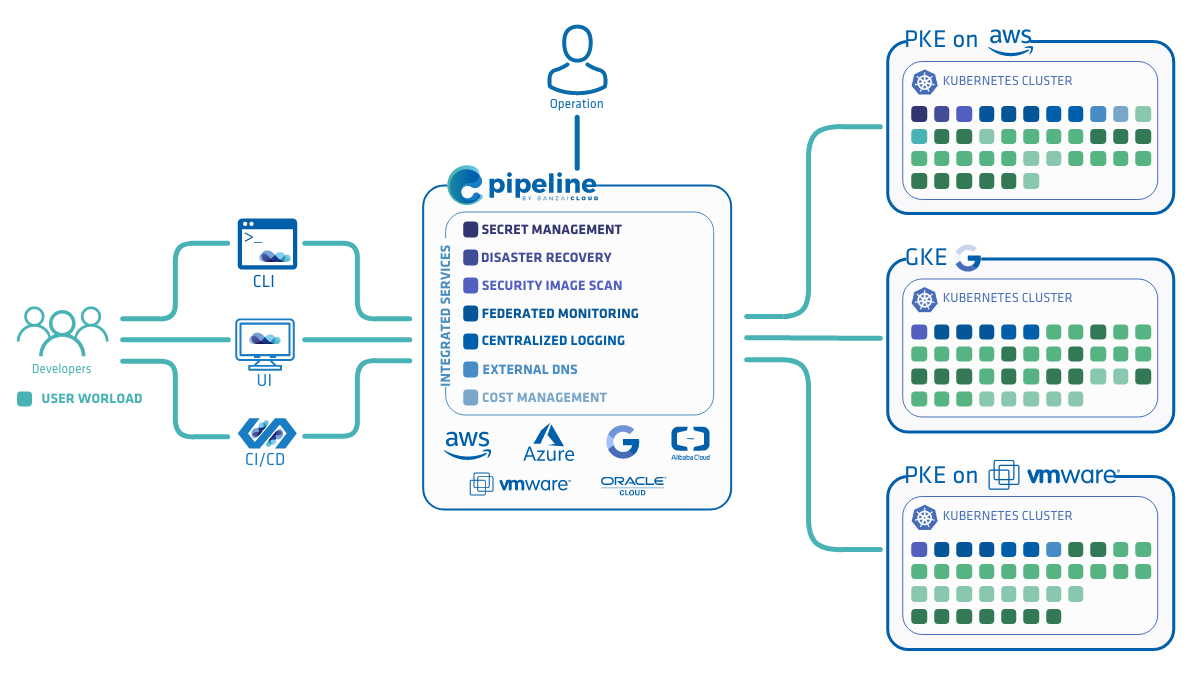
Integrated Services have long been a key feature of the Banzai Cloud Pipeline platform, making complex infrastructure components ready for use with just a few clicks in the UI or a single command from the Banzai CLI.
Some of the most important Integrated Services:
- Monitoring and Logging
- DNS
- Secrets Management
- Vulnerability scanning
There’s a lot of value already added by the current generation of Integrated Services:
