






Banzai Cloud’s Pipeline platform is an operating system which allows enterprises to develop, deploy and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security - multiple authentication backends, fine grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, etc. - is a tier zero feature of the Pipeline platform, which we strive to automate and enable to all enterprises.
tl;dr: 🔗︎
- The Pipeline platform automatically scans images for vulnerabilities
- We switched from Clair to Anchore Engine to gain multiple vulnerability backends, better multi-tenancy and policy validation
- We open sourced a Helm chart to deploy Anchore
- We open sourced a Kubernetes Admission Webhook to scan images
- Pipeline automates all of these steps
In this post we’d like to go into detail about how container image vulnerability scans work - with a focus on catching vulnerabilities at the point in time at which deployments are submitted into the cluster.
Key aspects of container image vulnerability scans 🔗︎
- Every image should be scanned no matter where it comes from (i.e: deployment, operator, etc.)
- It should be possible to set up policies with certain rules to allow or reject a pod
- These policies should be associated with clusters
- If a policy result is rejected, creation of the pod should be blocked
- There should be an easy way to whitelist a Helm deployment
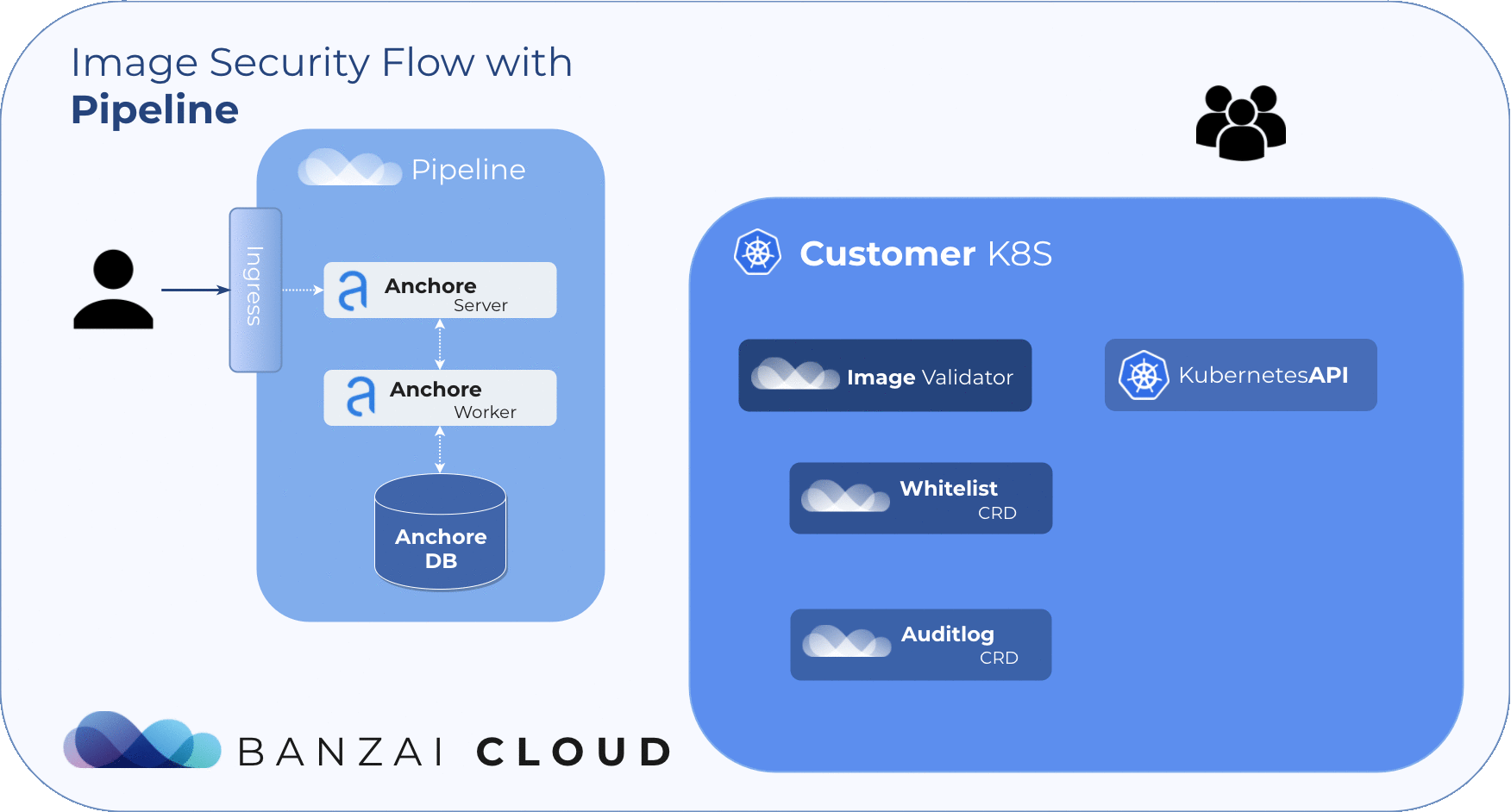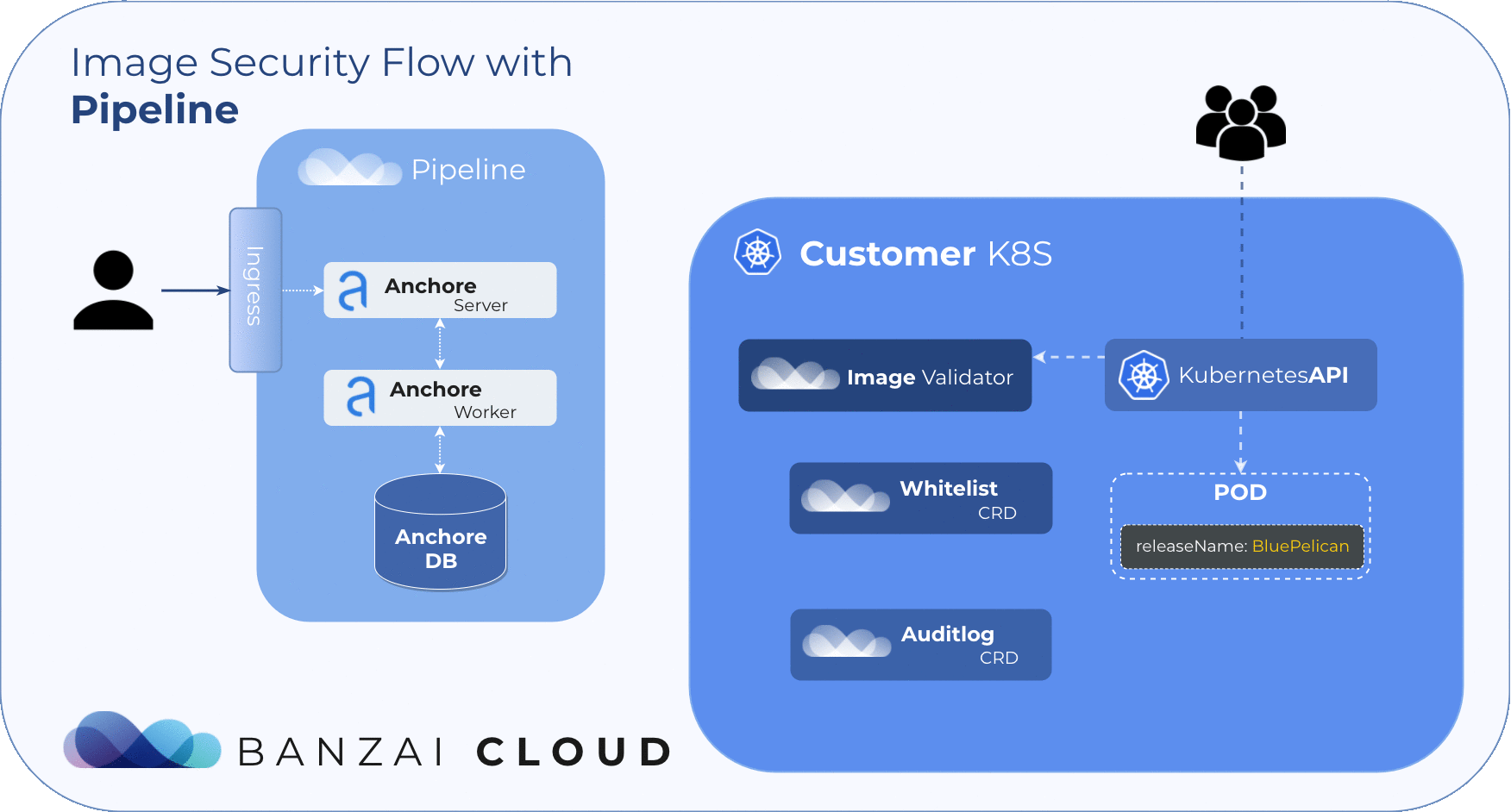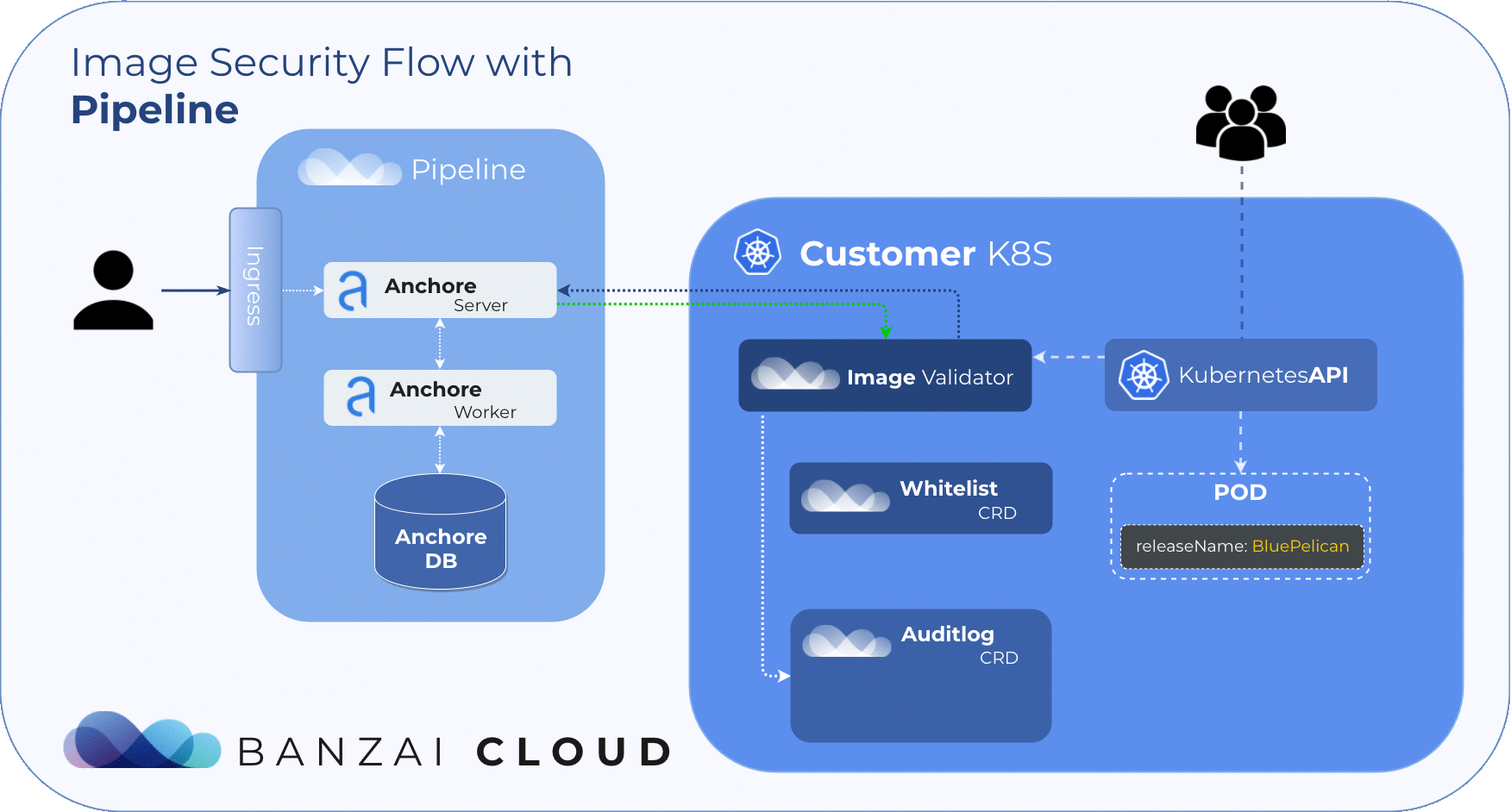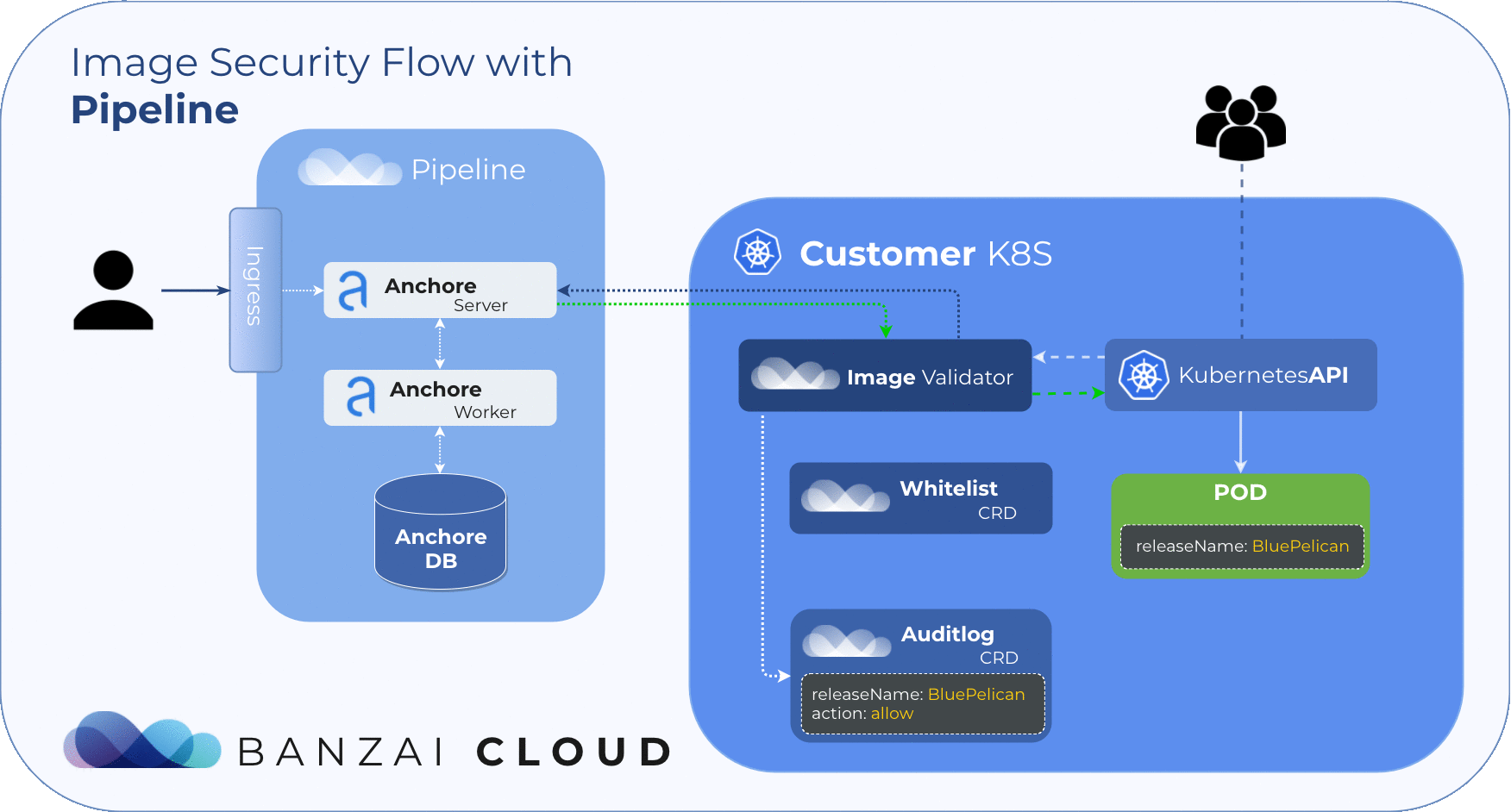
Admission webhooks and Anchore Engine 🔗︎
A few months back our vulnerability scans were based on Clair, but we ended up switching to Anchore Engine, due to the multi-tenant nature of our platform and a host of new requirements from our users.
The Anchore Engine is an open source project that provides a centralized service for the inspection, analysis, and certification of container images. A PostgreSQL database is required to provide persistent storage for the engine. And the Anchore engine can be accessed directly through a RESTful API or via the Anchore CLI.
