At Banzai Cloud we write Kubernetes tools that, no surprise, require other tools to get installed. These tools handle resource lifecycle operations like the installation, upgrade, and removal of various components that need to be integrated together. Kubernetes Operators solve all these and even more for a given application’s domain, but if the focus is simply on installation, upgrade and removal of a set of components - which are in our case operators themselves (operating operators), then we need a tool with different characteristics at hand.
Depending on the target environment there is de-facto software we can use off the shelf:
- For Kubernetes apps there is Helm and Continuous Delivery systems like Argo that can manage applications lifecycle described simply in naked yaml.
- For pure operators there’s Operator Lifecycle Manager (OLM).
- For more general infrastructure there is Terraform.
Although these tools are well known, flexible and declarative, it’s usually hard to discover the right set of configuration options for a specific use case. Advanced users usually find their way out of the jungle, but the amount of configuration that needs to be fine tuned to integrate multiple components together can be a source of frustration, error, and a nightmare to deal with.
Let us introduce the design choices that led us towards our current approach on how to solve the above problems and create a hopefully better user experience.
An intermediate approach 🔗︎
For a short term we’ve been looking at the Backyards CLI installer’s concept as the right path forward. It’s been using statically bundled Helm chart templates for it’s different components that are all rendered, then the resulting resources are applied in the right order to the Kubernetes cluster.
Its user interface has been imperative with install/uninstall commands and a handful of flags.
One problem was finding the right set of flags to keep the installer flexible while keeping the number of options minimal for clarity. Without a central place to look for an overall state of components, it was also hard to tell what has already been installed.
Lastly, even if it was a good way to get started, it wasn’t the right tool for automation. CD systems typically require Helm charts, Kustomize, or pure yaml resources to operate with. Although there is a --dump flag that generates yamls instead of applying them, it would still require someone to run the install command per component locally, and commit the generated resources into version control. The CD workflow would then have to specify sequential steps for each component separately, which would have made the whole flow difficult to extend over time.
The new approach 🔗︎
We wanted something that enables full declarative configuration, but at the same time provides a minimal interface for getting started easily.
Single binary 🔗︎
We write most of our tools in Go and there are lots of things we love about it. One is that it compiles to a single platform-dependent binary without any runtime dependencies. You just install the tool and run it without having to deal with any dependency issues at runtime. We wanted to keep this behavior so that users will never have to download plugins or modules from external repositories. With this in mind the installer could work in an air-gapped setup as well.
Multiple operating modes 🔗︎
Not just that a single binary should contain its dependencies, but it should support multiple usage scenarios. Think about Bank-Vaults where the bank-vaults tool can be used both as the configurer of a Vault instance managed by the operator, but also as a separate CLI tool. Or the Vault project itself that supports multiple operating modes like server, agent and remote management commands at the same time.
Our primary intent was to cover both imperative management commands and a one-shot, operator like reconciliation mode in a single binary.
Declarative configuration 🔗︎
We aim for a declarative configuration style which is core to Kubernetes. This is why we decided to use CRDs even if the installer is running in the command line. It can load an existing configuration by getting it from the Kubernetes cluster, or load it from a yaml file and apply it directly. The point is to make the core logic similar to what is running inside an operator: get a configuration with a known scheme and make the world look like as the configuration describes it. This provides us reproducibility, since we can recreate the whole setup with a single command.
All the managed components’ desired state is configurable in our Custom Resource, similar to how a Terraform module describes its resources. The main difference is that:
- dependencies between components are not analyzed, and
- the execution order is linear rather than a concurrent graph traversal.
Any state that needs to be persisted can be set in the resource’s status field, but since we are working with Kubernetes resources we don’t need to register all resource ids because we can depend on deterministic names.
Focus on static infrastructure 🔗︎
Initially we wanted to add templates for creating dynamic resources into the main CRD so that we could describe all the corresponding objects in a single resource. This unfortunately turned out not to be a good idea because of Kubernetes object size limitations, and it would also have made the main resource harder to reason about.
