One of the key features of Pipeline, our hybrid cloud container management platform, is its ability to provision Kubernetes clusters across multiple different cloud providers (Azure, Amazon, Google), private datacenters (vmWare, baremetal, etc), or any combination thereof. It does this by using either cloud provider-managed Kubernetes, or our own CNCF certified Kubernetes distribution - PKE.
Each cloud provider’s internal LB is different, and so is the way each is integrated with Kubernetes. However, we strive to apply the same level of automation and core ideas that power the Pipeline platform across our supported cloud providers, though this post will focus on Microsoft Azure’s cloud.
Interestingly enough, when it comes to Azure, most of our customers, or the users of Pipeline’s free developer version, end up using our own distributions instead of AKS. We’ve already blogged about some of the reasons for this in our Deploying Pipeline Kubernetes Engine (PKE) on Azure post. But, since then, the number of reasons has grown to include:
- Heterogeneous clusters with highly available nodes through the utilization of virtual machine scale sets
- Highly available load balancer support capable of handling the worker nodes of large clusters through the use of a Standard Azure LoadBalancer, which is zone-redundant and provides cross-zone load balancing
- Infrastructure resources stored in a single resource group that the user can control
As the adoption of PKE on Azure increased, so did the variety of our customers and the complexity of their requirements. Many of them had to comply with all sorts of regulations, and new requirements frequently arose, one of which was to run PKE Kubernetes clusters in a way that was isolated from the public Internet. This entailed the Kubernetes API master being reachable only on a private address, and, similarly, workloads being run on a cluster exposed only through private addresses. In such environments, centrally managed ARM policies that prohibit the creation of public IPs are not uncommon. Not having a public IP made it a challenge to provide the Kubernetes master and worker nodes with outbound connectivity to the internet.
Before we get into the nitty gritty of how to solve this problem, how Pipeline can deploy a private PKE cluster into an Azure resource group where the creation of a public IP is blocked by an ARM policy, let’s take a look at how Azure typically provides outbound connectivity.
Outbound connectivity on Azure 🔗︎
Azure currently provides VM instances with three different methods of outbound connectivity:
1: VMs with a public IP 🔗︎
VMs that have public IPs assigned to them can access the internet out-of-the-box. These VMs use their public IPs for all outbound flows, and this method of achieving outbound connectivity takes precedence over all others.
2: Load-balanced VMs without a public IP 🔗︎
Here, VMs are part of the backend pool of a public Basic or Standard Load Balancer. Rules have to be configured on the Load Balancer so as to link the backend pool to one of the Balancer’s public frontends. When the load-balanced VM creates an outbound flow, Azure translates the private IP address of the outbound flow to the public IP address of the public Load Balancer frontend. This is how outbound connectivity works for Load-balanced VMs without a public IP. It’s important to mention here that this behaviour is different when the Load Balancer is an internal Standard Load Balancer. Load-balanced VMs behind an internal Standard Load Balancer receive no outbound connectivity through their Balancer, and, according to Azure documentation, in that situation it’s recommended that you set up a separate, public Load Balancer with rules that allow only outbound connectivity.
3: VMs without a public IP address 🔗︎
Some VMs without public IP addresses are not part of a public Load Balancer or an internal Standard Load Balancer backend pool. When such a VM creates an outbound flow, Azure translates the private IP of the outbound flow to a public address, but the public IP that is used for this outbound flow does not belong to you and cannot be reserved. If the VM is recreated, the previously used public IP will be released and a new one will be requested. Load-balanced VMs behind an internal Basic Load Balancer behave in the same way.
These three different methods can be combined for outbound connectivity. When all are used, the order of precedence is: 1: VMs with a public IP -> 2: Load-balanced VMs without a public IP -> 3: VMs without a public IP address.