If you want to try it out for yourself, we open sourced the Helm chart that we built and are using on our Pipeline platform. It supports PostgreSQL and Google’s CloudSQL as database backends. Needless to say, the whole process is automated thanks to Pipeline.
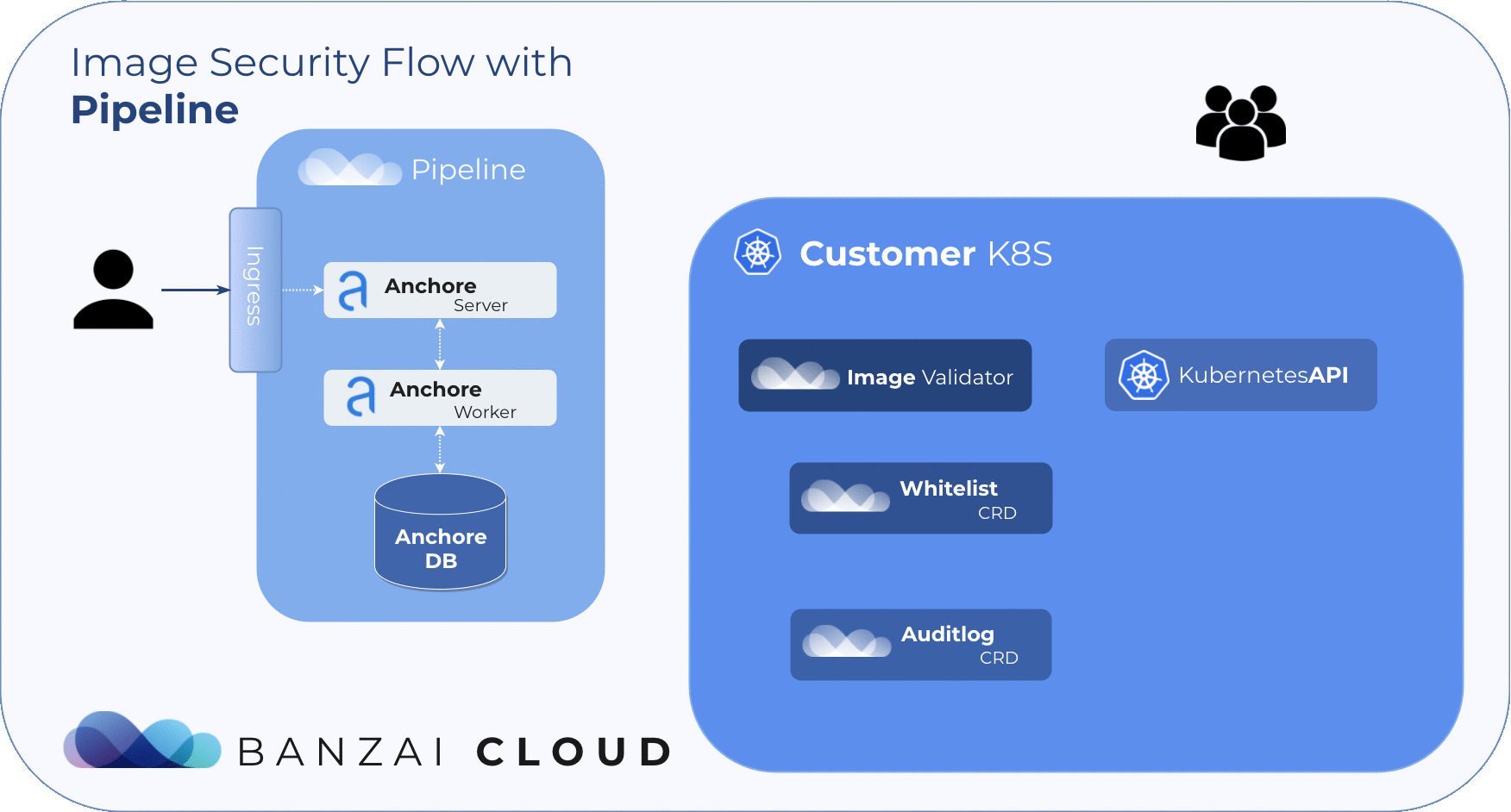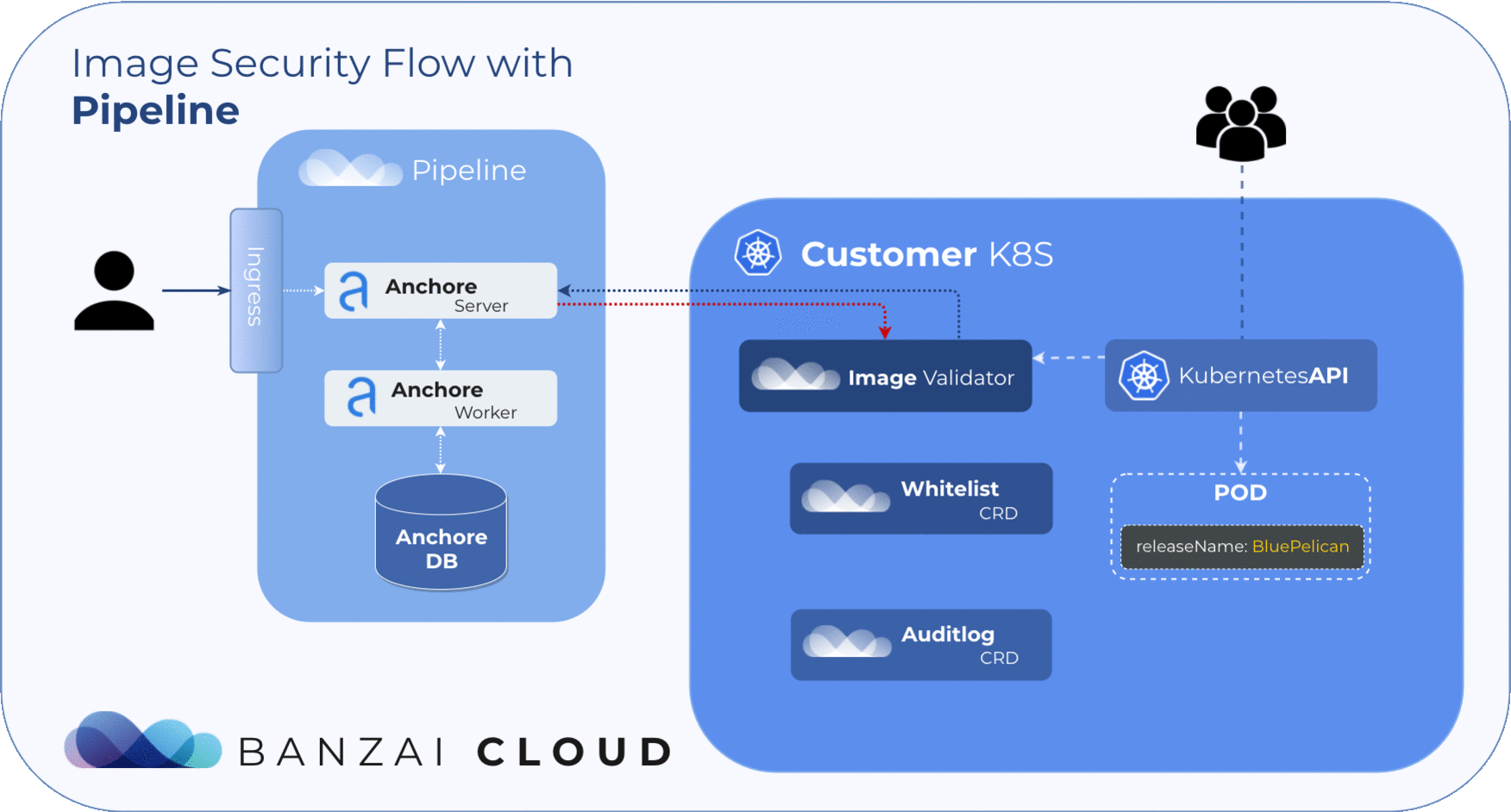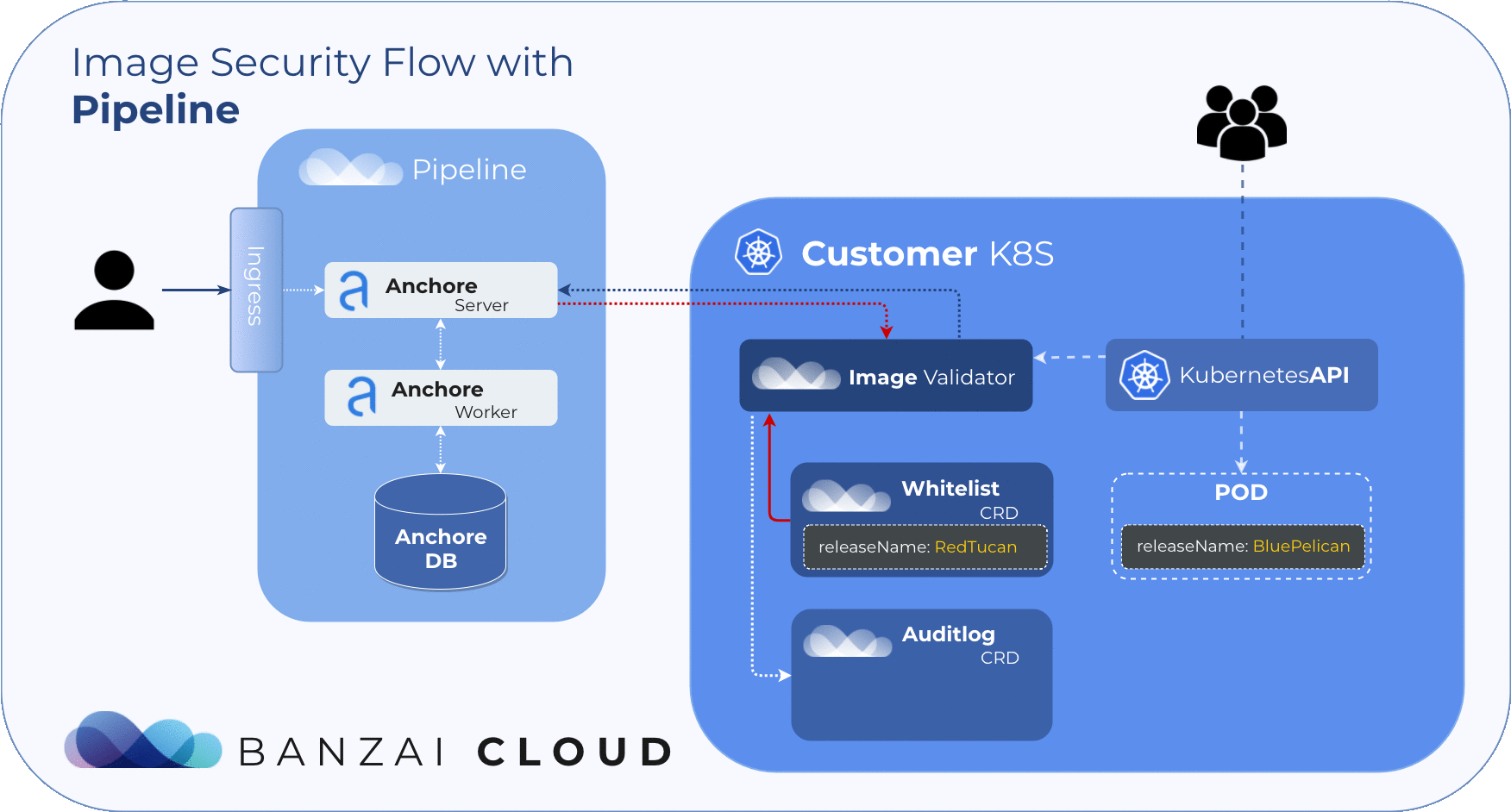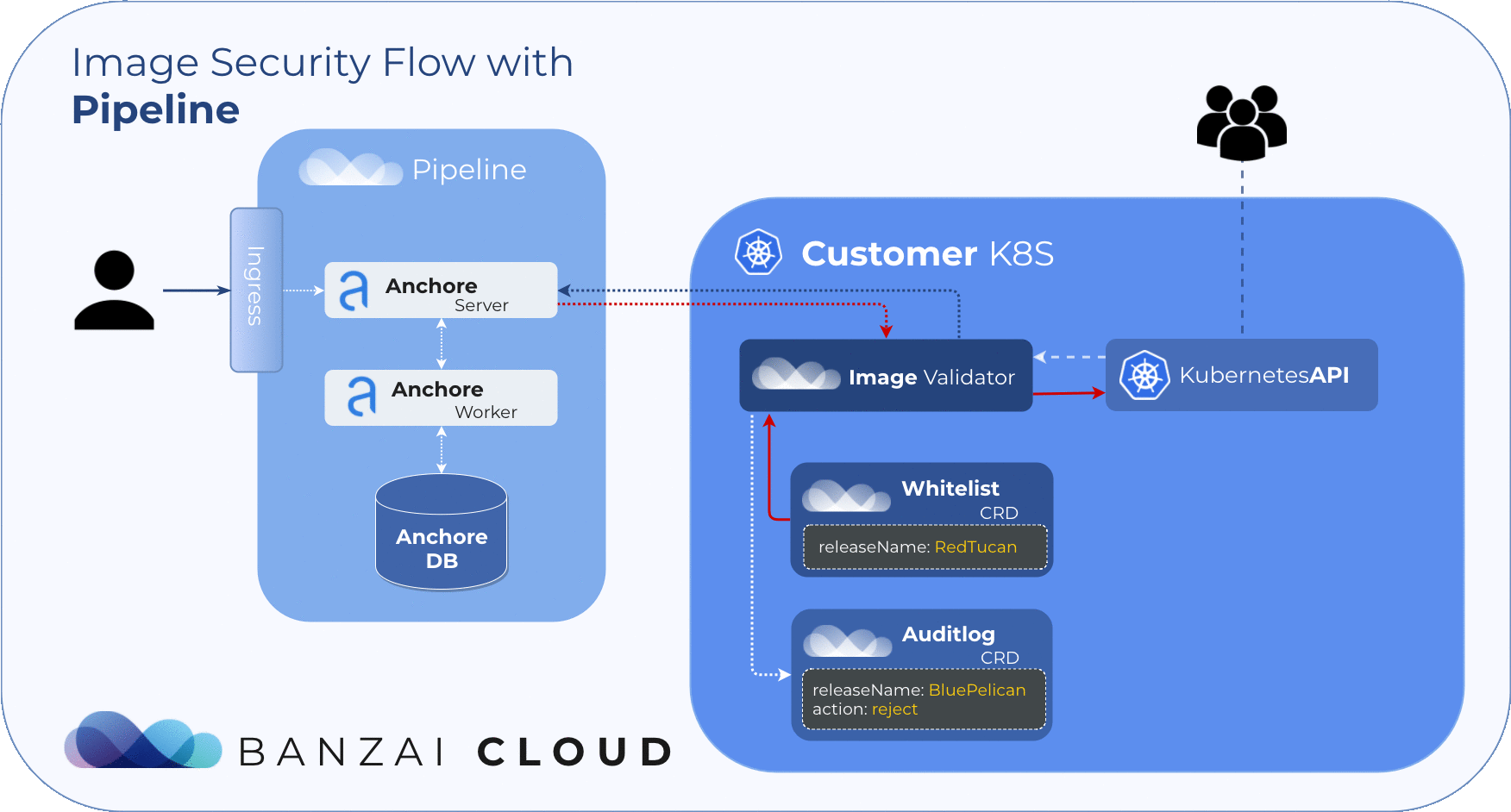
Anchore Image Validator 🔗︎
The Anchore Image Validator works as an admission server. After it is registered to the Kubernetes cluster as a Validating Webhook, it will validate any Pod deployed to the cluster. The server inspects the images that are defined in PodSpec against the configured Anchore Engine endpoint. Based on that response, the admission hook can decide whether to accept or reject that deployment.
If you want to learn more about
Validating Admission Webhooks, you can find a detailed description in one of our previous blog posts, here: in-depth introduction to admission webhooks
Anchore Image Validator was inspired by Vic Iglesias’ kubernetes-anchore-image-validator which leverages the Generic Admission Server for most of the heavy lifting of implementing the admission webhook API. We redesigned and extended it with whitelist and scanlog features. For flexibility, it uses Custom Resource Definitions to store and evaluate those extensions.
Using the Anchore Image Validator 🔗︎
The Helm deployment of Anchore Policy Validator contains all the necessary resources including CRDs.
