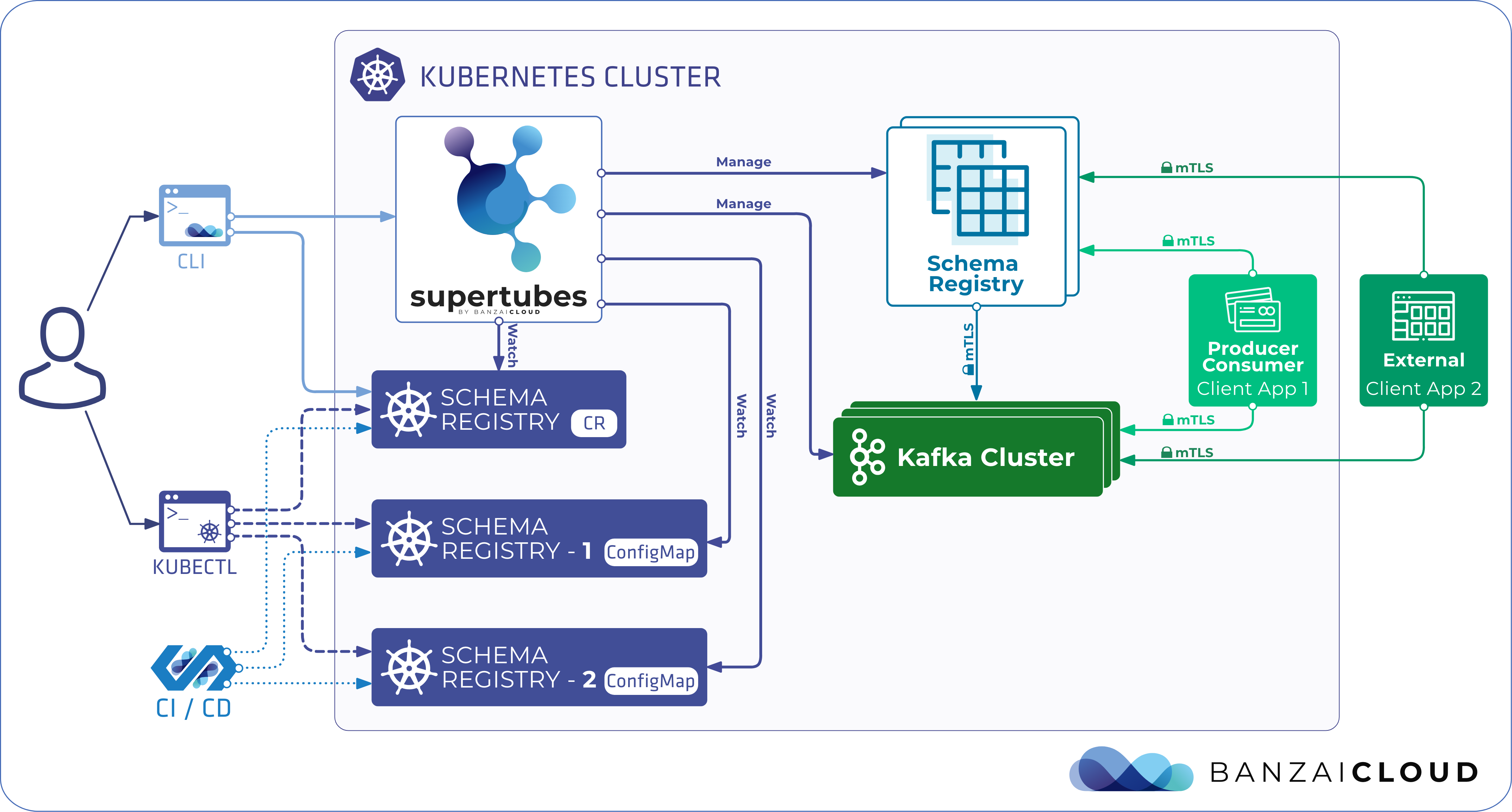
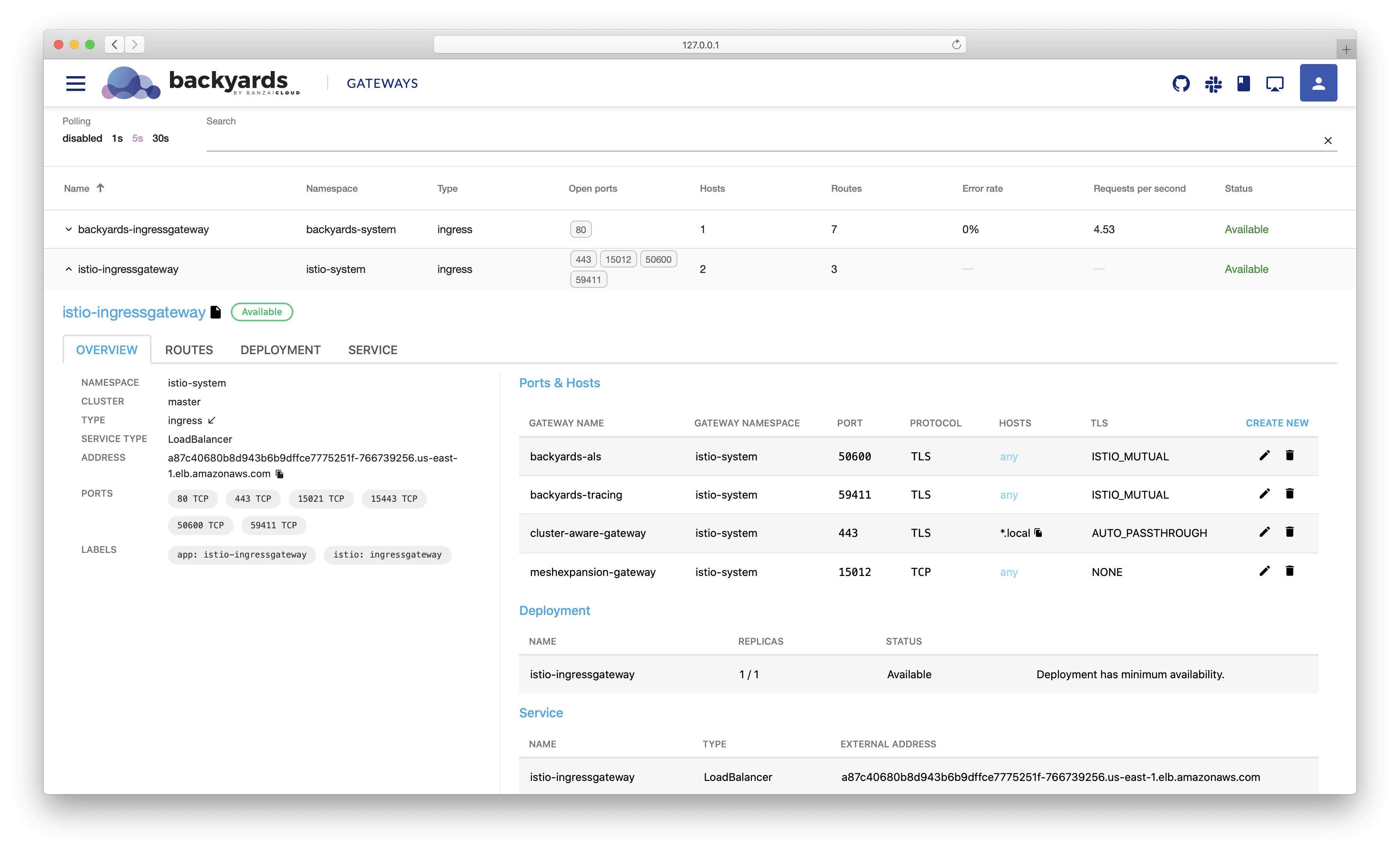
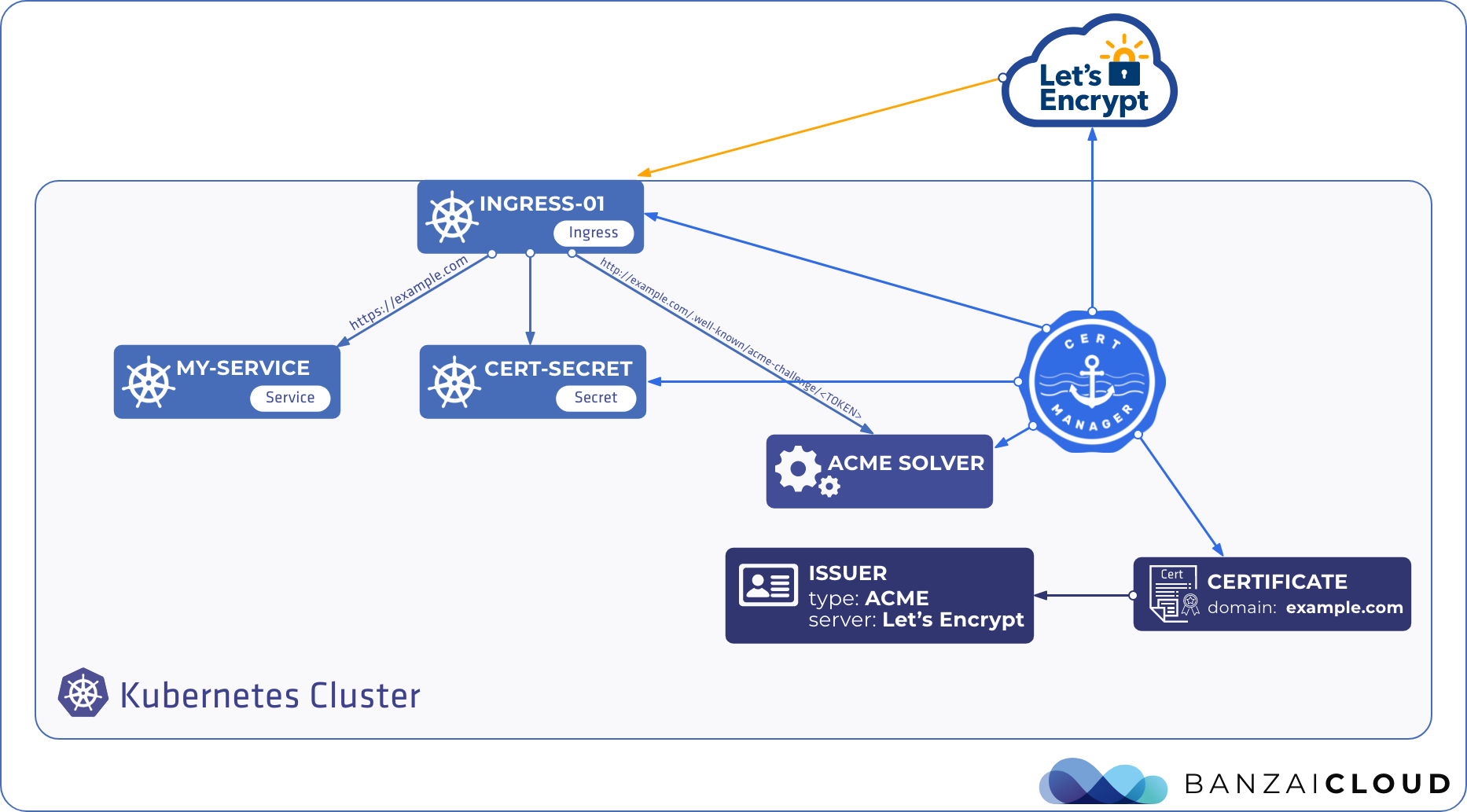
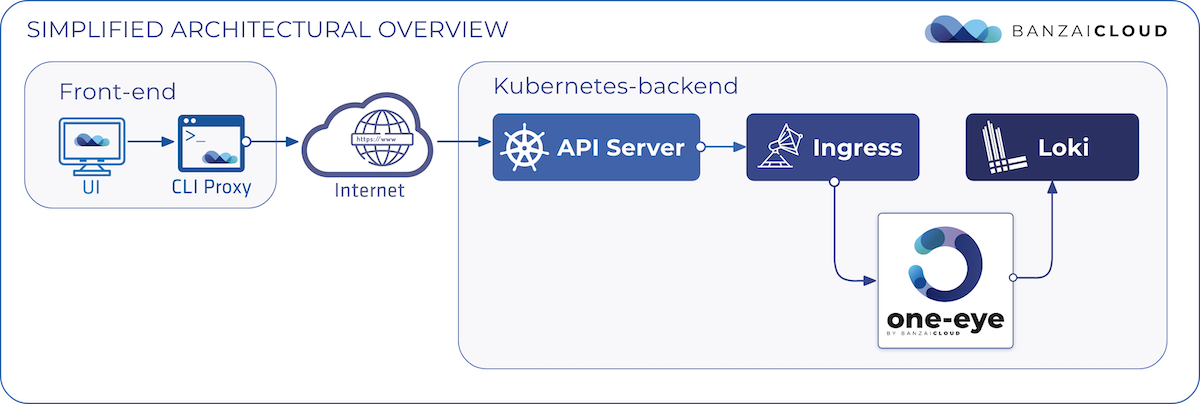
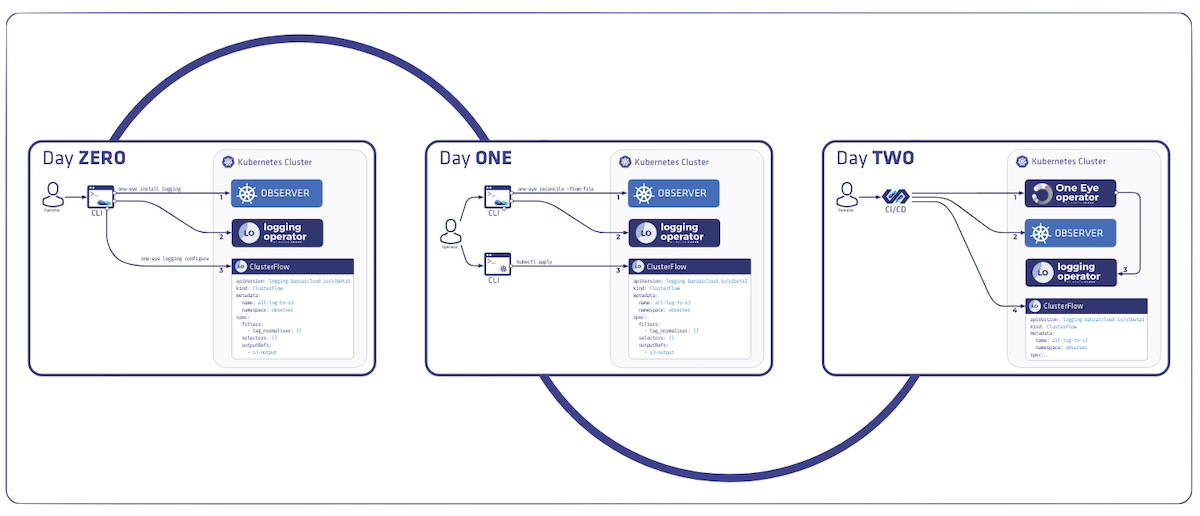
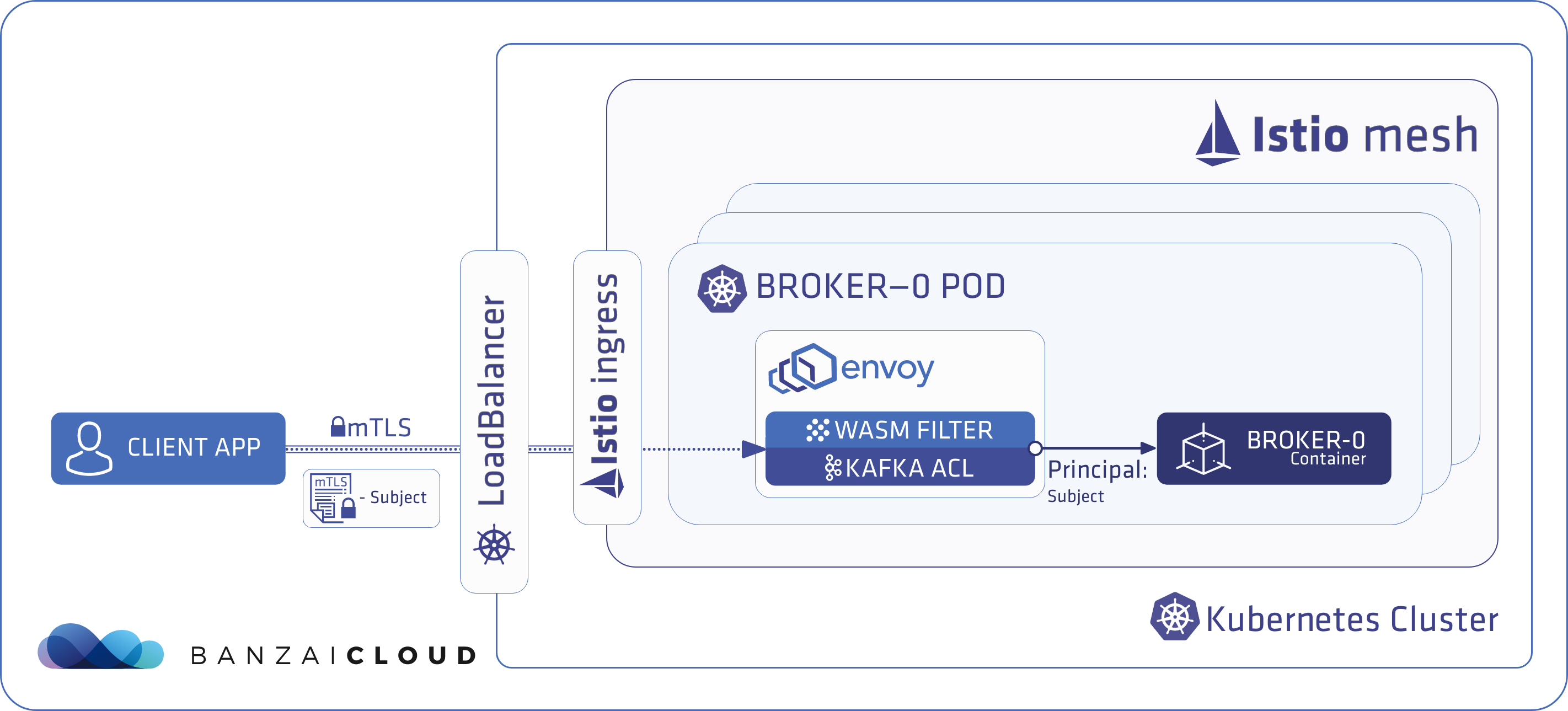
