Deploying Pipeline Kubernetes Engine on AWS with Cadence
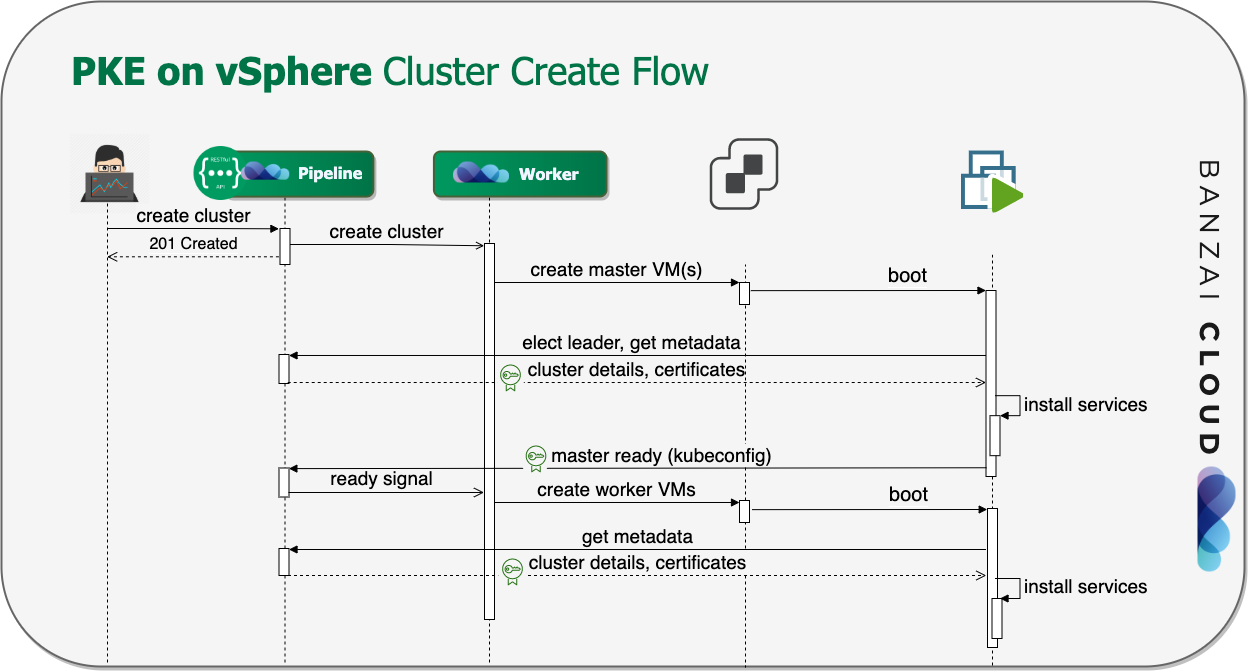
In our last post about using Cadence workflows to spin up Kubernetes we outlined the basic concept of Cadence and walked you through how to use the Cadence workflow engine. Let’s dive into the experiences and best practices associated with implementing complex workflows in Go. We will use the deployment of our PKE Kubernetes distribution, from Pipeline to AWS EC2 as an example.