$ kubectl get validatingwebhookconfigurations.admissionregistration.k8s.io
NAME AGE
validator-anchore-policy-validator.admission.anchore.io 1d$ kubectl get apiservices.apiregistration.k8s.io
NAME AGE
v1. 16d
v1.apps 16d
v1.authentication.k8s.io 16d
v1.authorization.k8s.io 16d
v1.autoscaling 16d
v1.batch 16d
v1.networking.k8s.io 16d
v1.rbac.authorization.k8s.io 16d
v1.storage.k8s.io 16d
v1alpha1.security.banzaicloud.com 1d
v1beta1.admission.anchore.io 1d
v1beta1.admissionregistration.k8s.io 16d
v1beta1.apiextensions.k8s.io 16d
v1beta1.apps 16d
v1beta1.authentication.k8s.io 16d
v1beta1.authorization.k8s.io 16d
v1beta1.batch 16d
v1beta1.certificates.k8s.io 16d
v1beta1.extensions 16d
v1beta1.metrics.k8s.io 16d
v1beta1.policy 16d
v1beta1.rbac.authorization.k8s.io 16d
v1beta1.storage.k8s.io 16d
v1beta2.apps 16d
v2beta1.autoscaling 16dAfter deploying these CRDs, you can access them via the Kubernetes API server:
$ curl http://<k8s-apiserver>/apis/security.banzaicloud.com/v1alpha1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "security.banzaicloud.com/v1alpha1",
"resources": [
{
"name": "whitelistitems",
"singularName": "whitelistitem",
"namespaced": false,
"kind": "WhiteListItem",
"verbs": [ ... ],
"shortNames": [
"wl"
]
},
{
"name": "audits",
"singularName": "audit",
"namespaced": false,
"kind": "Audit",
"verbs": [ ... ]
}
]
}And these resources are accessible with the kubectl command:
$ kubectl get crd
NAME AGE
audits.security.banzaicloud.com 21h
whitelistitems.security.banzaicloud.com 21h
$ kubectl get whitelistitems -o wide -o=custom-columns=NAME:.metadata.name,CREATOR:.spec.creator,REASON:.spec.reason
NAME CREATOR REASON
test-whiltelist pbalogh-sa just-testing
$ kubectl get audits -o wide -o=custom-columns=NAME:.metadata.name,RELEASE:.spec.releaseName,IMAGES:.spec.image,RESULT:.spec.result
NAME RELEASE IMAGES RESULT
replicaset-test-b468ccf8b test-b468ccf8b-2s6tj [nginx] [reject]Whitelists 🔗︎
While there exists a way of whitelisting in the Anchore Engine itself, such whitelists are only applicable to attributes like:
- image name, tag, hash,
- on concrete CVEs,
- libraries, files or other filesystem based matches.
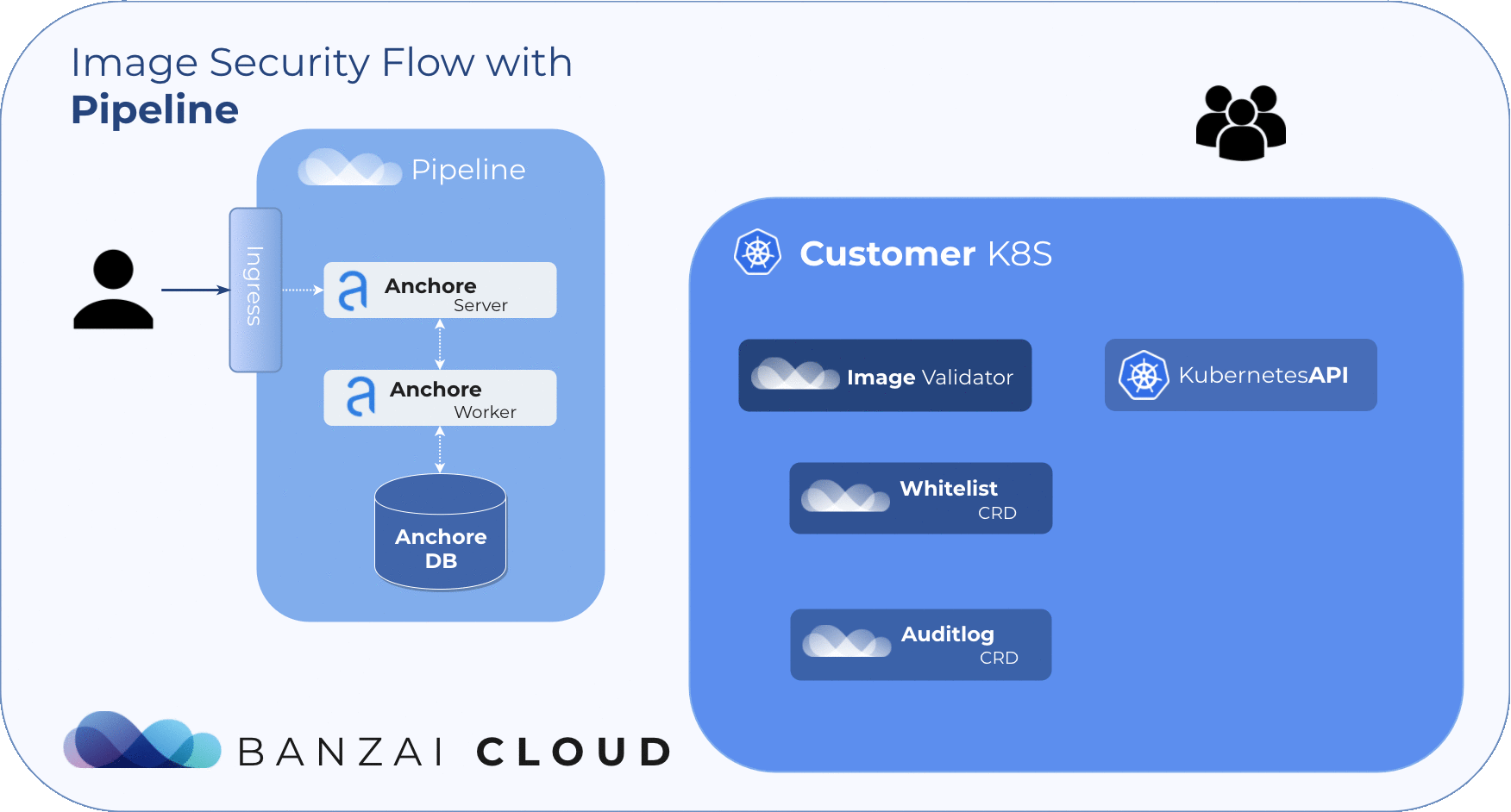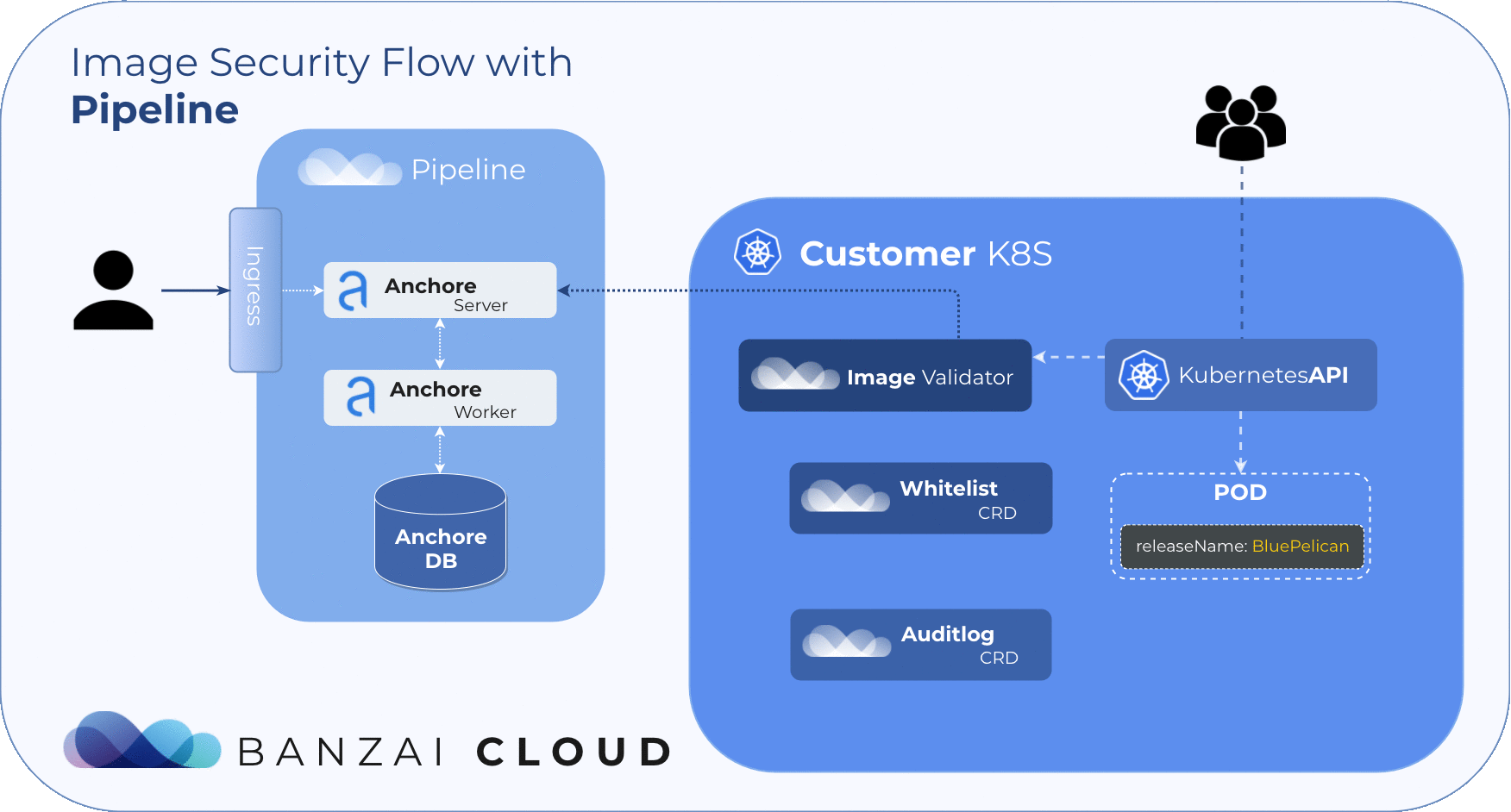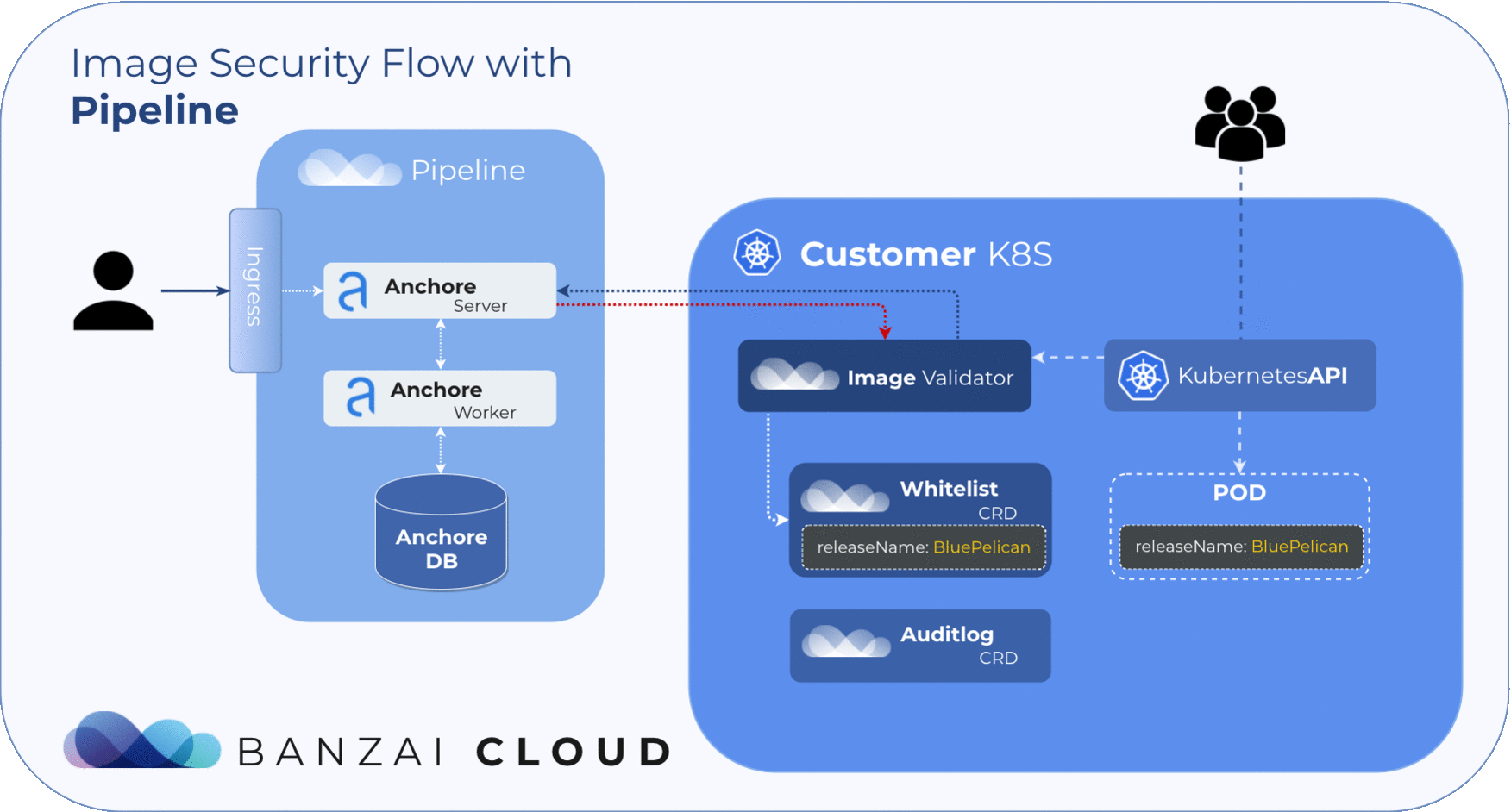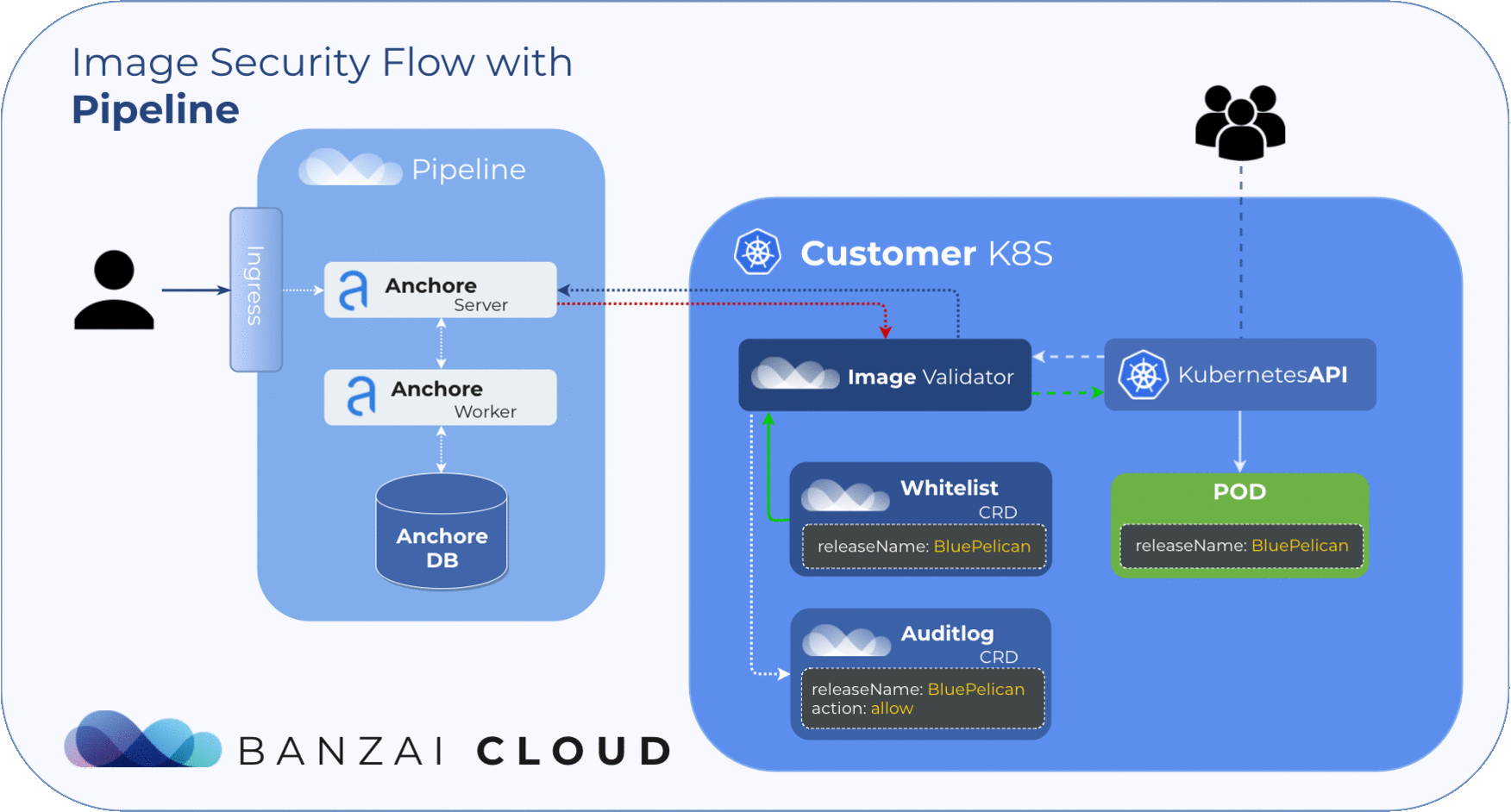