The outbound connectivity challenge 🔗︎
Pipeline takes care of setting up PKE cluster infrastructure on Azure. By default, it creates the infrastructure components necessary to set up a public cluster. The user can then fine-tune the infrastructure provisioned by Pipeline so that they choose:
- Whether access points are
publicorprivate. Pipeline then creates the appropriate type of cloud provider-specific Load Balancer for these access points (e.g. a public Load Balancer for public access points, an internal Load Balancer for private access points). - And which access points the API server is exposed through. This allows the user to select whether the API server is reachable through public or private or both types of access points.
When creating a private PKE cluster, the user will tell Pipeline to create a single, private access point and to expose the API server exclusively through that access point.
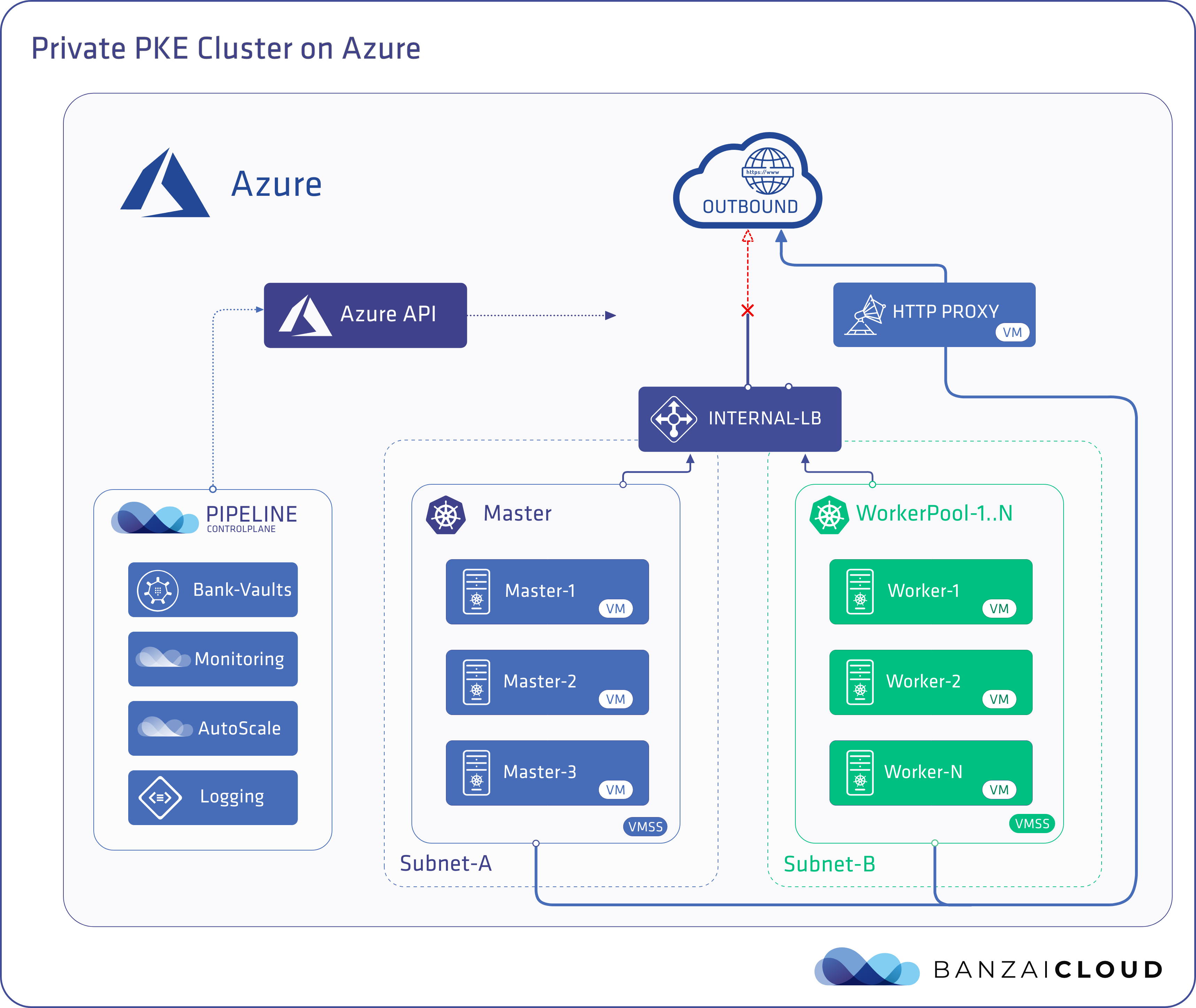
During that setup, Pipeline will provision the following infrastructure resources on Azure:
- An Internal Standard Load Balancer, which the API server is exposed through on a private IP address. Master and worker nodes are placed into Load Balancer backend pools and the appropriate inbound rules are configured for the master nodes. Kubernetes will set up additional inbound rules and frontend IP configurations, on demand, for load balancer-type Kubernetes services and worker nodes. Note, a Standard Load Balancer is used instead of a Basic Load Balancer, since Standard Balancers provide multizone redundancy and support multiple virtual machine scale sets.
