At Banzai Cloud we work on a multi- and hybrid-cloud container management platform, Pipeline. As a result, we’ve opensourced quite a few Kubernetes operators. While writing some of the more complex operators, such as those for Istio, Vault or Koperator , we were faced with lots of unnecessary Kubernetes object updates. These updates are a byproduct of the fact that operators are typically used to manage a large number of resources. In each iteration, resource objects are first populated with their desired values, then sent to the Kubernetes API Server to ensure their desired state. This doesn’t just mean more work for the API Server, but also simultaneously hides flapping changes and other potential inconsistencies.
tl;dr: 🔗︎
- We opensourced an objectmatcher library to avoid unnecessary Kubernetes object updates while working with operators
Challenges in matching desired states 🔗︎
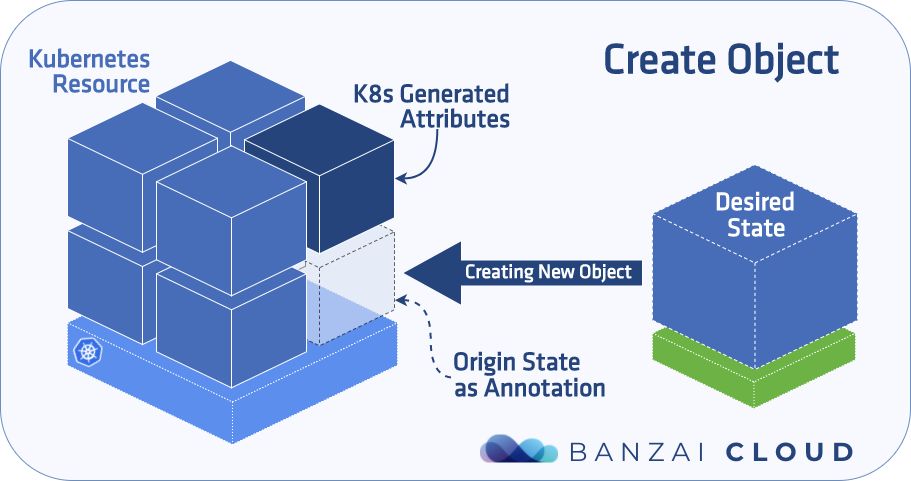
Most of the operators out there either just create objects and check specific fields on an individual basis, or else use reflect.DeepEquals to match up objects based on their Spec. The first solution doesn’t scale well, while we consider the second to be sloppy for a variety of reasons:
- Every Kubernetes object is amended with different default values when being submitted.
- Some Kubernetes objects are amended with calculated values when they are being submitted or even later as those values get available.
- There are incompatibilities between different client and server versions.
To demonstrate, let’s look at this very simple service before and after creation:
Before 🔗︎
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
After 🔗︎
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2019-06-30T14:54:26Z"
name: my-service
namespace: default
resourceVersion: "564"
selfLink: /api/v1/namespaces/default/services/my-service
uid: f4903399-9b46-11e9-856a-e61351a73615
spec:
clusterIP: 10.103.65.49
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: MyApp
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
Fields with default values:
metadata.namespacespec.ports.targetPortspec.sessionAffinityspec.type
Fields with calculated values:
metadata.creationTimestampmetadata.resourceVersionmetadata.selfLinkmetadata.uidspec.ClusterIP
The idea and a naive solution 🔗︎
Our first idea was to leverage a few existing Kubernetes capabilities, namely the json and strategic merge patch libraries, to create a two-way patch between actual and desired states.
A two-way patch would mean that deletions would also be taken into account, so that when such a patch is applied to the actual object the result is fully identical to the desired state.
A json patch is required for unstructured objects, while its strategic counterpart is for known types. These patches are great because they operate on the level of json representations, allowing us to redefine parts of objects with our own local types, and, for example, letting us ignore fields we don’t care about.
