






One of our goals at BanzaiCloud is to make our customers’ lives easier by providing low barrier to entry, easy to use solutions for running applications on Kubernetes. To achieve this, we often rely on Kubernetes Operators to provide comprehensive solutions over the course of an application’s lifecycle. Here is a list of our operators, which we have already open sourced:
Today’s post will focus on MySQL on Kubernetes. MySQL is a popular, well known open source RDBMS. Operating a MySQL cluster on Kubernetes is not a straightforward process, especially if we go beyond provisioning, which is why we use an operator to automate this work for end-users. There are a couple of good MySQL operators available as open source code, so let’s weigh the benefits and drawbacks of each one to understand which best fits the needs of our users. This entails support for multiple namespaces, RBAC, TLS, backup/restore capabilities, high availability, monitoring etc.
MySQL operators comparison 🔗︎
There are 3 different MySQL operators on this list, which are built by the community and managed by CoreOS.
This table compares these operators’ capabilities.
Feature *** |
grtl/mysql-operator | presslabs/mysql-operator | oracle/mysql-operator |
|---|---|---|---|
| Self healing cluster | No* |
Yes | Yes |
| Multiple version | Yes | Yes (Only percona’s image) | X (official and GA image) |
| Multiple namespaces | No ** |
Yes | Yes |
| Multiple replicas | Yes | Yes | Yes |
| Multimaster | No | No | Yes |
| RBAC support | No | No | Yes |
| TLS support | No | No | Yes |
| Custom config | No | Yes | Yes |
| Backup/Restore | PVC | GCS/S3/HTTP (with helper image) | S3/GCE(only with s3 interface) |
| Create cluster from backup | Yes | Yes | No |
| Monitoring support | Yes | Yes | Yes |
* Unclear, because we couldn’t find any documentation.
** Operator behavior manages MySQL clusters created in the same namespace.
*** This comparison does not include all features.
We opted for the Oracle MySQL Operator, as it provides the most comprehensive feature set for our needs in creating, operating and scaling self-healing MySQL clusters on Kubernetes.
Key features 🔗︎
- Self-healing solution
- Complete high availability solution for MySQL running on Kubernetes.
- Built on InnoDB storage, using group replication.
- The MySQL Group Replication feature is a multi-master update-anywhere replication plugin for MySQL with built-in conflict detection and resolution, automatic distributed recovery, and group membership.
- Backup (with a scheduler feature) and restore databases
- You can create a backup on-demand or schedule a time period. Currently implemented using
mysqldump, but Oracle is working on a MySQL Backup Enterprise solution.
- You can create a backup on-demand or schedule a time period. Currently implemented using
- Monitoring
- The operator has a built-in Prometheus metrics entry point
- All statefulset are annotated for Prometheus
Infrastructure overview 🔗︎
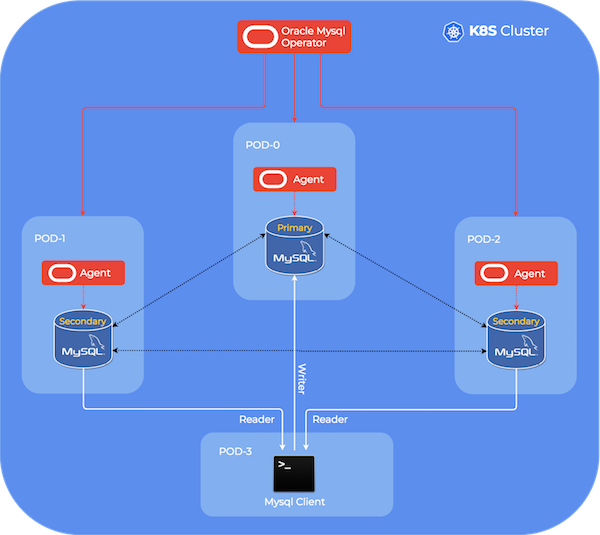
Limitations 🔗︎
Currently, this operator has some shortcomings:
- The database backup is implemented using
mysqldumpand backup can be stored only on S3 or S3 compatible storage. - It doesn’t support bootstrapping a new database from SQL script or from backup.
- The operator annotates statefulset for Prometheus, however, these are hardcoded.