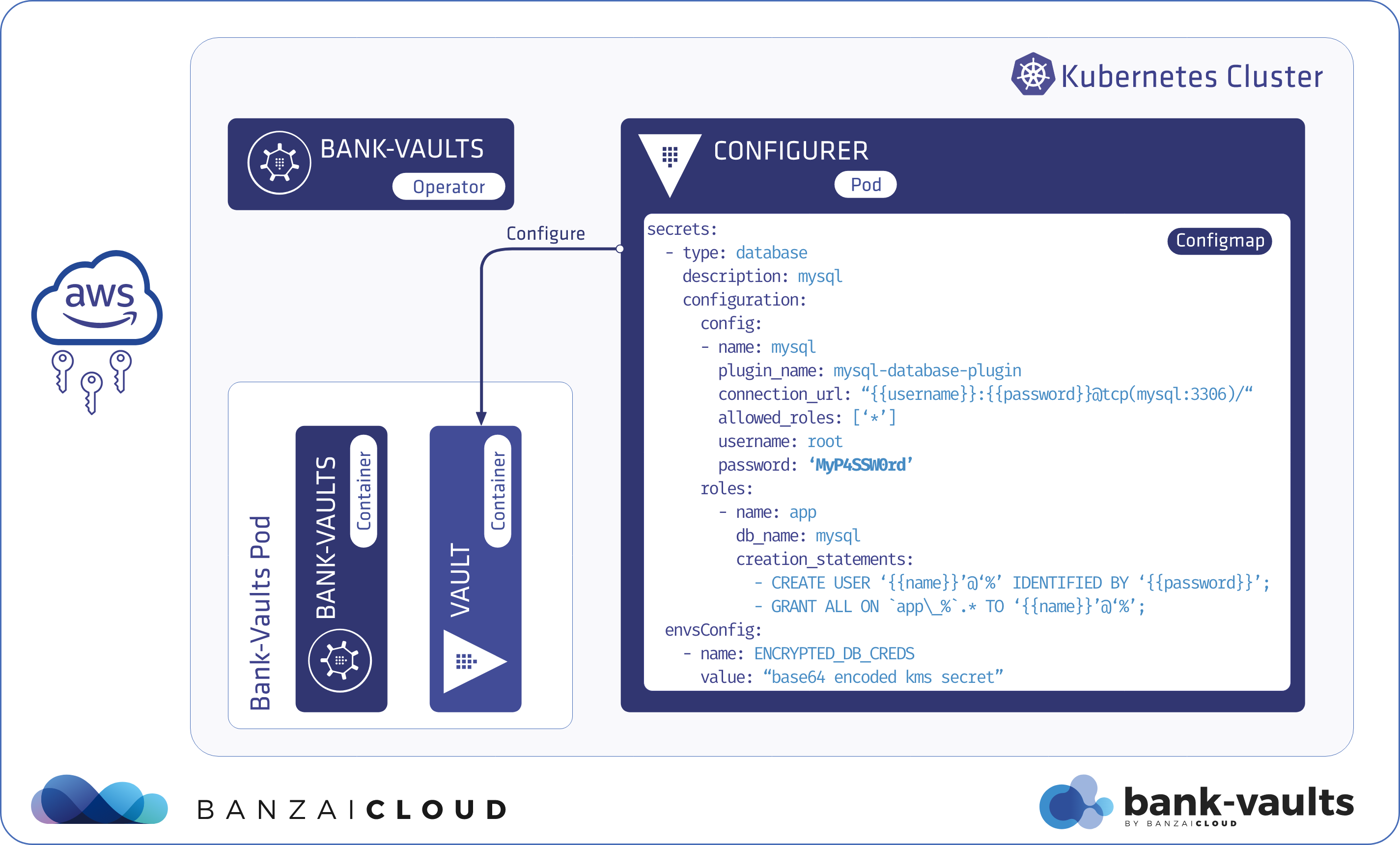
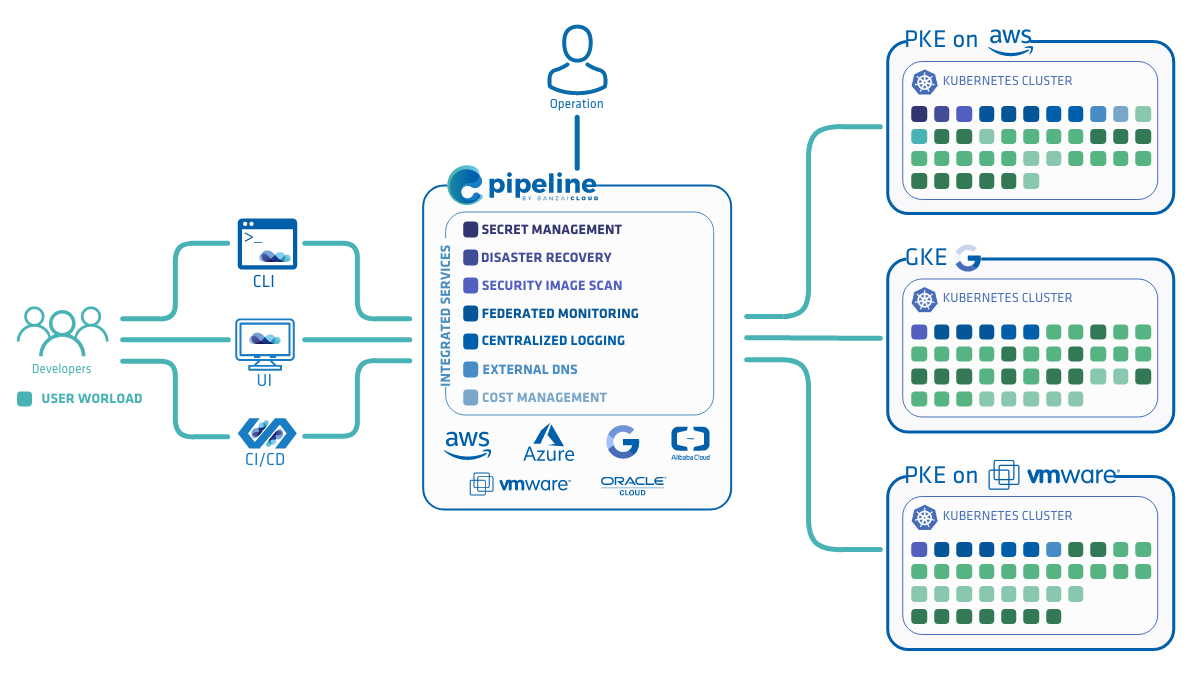
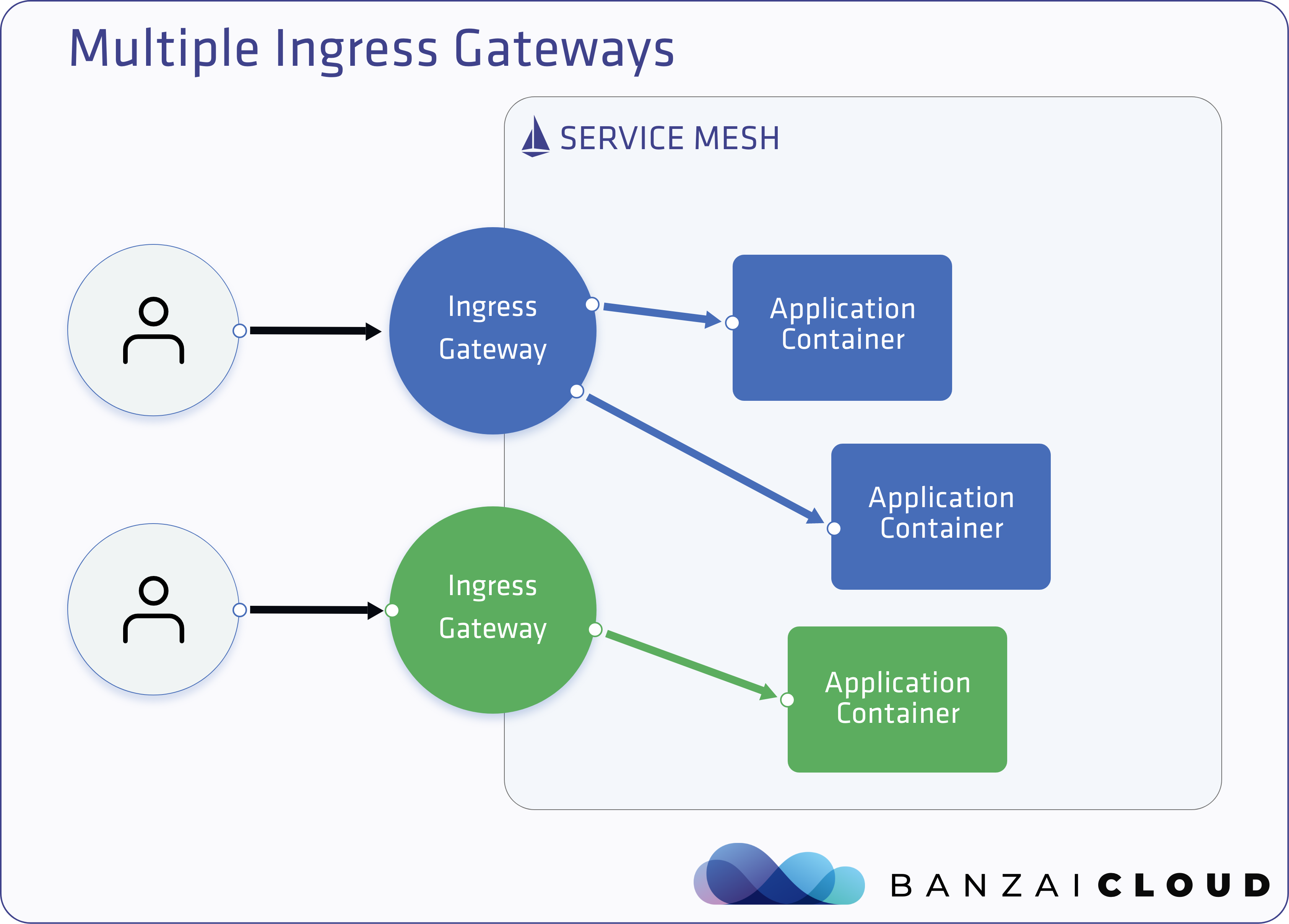
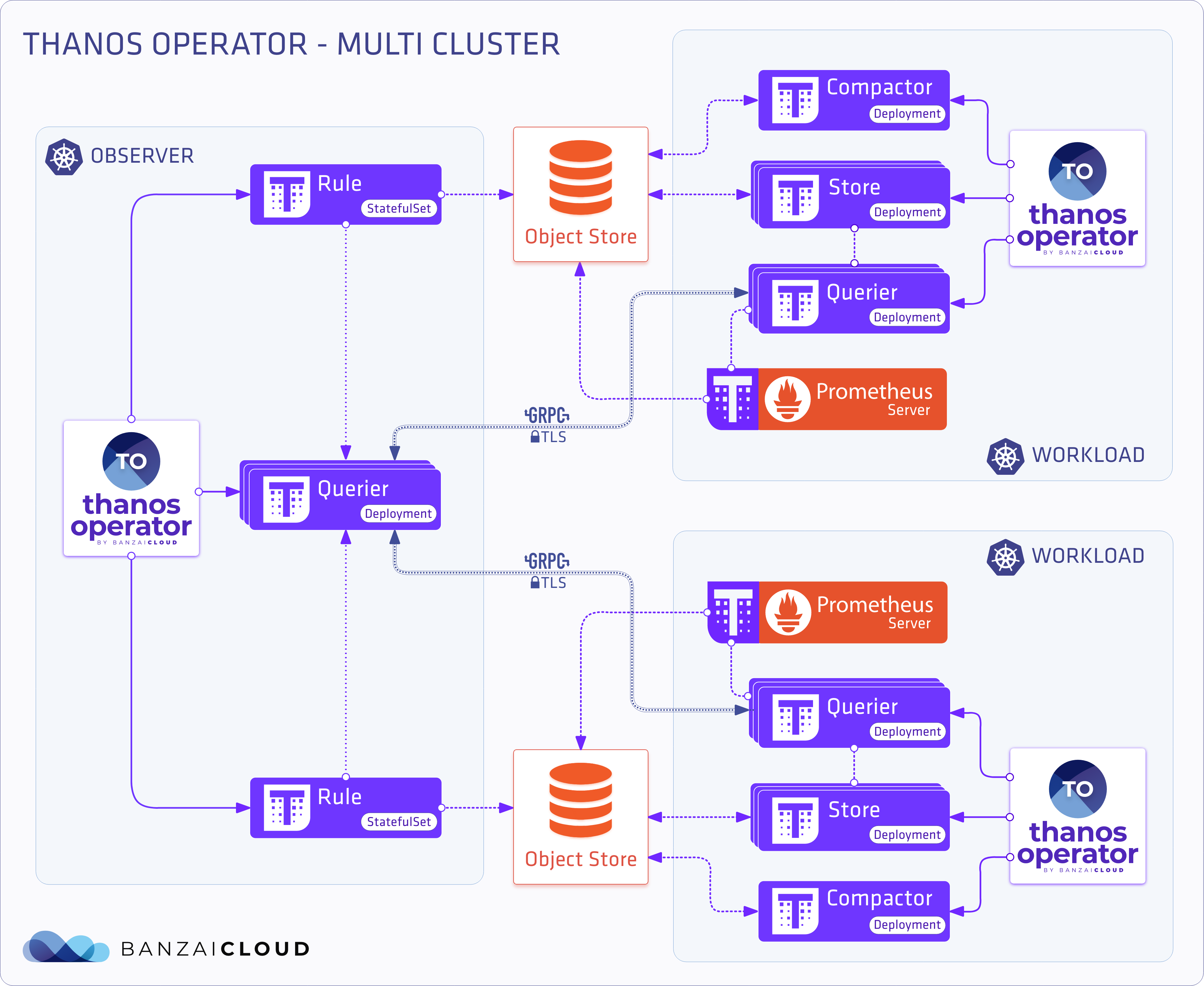
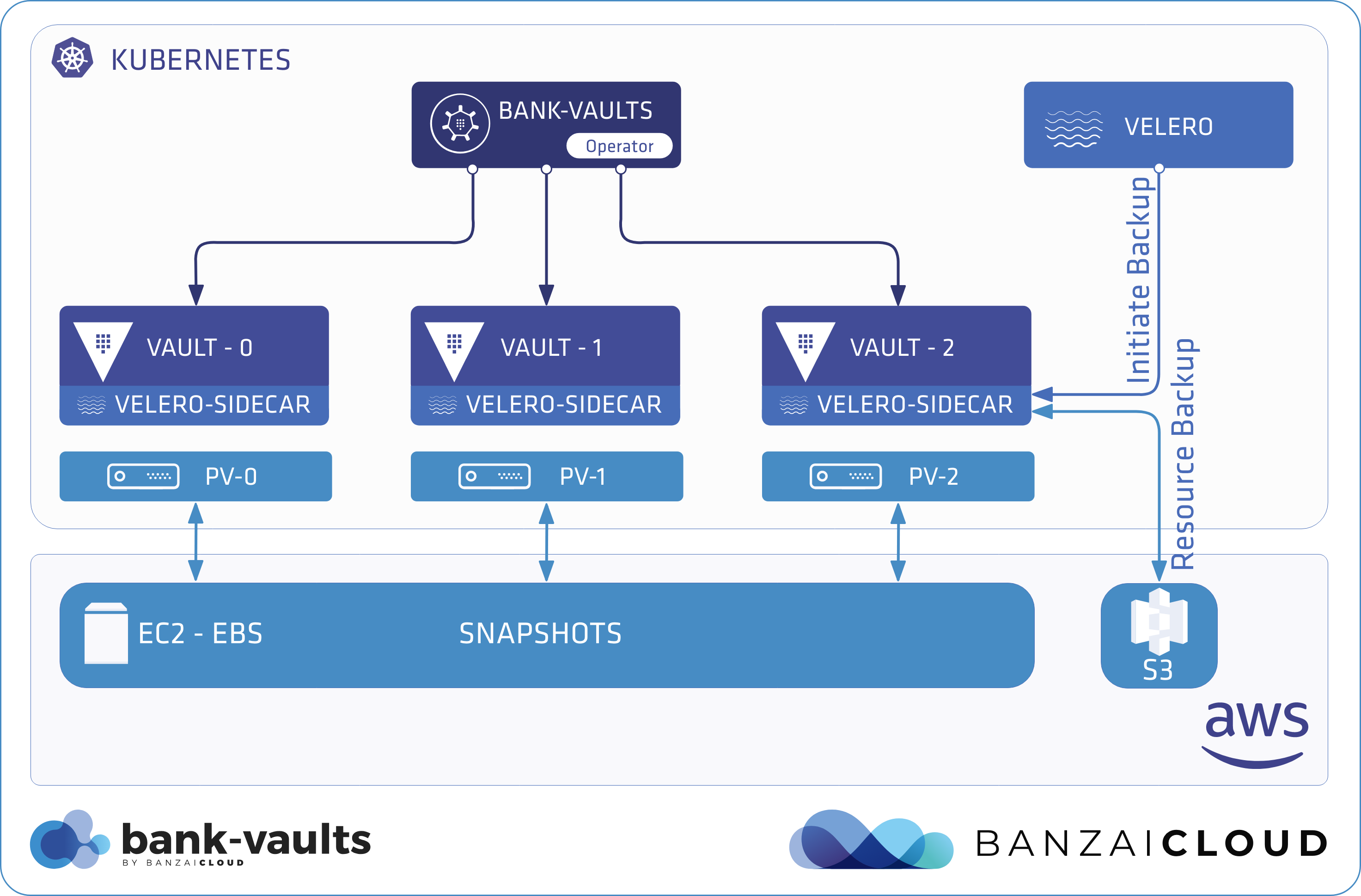
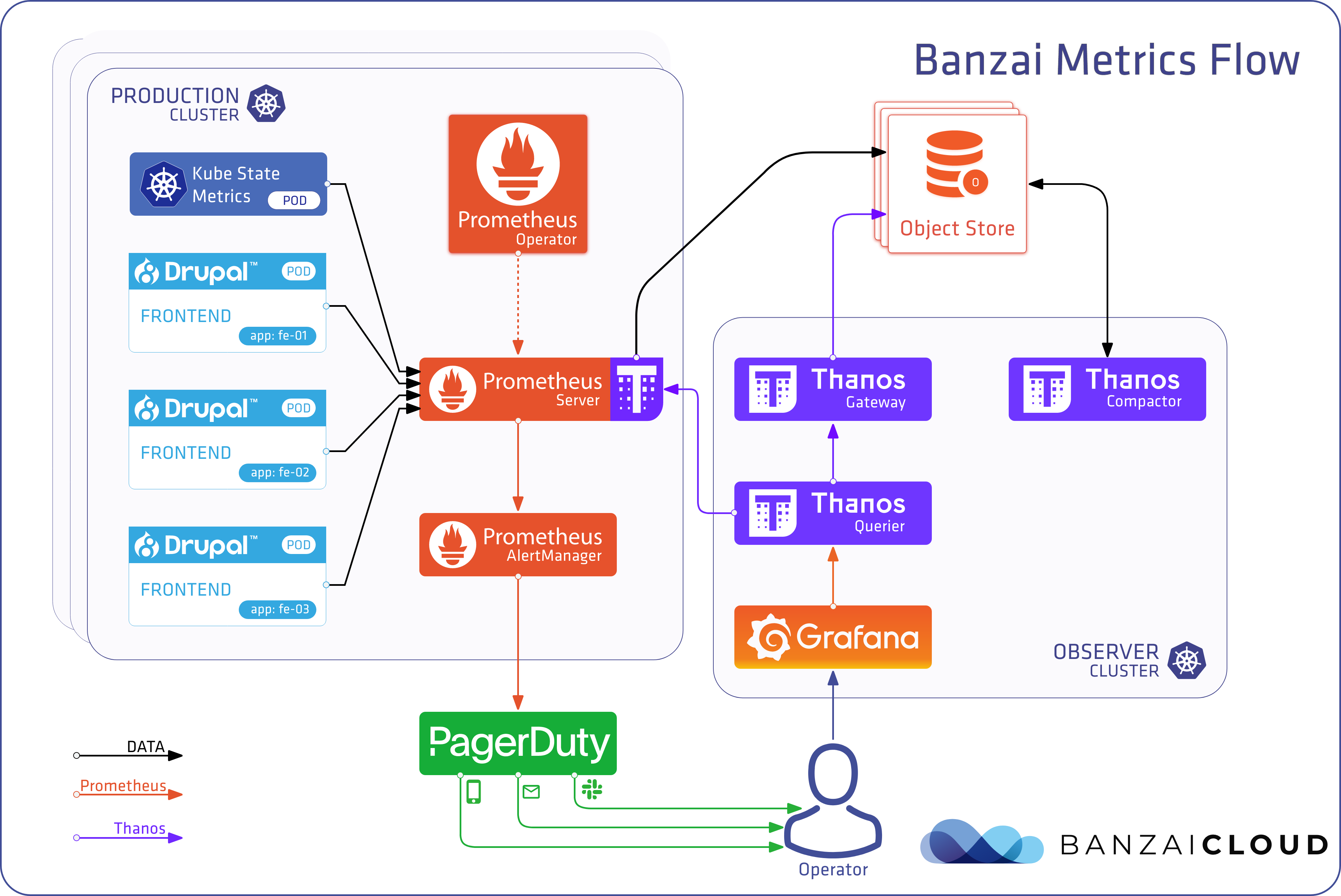
Proxying services into Kubernetes
