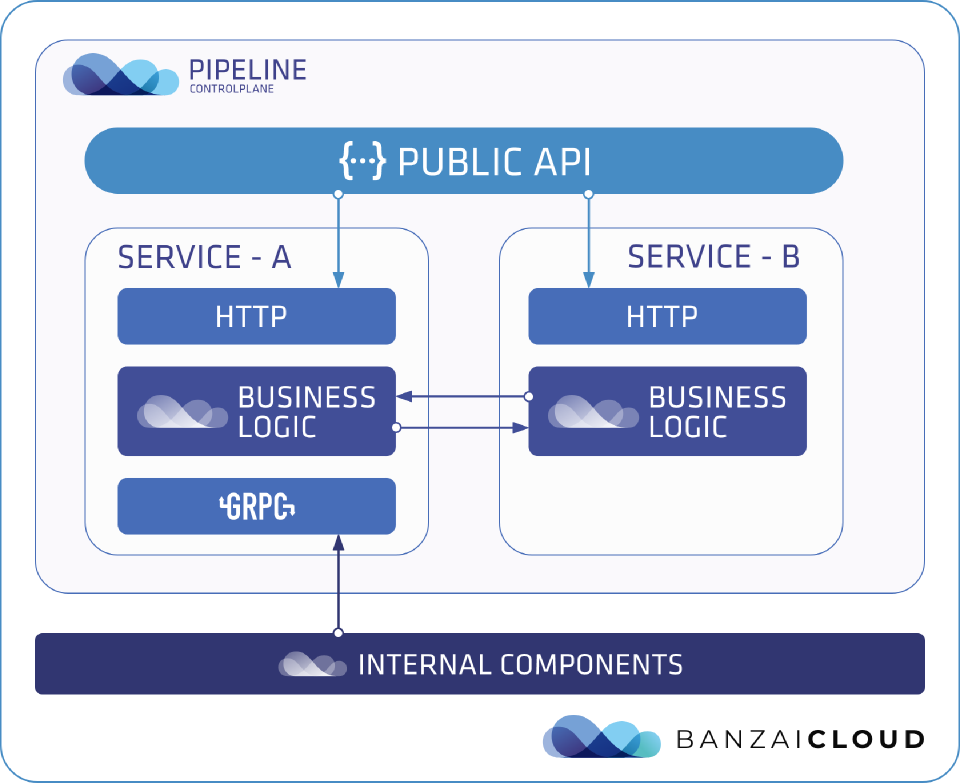
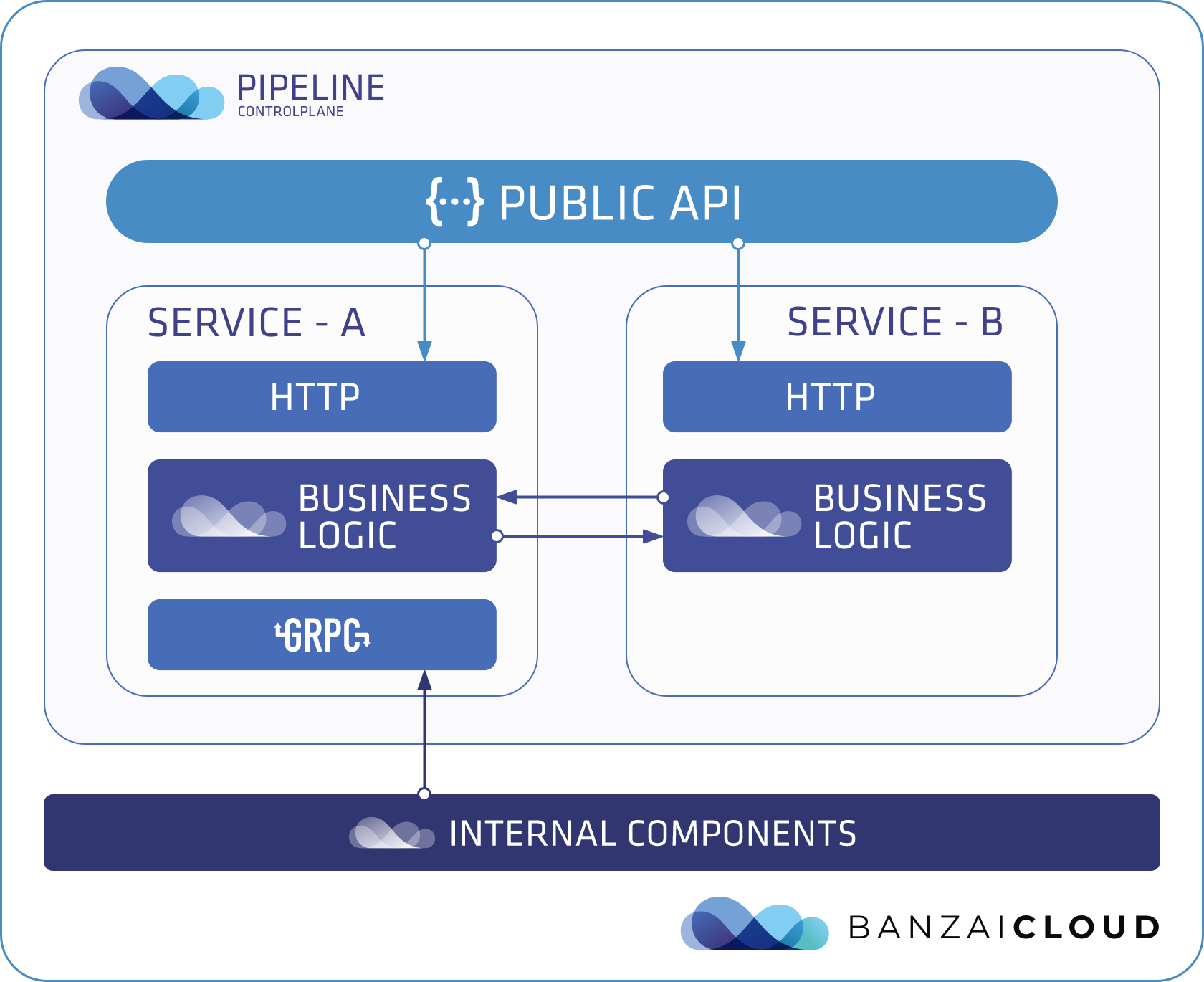
Integrating business logic into transport layers is usually a boring job. That’s why we generate most of that code, so that we can easily integrate business services into various transport methods (using Go kit).
We also generate certain event-driven handlers and mocks for interfaces using the technique explained above. Check out the tool we use for code generation for more examples.
Conclusion 🔗︎
The framework provided by Kubebuilder (controller-tools) provides an easy way to annotate and parse code for code generation purposes whereas text/template and jennifer help with the actual code generation.
Regardless of the use case, this combination can be used to quickly create code generators for various purposes.