Features we are working on and about to contribute back 🔗︎
There are a couple of features that we think would make good additions to the MySQL operator, some of which we plan to pick up in the future and contribute back:
- Multiple storage provider (Google Cloud Storage, Azure Blob Storage) and PVC support for backup
- Configurable statefulset annotations
- Create clusters with bootstrap SQL or from an existing backup
- A backup solution besides
mysqldump - Multiple service definitions (read-only, read-write)
How to install Oracle MySQL Operator 🔗︎
Installing the MySQL Operator Chart 🔗︎
helm repo add banzaicloud-stable http://kubernetes-charts.banzaicloud.com/branch/master
helm install --name my-release banzaicloud-stable/mysql-operatorExamples 🔗︎
The following examples show how the MySQL Operator can be used to create and restore MySQL Clusters with a backup.
Create cluster 🔗︎
root password secret
First, a Kubernetes Secret containing the database root password needs to be created.
kubectl create secret generic mysql-root-password --from-literal=password="Ch4Ng3mE"You need this minimal config to use a MySQL server with legacy password.
mysql-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: your-mycnf
data:
my.cnf: |-
[mysqld]
default_authentication_plugin=mysql_native_password
skip-host-cache
skip-name-resolveCreate a configmap from the YAML file.
kubectl create -f mysql-config.yamlCluster 3 members without multi-master mode with specific root password.
cluster-minimal.yaml
apiVersion: mysql.oracle.com/v1alpha1
kind: Cluster
metadata:
name: your-cluster-name
spec:
members: 3
multiMaster: false
rootPasswordSecret:
name: mysql-root-password
config:
name: your-mycnfCreate a cluster from the YAML file.
kubectl create -f cluster-minimal.yamlList all MySQL clusters 🔗︎
kubectl get mysqlclusterNAME AGE
your-cluster-name 30m
kubectl get mysqlclusterCheck that all pods are up and running 🔗︎
kubectl get pods -l v1alpha1.mysql.oracle.com/cluster=your-cluster-nameNAME READY STATUS RESTARTS AGE
your-cluster-name-0 2/2 Running 0 2m
your-cluster-name-1 2/2 Running 0 1m
your-cluster-name-2 2/2 Running 0 1mFind the “primary” node (not necessary if you use multimaster=true) 🔗︎
➜ kubectl get pods -l v1alpha1.mysql.oracle.com/role=primary
NAME READY STATUS RESTARTS AGE
your-cluster-name-0 2/2 Running 0 2mIn this case, you will also need to create ReadOnly and ReadWrite services 🔗︎
cluster-services.yaml
apiVersion: v1
kind: Service
metadata:
labels:
v1alpha1.mysql.oracle.com/cluster: your-cluster-name
name: your-cluster-name-rw
spec:
clusterIP: None
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
v1alpha1.mysql.oracle.com/cluster: your-cluster-name
v1alpha1.mysql.oracle.com/role: primary
type: ClusterIP
---
apiVersion: v1
kind: Service
metadata:
labels:
v1alpha1.mysql.oracle.com/cluster: your-cluster-name
name: your-cluster-name-ro
spec:
clusterIP: None
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
v1alpha1.mysql.oracle.com/cluster: your-cluster-name
v1alpha1.mysql.oracle.com/role: secondary
type: ClusterIPCreate services for the cluster from the YAML file
kubectl create -f cluster-services.yamlCheck your MySQL services 🔗︎
Run a simple pod to check statuses
kubectl run -i --rm --tty mysql-client --image=mysql/mysql-server --restart=Never --command -- /bin/shInstall necessary command to check DNS information
yum install bind-utils -yCheck service cluster DNS entries
sh-4.2# host your-cluster-name-ro
your-cluster-name-ro.default.svc.cluster.local has address 10.1.0.159
your-cluster-name-ro.default.svc.cluster.local has address 10.1.0.160
sh-4.2# host your-cluster-name-rw
your-cluster-name-rw.default.svc.cluster.local has address 10.1.0.158Check MySQL global read-only status
sh-4.2# mysql -u root -p -hyour-cluster-name-ro.default.svc.cluster.local -e "SELECT @@global.read_only;"
Enter password:
+--------------------+
| @@global.read_only |
+--------------------+
| 1 |
+--------------------+
sh-4.2# mysql -u root -p -hyour-cluster-name-rw.default.svc.cluster.local -e "SELECT @@global.read_only;"
Enter password:
+--------------------+
| @@global.read_only |
+--------------------+
| 0 |
+--------------------+If you recieved similar results then everything is going smoothly. :)
What happens when the primary node dies? 🔗︎
It’s pretty simple: the operator keeps the cluster healthy. It changes the role of primary to another MySQL instance, and starts a new MySQL instance. This process takes just a few seconds, however if that’s too long, you can use a multi-master setup.