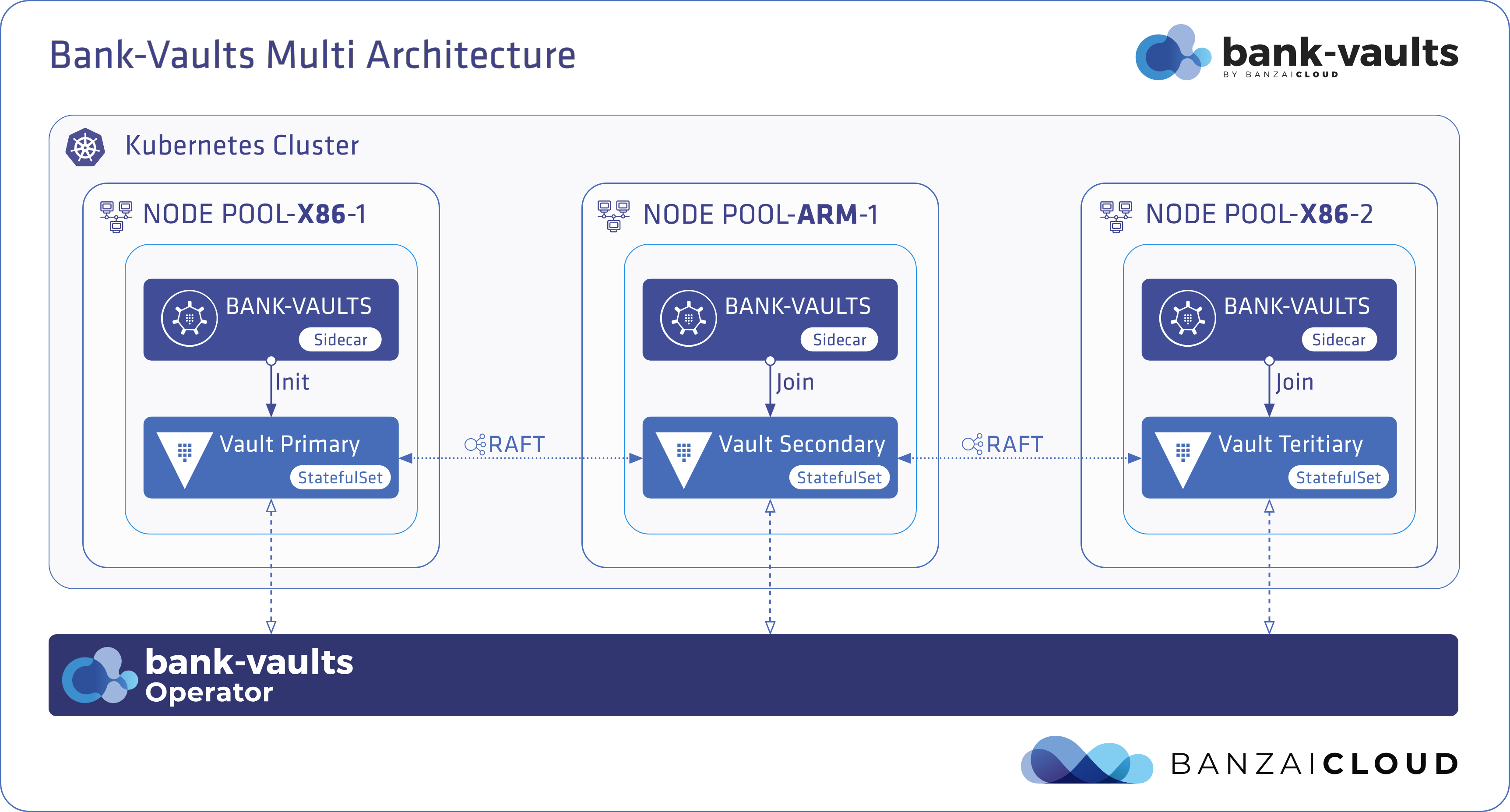
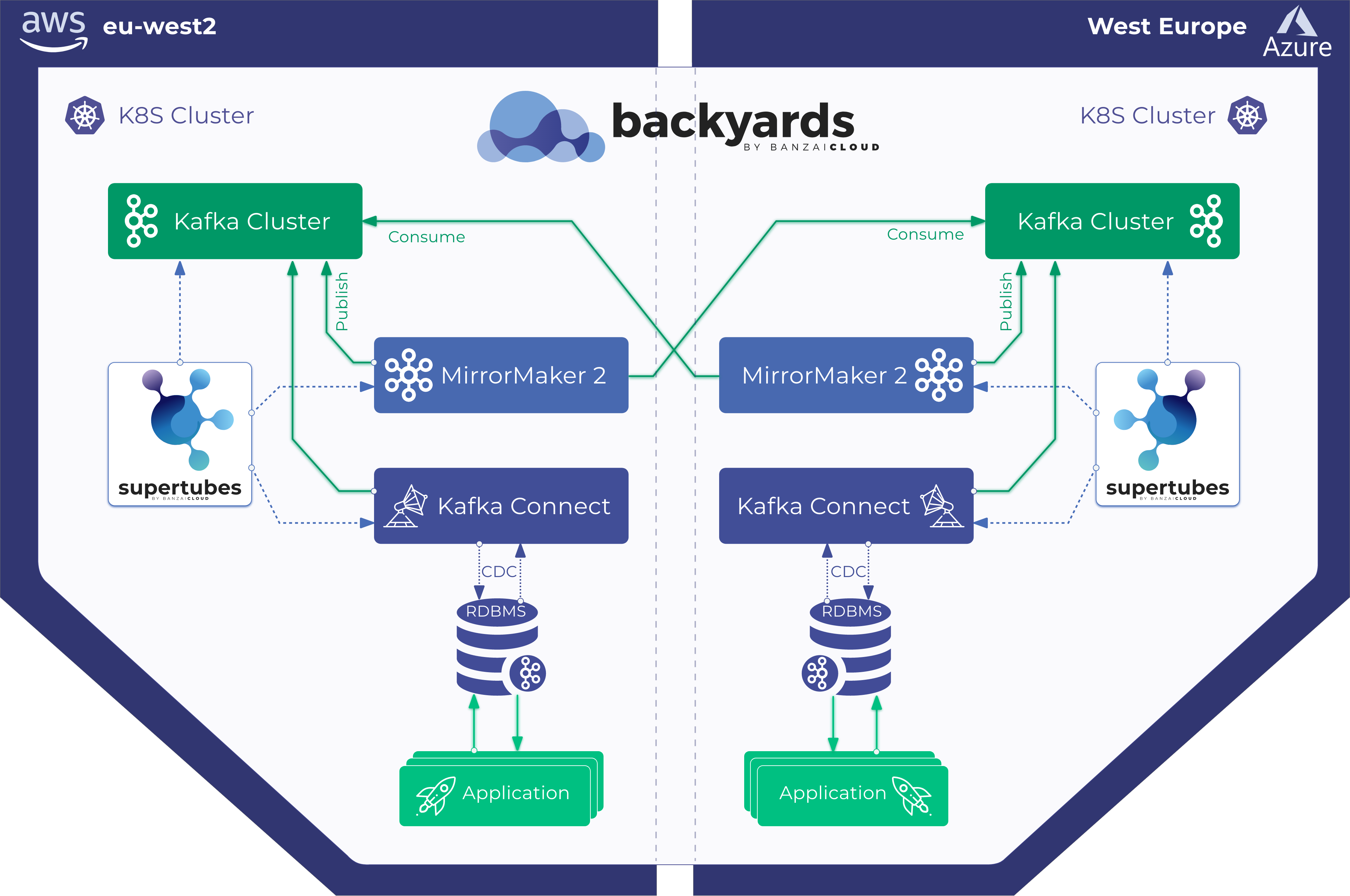
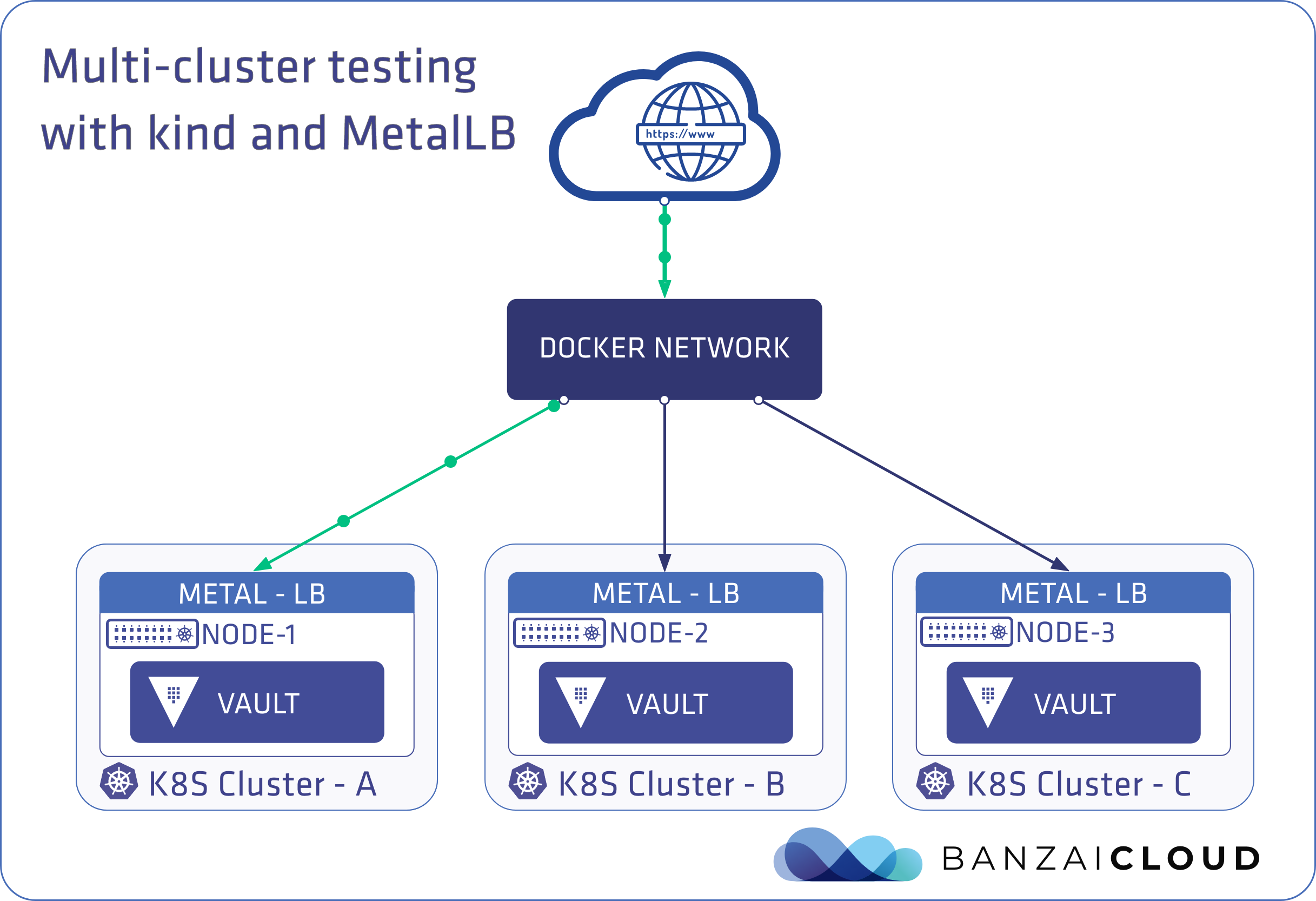
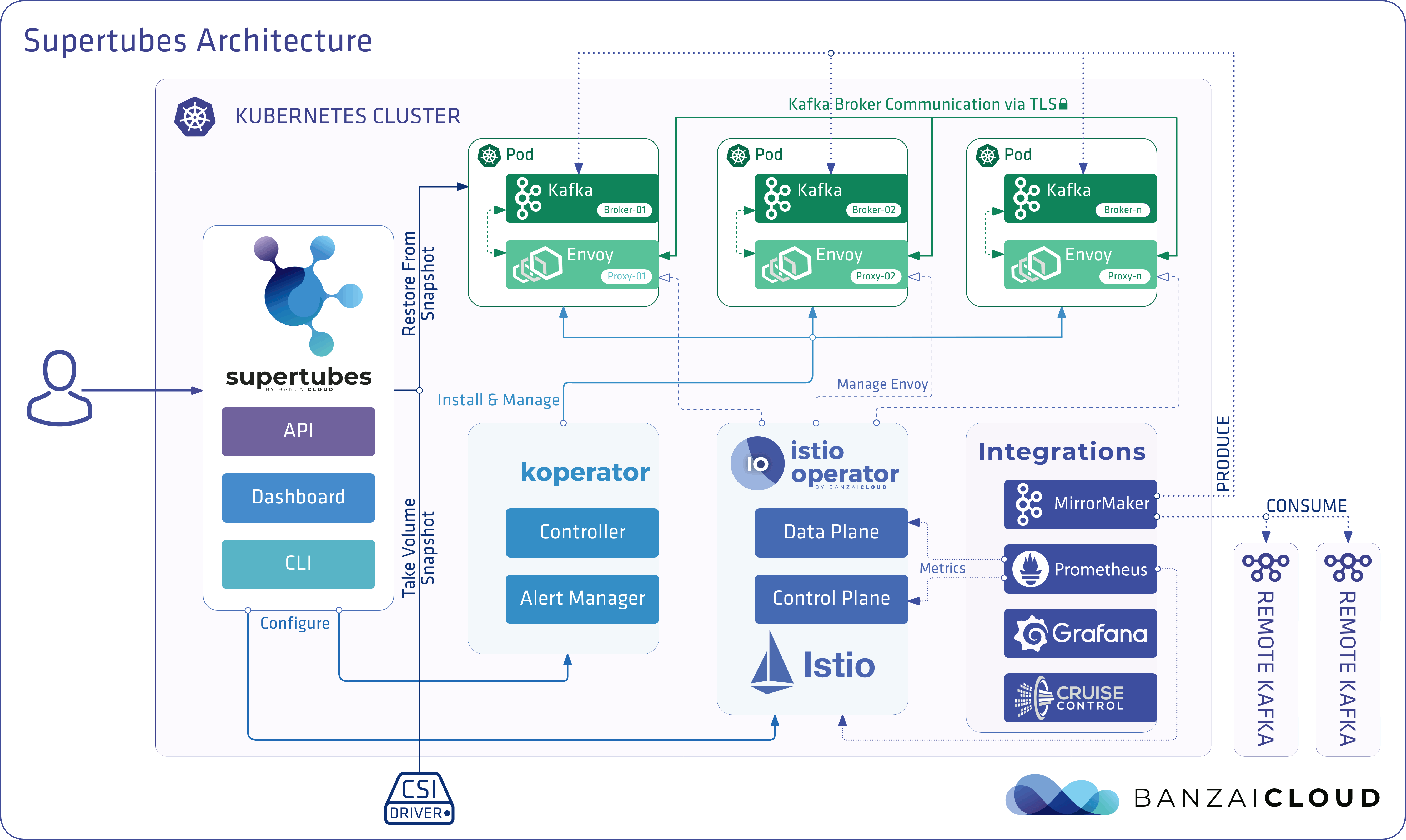
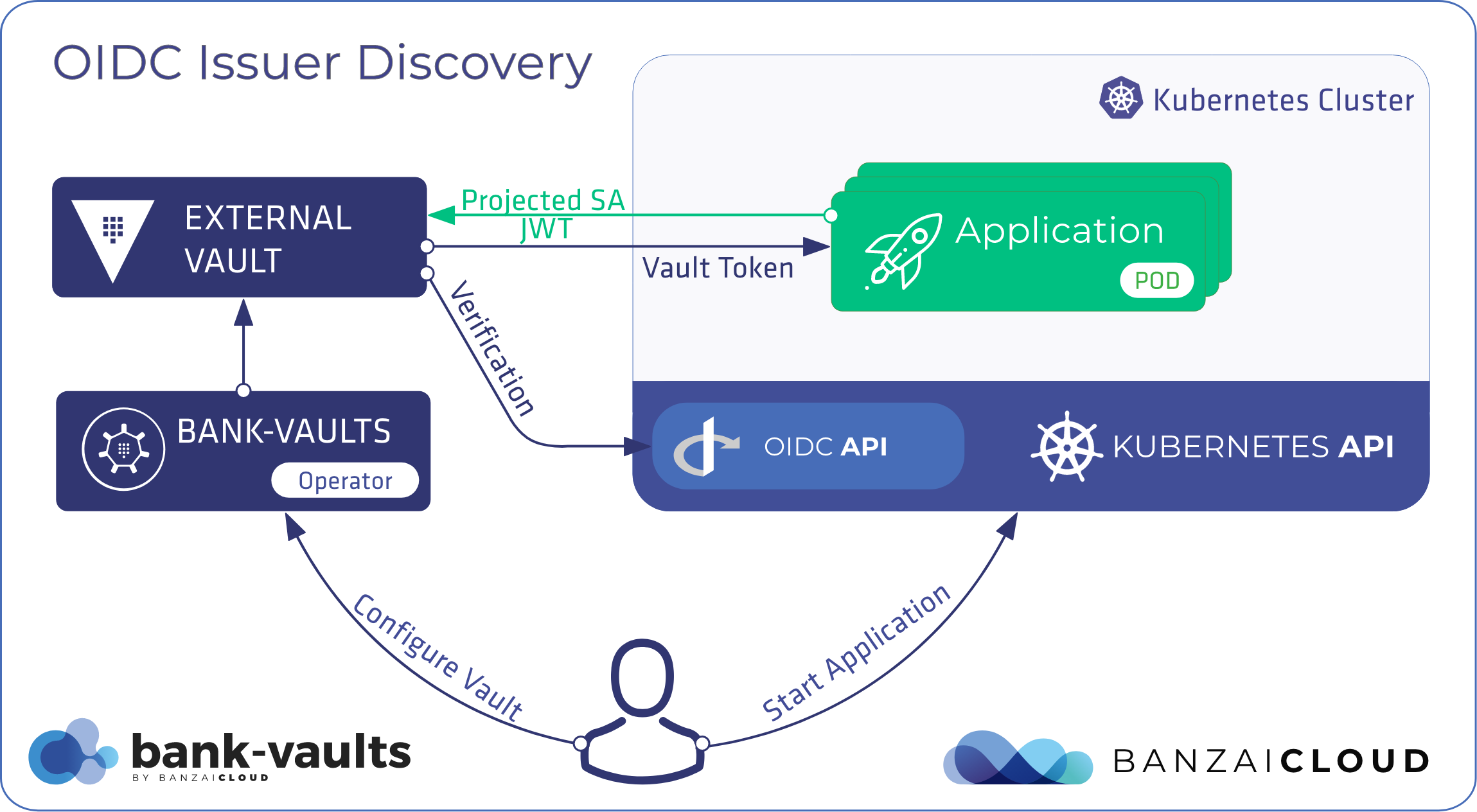
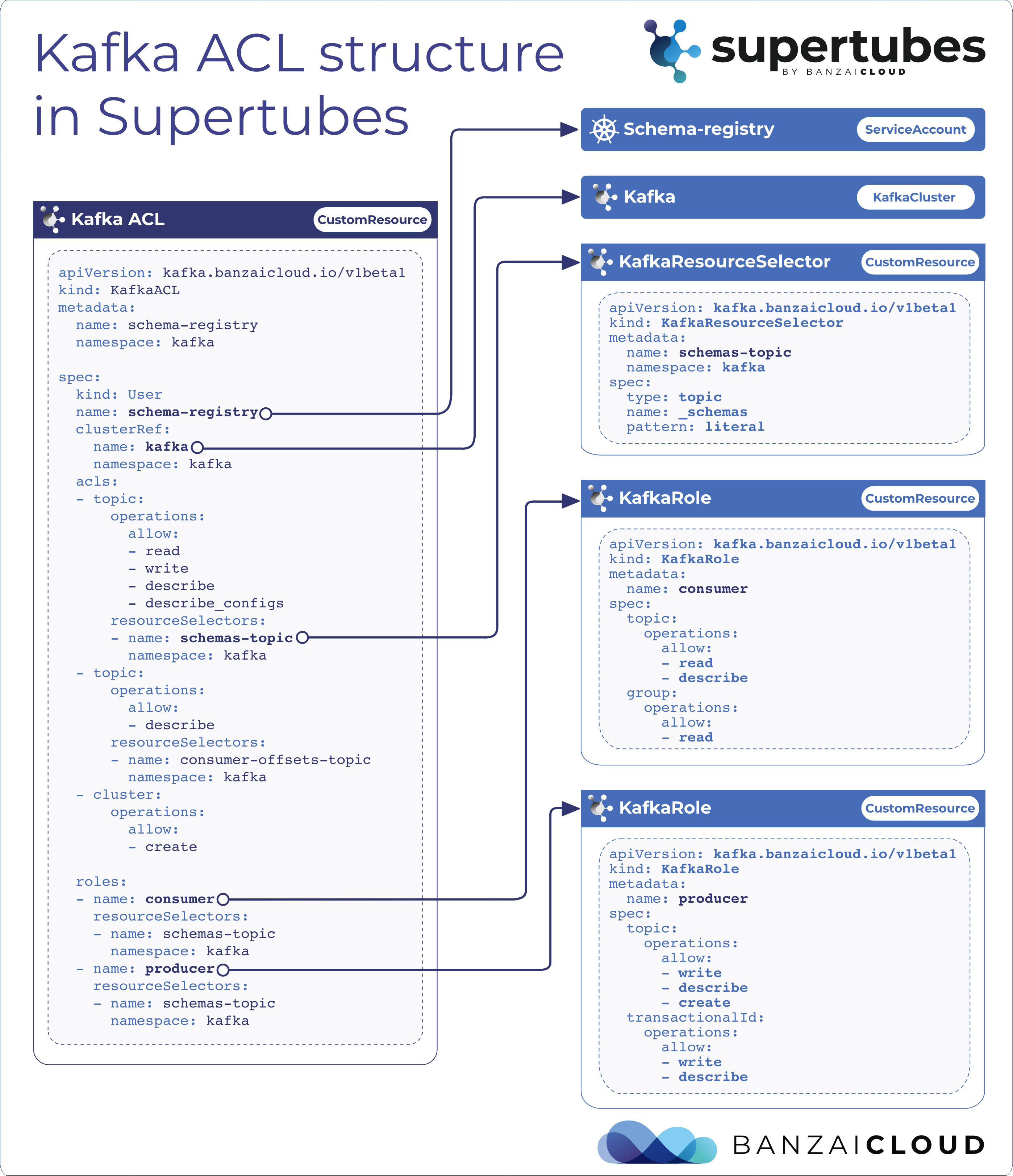
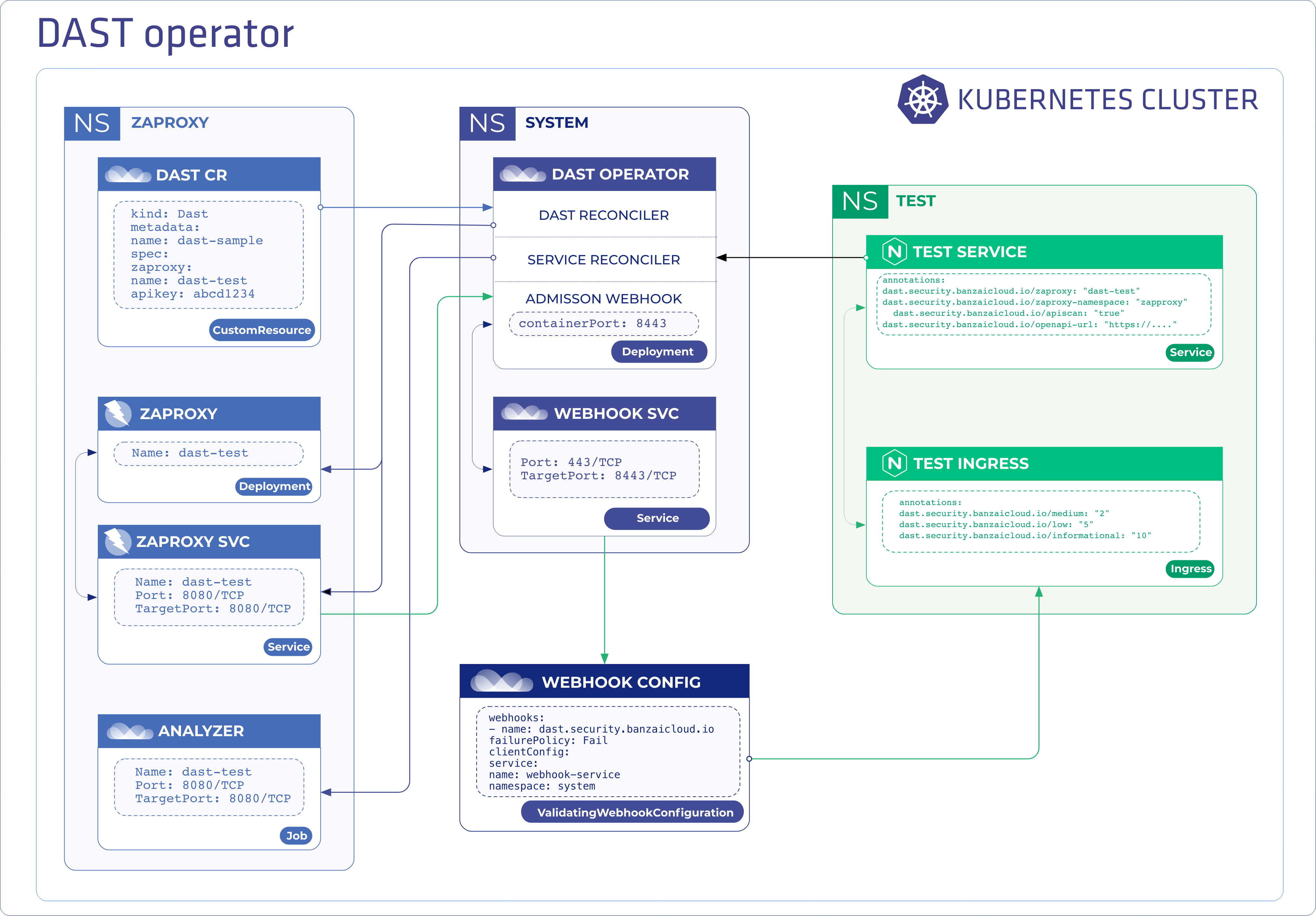
