Cloud cost management series:
Overspending in the cloud
Managing spot instance clusters on Kubernetes with Hollowtrees
Monitor AWS spot instance terminations
Diversifying AWS auto-scaling groups
Draining Kubernetes nodes
Cluster recommender
Cloud instance type and price information as a service
You may remember the Hollowtrees project we open sourced a few weeks ago: a framework for the management of AWS spot instance clusters, batteries included:
- Hollowtrees, an alert-react based framework that’s part of the Pipeline PaaS, which coordinates monitoring, applies rules and dispatches action chains to plugins using standard CNCF interfaces
- AWS spot instance termination Prometheus exporter
- AWS autoscaling group Prometheus exporter
- AWS Spot Instance recommender
- Kubernetes action plugin to execute k8s operations (e.g. graceful drain, rescheduling)
- AWS autoscaling group plugin to replace instances with better cost or stability characteristics

Last week we introduced a spot instance termination exporter for Prometheus. In this post we’re going to take a deep dive into another core component, the AWS Autoscaling action plugin. The action plugin (and other components) can be used independently of Pipeline or Hollowtrees.
tl;dr 🔗︎
We wanted to use spot instances in our long-running AWS Kubernetes clusters. Accordingly, we needed to find a way to use auto-scaling groups with multiple instance types and different bid prices. In order to accomplish that, we created a project that listens on a gRPC interface, and can be instructed to swap a running instance in an auto-scaling group with another instance with different cost or stability characteristics. This diversifies instance types in a group, and reduces the chances of critical failure occuring in the cluster.
Problems with spot instance clusters 🔗︎
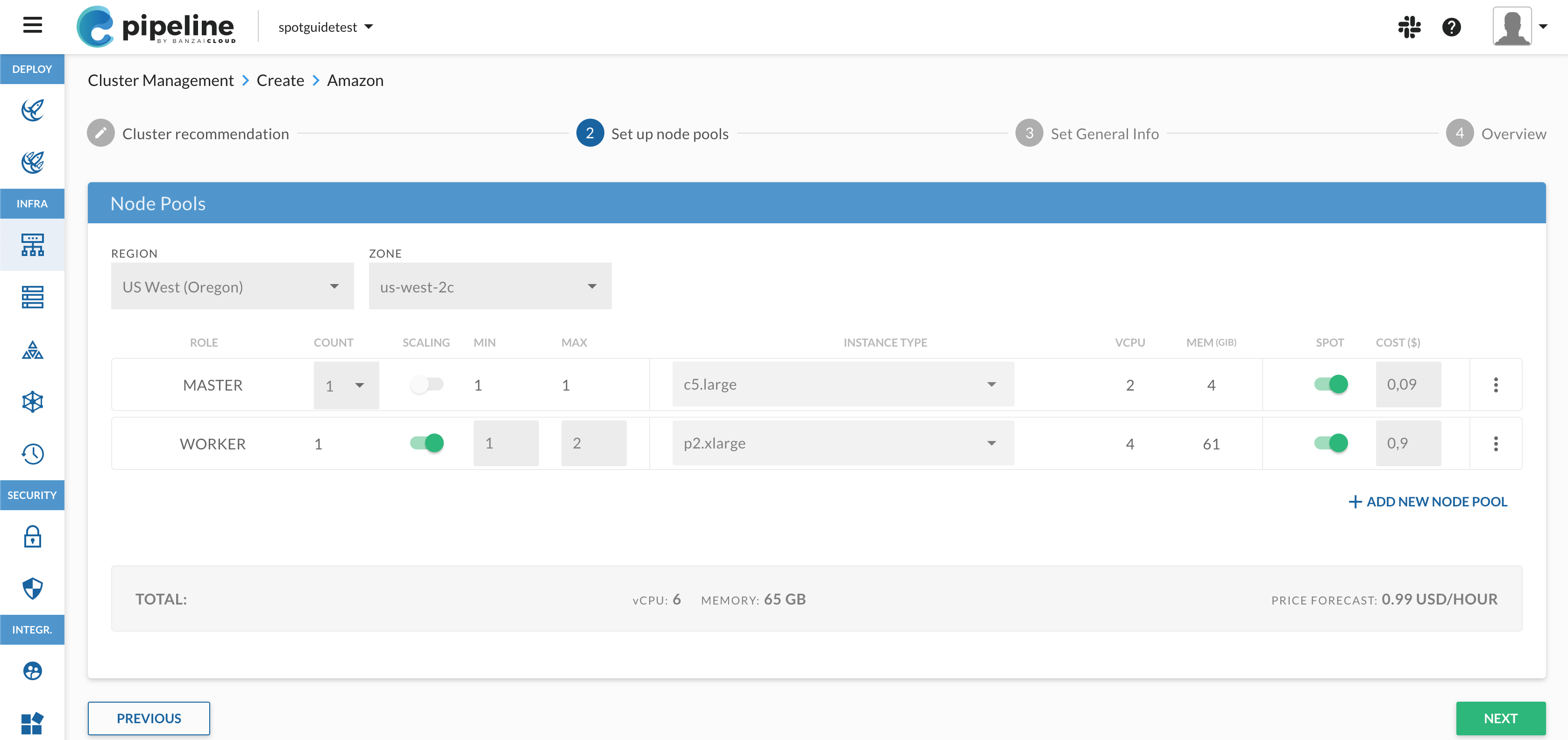
Using spot instances can be useful for fault-tolerant workloads, when it doesn’t matter if (some) instances are taken away. When using spot instances in auto scaling groups, the naive approach is to set instance type and spot price during the launch configuration. But that means that even if your auto-scaling group is spread across availability zones, a very large portion of instances will be running in the same spot market and, therefore, there exists a high probability that such instances would be taken offline when spot pricing surges above the bid price, which would have a critical impact on the cluster. AWS came up with Spot Fleets for that very reason, but a spot fleet is a completely different service with a different API that doesn’t integrate as easily with other AWS services (like ELB).
