






One of the main goals of the Banzai Cloud Pipeline platform and PKE Kubernetes distribution is to radically simplify the whole Kubernetes experience and execute complex operations on behalf of the users. These operations communicate with a number of different remote services (from cloud providers to on-prem virtualization or storage providers) where we have little or no way to influence the result of these calls: how long will it take, will it ever succeed, whether it provides the desired result and so. While we were building the Pipeline codebase we had already implemented some quite robust recovery logics (built on a provider by provider basis) and we needed a way to unify them and make a more reliable approach. Business as usual for Pipeline, we needed a solution which can be easily monitored and observed even though running in a highly distributed environment.
We have different technical backgrounds and have been working with different long-running workflow engines but most of these were not really fitting into the cloud native mantra—but more importantly they were not made in our preferred programming language, Golang (we like to move fast, and choose frameworks where we can quickly learn the codebase and contribute back fixes and features). Finally, we were looking for a solution that was as simple as possible, yet, at the same time, could give us the tools to gradually make our operations more robust.
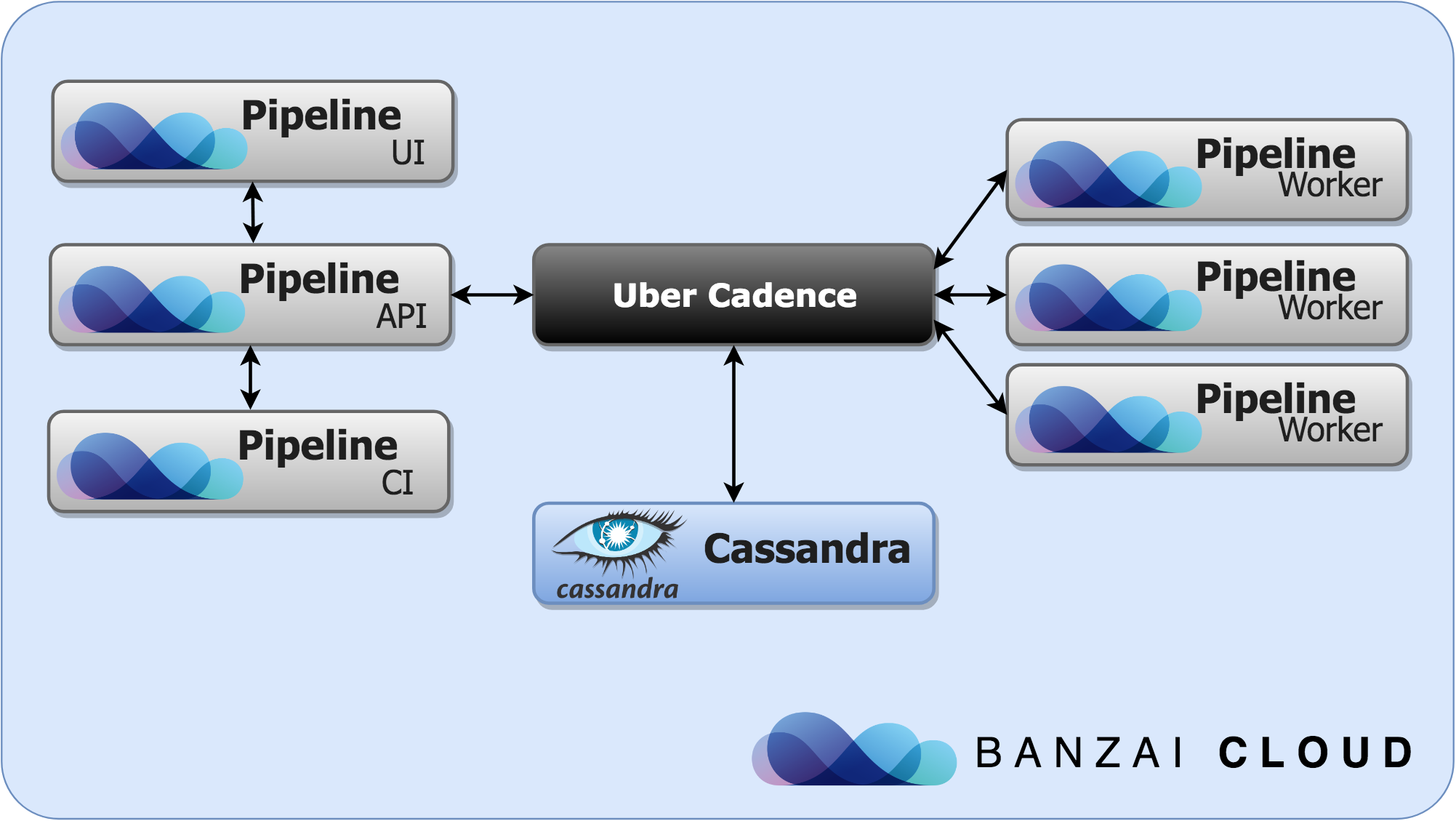
The Uber Engineering team’s excellent Cadence framework comes with the simplicity inherent in modern task queues and with the power and expressiveness of mature workflow engines, but simultaneously allows Go developers to keep using their comfortable programming language for defining workflows. This makes migrating plain application code much easier, and allows using the same code base and development environment.