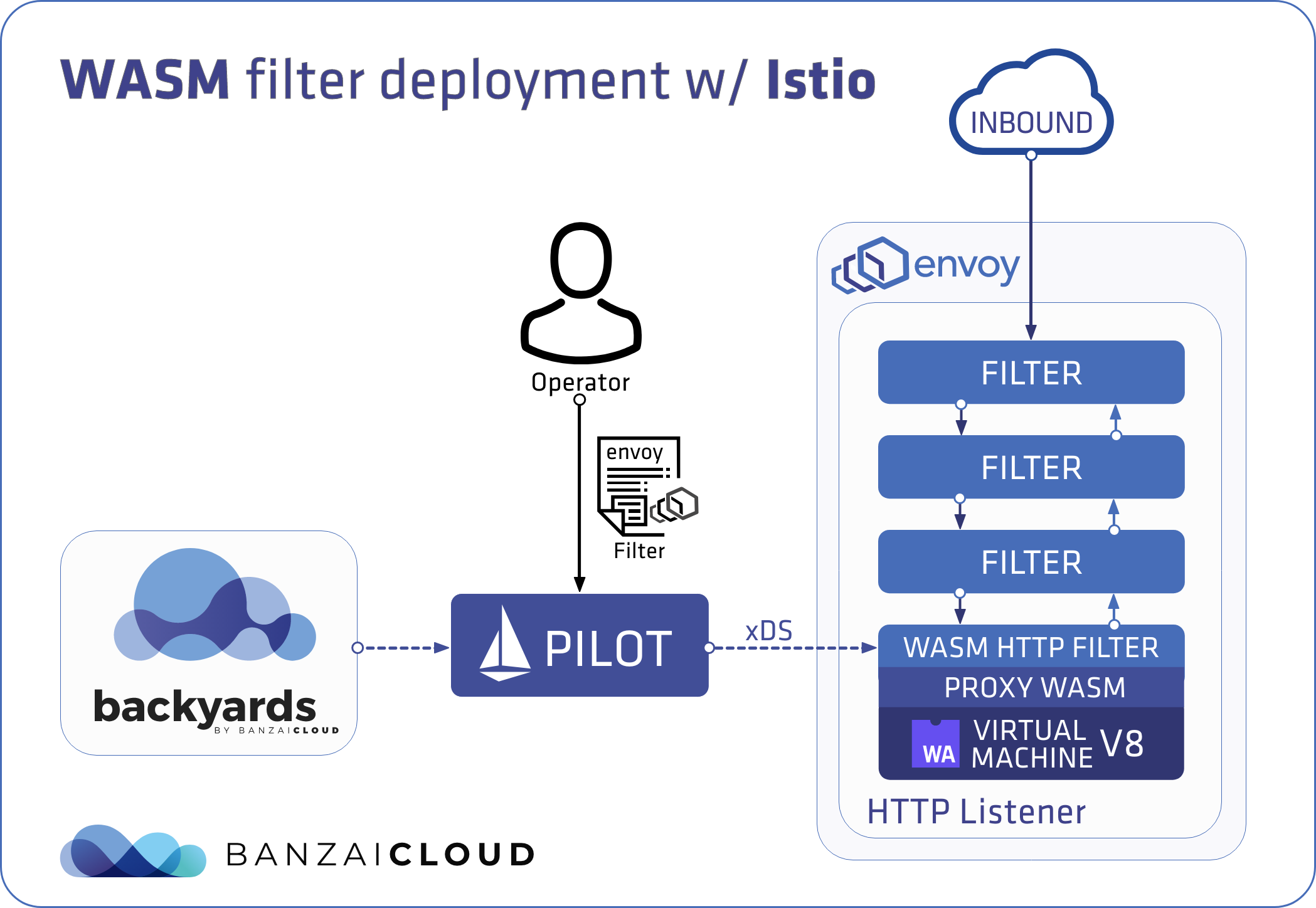
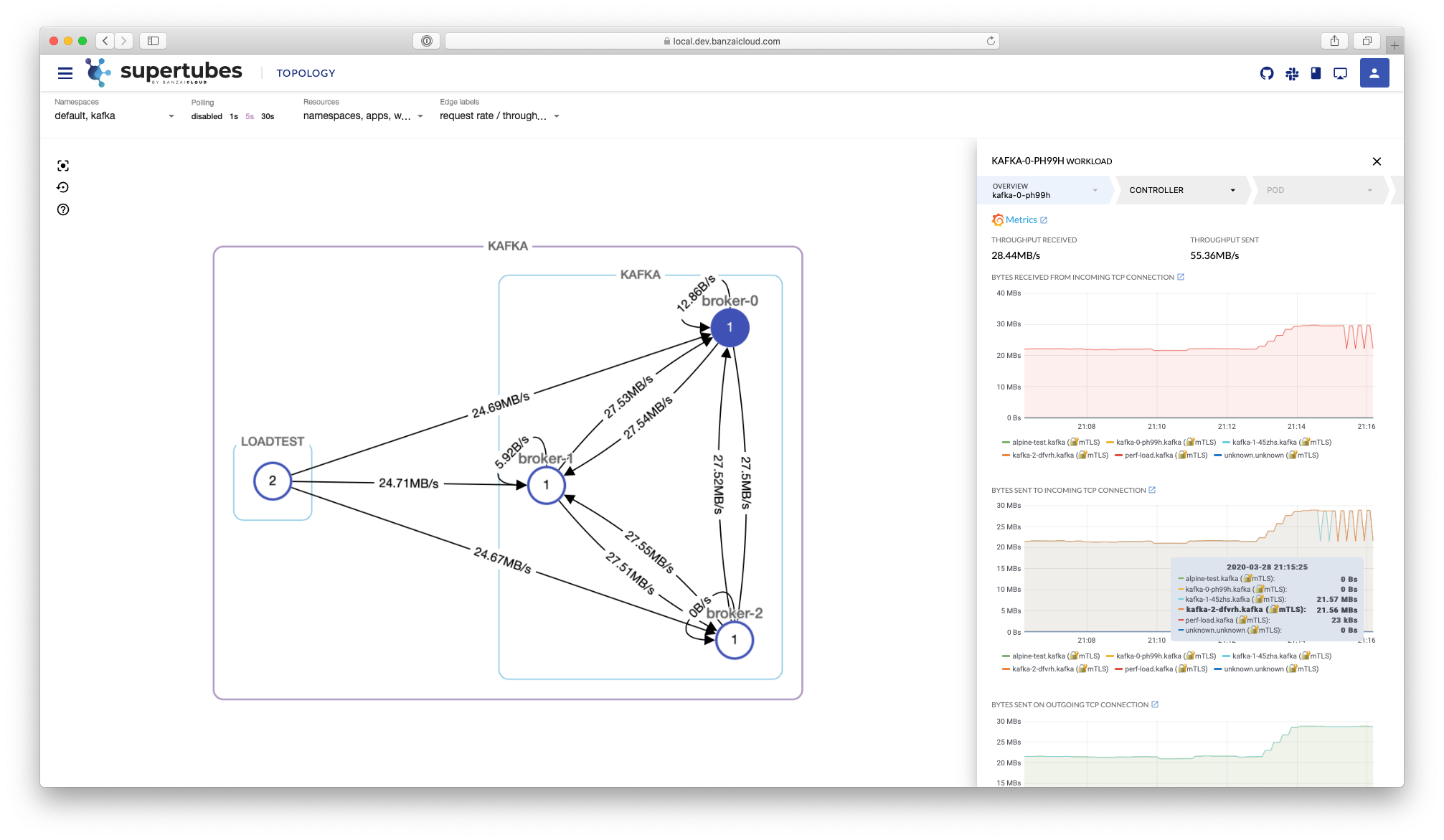
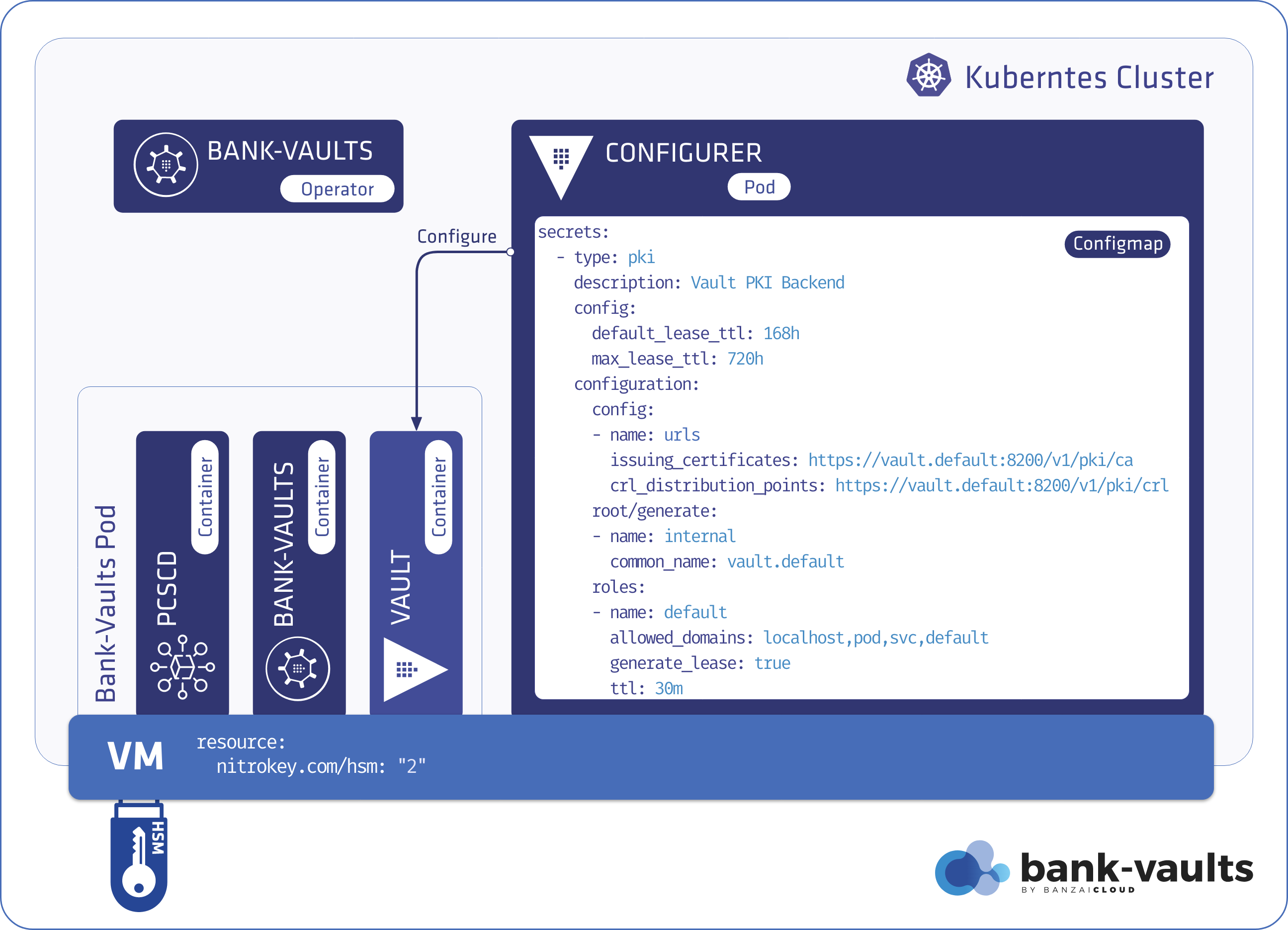
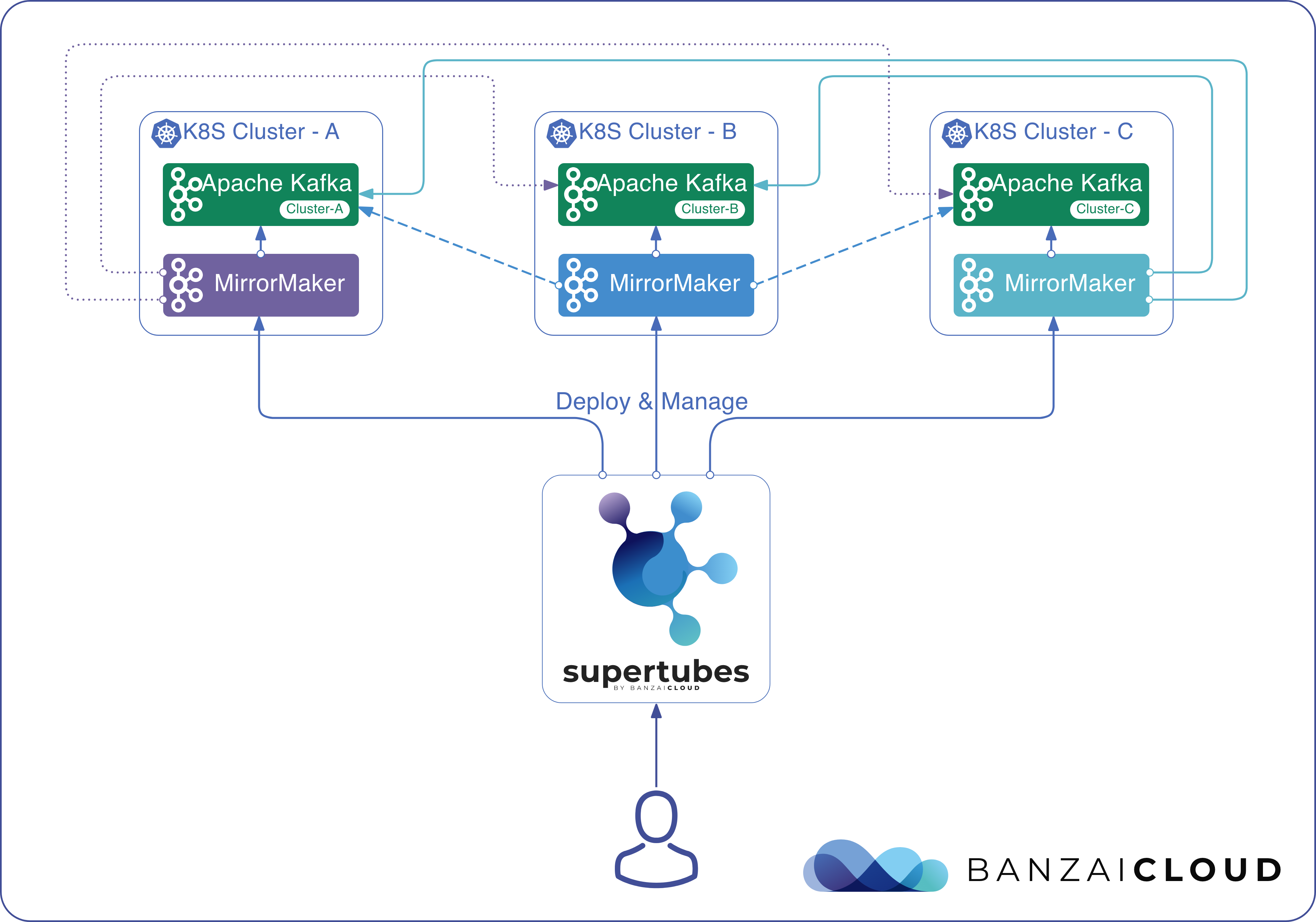
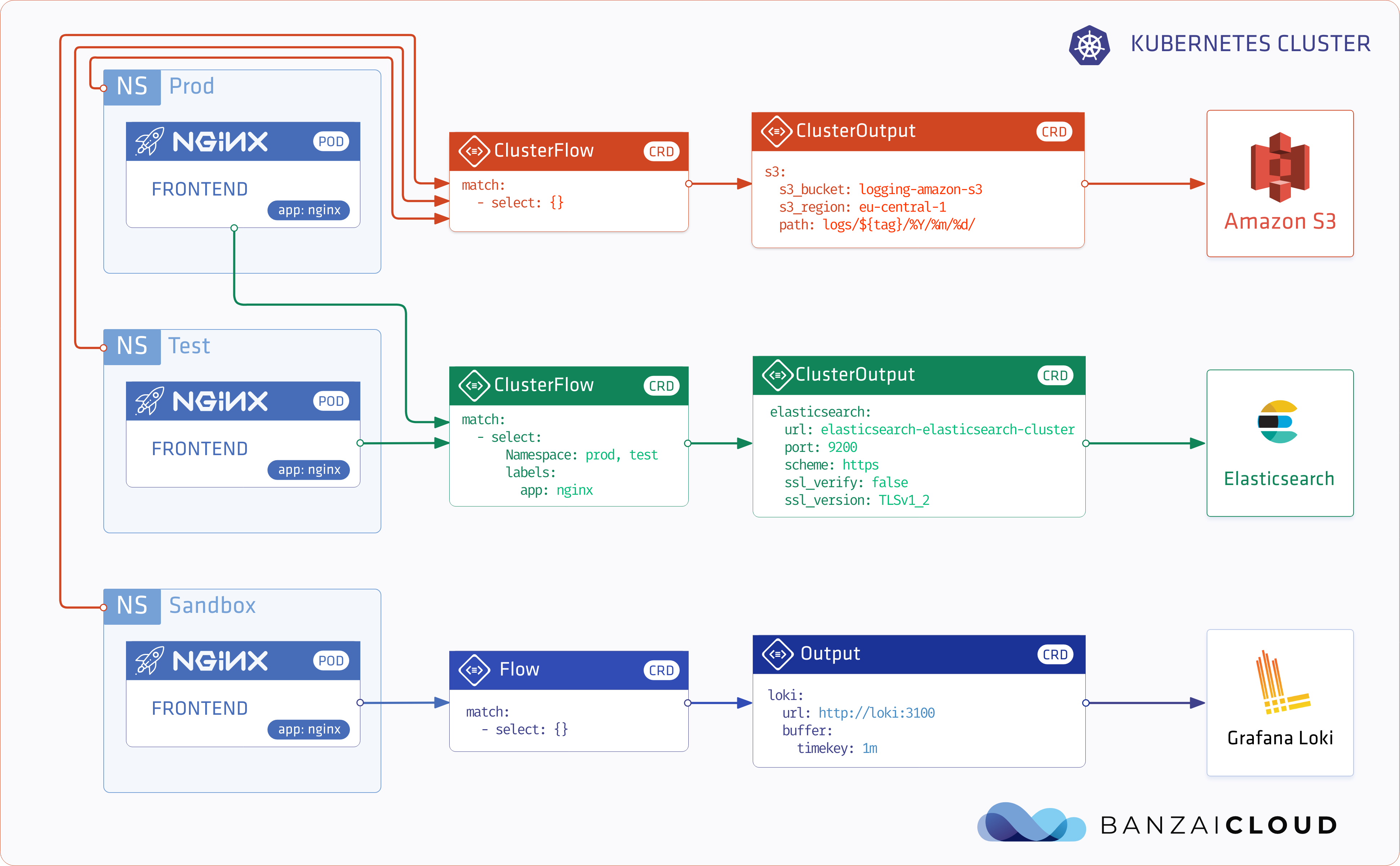
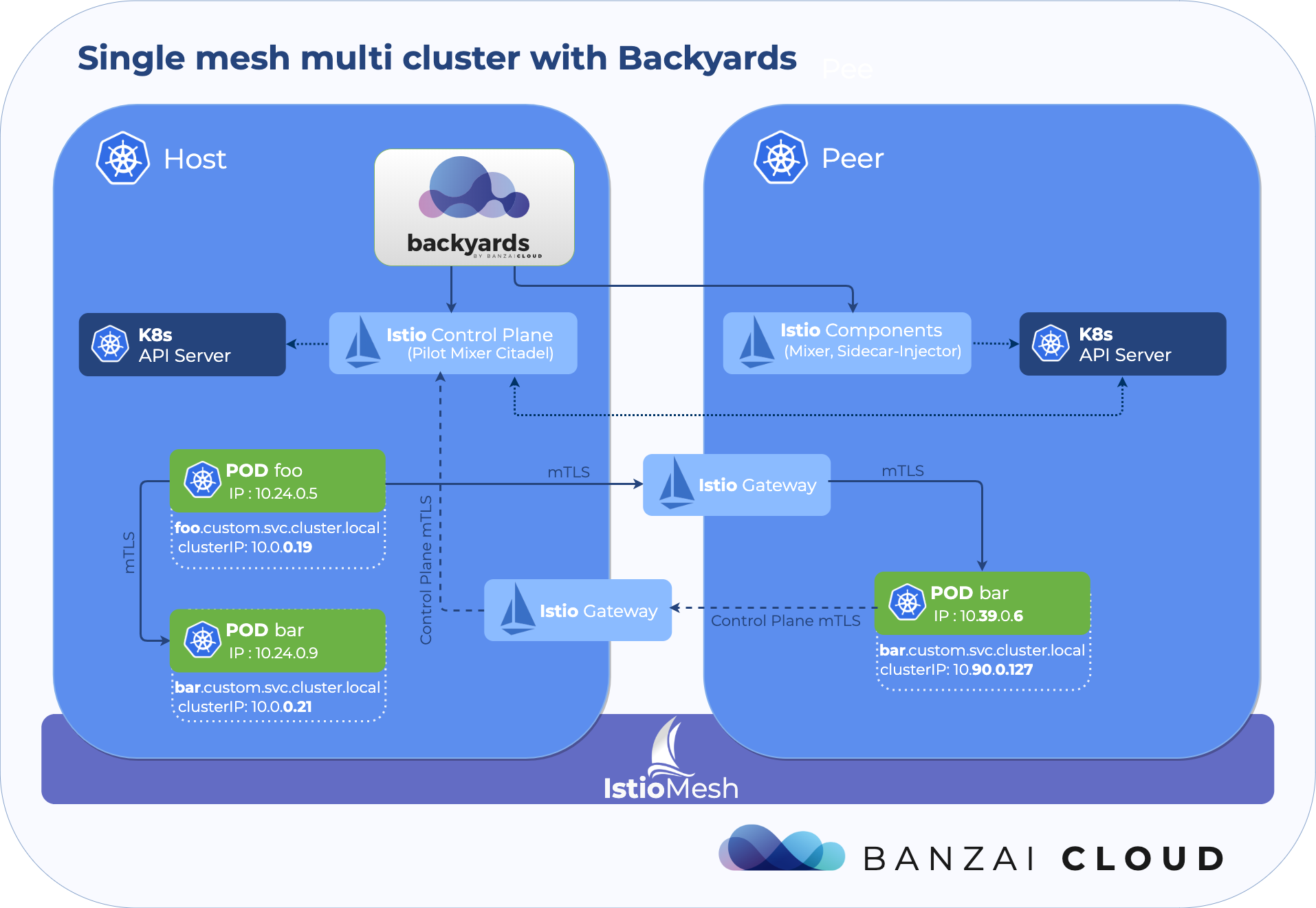