If you’re not familiar with spot instances, make sure to read our previous blog post first, which recaps the lifecycle of spot instances and describes the different ways of requesting spot instances. Or, for a more in-depth guide, read the corresponding part of the AWS documentation
Swapping instances 🔗︎
AWS auto-scaling groups only use one launch configuration, which describes the instance type and the spot price of all the instances in the group. So if you want to use multiple types you’ll need to use a little trick: the AWS API allows detaching and attaching instances to a group, regardless of its instance type and other configurations. The business logic of this plugin lies in using this trick to swap existing instances in the cluster for different instances. Let’s see the steps laid out in the code:
- Based on incoming event info, the plugin fetches information from the auto-scaling group and its corresponding launch configuration.
- An instance-type recommendation is requested from the Banzai Cloud spot instance recommender through an HTTP API. We’ll write more about this recommender in another blog post soon.
- The original instance is detached from the auto-scaling group.
- Based on the instance-type recommendation, a new spot instance is requested from AWS. The code waits until the instance is started. The launch specifications of the new instance, like the image ID, EBS volumes, SSH keys, etc. are copied from the auto scaling group and its related launch configuration.
- The instance is attached to the auto-scaling group.
- If requested, the detached instance is terminated. Termination is optional. If one spot instance is swapped for another because its termination notice has arrived, that instance will be terminated by AWS after two minutes. It doesn’t make sense to shut the instance down beforehand, because draining scripts may be running during that time.
Hollowtrees action plugin interface 🔗︎
This project is a Hollowtrees action plugin, so its gRPC interface follows the standard Hollowtrees plugin interface. This interface uses an event-based schema, and is described in a simple .proto file in the Hollowtrees repository, here. The interface is very simple, it has only one rpc function wherein the requested payload is an AlertEvent message that follows the structure of current CloudEvents specifications. Routing inside the plugin is done via the EventType of the message.
We’ve implemented a very simple “SDK” for this interface. To use it, the plugin needs only to do two things:
- Implement the
AlertHandlerinterface’sHandlemethod with custom behaviour. In this case, it calls the instance swap mechanism with the payload from the event. - Call the
Serve()function from the SDK via the newAlertHandler. This will start the gRPC server that listens on the configured port.
Try it out 🔗︎
Build and run 🔗︎
To keep things simple, building the project is as simple as running a go build command. The result is a statically linked executable binary.
go build .
The following options can be configured while starting the binary. Configuration is done through a plugin-config.toml file that can be placed in the ./conf/ directory or near the binary.
Notes:
- Currently, the application can only interact with one AWS region, so, if you’d like to use it for multiple regions, you’ll need to run an instance of the application in each one.
- The project uses the default AWS go [client](https://github.com/aws/aws-sdk-go, and access credentials are configured through the default client. That means that
instance profileconfiguration files in the home directory (~/.aws/credentials) as well as environment variables can be used.
[log]
format = "text"
level = "debug"
[plugin]
port = "8888"
region = "eu-west-1"
Running the project is as easy as running the executable binary from the build.
Deploy it to a Kubernetes cluster 🔗︎
At Banzai Cloud we run all our deployments inside Kubernetes. We use a standard Helm package manager, but all our deployments use Pipeline - we’ve previously made Helm deployments available over a RESTful API, as well. The charts are available as part of our GitHub charts repository.
Install the exporter’s chart with the release name aws-asg-action-plugin, like so:
$ helm install --name aws-asg-action-plugin banzaicloud-incubator/ht-aws-asg-action-plugin
The helm chart will deploy a configmap for the configuration file, a pod for the action plugin, and a service to reach the gRPC interface.
Test it 🔗︎
To test the plugin, you’ll need to write a client that calls the gRPC interface, or use the Hollowtrees engine and configure some rules that govern when to swap an instance. Or, if you just want to play around, use a tool like grpcc to connect to the plugin and send a few basic events.
Future plans 🔗︎
We consider this plugin to be in an early alpha version. There are important things missing, like security on the gRPC interface, things to improve, like the recommendation engine that’s called to discern new instance-types and bid prices, and new features that will keep the auto-scaling group in a stable state, like cooldown periods, or that keep a percentage of the cluster on on-demand instances.