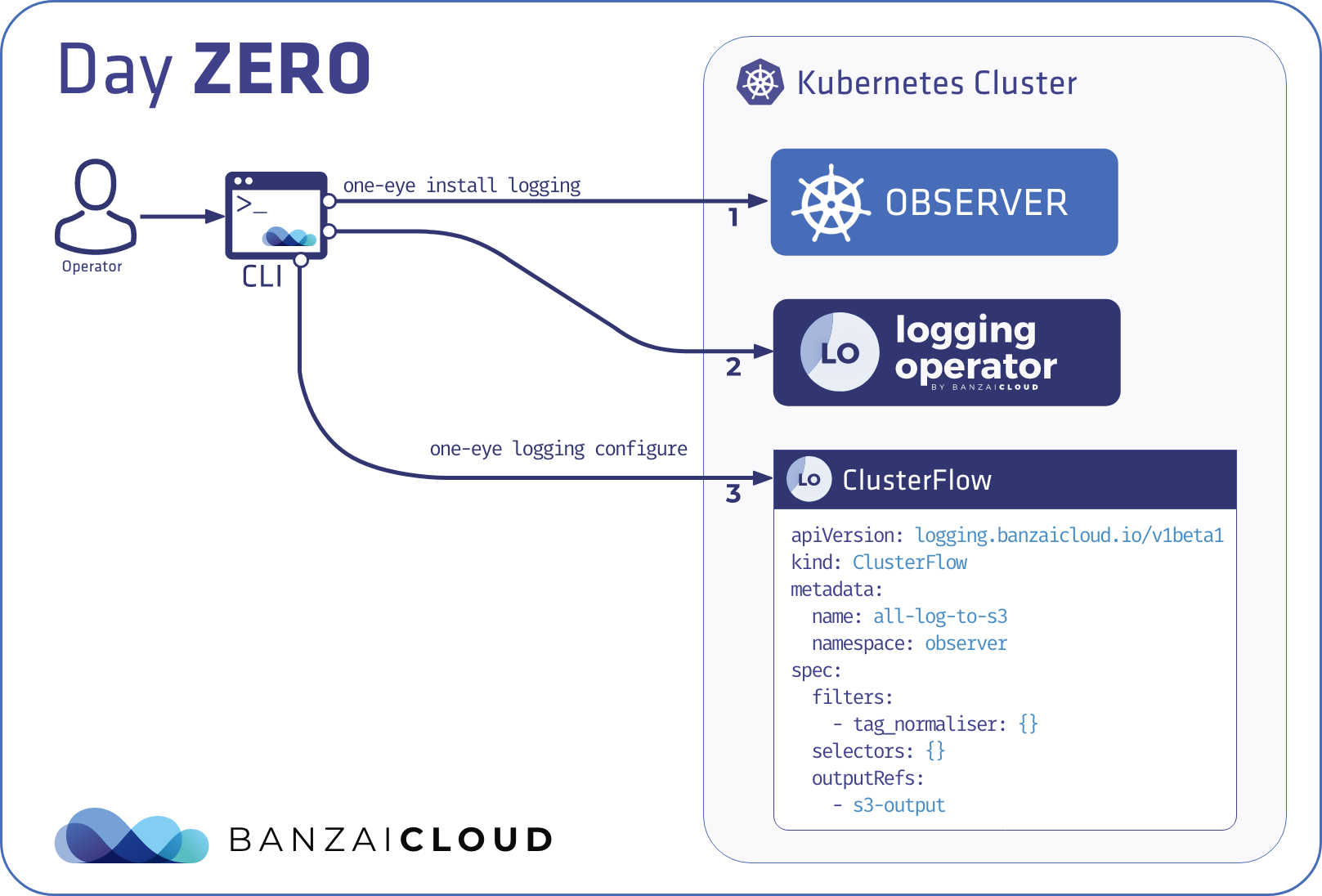
For example in case of One Eye managing the Logging Operator is the installer’s responsibility, but Logging CRDs are not. We have instead created a helper command (one-eye logging configure) to create Logging CRs interactively to get started, but there is no requirement on how dynamic resources like these should be managed.
This is also important to avoid requiring operators frequently rerunning the reconcile command if they have to do it manually.
Don’t reimplement what’s already available 🔗︎
We built our own operators where we saw the need to create one, but we are cool with reusing existing tools if they already match a given use case. With this in mind we added support to statically compile and preconfigure Helm charts as building components to our tool.