ObjectMeta is a good example of this. We can convert the original ObjectMeta from k8s.io/apimachinery/pkg/apis/meta/v1 into one with a locally defined type, wherein we care only about specific fields (labels, annotations, ownerReferences):
type ObjectMeta struct {
Labels map[string]string `json:"labels,omitempty"`
Annotations map[string]string `json:"annotations,omitempty"`
OwnerReferences []metav1.OwnerReference `json:"ownerReferences,omitempty"`
}
func (om *objectMatcher) GetObjectMeta(objectMeta v1.ObjectMeta) ObjectMeta {
return ObjectMeta{
Labels: objectMeta.Labels,
Annotations: objectMeta.Annotations,
OwnerReferences: objectMeta.OwnerReferences,
}
}
We can then use this locally overridden ObjectMeta in place of the original by using a local type for our own objects. Here, we use a DaemonSet to demonstrate this. As you can see, we are only concerned with the ObjectMeta and Spec fields, not Status.
type DaemonSet struct {
ObjectMeta
Spec appsv1.DaemonSetSpec
}
oldObject := DaemonSet{
ObjectMeta: objectMatcher.GetObjectMeta(old.ObjectMeta),
Spec: old.Spec,
}
oldData, err := json.Marshal(oldObject)
We can then marshal our object to json and, in a similar manner, prepare for the new object version from the desired state.
newObject := DaemonSet{
ObjectMeta: objectMatcher.GetObjectMeta(new.ObjectMeta),
Spec: new.Spec,
}
newData, err := json.Marshal(newObject)
Here, we use the objectMatcher instance to create a patch and check whether it’s empty so that it can report a match.
matched, err := m.objectMatcher.MatchJSON(oldData, newData, newObject)
if matched {
// no need to update!
}
Even if everything above were hidden behind a simple interface, without the client knowing any of the details, it required a lot of type specific logic to deal with the challenges we’ve discussed. To handle default values for instance, it had to use defaulting functions from the main kubernetes repo. This had serious consequenses as it was much harder to incorporate into downstream projects because of the tighter dependency version requirements. It was also harder to deal with different server versions since the specifc version of the defaulting functions we used, naturally had incompatibilities with some of them. We ended up writing an integration test matrix that could be run against multiple server versions and helped maintaining compatibility. The amount of if statements and type switches were already overwhelming at this point.
Also, the implementation had to remove null values (meaning deletions) from each patch. Removing these null values was necessary to avoid dealing with every single field generated solely on the server side, but also meant that objectMatcher was unable to detect such deletions.
So we put this method aside in favor of a more generic solution.
The more generic solution 🔗︎
Luckily, there’s an easier answer to our problem. kubectl apply does exactly what we need under the hood, since it can detect changes precisely by using three-way merges. Three-Way Merging: A Look Under the Hood
from Pablo Santos does a good job of illustrating how these work.
This method has the advantage of letting us ignore fields that aren’t set locally. This is because three-way merging primarily uses original vs. modified states to detect changes and deletions. The current state is then only checked partially, in order to see if any of the fields present have been changed or deleted so that the modified state differs from the current one. A conflict is reported when any change to a field has been made differently remotely, than locally. In our case, we’re not really interested in conflicts, we always want our desired, locally computed changes to win.