- We can enable and disable complex features on demand through the Integrated Service API easily, without any extra tooling from the user
- We can upgrade these Services to their latest version with a single click, as long as the upgrade doesn’t require special steps when migrating
- We can leverage existing Helm charts and use Helm libraries for deployment in the background
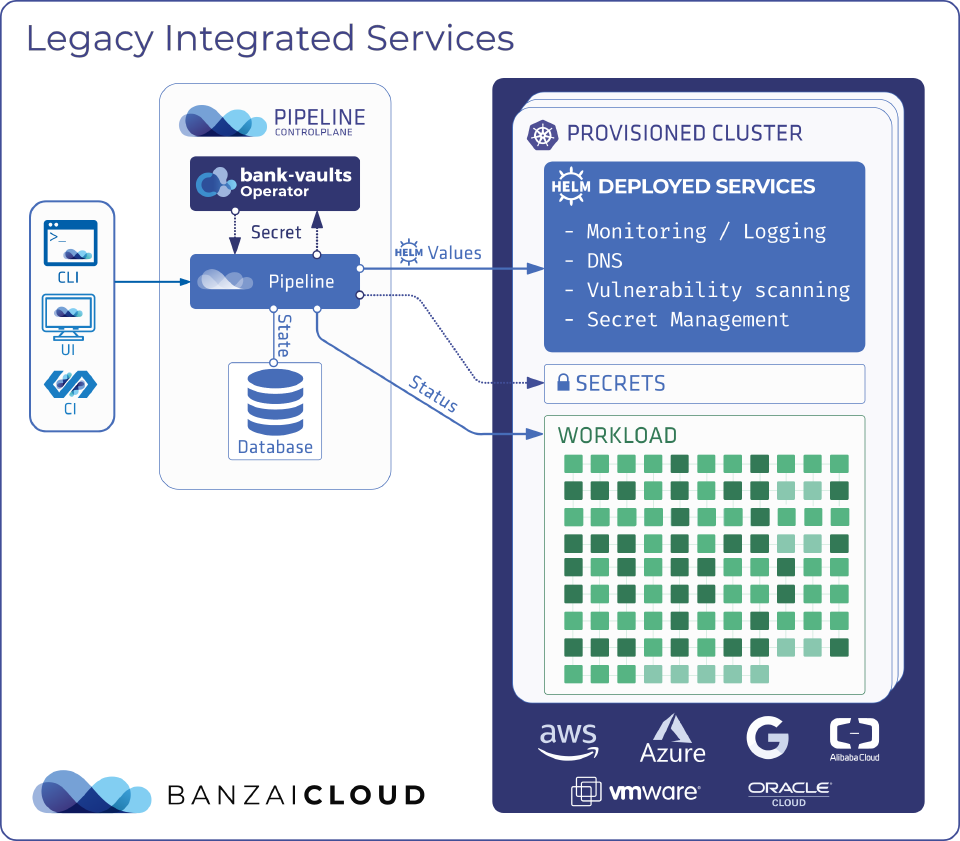
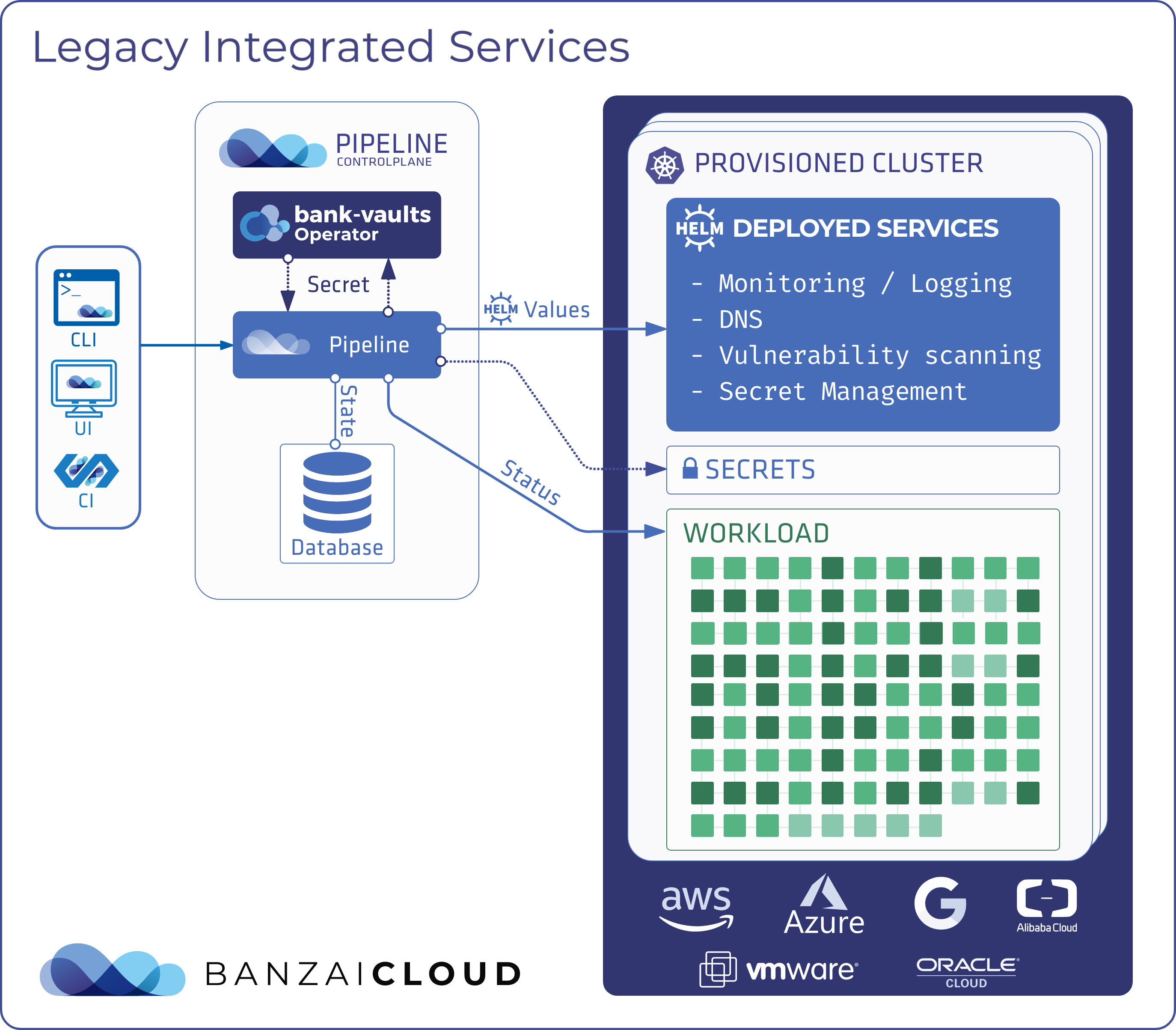
The current architecture and features have served us well, but there are a few shortcomings we’ve been wanting to address.