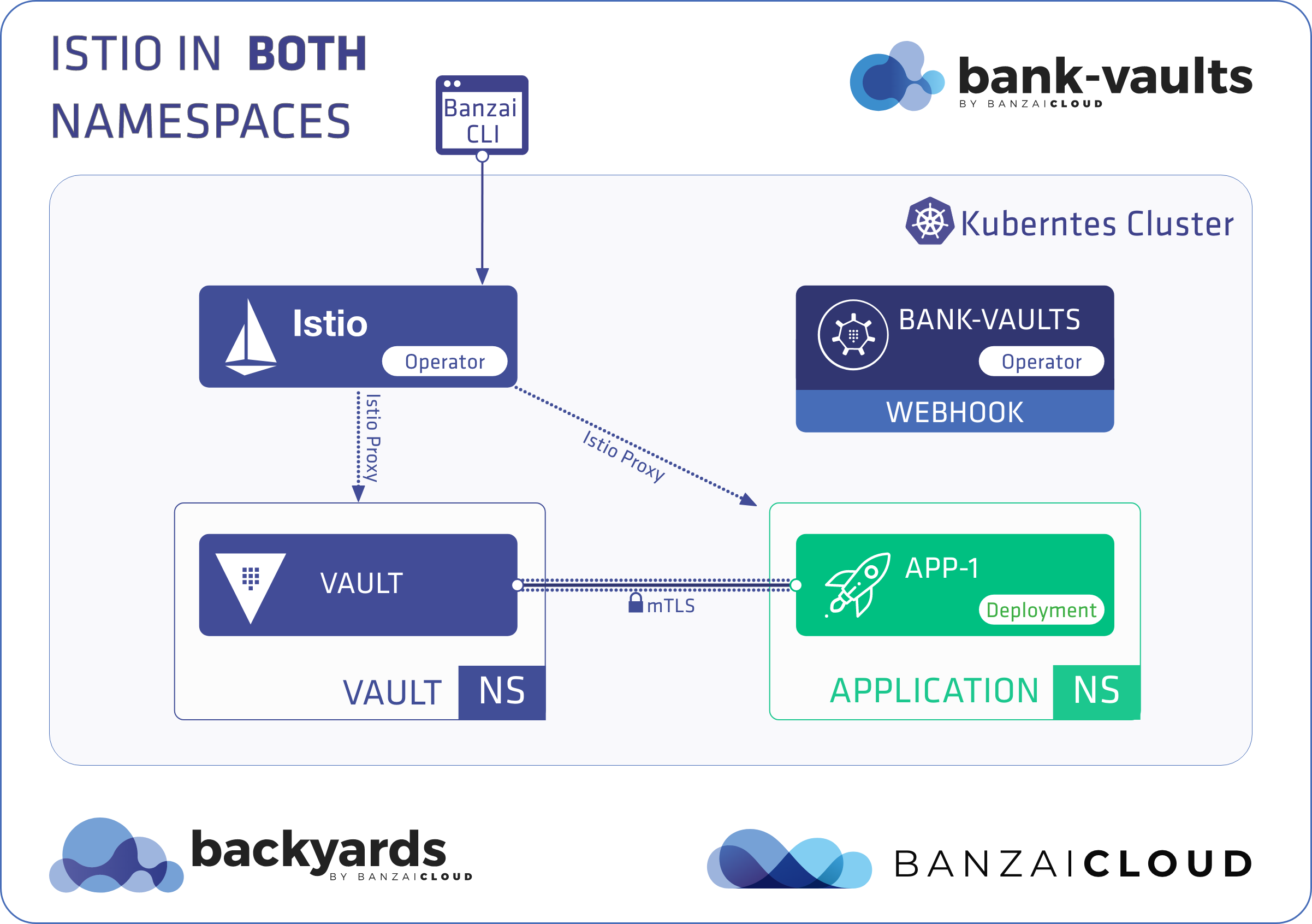
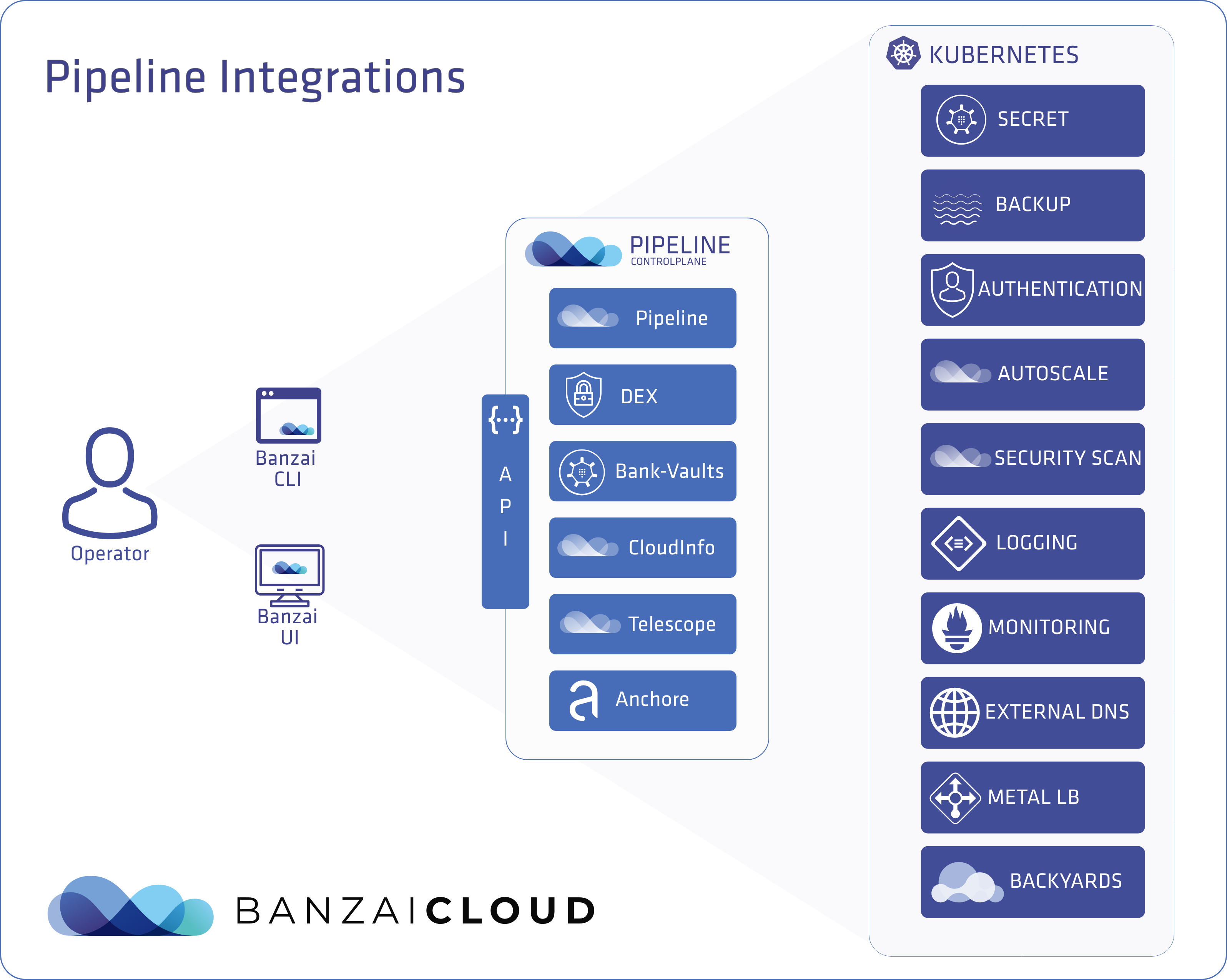
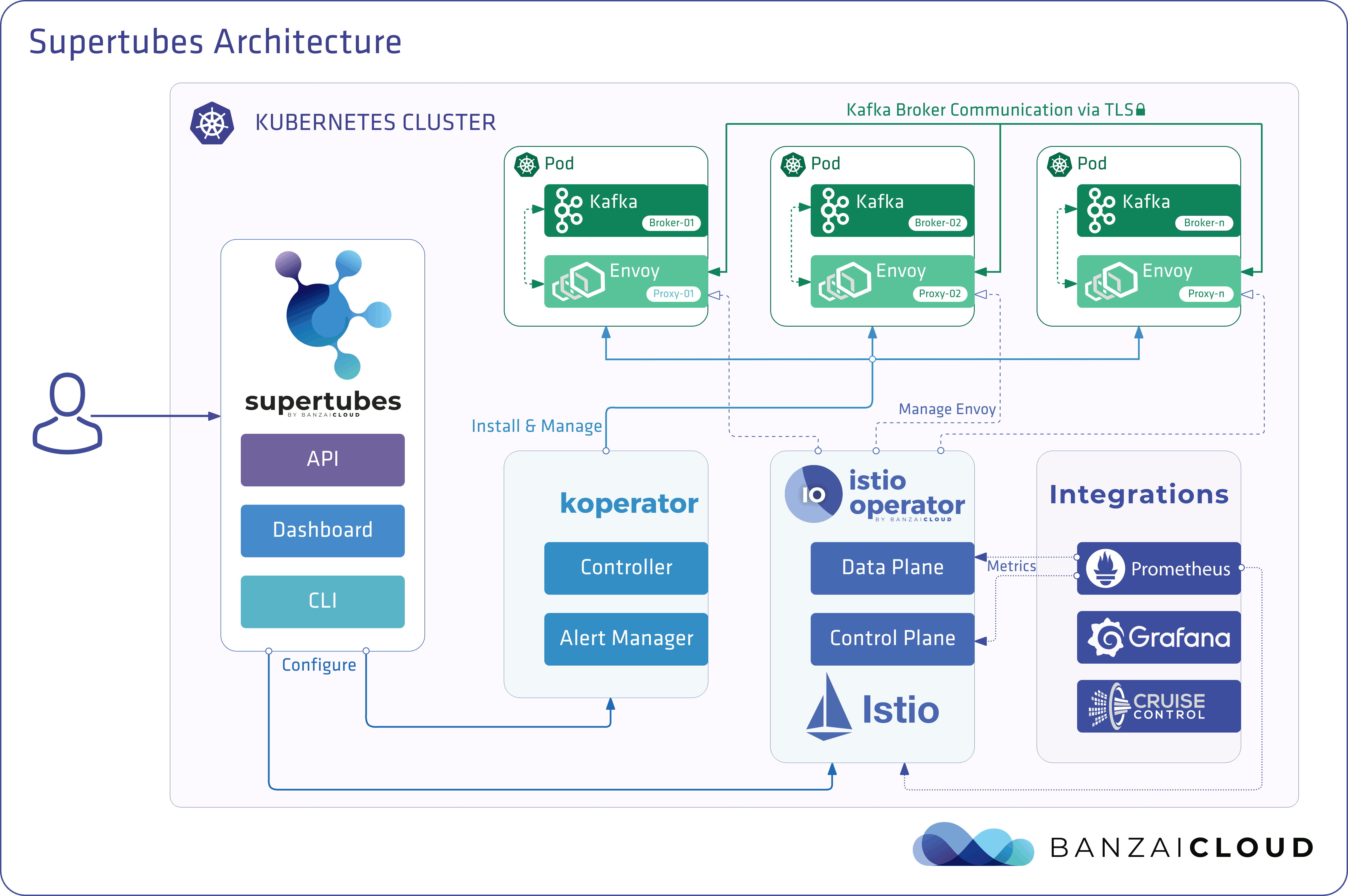
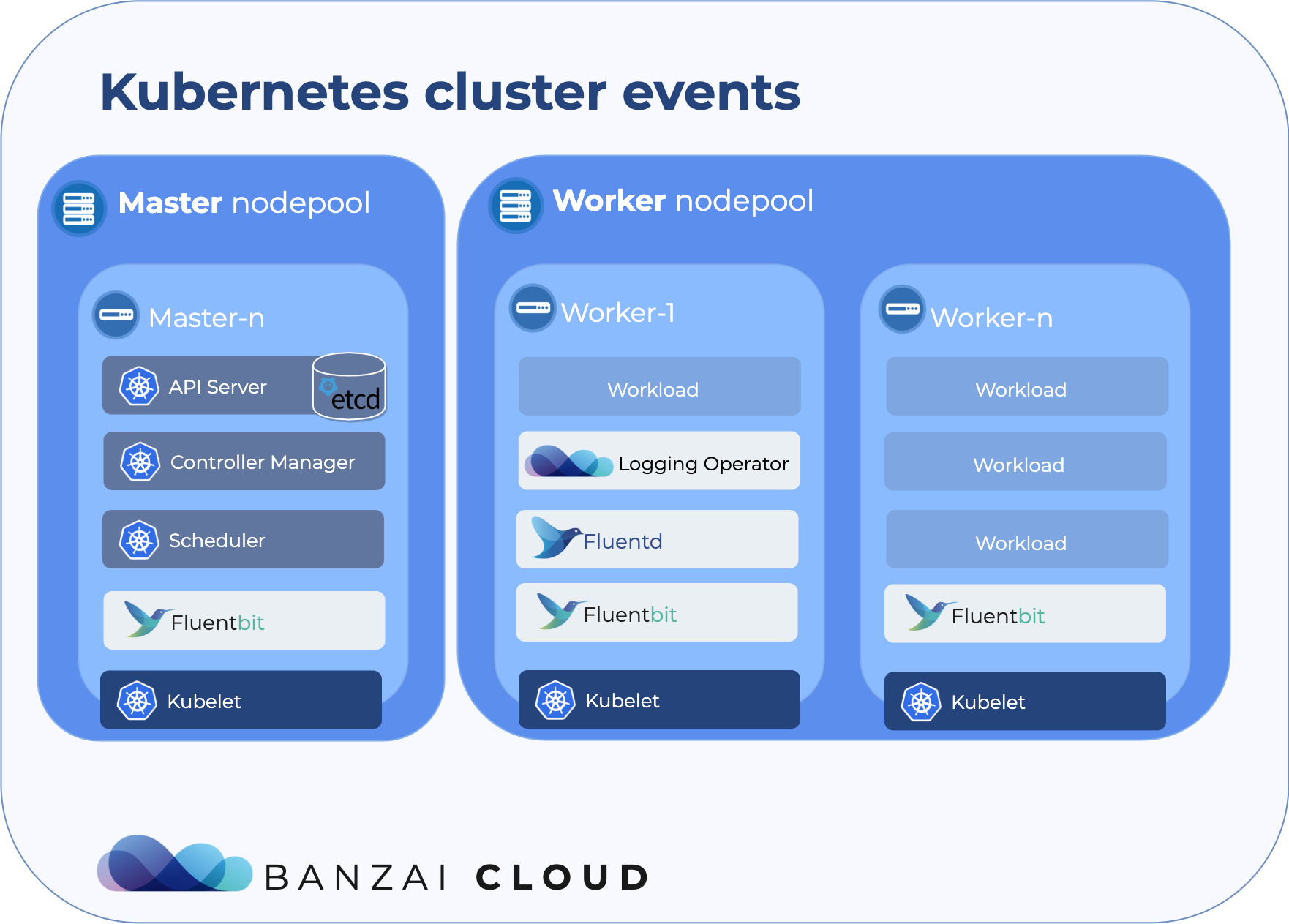
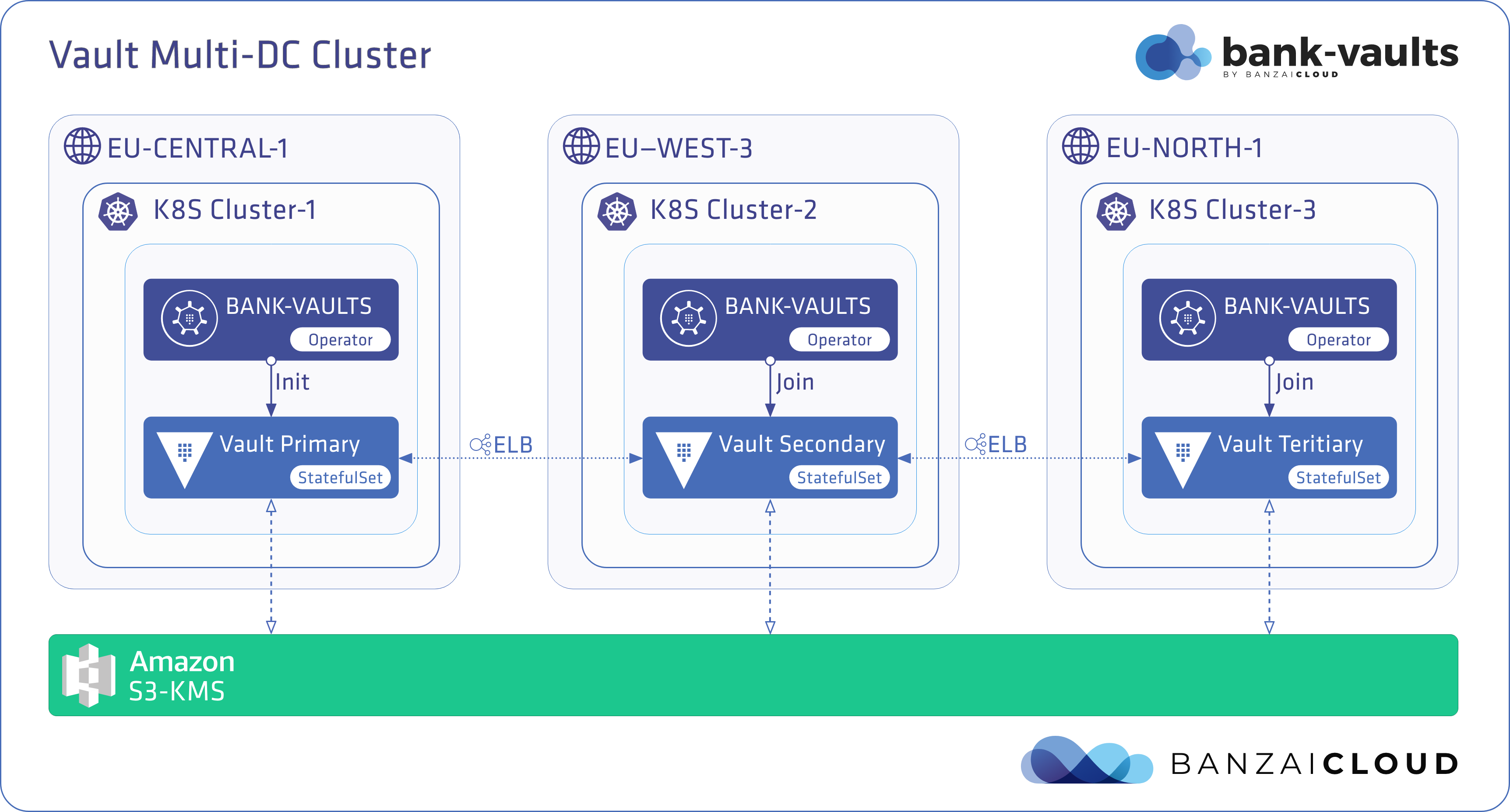
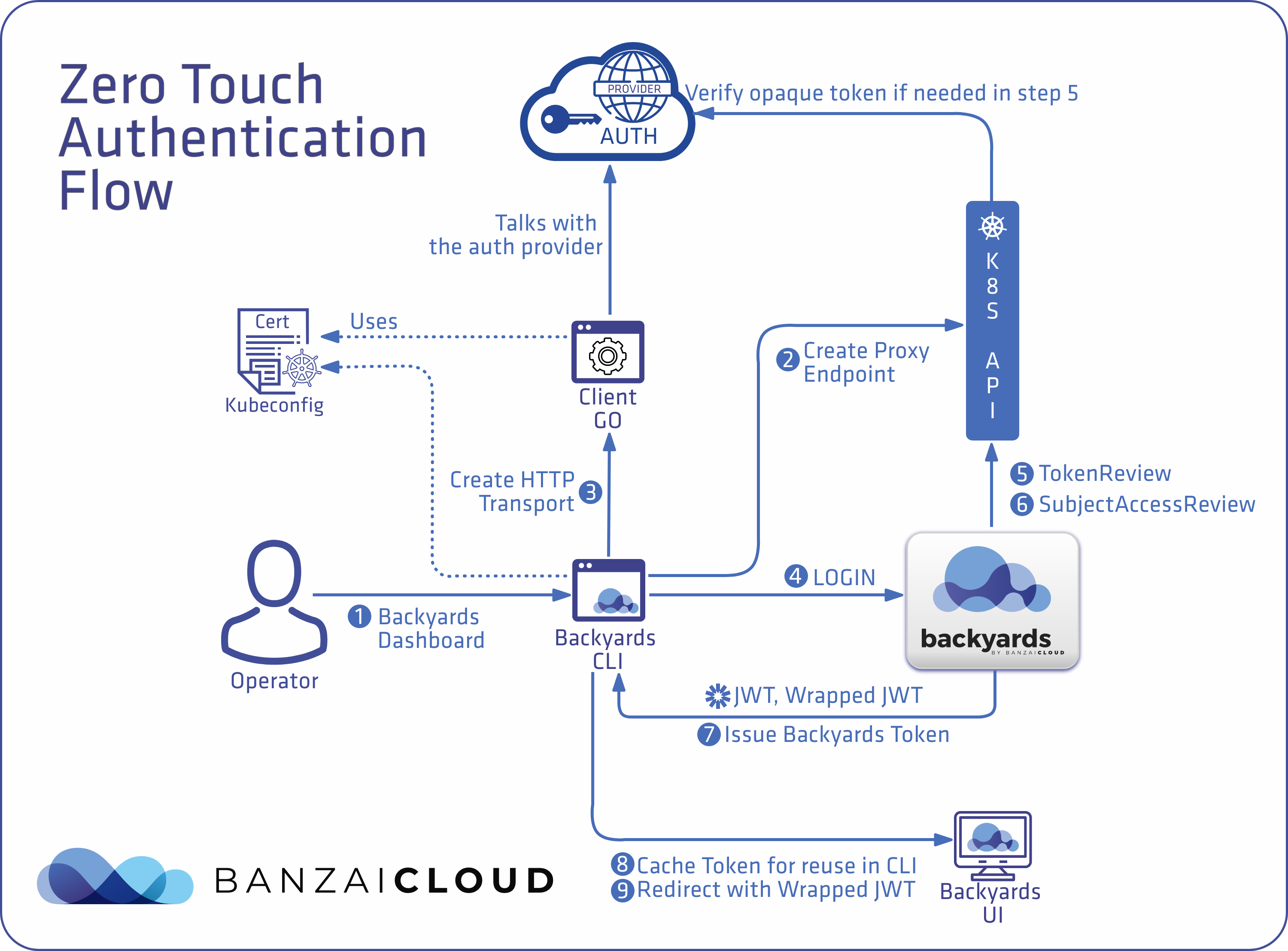
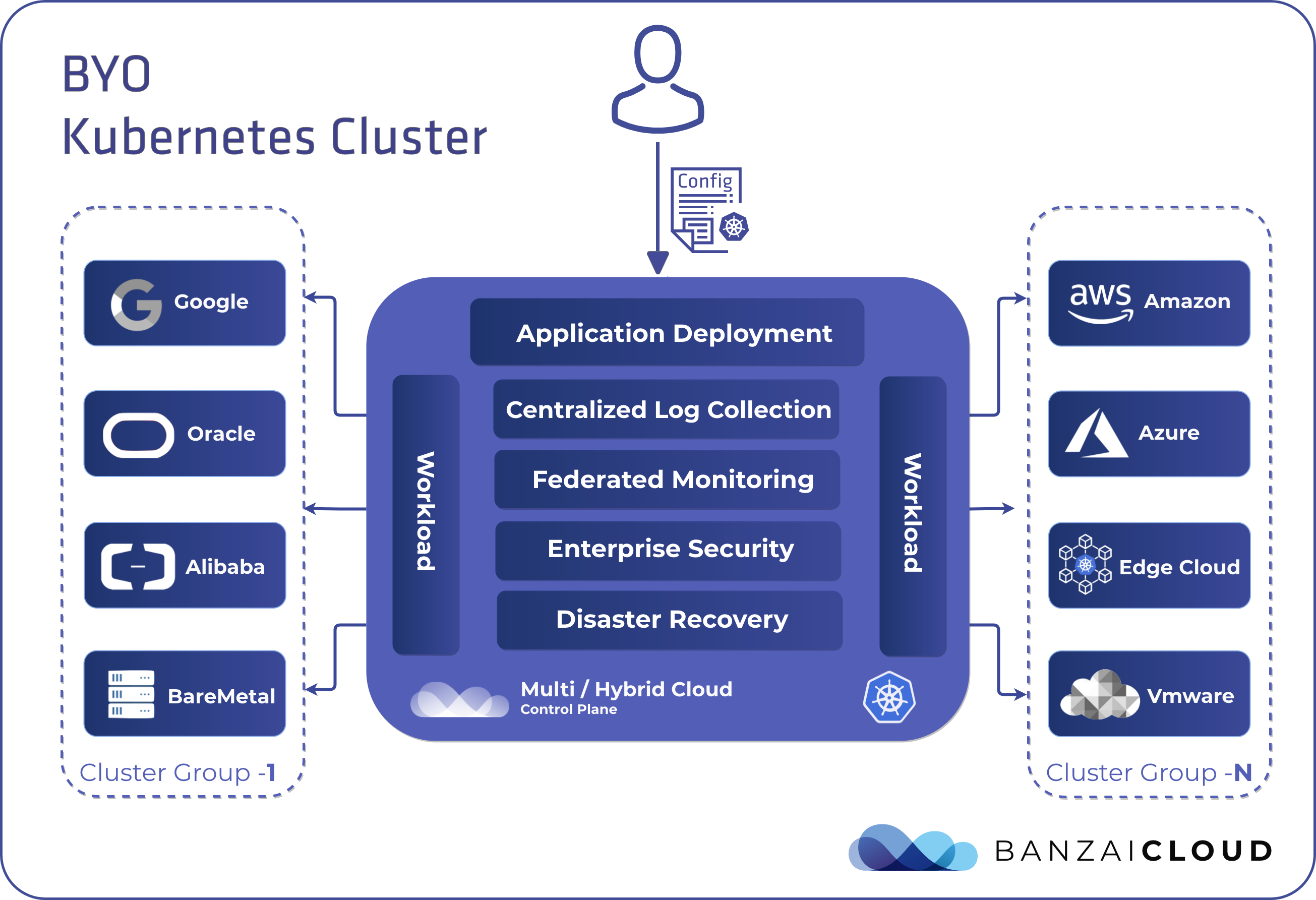