With three-way merges we detect local changes such as:
- modified values
- new fields or slice items
- deleted fields or slice items
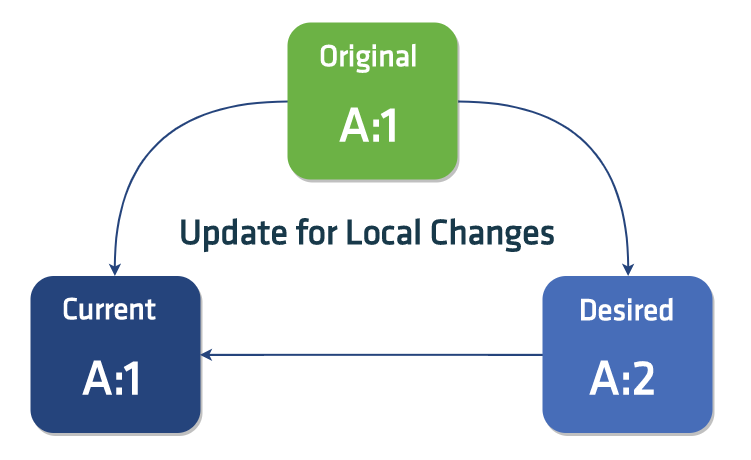
We also detect remote changes such as:
- modified values and deletion of fields or slice items that were present in the
originalobject - new fields or slice items that were also created in the
modifiedobject concurrently
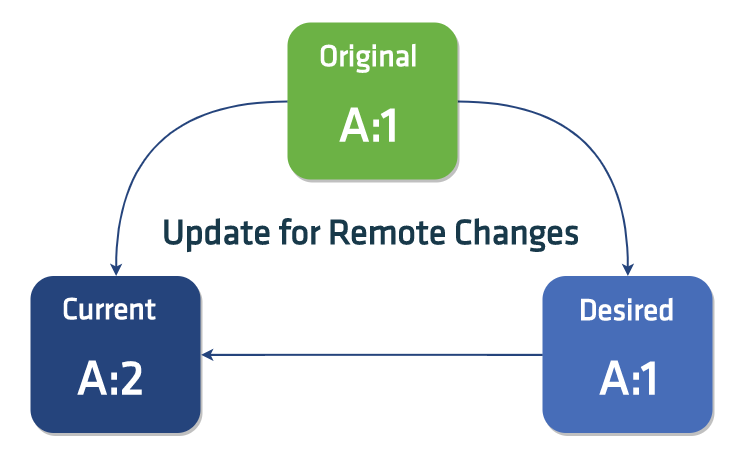
Lastly we ignore changes such as:
- additions, changes and deletions of fields and non-primitive slice items, that were not present in the
originalneither in themodifiedobject
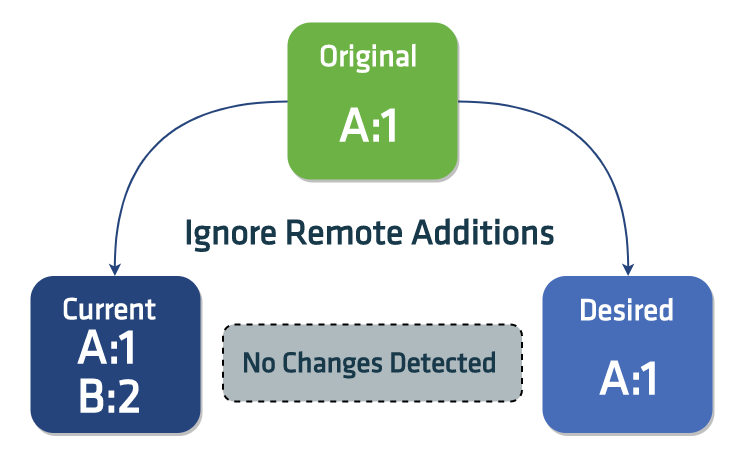
Keeping the last applied local state 🔗︎
However, for this to work properly we need to keep track of the last applied local version of our object: original. Unfortunately, Kubernetes does not hold on to previously submitted object versions, but we can save them into annotations the same way kubectl apply does.
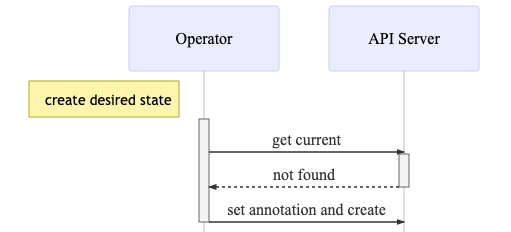
Next time we query the current state of an object from the API Server, we can extract the original version from the annotation.
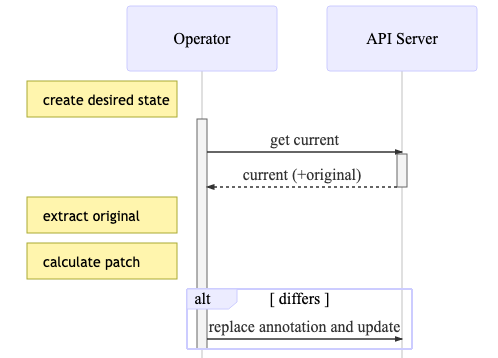
Once we have the original, current and our new desired objects in place (which, of course, may or may not differ from the original), the library takes care of the rest.