Spec and defaulting 🔗︎
There are two levels of configuration for Integrated Services. The Pipeline API-level config, which we call the spec, and the deployment-level config, which is typically a set of Helm chart values assembled from the spec with some additional defaults. Defaulting is good since it makes the spec much smaller and easier to understand for the user, but no single set of defaults will fit every use case. We need a way to let the user define and persist custom overrides if necessary, but, currently, that is not possible.
Tight coupling 🔗︎
The async workflow is tightly coupled to the actual service deployment implementation. Using Helm is beneficial, since we have ready to use packages, but the fact that we calculate the actual Helm chart values in Pipeline means that it cannot be compatible if the structure of values change between chart versions. We could extend the code to handle multiple chart versions and understand multiple values schemes, but that would require us to release Pipeline every time we wanted to add support for a new service version. Coupling goes the other way as well. Integrated Services code cannot be simply used on any Kubernetes cluster without that cluster being managed by Pipeline.
State management 🔗︎
Desired state of the Integrated Service (the “spec”) is kept in the database. Since there is nothing to reconcile this state automatically, we may end up with the spec drifting away from the actual state in the cluster, if someone updates resources in the background either intentionally or accidentally. Another problem to this approach is tight coupling, since services cannot be managed without Pipeline and its database.
Service versions 🔗︎
To avoid compatibility problems we decided to always update the service to the version pinned in the actual Pipeline release when the user initiates an action (activates, updates or deactivates a service). Since this is not automatic, we cannot guarantee that the user can upgrade cleanly if they happen to lag multiple versions behind.
Upgrade hooks and downgrades 🔗︎
Upgrades are not always as trivial as running the new version of the installer in place of the old one. Sometimes we have to remove or make changes in resources to be able to install a new version of a service. Cert manager for example, when upgrading from 0.13 to 0.14, requires users to remove its deployments. We also want to support downgrades, which may or may not be symmetric to their upgrade counterparts to complicate things even further.
Next Generation Integrated Services 🔗︎
How will the next generation of Integrated Services help to fix these issues? 🔗︎
The primary change that we are going to introduce is a clean separation of the Integrated Service configuration and deployment from the spec. We achieved this by introducing an external component - a Kubernetes operator - with the responsibility of understanding how to install the service based on a Custom Resource. The operator receives the desired service version, the service spec and the user’s custom overrides through a Custom Resource and automatically persists it without the need for it to be put it into the database.
This transition also means that Integrated Services will be able to work independently and be managed externally. Users can keep using Pipeline to provision their clusters across providers and manage integrated service definitions through Kubernetes Custom Resources while simultaneously using their favorite gitops tool like ArgoCD.