- Virtual machine scale sets are used to spawn both master and worker nodes without a public IP. These virtual machine scale sets support multizone VMs and make possible the creation of scalable heterogeneous clusters.
Master and worker nodes will still need outbound connectivity to be able to download PKE packages. This can accomplished with our air-gapped PKE setup and private registry. However, some customers may need to run workloads on clusters that connect to third party external services. These will still require some outbound connectivity.
Since an Internal Standard Load Balancer is used to meet the HA and scalability requirements of our customers, we hit on the idea of not having outbound connectivity as described in 2: Load-balanced VMs without a public IP. Remember that the creation of public IPs is blocked through ARM policies, so provisioning a separate public Load Balancer to provide outbound connectivity as the Azure documentation suggests won’t help; a public Load Balancer requires a public IP.
Pipeline solves this by employing an HTTP Proxy hosted on a VM with no public IP. This VM has outbound connectivity through the third method we discussed, 3: VMs without a public IP address. Pipeline configures the master and worker nodes of the PKE cluster to use this HTTP Proxy server and thereby achieve outbound connectivity. The credentials needed to access that HTTP Proxy are securely stored by Pipeline in Vault, and managed by our Bank-Vault Vault operator and webhook.
This method of having the master and worker nodes go through a pre-configured Proxy has been well recived by our customers. It provides them with additional capabilities like bandwidth control, an internet web filter, a web cache, an audit log, and security control (just to name a few).
Load Balancer-type services 🔗︎
Load Balancer-type services are used to expose services externally. Kubernetes includes a Controller which is responsible for creating a Load Balancer on the cloud provider side, and for configuring the rules responsible for directing traffic from the cloud provider’s Balancer to the appropriate Pods. This Controller is implemented for each cloud provider with Kubernetes integration. The Azure specific Controller creates a public Load Balancer, by default, if it can’t find one with the same name as the cluster in the resource group in which the cluster resides (in future Kubernetes versions, the name of the Load Balancer will be configurable and will have the capability of being different from the name of the cluster).
This process will fail if the creation of a public IP is blocked by an ARM policy, because the Load Balancer-type Kubernetes service will never receive a public IP. The controller has to be instructed to use an internal Load Balancer instead of a public one. This can be done by adding the appropriate annotation.
To ease user experience, we developed a mutating webhook that applies annotations to Kubernetes services automatically at time of deployment.
We use admission webhooks in various places. Check out these posts to learn more about where and how.
Our webhook is designed to anticipate a configuration file with a set of rules, each rule specifying a label selector for selecting Kubernetes services and a list of annotations to be applied to those selected services.