Introduction to Cadence 🔗︎
So what is Cadence? Cadence is a distributed, scalable, durable, and highly available orchestration engine developed at Uber Engineering to execute asynchronous long-running business logic in a scalable and resilient way.
There is a wide variety of different task queues on the market (I’m not kidding you can check them out for yourself at taskqueues.com), so what is it that makes Cadence exceptional? What makes it more than a sophisticated distributed task queue manager? For one thing, you can define workflows in code and let Cadence handle state, timeouts, history and all the other little necessities. Then, those workflows can be inspected after submission, so you can check their progress and results, or send them external signals as needed.
The best part in using Cadence is the powerful SDK that accommodates all our needs in handling and defining workflows.
Cadence Architecture 🔗︎
To understand how it works let’s examine the internal components of Cadence.
Cadence’s entry point is its Frontend Service, which routes the requests of clients and workers to the History and Matching services. Workflow metadata, statuses, progress updates, and results can be queried—and some administrative resources, like workflow domains, can be managed—from there.
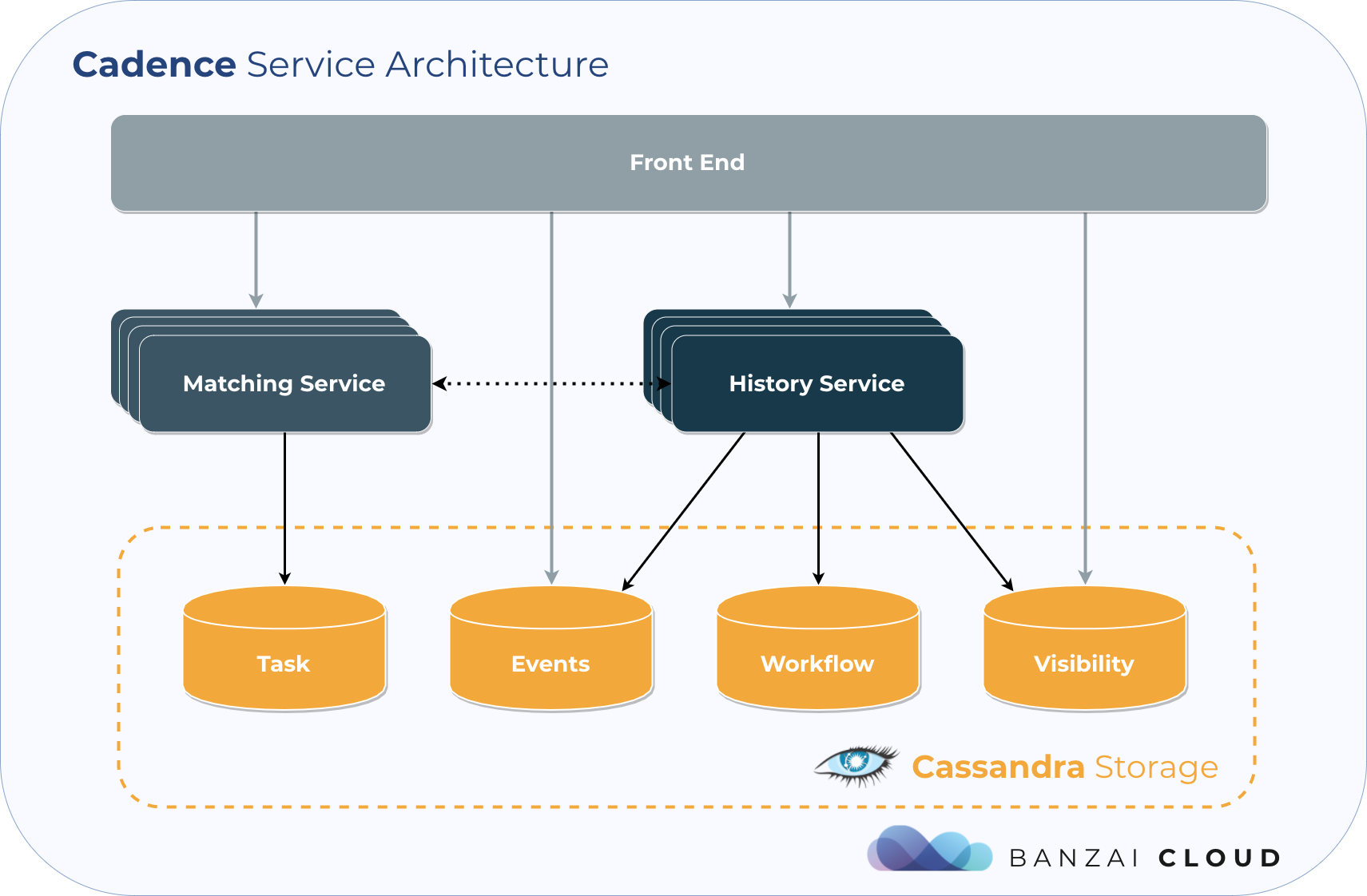
The Matching service is responsible for dispatching tasks. It guarantees the at-most-once semantics, which means that every activity of a workflow is either executed exactly once, or (in case of failures) not at all. The History service is where the magic happens. It manages queues, handles events, stores and mutates workflow states.