Service object example 🔗︎
In case the object does not exist, set the annotation and create it:
desired := &v1.Service{
...
}
current, err := client.CoreV1().Services(desired.GetNamespace()).Get(desired.GetName(), metav1.Getoptions{})
if err != nil && !apierrors.IsNotFound(err) {
// handle the error
}
if apierrors.IsNotFound(err) {
if err := patch.DefaultAnnotator.SetLastAppliedAnnotation(desired); err != nil {
// handle the annotation error
}
if _, err := client.CoreV1().Services(desired.GetNamespace()).Create(desired); err != nil {
// handle the creation error
}
}
...
In subsequent iterations, once the object already exists, we can check differences and set the last applied annotation, in case of an update is necessary.
desired := &v1.Service{
...
}
current, err := client.CoreV1().Services(desired.GetNamespace()).Get(desired.GetName(), metav1.Getoptions{})
if err != nil {
// handle the error
}
patchResult, err := patch.DefaultPatchMaker.Calculate(current, desired)
if err != nil {
// handle the error
}
if !patchResult.IsEmpty() {
err := patch.DefaultAnnotator.SetLastAppliedAnnotation(desired)
// Resource version is required for the update, but need to be set after
// the last applied annotation to avoid unnecessary diffs
desired.setResourceVersion(current.getResourceVersion())
err := client.CoreV1().Services(desired.GetNamespace()).Update(desired)
} else {
// Log all the details about the diff for better visibility into what is happening
log.V(3).Info("resource diffs",
"patch", string(patchResult.Patch),
"current", string(patchResult.Current),
"modified", string(patchResult.Modified),
"original", string(patchResult.Original))
}
Please note the comments above on some caveats:
- The field
metadata.resourceVersionneed to be set after the call toSetLastAppliedAnnotationotherwise it will be included in the patch and will always be detected as a change (resourceVersionchanges with every update). - It is recommended to log the patch and the object states in case of a diff for better visibility into what’s happening.
The challenges of using three-way strategic merges 🔗︎
This all looked good initially, but, as we started to test existing use cases against three way strategic merge patches, we saw two issues:
Empty fields 🔗︎
Struct fields, which are declared omitempty for json marshaling but are not pointer-type, cause problems because they are set to a zero value after being marshalled to json in original and desired. If one of those fields has a different value in current, then the patch will try to overwrite it, which is not what we want to happen.
For example, CreationTimestamp should be left out of an object’s json representation, if it has not been set. But, since it’s not pointer-type, it will be included.
CreationTimestamp Time `json:"creationTimestamp,omitempty" protobuf:"bytes,8,opt,name=creationTimestamp"`
One would expect creationTimestamp to be present with a zero value such as 0001-01-01T00:00:00Z, but actually it will be null in the encoded json, due to custom json marshalling.
Unfortunately
godoes not yet support zero values of structs with omitempty, although that seemingly irritates a lot of people: https://github.com/golang/go/issues/11939
This is not an issue with
kubectl apply, since it works with yaml and json configurations directly, wherein the abovegolimitation does not apply.
What we ended up doing here is removing fields with null and zero values from the original and modified objects; three-way merges detect changes correctly without this information, anyways.
To detect zero values we can use reflection.
Unnecessary ordering 🔗︎
Lists mutated on the server-side result is a totally different headache. The most prominent example is Volume and VolumeMount being mutated for pods in order to mount service account tokens into containers automatically. The strategic merge patch does not report a change explicitly for the automatically generated list items, but will add unnecessary SetElementOrder directives.
Currently, this is mitigated by applying a patch locally and checking it against the current version to determine if it is a false positive.
We beleive this is a limitation or maybe even a bug in the upstream Kubernetes library, although we haven’t gotten to the bottom of it as of yet. A github issue has been created on our repo to further investigate the case, and possibly a Kubernetes issue will follow soon.
We need your feedback 🔗︎
If you happen to have any ideas on how to make this library better, please don’t hesitate to share your thoughts and ideas, or reach out to us on our community slack!