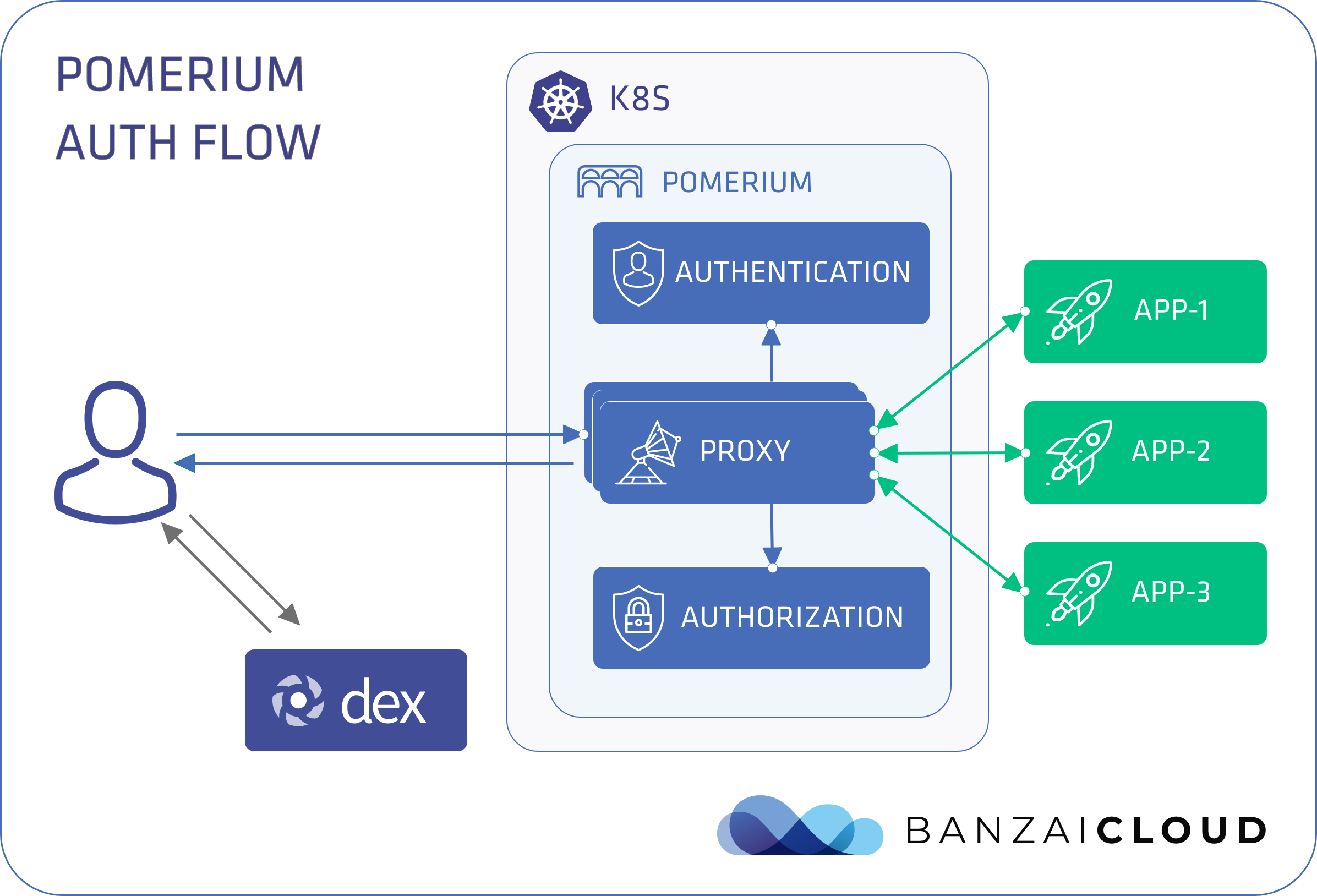
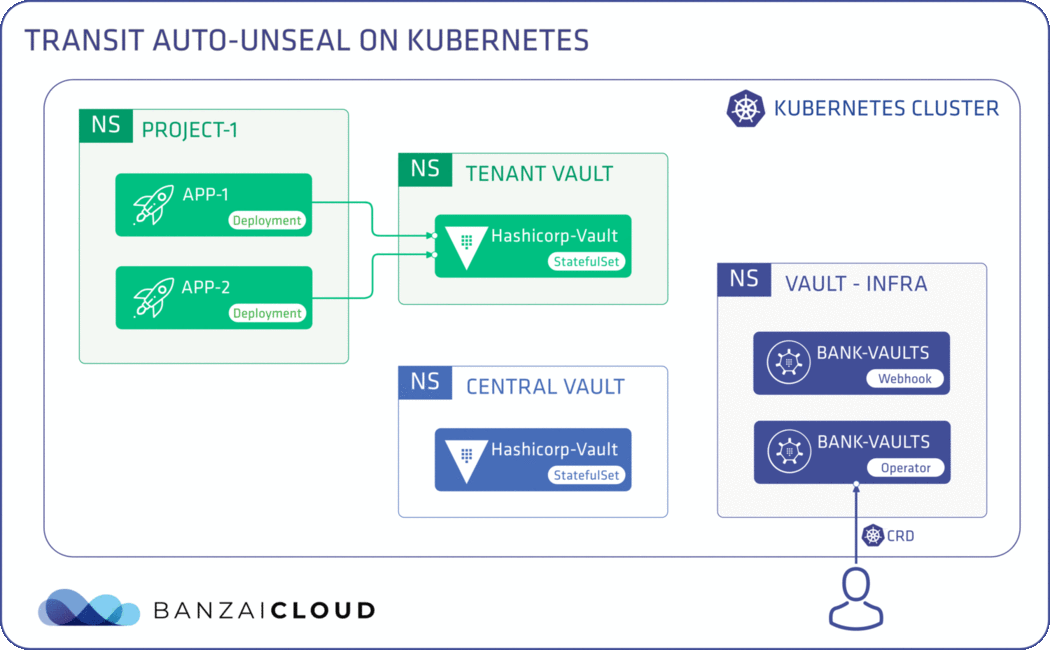
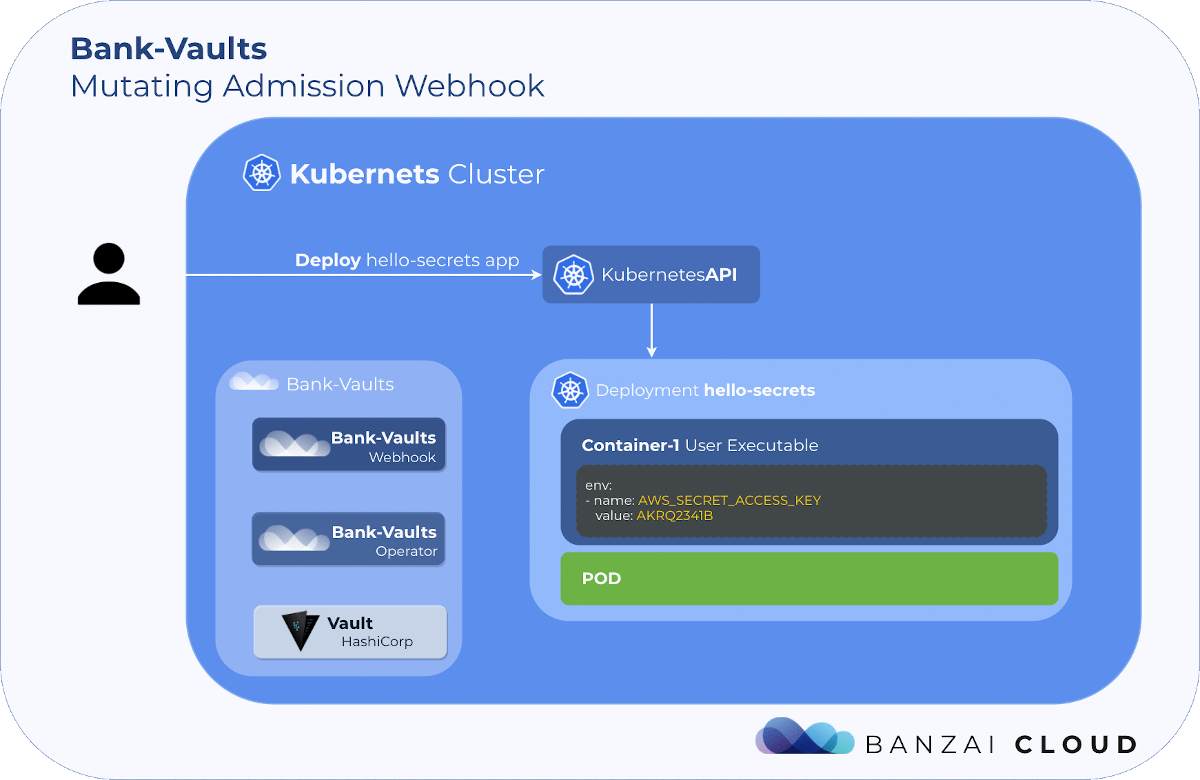
At Banzai Cloud we do a lot more than work on Pipeline, our container management platform, and PKE, our lightweight CNCF certified Kubernetes distribution. In fact, we’re currently developing a variety of services that run on Kubernetes. These range from operators (Istio, Vault, Kafka, Logging, HPA to name a few), webhooks, K8s and cloud controllers to more general applications that we develop and test each day. During the development phase for these projects, we usually need to experiment and rapidly iterate applications, but, when using Kubernetes, this isn’t as easy as running each application inside a container.
READ ARTICLE


Wed, Aug 21, 2019