Our approach to filtering is based on Helm Deployments. However, covering whitelists at the deployment level with CVE or image names is simply not feasible. To manage whitelisted deployments we use a custom resource definition, so the admission hook will accept deployments that match any whitelist element no matter what the scan result is.
Note: All resources included in a Helm Deployment must have the
release-namelabel.
The CRD structure should include the following data:
NameName of the whitelisted releasecreatorThe Pipeline user who created the rulereasonReason for whitelisting
Example whitelist:
$ kubectl get whitelist test-whitelist -o yaml
apiVersion: security.banzaicloud.com/v1alpha1
kind: WhiteListItem
metadata:
clusterName: ""
creationTimestamp: 2018-09-25T06:44:49Z
name: test-whitelist
namespace: ""
resourceVersion: "1981225"
selfLink: /apis/security.banzaicloud.com/v1alpha1/test-whiltelist
uid: 7f9a094d-c08e-11e8-b34e-42010a8e010f
spec:
creator: pbalogh-sa
reason: just-testingThis approach will allow the investigation of problems while not disturbing production services.
Scan Events (Audit logs) 🔗︎
Finding the result of an admission hook decision can be troublesome, so we introduced the Audit custom resource. With this custom resource it’s easy to track the result of each scan. Instead of searching in events, you can also easily filter these resources with kubectl. The CRD structure includes the following data:
releaseNameScanned releaseresourceScanned resource (Pod)imageScanned images (in Pod)resultScan results (per image)actionAdmission action (allow, reject)
During image scans, Admission server logs result to audits.security.banzaicloud.com and set their ownerReferences to the scanned Pod’s parent. This provides us with a compact overview of the resources running on the cluster. Because these events are bound to Kubernetes resources, it allows for the cluster to clean them up when the original resource (pod) is no longer present.
Example audit log:
$ kubectl get audits replicaset-test-b468ccf8b -o yaml
apiVersion: security.banzaicloud.com/v1alpha1
kind: Audit
metadata:
clusterName: ""
creationTimestamp: 2018-09-24T09:06:31Z
labels:
fakerelease: "true"
name: replicaset-test-b468ccf8b
namespace: ""
