Proxy servers are out of fashion, but you may meet them at some places, or you might even realize that they are a good candidate to solve your problem. We’ll look into the history and the basic workings of HTTP proxies to understand their limitations, the environment where they worked well, and see how they can be best used today.
Some networking history 🔗︎
Networking protocols are one of the last thing you should expect to significantly change when designing a system or software. Most of the essential protocols in use today are compatible with, and not particularly different from their first mature version from the early 1990s if not from the 1980s.
That’s the case with the most popular network protocols like IPv4, TCP or HTTP as well. They were specified in a world where there were a total of a few thousands of interconnected computers, and close to zero recognized network security attacks or blackhat hackers. But the layered architecture, together with some minor modifications and additions outside of the original scope of the protocols makes them usable after decades — TCP and IPv4 standards are close to their 40th anniversary.
This also means that we could connect to a typical UNIX system from the late 80s with a current developer machine without any special tools or archaic software that isn’t there already (given that physical layer connectivity is available). Of course these protocols are only the ones that survived, so you can’t be sure that we’ll use any given protocol for another 20 years.
The two main issues of the above mentioned stack are security and scalability, the increasing number of machines and users involved.
The most common answer to network security concerns is to use TLS (Transport Layer Security, formerly SSL). It’s an additional layer between the existing transport layer protocols (TCP in the example) and the application layer (HTTP in this case). The introduction and retirement of TLS protocol versions can be considered rapid if you compare it to lower level protocols, but this doesn’t mean that you couldn’t use the 20 years old TLS 1.0 in a current web browser today (but you will get a warning at least). These protocols were superseded by TLS 1.2 more than ten years ago, but some services still use them. This relatively quick process is driven by the previous experience of finding practically usable exploits for known protocol flaws that were already addressed in newer protocols. Some of these couldn’t been fixed in the implementation, because the flaw was part of the protocol. This motivation can’t be observed for the other layers of this stack, transition to newer protocol versions is even slower.
There are some protocols that incorporate encryption instead of the layered approach, and we can see that these tend to lag behind TLS (or for example HTTPS) in the introduction, deprecation, and the practical use of recent crypto algorithms.
The other problem of the stack comes from the limited (and segmented) address space that IPv4 provides. There were considerable efforts made to replace these protocols with a new IP protocol version at once to solve every single problem identified, including the address space limitation, although the adaption is extremely slow. The more than 20 years old IPv6 standard, which was developed to replace IPv4 is supported by all major operating system and most of the core networking equipment, and it has been deployed by many ISPs and organizations in the past few years, but there are hardly any IPv6-only deployments, and the supposedly transitional dual-stack operation (IPv4 and IPv6 on the same network) seems neither a high priority for enterprises.
In the past 10 years we’ve seen multiple announcements about the allocation of the last IPv4 blocks, and now we can state that the globally routable IPv4 address space is fully and finally allocated, and can’t be extended anymore. However, this isn’t enough motivation for the big players to drive a transition (even if many old US tech companies had to give back their generously allocated /8 networks).
Why would you operate a proxy server? 🔗︎
Proxy servers were once a basic element of most networks with access to the internet. They have multiple roles at the same time:
- Security: restrict and audit internet usage, prevent incoming connections by design.
- Gateway: give internet access to internal machines that couldn’t be normally routed to the internet (non-IP or private network).
- Cache: gain speed and decrease redundant bandwidth usage.
This all looks good, but why did proxy servers lose popularity? Let’s take the above mentioned roles one by one.
First of all: there are two ways of proxying HTTPS traffic. You can tunnel the TLS session to the endpoint, where the proxy server has no access to the traffic, the operator gains little advantage compared to transparent internet access. The other way is to terminate and re-encapsulate the session. This breaks the end-to-end nature of proper TLS, which could be otherwise enforced with extensions like strict transport security (HSTS).
Proxies can be used to provide access to resources in different networks which can’t be routed directly. While the most common scenario is when the client is in a private network, it can be the other way around: you may consider using a HTTP proxy to access resources in a remote private network, just like kubectl proxy does.
A proxy server was a practical solution before stateful packet filters, dynamic network address translation (NAT), and even virtual private networking (VPN) became performant and widely available in almost all routers and firewalls. It was also quite easy to deploy because the operator didn’t have to care much about lower layers, just install a simple user mode service on any machine which had internet connectivity and was accessible from the internal network. Now, it’s easier to configure and maintain a gateway that works on Layer 3, and most of the control, traffic analysis, auditing that can be achieved with proxies is available as well.