Operating modes 🔗︎
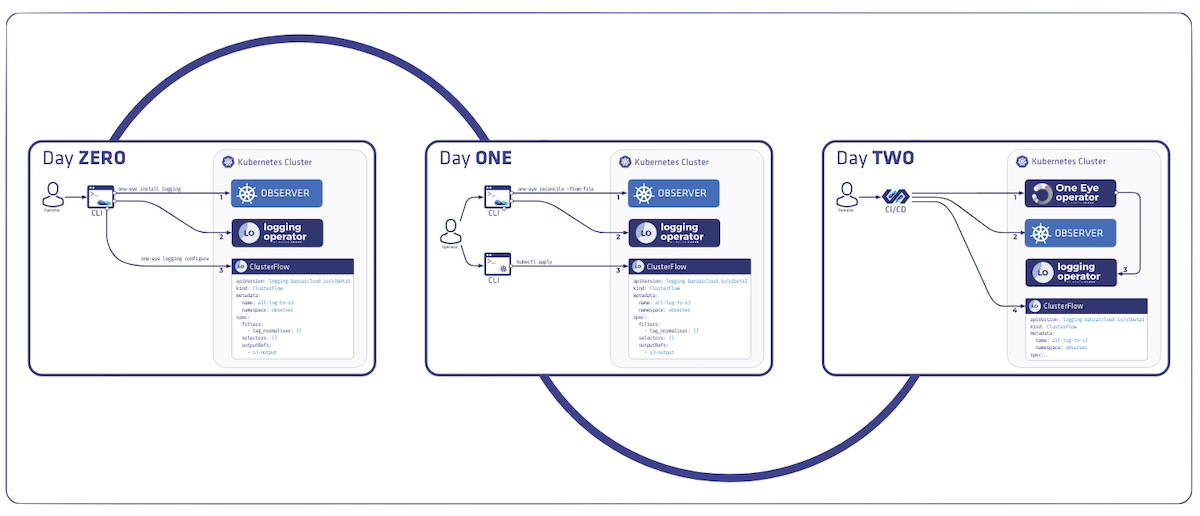
Day 0 - imperative commands: install, delete 🔗︎
The concept is to provide easy to use commands to get started and experiment with the various components. These commands allow only a small subset of the available configuration options, to avoid getting overloaded with command line flags. Obviously they are not meant to enable each and every configuration use case, instead they help the user kicking off with the default settings and some of the most important configuration flags.
Internally install and delete commands work as follows: they change the component-specific parts of the main configuration, then trigger the reconciliation of the affected components.
Other commands like
configureon the following diagram can be different. It doesn’t change the main configuration, neither trigger reconciliation of any component. It’s just a helper command to extend the toolset by creating dynamic resources which are out of scope for the reconcilers, but are convenient for getting started without ever leaving the CLI.
Once the experimentation is over, the recommended way forward is to switch to the reconcile command and apply all configuration through the custom resource directly. This is analogous to how you use kubectl create and then switch to using kubectl apply when you already have a full configuration and just want to apply changes incrementally. Advanced users would simply skip to using the reconcile command from the start.
Day 1 - CLI declarative mode: reconcile 🔗︎
The reconcile command is a one-shot version of an operator’s reconcile flow. Component reconcilers are executed in order and can decide whether they require another reconciliation round or already finished. New configuration gets applied, disabled components get removed from the system.
A component can be anything that receives the whole configuration, understands its own part from it to configure itself and is able to delete its managed resources once disabled or removed. Currently two implementations exist in our operator-tools library.
- The native reconciler triggers a “resource builder” to create Kubernetes resources along with their desired state (present or absent) based on the component’s configuration. Such resource builders are typically simple Go code that create CRDs, RBAC and a Deployment resource to be able to run an operator.
- The other implementation is the Helm reconciler that basically acts as a Helm operator. It installs and upgrades an embedded chart if it has changed, or uninstalls if it has been removed from the main configuration.
This mode is better suited to a GitOps style, generic CICD flow, where changes to the main configuration are applied to a specific cluster directly.