ownerReferences:
- apiVersion: extensions/v1beta1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: test-b468ccf8b
uid: 1c20ed8d-bfd9-11e8-b34e-42010a8e010f
resourceVersion: "1857033"
selfLink: /apis/security.banzaicloud.com/v1alpha1/replicaset-test-b468ccf8b
uid: 20e75829-bfd9-11e8-b34e-42010a8e010f
spec:
action: allowed
image:
- postgres
releaseName: test-b468ccf8b-2s6tj
resource: Pod
result:
- 'Image passed policy check: postgres'
status:
state: ""A core feature of the Pipeline Platform 🔗︎
These building blocks are great. However, ordinarily there would be many steps left to perform manually. We have tightly integrated these tasks into Pipeline, to help manage your cluster security. We automated the following:
- Generate Anchore User with Credentials (This is one technical user per cluster)
- Save the generated credentials to Vault - Pipeline’s main Secret Store. (We persist these credentials for later use)
- Setup the Anchore User
Policy bundles. The user can choose one from a number of predefined policy bundles or create a custom one. - Deploy the
Validating Admission Webhookusing credentials and Anchore Engine service URL - Provide a RESTful API for all resources trough Pipeline
Predefined policy bundles 🔗︎
To simplify bootstrapping, we have predefined basic policy bundles for Anchore
Allow allThis policy is the most permissive. One can deploy anything, but it recieves feedback about all the deployed imagesReject CriticalThis policy will prevent deploying containers with critical CVEReject HighThis policy will prevent deploying containers with high severity CVEBlock rootThis policy will prevent deploying containers with apps running root privilegesDeny allThis is the most restrictive policy. Only explicitly whitelisted releases are accepted
Next steps 🔗︎
The implementation of this image validation solution represents a huge step towards enabling a secure and safe Kubernetes infrastructure. This post describes how we block deployments that fail the configured security policies. The Pipeline platform follows the vulnerability lifecycle of a deployment and provides regular scans and notifications to alert the operators when a new security issue is found. Stay tuned; we’ll write more about this feature of the Pipeline platform soon.