Caching is useful, but a big portion of the internet traffic is now either encrypted, dynamic, or streamed — neither of which is a good candidate for caching. Typical cacheable data, like software updates have their own application level solution for local caching, which could be more effective than what you can achieve with a generic least-recently-used strategy. Moreover, internet bandwidth is available at most locations, and inexpensive compared to the potential benefits and costs of operating a caching proxy.
How do they work? 🔗︎
This blog post is about forward proxies. A related concept, reverse proxies are for accessing a group of related services, where the origin address is always the same, or limited to a list of addresses. Reverse proxies are similar in implementation, but not directly related to today’s topic. Check our posts about ingress controllers for more details.
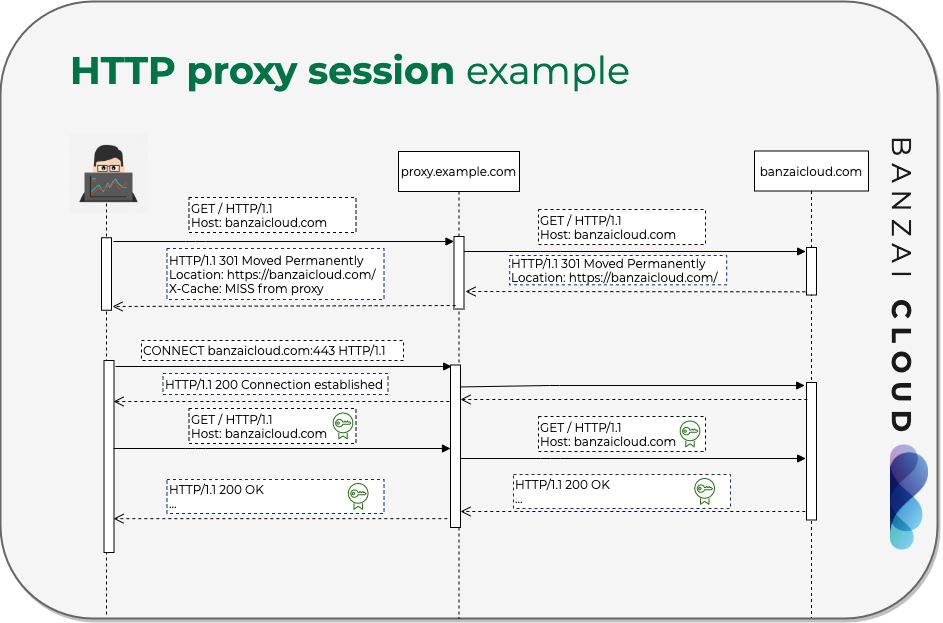
Let’s see an example. The user wants to access http://banzaicloud.com from their browser, which is configured to use http://proxy.example.com:3128 as a HTTP and HTTPS proxy.
So instead of looking up the IP address of banzaicloud.com in DNS, it looks up proxy.example.com, and sends a HTTP request to it:
GET / HTTP/1.1
Host: banzaicloud.com
The proxy server checks if it has a valid cache about this page, and if not, it looks up the IP address of banzaicloud.com, and sends a HTTP request to it (often with some additional metadata):
GET / HTTP/1.1
Host: banzaicloud.com
Now the proxy gets a reply:
HTTP/1.1 301 Moved Permanently
Location: https://banzaicloud.com/
The proxy forwards this response to the browser with some additional metadata:
HTTP/1.1 301 Moved Permanently
Location: https://banzaicloud.com/
X-Cache: MISS from proxy
The browser understands that the requested page is available over https, so sends another, special request to the configured HTTPS proxy (which is actually the same address in this case):
CONNECT banzaicloud.com:443 HTTP/1.1
Host: banzaicloud.com:443
CONNECT is a HTTP method specific to proxies, it initializes a TCP connection to the given endpoint, which will replace HTTP traffic on the same connection from this point.
As we mentioned earlier, the proxy has basically two options:
- decide if the connection is allowed, establish it, and forward every single byte unchanged, or to
- terminate the TLS connection, and proxy the content.
Let’s take the simpler approach. The server acknowledges the connection request to the browser:
HTTP/1.1 200 Connection established
In the consecutive packets within the TCP session from the browser to the proxy, the normal TLS traffic begins with the usual Client hello.