The code what you will have to write:
- workers that define workflows and do the actual task of executing activities,
- code to submit requests for workflow execution, and
- optionally check the workflow progress or results.
If you would like a deeper understanding of Cadence architecture and to learn about how it scales, you should take a look at this recording of a meetup on the topic.
One of the most obvious perks of this setup is that you can easily scale your worker pods, independently from your application acting as a Cadence client (for instance, web application backends that submit workflows). Moreover you can scale each Cadence service independently as well.
Moving your code into Cadence 🔗︎
The unit of work that you can execute with a Cadence client is the Workflow . This is basically a Go function, which describes the main flow, precedence, branching, or, for example, iterations of actions. However there are some rules that you have to follow to get a correct and reliable behavior.
Unlike Activities—the reusable building blocks of Workflows—which are guaranteed to run at most once, Workflow code is re-executed multiple times. While you have the freedom to organize your workflow code the way you prefer, and can safely use the control structures and pure functions (i.e. those which have no side-effects) of Go, it is essential to make sure your workflows are deterministic. To accomplish this, you should use special functions provided by Cadence, instead of constructs with side-effects or which are dependent on some external state, like a database, entropy source or wall-clock time. We prefer to reposition most variables as workflow parameters, in lieu of querying them during execution.
Don’t forget, no such restrictions exist for Activities, which can use arbitrary Go constructs appropriate in programs that run for longer periods of time. Of course, you should not leak resources or launch unattended Go routines in your code. On the other hand, you will have to handle failures and re-executions of Activities in your own Workflow code, which is often easier with idempotent activities.
Using Cadence is as easy as writing Golang code. The following examples illustrate how built-in Golang structures and functions translate into Cadence library calls:
Execution of activities in a Cadence workflow 🔗︎
// Synchronous activity execution
workflow.ExecuteActivity(ctx, sendEmailActivity).Get(ctx, &result)
// Asynchronous activity execution
future := workflow.ExecuteActivity(ctx, sendEmailActivity)Running Go routines 🔗︎
// Cadence
workflow.Go(ctx, func(ctx workflow.Context) {/* … */})
// Plain Go
go func(ctx context.Context) {/* … */}(ctx)Creating channels, sending and receiving data 🔗︎
// Cadence
channel := workflow.NewChannel(ctx)
channel.Send(ctx, true)
channel.Receive(ctx, &result)
// Plain Go
channel := make(chan interface{})
channel <- true
result := <-channelCreating a cancellable context 🔗︎
// Cadence
childCtx, cancelHandler := workflow.WithCancel(ctx)
// Plain Go
childCtx, cancelHandler := context.WithCancel(ctx)Timers 🔗︎
// Cadence
workflow.NewTimer(childCtx, processingTimeThreshold)
// Plain Go
timer.NewTimer(processingTimeThreshold)Sleeping 🔗︎
// Cadence
workflow.Sleep(sleepTime)
// Plain Go
time.Sleep(sleepTime)Waiting for completion of an action 🔗︎
// Cadence
selector := workflow.NewSelector(ctx)
selector.AddFuture(future, handle)
selector.Select(ctx)
// Plain Go
select {
case <-ready: handle()
case <-ctx.Done():
}Cadence by example 🔗︎
If this has whet your appetite for Cadence, try some simple experiments; there is a large number of examples ready to be run in this repository. To get you started, we’ll explain how to run that repository’s Hello World workflow.
Spin up Cadence 🔗︎
To get started with Cadence, you can either use the official docker-compose example environment, or the cadence Helm chart we contributed to the official incubator repository.