When you delete the primary instance
kubectl delete pods -l v1alpha1.mysql.oracle.com/role=primaryThe MySQL operator changes the role of primary from your-cluster-name-0 to your-cluster-name-1
kubectl get pods -l v1alpha1.mysql.oracle.com/role=primaryNAME READY STATUS RESTARTS AGE
your-cluster-name-1 2/2 Running 0 34mAnd of course, we get another secondary instance
kubectl get pods -l v1alpha1.mysql.oracle.com/role=secondaryNAME READY STATUS RESTARTS AGE
your-cluster-name-0 2/2 Running 0 2m
your-cluster-name-2 2/2 Running 0 37mBackups 🔗︎
The operator supports two types of backups:
- on demand backups, which allows the user to initiate a database backup on demand
- scheduled backups, which allows the user to schedule backups
The component that actually executes the process of creating a database backup is configurable. The user can specify the name of the backup executor to be used under the executor section:
apiVersion: mysql.oracle.com/v1alpha1
kind: Backup
...
spec:
executor:
mysqldump:As of now, only mysqldump is available as a backup executor.
The backup process is executed on one of the secondary nodes if any are available, otherwise it is executed on the primary node. The resulting database backup file is stored in storage that the user can configure under the storageProvider section:
apiVersion: mysql.oracle.com/v1alpha1
kind: Backup
...
spec:
...
storageProvider:
s3:The current implementation supports only S3 or S3 compatible storage.
Create an on-demand backup 🔗︎
First, a Kubernetes Secret containing the AWS credentials needs to be created.
kubectl create secret generic s3-credentials --from-literal=accessKey="******" --from-literal=secretKey="******"The backup should contain some information:
- The cluster name (your-cluster-name)
- The list of database names (test,test2,test3)
- S3 specific information with credentials from the Kubernetes Secret
backup.yaml
apiVersion: mysql.oracle.com/v1alpha1
kind: Backup
metadata:
name: mysql-backup
spec:
executor:
mysqldump:
databases:
- name: test
- name: test2
- name: test3
storageProvider:
s3:
endpoint: your.s3.endpoint
region: us-west-1
bucket: your-bucket
credentialsSecret:
name: s3-credentials
clusterRef:
name: your-cluster-nameThen, create a backup from the YAML file.
kubectl create -f backup.yamlScheduled backups 🔗︎
This is essentially the same as the on-demand backups described above, but the user can specify a schedule in cron format for initiating backups:
apiVersion: mysql.oracle.com/v1alpha1
kind: BackupSchedule
metadata:
name: mysql-backup-schedule
spec:
schedule: '*/2 * * * *'
backupTemplate:
executor:
...Verifying the status of backups 🔗︎
The user can check the status of backups by running:
kubectl describe mysqlbackup mysql-backupRestore from backup 🔗︎
Databases can be restored from a previously created MySQL backup with:
apiVersion: mysql.oracle.com/v1alpha1
kind: Restore
metadata:
name: mysql-restore
spec:
cluster:
name: your-cluster-name
backup:
name: mysql-backupThis will restore any and all databases backed up earlier by the corresponding backup resource.
Note: the mysql-operator is actively being developed, so if you use the latest version from master, you may run into some issues. As of writing, I noticed that backups don’t go through completely in my dev environment and never enter a completed state. If you want to play with the backup/restore functionality, use one of the released versions
Delete cluster 🔗︎
Finally, if you don’t want to use a cluster, it can be deleted with this command.
kubect delete mysqlcluster your-cluster-nameConclusion 🔗︎
Although the MySQL Operator is still under development, it’s already an effective tool. We’ve used it for a while and, if you are running MySQL on Kubernetes, we believe it’s a pretty good option.
Visit https://github.com/oracle/mysql-operator to learn more.