Here’s an example rule that applies the service.beta.kubernetes.io/azure-load-balancer-internal annotation to services identified by a label selector:
- selector:
app: http-service
annotations:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"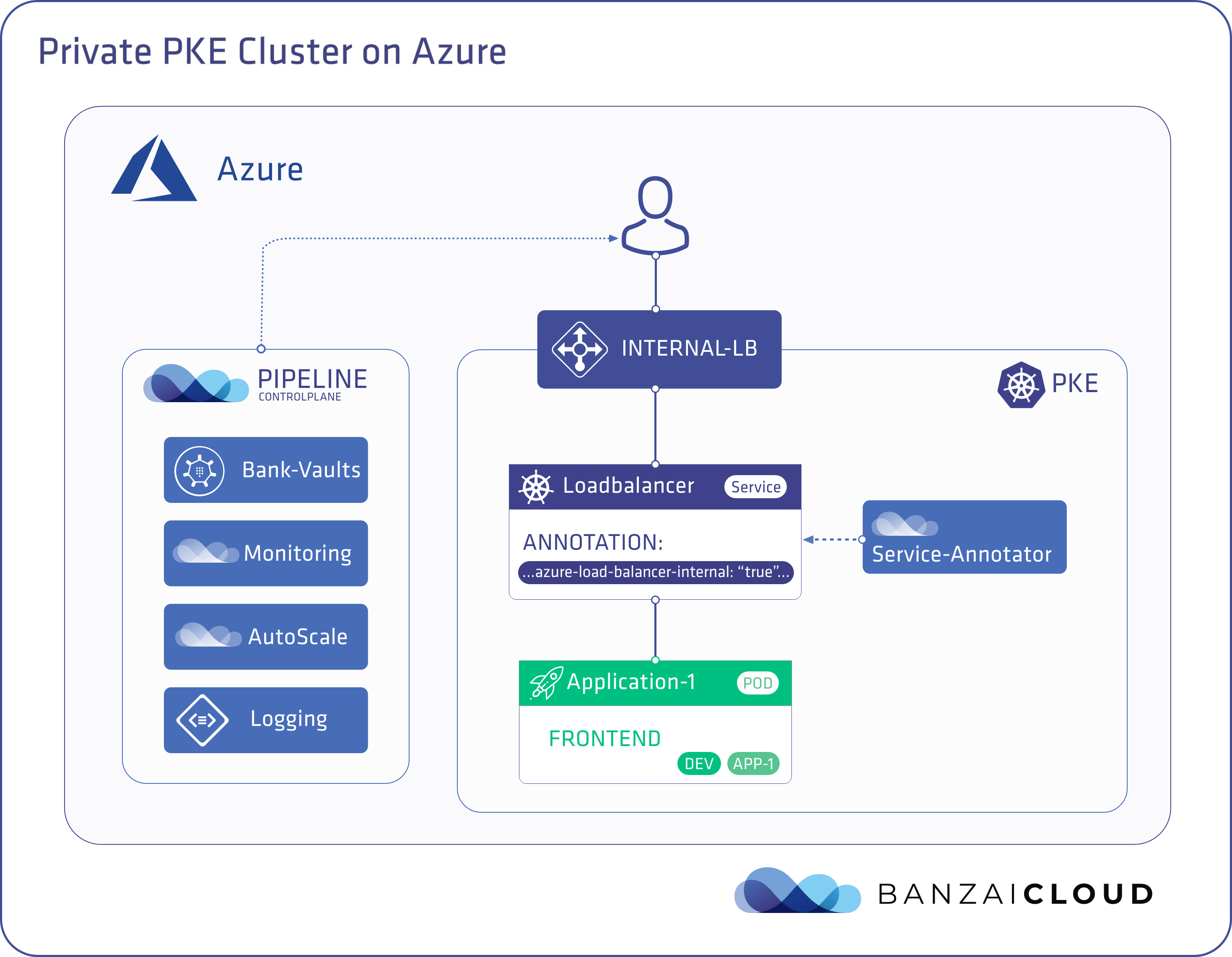
Conclusion 🔗︎
The use of a Proxy to solve this problem is not restricted to the Azure environment. Instead, this is a generic solution that works in a variety of environments. At the same time, we recognize that this solution may not fit all possible environments, so we’ll be continuously developing new capabilities in our efforts to support customers in the challenges they face. If you’d like to give it a try, check out the hosted free developer version of Pipeline or get in touch with us directly.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.