What happens when the proxy server wants to inspect the TLS traffic? 🔗︎
In this case the proxy has to impersonate the remote server, which involves using a certificate issued for the name of the requested remote server. This is normally issued on demand by a local certificate authority that is trusted by the clients.
This is another thing that has to be configured in the clients, and makes the proxy server responsible for evaluating the identity of the remote server instead of the end user.
Different types of proxy servers 🔗︎
A proxy server is usually identified by a URL, for example http://proxy.example.com:3128.
The http scheme in this example shows that the proxy uses the HTTP protocol to communicate with the clients, but as in the example session above, it can be used as both a HTTP and a HTTPS proxy.
You can use HTTPS to communicate with the proxy server too, but this seems to be less frequent, and it’s not even supported that widely. It’s also rare that you have different proxies for HTTP and HTTPS, for example to access the HTTP proxy over HTTP, while use HTTPS for the HTTPS proxy in the same installation.
However, using TLS to communicate with the proxy makes much sense, because impersonating a proxy server would have important consequences, and more importantly the user authentication information may be transferred in clear text if HTTP is used to access the proxy server. It’s not unheard of that the proxy uses HTTP Basic authentication with user names and passwords from a directory also used for authenticating other services in the organization.
We can mention SOCKS proxies too, which basically provide a service similar to the above mentioned CONNECT method.
Some of the available HTTP proxy server products also implement an FTP proxy.
Configuring clients 🔗︎
A protocol implemented in the application layer makes the implementation of both server and a single client easier, but it also means that it will be the responsibility of the application developer (or the libraries they use) instead of the operating system. The fact that you access internet over a specific proxy server affects all your different applications and services who want to communicate over the internet (in the lucky case when you use a protocol that’s proxied at all).
Unfortunately, neither POSIX nor Linux has a detailed and widely implemented specification about proxy configuration, so we can only speak about common patterns or conventions. Some Linux distributions may provide a system-wide proxy setting, but you can’t be sure that it’s applied to every piece of software you use. This setting may only be used by the package manager.
Most applications use a library for HTTP connection, which usually implements proxy configuration based on environment variables. So if you try to configure proxies for a specific application, the programming language it’s written in will give a good starting point about how to do that — if the developer didn’t come up with something worse than the defaults.
In most cases you can set the http_proxy, https_proxy and no_proxy environment variables (normally lower case), but some software expect the upper case version. (Also note that most Java programs don’t recognize these environment variables.)
The first two variables are normally set to the same value, which is an URL with http or https scheme, usually an explicit port number, and no path.
It can also include a username and password that’ll be forwarded in the Proxy-Authorization header if requested by the server. Don’t forget to URL-encode the credentials if they have special characters.
A simple host:port setting may be accepted by some tools, but not by others.
no_proxy is more interesting.
It specifies the exceptions for proxying in a comma separated list.
Complete hostnames and IP addresses are universally supported.
Of course, IP addresses limit only the use of proxy for resources requested by IP address, and note that search domains are also handled on the server side, so if you use them, you’ll have to decompose them in the no_proxy list.
Unless you are sure that the application doesn’t connect to services on the local machine, you should always include localhost and 127.0.0.1, because the proxy server won’t be able to handle those.
Some software always exclude them regardless the configuration.
Local networks may also be added, but it won’t help that there are different approaches to defining patterns.
You may specify a domain name (like example.com), which may also mean all of its subdomains.
Most applications can handle patterns like .example.com to mean all the subdomains but not example.com itself.
Some handle *.example.com the same way, usually recursively (i.e. subdomains of any depth).
In some cases, IP addresses and domains may be specified with globbing patterns like 192.168.0.*, but most implementations have limitations like you can only use * as the end or the beginning of a pattern, or it doesn’t match ..
You could of course list all the possible addresses, but it’s far from practical.
You may specify a port number for some implementations.
The Cloud Native world uses the Go programming language to a high extent, which now supports IP ranges in the CIDR notation, for example 192.168.0.0/24, just like Python’s requests and cURL.