The Banzai Cloud Pipeline platform is a free service that helps you to spin up production grade Kubernetes clusters at multiple different cloud providers or on-premise. If you are experimenting with Cadence, and don’t have an application to integrate it into, we recommend trying out our Modern Go Application Spotguide, which has all the basic boilerplate and ops code a web application might require—from a CI/CD pipeline to production-ready services like monitoring, log handling or secret management to name a few.
Note: The Pipeline CI/CD module mentioned in this post is outdated and not available anymore. You can integrate Pipeline to your CI/CD solution using the Pipeline API. Contact us for details.
For docker-compose, set up a docker-compose.yml file based on the example, and run docker-compose up -d on your development machine. After that build and run the Hello World example.
## Clone cadence repository
git clone git@github.com:uber/cadence.git
cd cadence/docker
docker-compose up -d
## Clone the examples
mkdir cadence-samples/src/github.com/samarabbas/
export GOPATH=$(PWD)/cadence-samples
cd cadence-samples/src/github.com/samarabbas/
git clone git@github.com:samarabbas/cadence-samples.git
cd cadence-samples
make
## Start workflow execution for helloworld workflow
./bin/helloworld -m trigger
## Start workers for helloworld workflow and activities
./bin/helloworld -m workerIf you did everything correctly, congratulations! You’ve run your first Cadence task!
Conclusions and the next steps 🔗︎
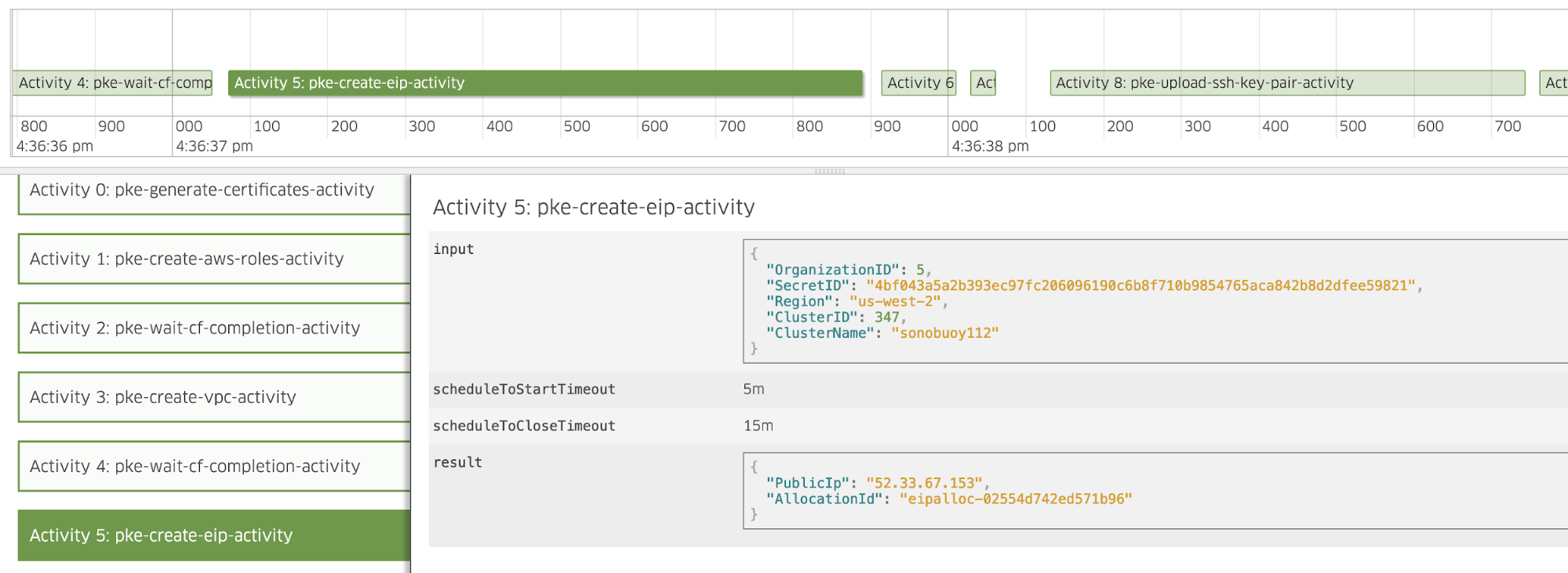
In this blog we explained why we chose Cadence as our workflow engine and demonstrated some of the powerful features it brings to the table. Stay tuned, because in a follow up post we’ll take a deep dive into how we created workflows to spin up clusters that go from zero to hero, and how we manage errors and deal with timeouts.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.