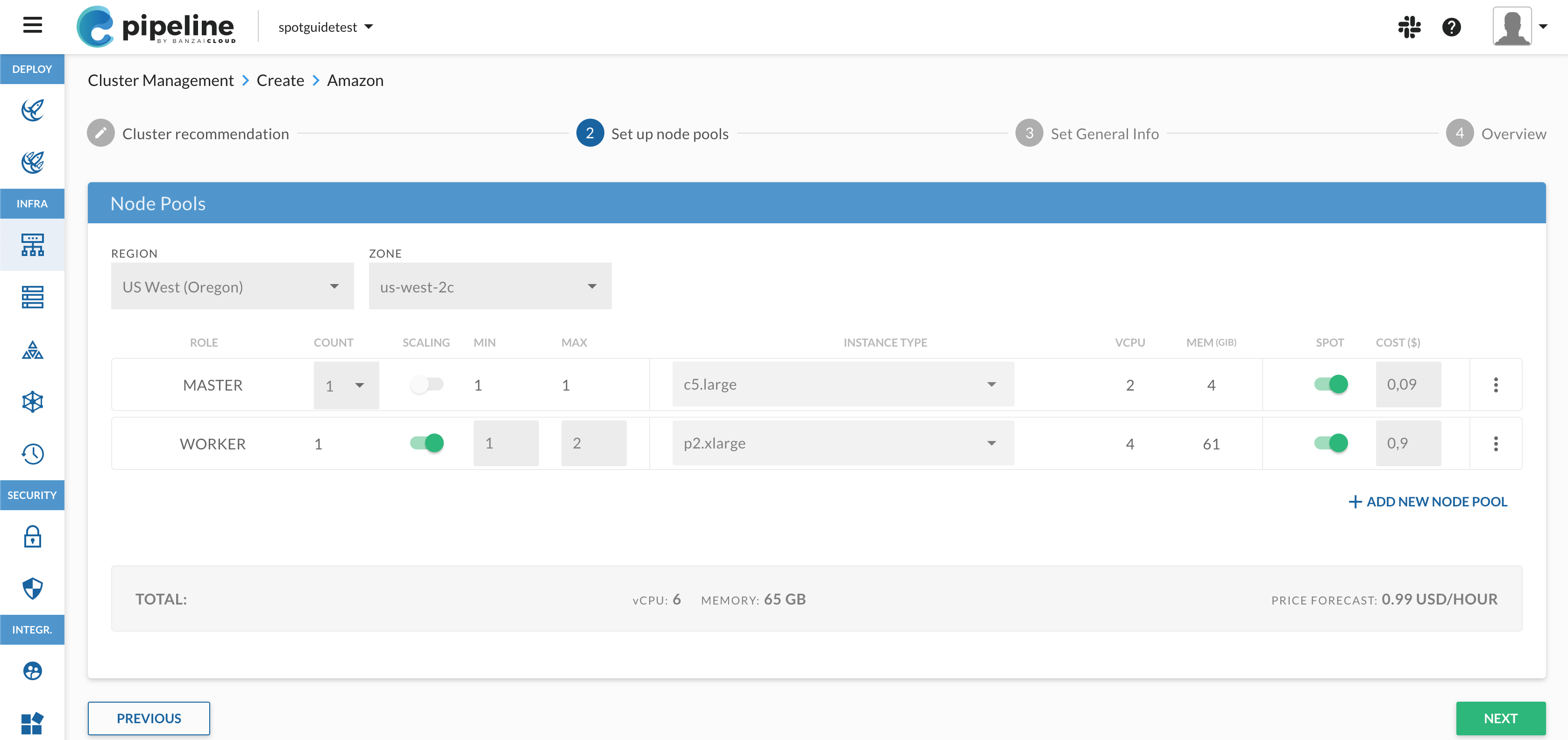
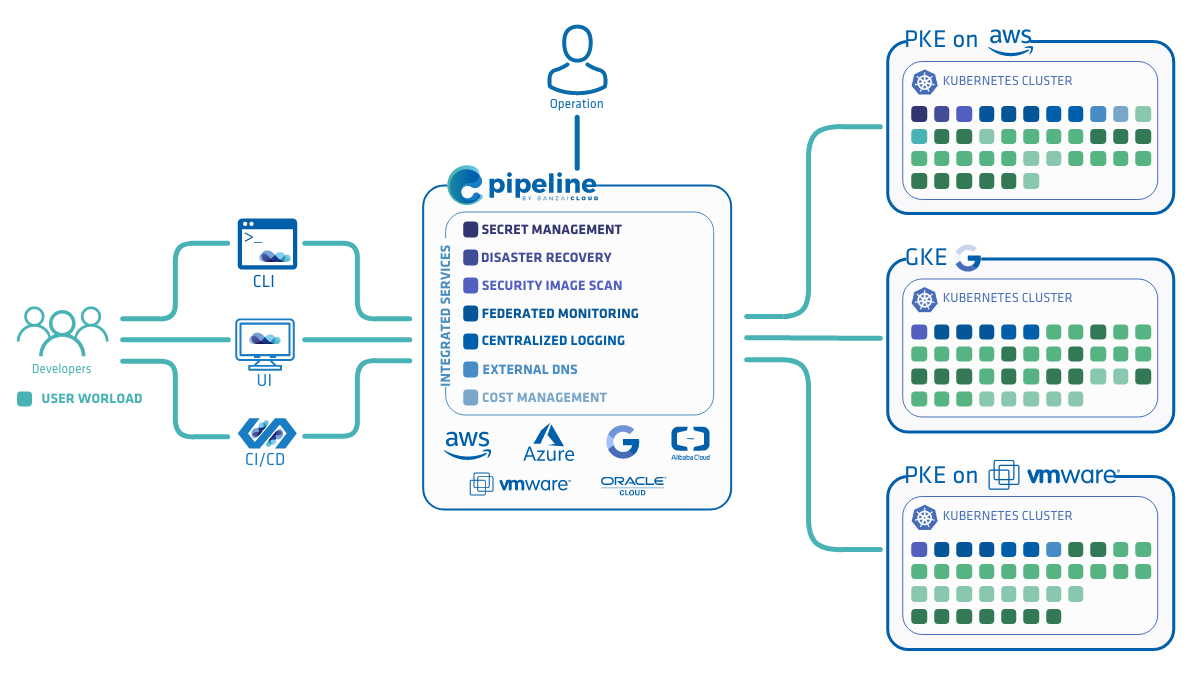
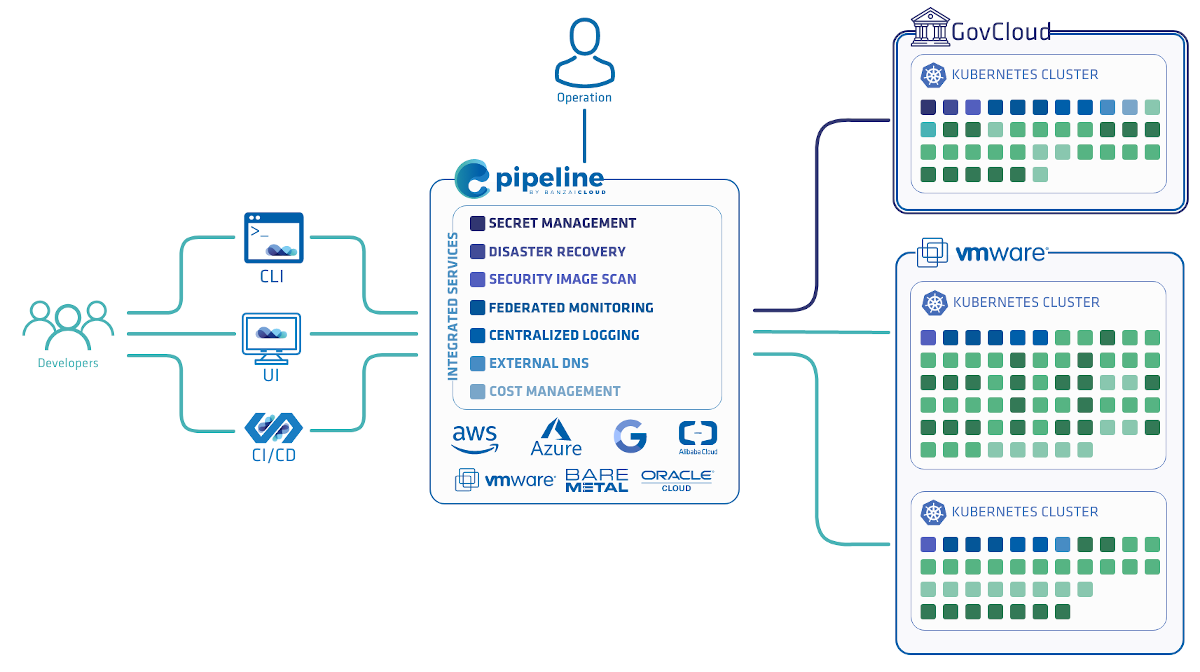
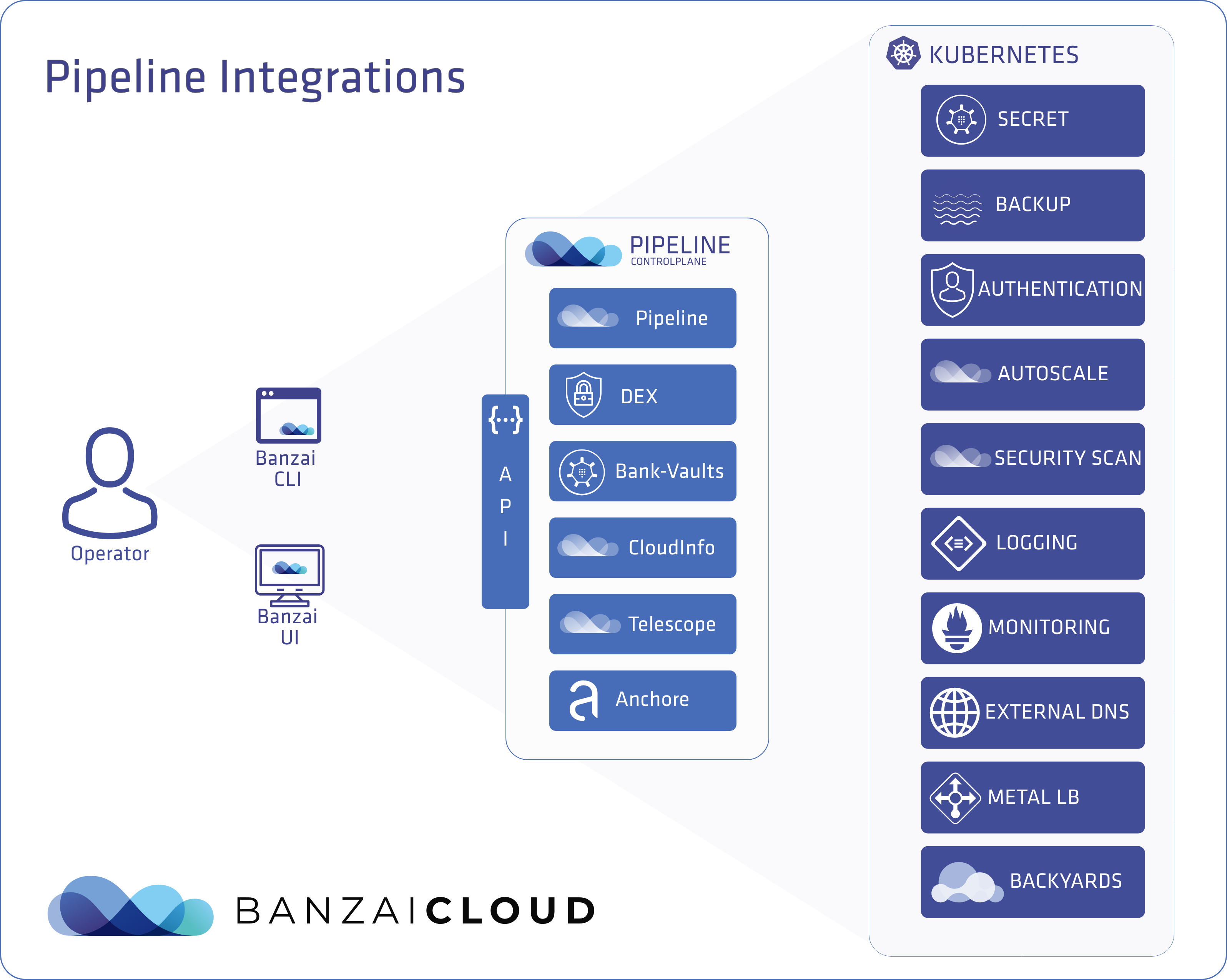