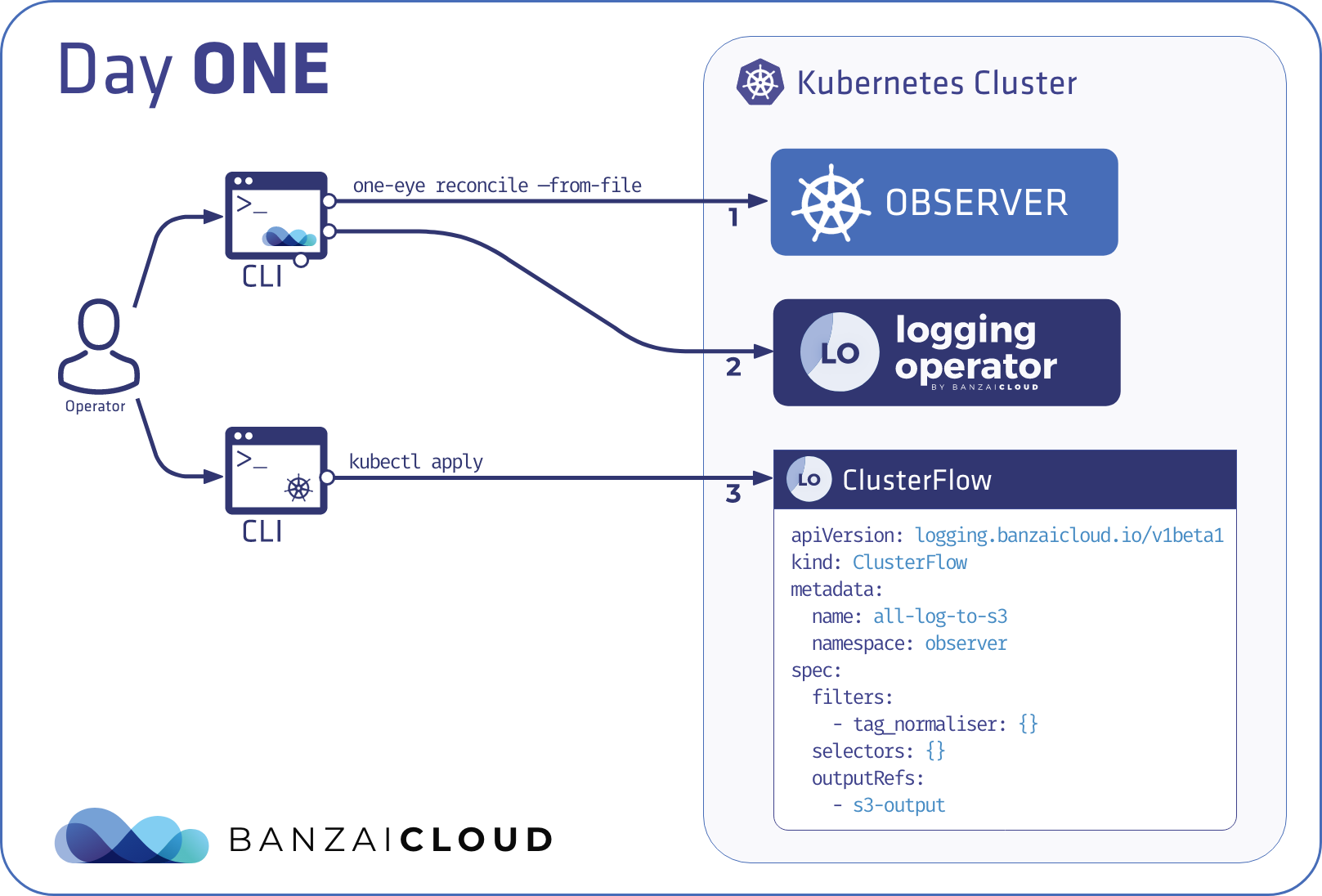
Compared to kubectl apply: adds ordering and allows custom logic to get executed if required. Removes resources not present in the config anymore. The CLI in this case executes the control logic as well.
Compared to terraform: dependencies are managed in predefined execution order and static binding using deterministic names. Lower performance, but easier to follow. Remote state is the CR saved into the API server.
Day 2 - Operator mode 🔗︎
The operator mode should be no surprise to anyone already familiar with the operator pattern. Watched events on resources trigger a reconciliation for all components in order, the same way we trigger the reconcile command locally. But in this case the operator is running inside Kubernetes and not on a remote machine. This naturally means that this mode is exclusive with the install, delete, and reconcile commands.
Also, this is the recommended way to integrate the installer in a Kubernetes native continuous delivery solution, like the one Argo provides, where the integration boils down to applying yamls to get the installer deployed as an operator.