So why do some networks keep using HTTP proxies? 🔗︎
Firstly, even if it needs significant extra work from the operators of individual services within the organization, most problems can eventually be solved: at the end of the day all systems that need internet access will get it. Many of these organizations have a complex system of policies for information security, which has been accepted by all parties including external auditors — keeping something suboptimal may seem much better than transitioning to another solution, which may lead to losing some security controls. Operating a strict proxy server needs expertise and the work of a team, which will have their own interests and arguments too. In some environments, the starting point would be no outgoing internet access, but the organization realized that specific types of network usage, like access to software updates may not be possible through local mirrors: which would be a higher risk than internet access alone. This may lead to an always growing filter configuration, which could be easily implemented with commercial proxy solutions.
Alternatives 🔗︎
The most common alternative of HTTP proxies is direct internet routing. If the endpoints have no globally routable IP addresses, dynamic NAT will easily solve the problem: the source address of outgoing packages is rewritten to an address from a pool of public addresses (often a single address in small networks). When a reply arrives to the recorded source port of that address, the destination will be rewritten to the original source address and forwarded.
This can be combined with a stateful packet filter for basic control and auditing.
Endpoint authentication can also be solved in lower layers (for example via 802.1x) too. Deeper analysis of the traffic can be solved by mirroring it to an IDS/IPS system.
The classic type of proxy server is the forward proxy, which is configured in the browser or the HTTP client. The client sends all requests directly to the proxy server, which in turn sends a similar request to the origin, and returns a response based on the origin’s response. The same principle can be implemented in a transparent way too: the client resolves the IP address of the targeted host, and initiates a connection to it, but the connection is intercepted or redirected by a gateway between the two machines. A transparent proxy may work surprisingly well in case of unencrypted HTTP traffic, but TLS interception raises even more problems compared to traditional proxy approach. Security improvements around HTTPS are meant to protect against exactly the same scenario with the only exception that in this case you trust (have to trust) the man-in-the-middle who intercepts your supposedly end-to-end encrypted traffic.
Some transparent proxy solutions provide endpoint authentication too, but it’s managed on a different channel.
A common difference between classic proxy servers and the solutions mentioned is that DNS resolution happens on the proxy server in case of a classic proxy.
This has two important implications.
Both alternative solutions need to inspect the payload to see the requested hostname (the Host header in HTTP or the server name indication [SNI] in TLS if encrypted client hello [EHO] is not used).
Moreover, a DNS resolver has to be available for the clients, which opens the possibility of DNS tunneling.
What’s the problem? 🔗︎
Let’s conclude the disadvantages of classic HTTP proxy setups:
- You may have to trust the proxy’s certificate authority, and won’t see the original certificates
- No access to other protocols like SSH (which is widely used for example for Git)
- Different client implementations, no centralized configuration on Linux
- Direct access to local (LAN) resources needs additional configuration
- Many actual setups have security flaws that cause more harm than good
Using Kubernetes behind a HTTP proxy 🔗︎
Most of the time, Kubernetes control plane components don’t even need access to resources on the internet, so unless you absolutely need them, we recommend not to set the environment variables for the etcd cluster or the API server.
Unless your cluster runs with a cloud integration where the cloud provider API is not accessible directly, the controllers can also work fine without the proxy.
However, if they do need it, you should set up no_proxy to exclude at least the API server address, the svc domain for Kubernetes services, and the PodIP range.
If you use Docker containers from the internet, you’ll have to set up the Docker daemon or Containerd to use the proxy.
Finally, we recommend to evaluate your workloads individually if they need internet access.
If they do, you should pass the above mentioned environment variables to the pods, and include the above mentioned hosts in the no_proxy list.
If your proxy intercepts HTTPS traffic, you will have to mount or build into your container images the certificate of the CA used by the proxy.
Note that if you use Helm charts from the internet, the Helm client will also have to be configured.
Banzai Cloud Pipeline together with PKE can be set up globally or on a per-cluster level to use a Proxy for accessing cloud provider APIs, Helm charts, Docker containers, etc from the internet, but most of the time, we set up local mirrors and repositories in the restricted environment of our enterprise customers.
For an universal solution of injecting proxy configuration to your workloads, check our Pod level external HTTP(S) proxy configuration with Istio blog post.
About PKE 🔗︎
Banzai Cloud Pipeline Kubernetes Engine (PKE) is a simple, secure and powerful CNCF-certified Kubernetes distribution, the preferred Kubernetes run-time of the Pipeline platform. It was designed to work on any cloud, VM or on bare metal nodes to provide a scalable and secure foundation for private clouds. PKE is cloud-aware and includes an ever-increasing number of cloud and platform integrations.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.