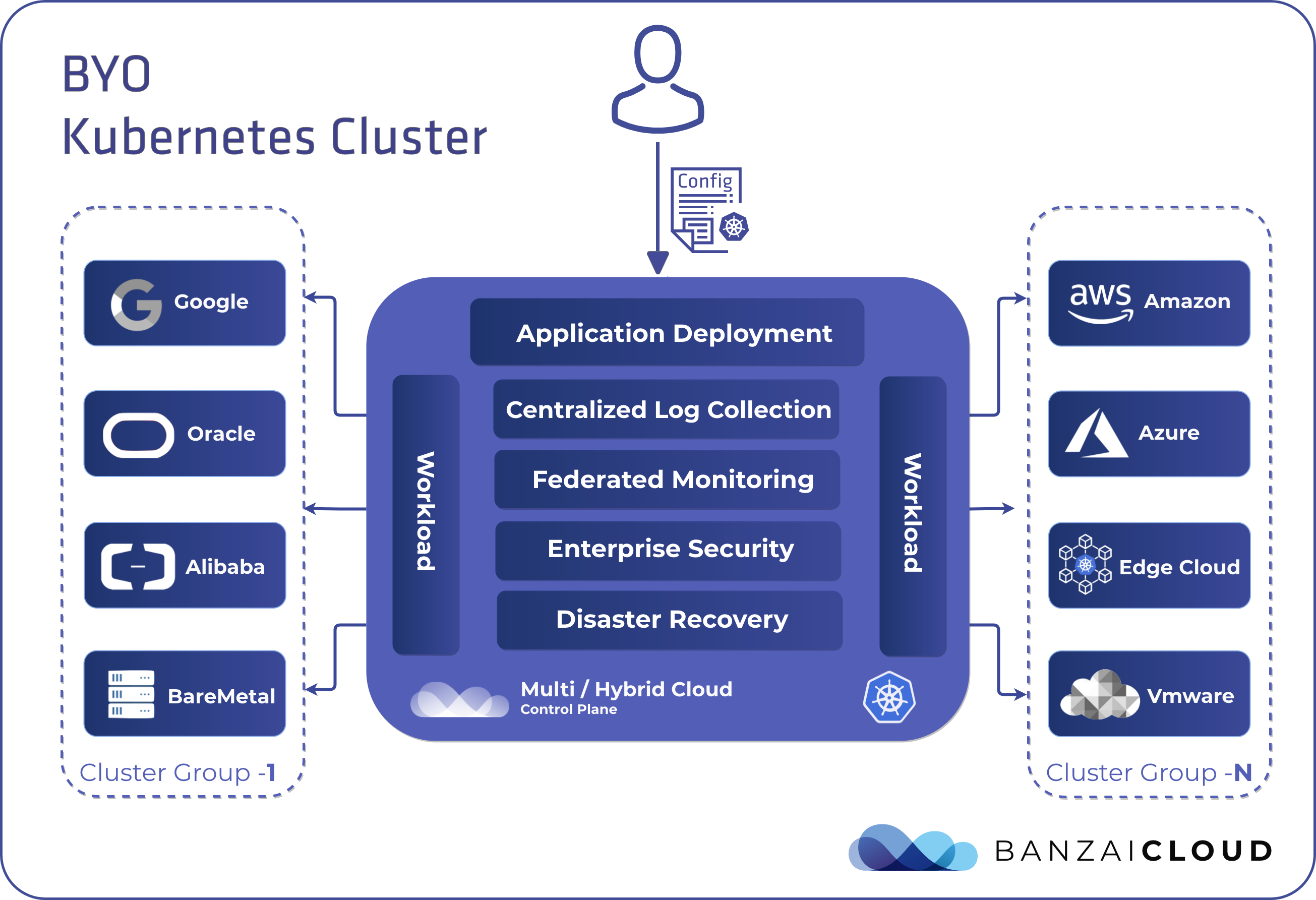
Of course, you can deploy PKE independently, but Pipeline takes care of your cluster’s entire life-cycle , starting from nodepool and instance type recommendations, through infrastructure deployment, certificate management, opt-in deployment and configuration of our powerful monitoring, logging, service mesh, security scan, and backup/restore solutions, to the scaling or termination of your cluster.
READ ARTICLE


Tue, Apr 23, 2019