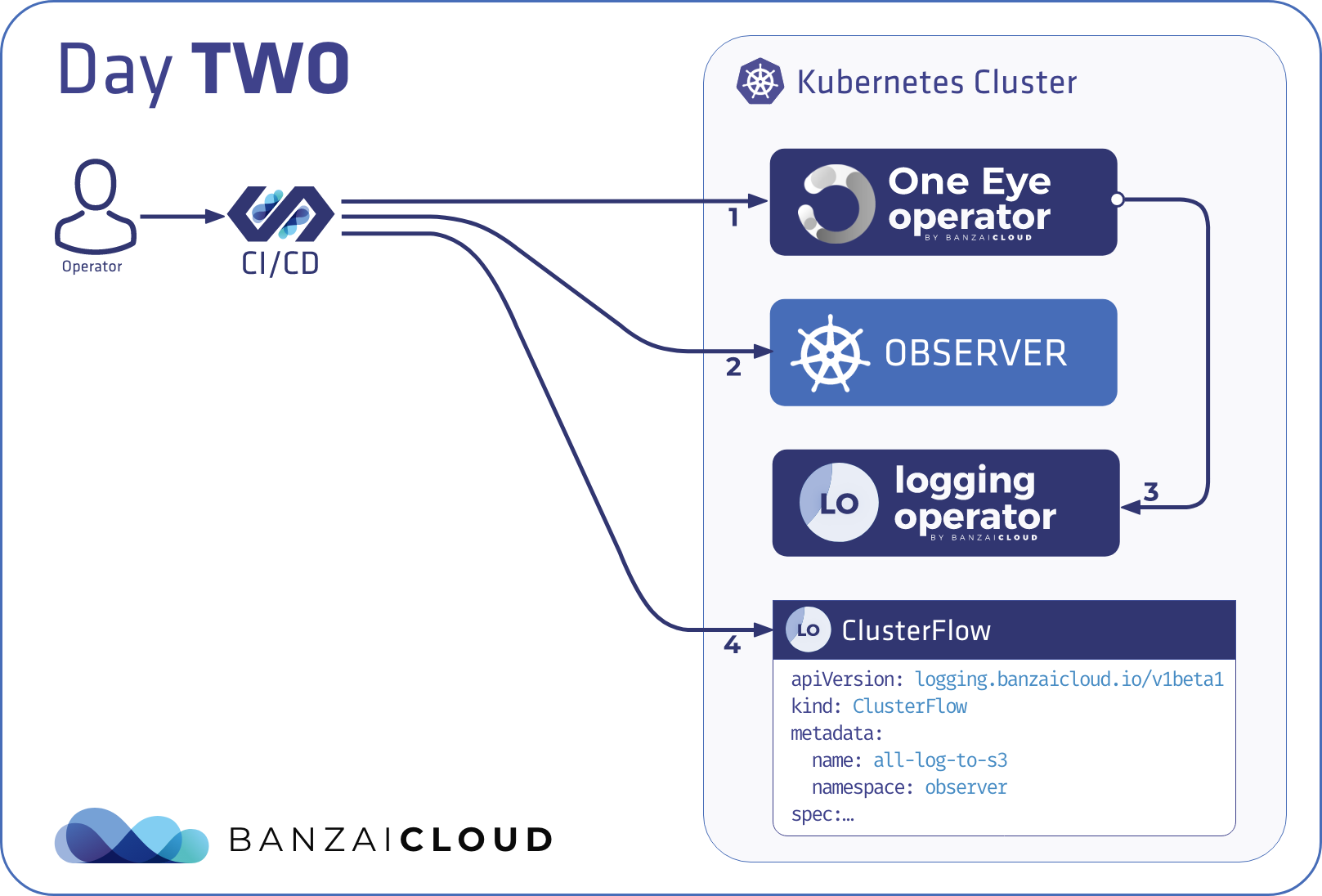
Existing configuration managed by the reconcile command previously will work out-of-the box after switching to the operator mode.
Example: One Eye CLI 🔗︎
Let’s look at an example: the CLI for One Eye.
One Eye has several components, some of those are: Prometheus, Grafana, the Logging and Thanos operators, and an ingress to make the UI and Grafana dashboards accessible.
Install 🔗︎
You can install the logging infrastructure (the Logging operator, the Logging extensions operator), and Prometheus and Grafana preconfigured with the following command:
one-eye logging install --prometheus
Running this command creates the following configuration:
apiVersion: one-eye.banzaicloud.io/v1alpha1
kind: Observer
metadata:
name: one-eye
spec:
controlNamespace: default
ingress: {}
logging:
extensions: {}
operator: {}
prometheus:
prometheusOperatorChart: {}
thanos: {}
The logging and extensions operators are installed with their default configurations, although they also provide several configuration options for fine tuning.
For Prometheus we leverage the prometheus-operator chart with some preconfigured defaults, which are not visible in the generated config, but available if you query the helm values using helm get values one-eye-prometheus-operator.
Custom helm values can be defined using the prometheusOperatorChart.values field and will be merged on top of the defaults.
The thanos and ingress components are part of the configuration, but not yet configured further, so they won’t get installed.
Upgrade 🔗︎
Once we configured all the required components and settled on a decent setup, eventually we will have to upgrade.
A future version of One Eye will contain updated versions for some - or even all - of the above components. Ideally we have nothing else to do, but download the latest One Eye CLI and run one-eye reconcile over the previous configuration, or simply upgrade the operator if it’s deployed into the cluster.
Wrapping up 🔗︎
The approach we described in this post builds on existing concepts and integrates them into a single tool, to make the transition from evaluation to a fully automated production setup smooth. One Eye, Backyards (now Cisco Service Mesh Manager) and Supertubes all started to converge into this direction so that we can produce a consistent and convenient user experience across all these products.