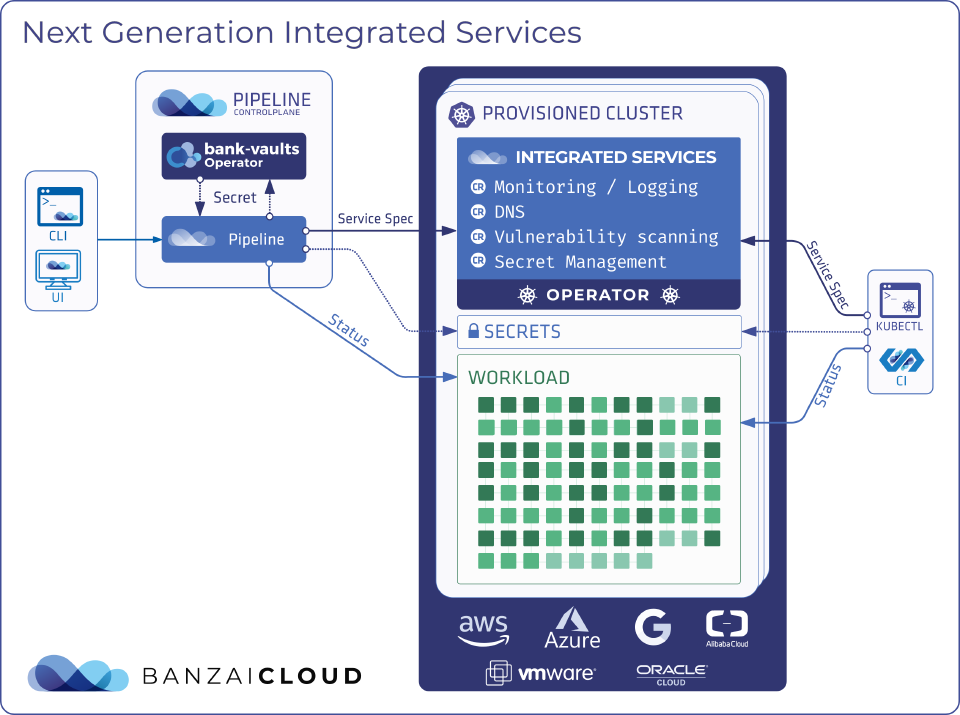

Integrated Service Operator 🔗︎
Let’s take a look at the operator to understand how it works, and more importantly, how it addresses the issues we’ve highlighted above.
Service Installation 🔗︎
The interaction with the operator is as follows: we create a resource that represents our service by specifying the name of the service and the operator will fill the available versions for us in the resource status.
We can now set the desired service version (or skip the previous step if we know what versions exist) and let the operator install it for us. We can track the progress through its resource status.
Service Upgrade 🔗︎
Upgrades are a bit more complicated since we might have to do specific things to get from version A to B. They can be as simple as patching existing resources or as complex as backing up a database and applying schema changes.
Another common problem is not being able to upgrade multiple versions in a single step, instead, we have to walk through intermediate versions. This makes sense since we don’t want to support single step upgrades from all legacy versions, and so simply rely on step-by-step upgrades.
Internally, our services have installers and upgraders:
- Installers know how to install a specific version of a service.
- Upgraders know how to transition from one version to another.
If we combine these, we can calculate the available target versions with all the required intermediates.
For example, with three installers - A, B, C - and two upgraders - A->B, B->C - we can upgrade from A to C in two steps, A->B->C.
Upgraders should support downgrades as well, which are very important in case we have to rollback a change.
But let’s get back to the interaction with the operator. Once a new operator comes out that understands newer service versions, it automatically updates all resource statuses with their new options. It also calculates the upgrade steps for each target version exposed in the resource status, so that we know what to expect when we select one of the targets.
Given all this, once we upgrade the operator on the cluster, all the services will automatically show up as upgradeable, in case there are new versions available.
The spec 🔗︎
So far we have learned about how we can control service versions, but another important aspect is how we manage the spec. To recap: the spec is the deployment configuration of our service that Pipeline validates and controls through the service’s Custom Resource. We can keep the schema of the spec stable, independently of how the underlying deployment configuration may change between service versions. Internally, the operator understands the spec and typically assembles chart values from it, which was previously the responsibility of Pipeline.
Secrets 🔗︎
Secrets are required for almost every service. Pipeline has its own abstraction to manage secrets. Behind the scenes, it actually uses Vault to keep them safe. But how can we transfer them to the operator? The way this currently works is that we copy the secrets required for the integrated services into the managed clusters as plain Kubernetes secrets and provide the secret name in the spec so that the operator can use it.
State management 🔗︎
There’s one last thing left worth understanding, which is how this will fix the state management and consistency issue mentioned previously. This is not without its tradeoffs, but given that we can set the spec directly on the Custom Resource and read the status from there, we don’t need to put anything into the database anymore. The managed cluster is authoritative from this point on, and a comprehensive cluster backup and restore solution should handle Integrated Services just fine, without any extra effort.
Summary 🔗︎
The next generation of Integrated Services leverages Kubernetes Custom Resource Definitions to give control to users if and when they need it. By opening up a Kubernetes native interface for these services, Pipeline can focus on high level abstraction and configuration without being tied too much to actual implementation.