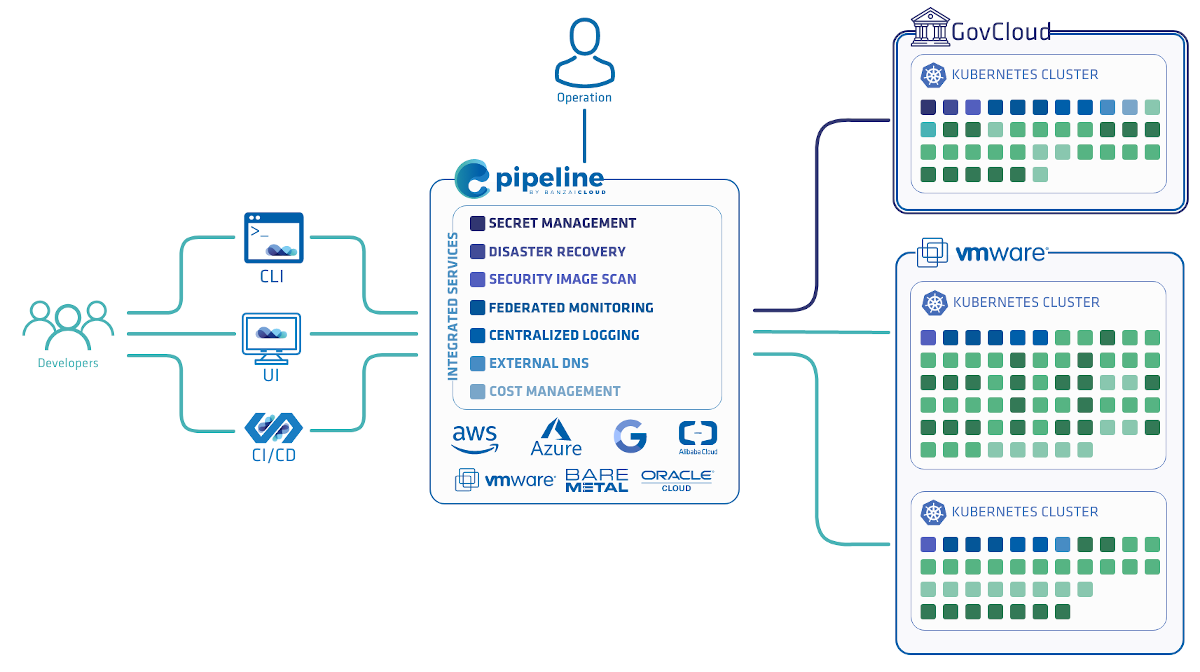
One of the main features of the Banzai Cloud Pipeline platform is that it allows enterprises to run workloads cost effectively by mixing spot or preemptible instances with regular ones, without sacrificing overall reliability. The platform allows enterprises to develop, deploy and scale container-based applications and it leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive yet flexible environment for developers and operation teams alike.
tl;dr 🔗︎
The Banzai Cloud Pipeline platform switched to a unified, cloud-aware spot instance termination handler to properly drain the cluster node and provide information to the monitoring system if an instance is going to be preempted from a cluster nodepool. This information (alongside spot prices and market capacity metrics) is used by the other parts of the platform to predict, replace or automatically maintain the desired cluster node size.
Spot instances 🔗︎
In order to constantly provide the elasticity of on-demand instances, cloud providers must maintain a huge infrastructure with a lot of unused capacity. To put this capacity into work providers make those resources available for a lower price than the on-demand. However, they can reclaim these resources at any given moment due to higher priority demands.
At Amazon’s EC2 they called spot instances, at Google Cloud preemtible VMs and they are useful for fault-tolerant workloads, in which it doesn’t matter if (some of) the instances are terminated. It is very important to deploy a cluster with diversified instance types, and to manage the cluster lifecycle to keep the cluster available, even when a number of instances are preempted from the cluster.
Availability in spot-instance clusters 🔗︎
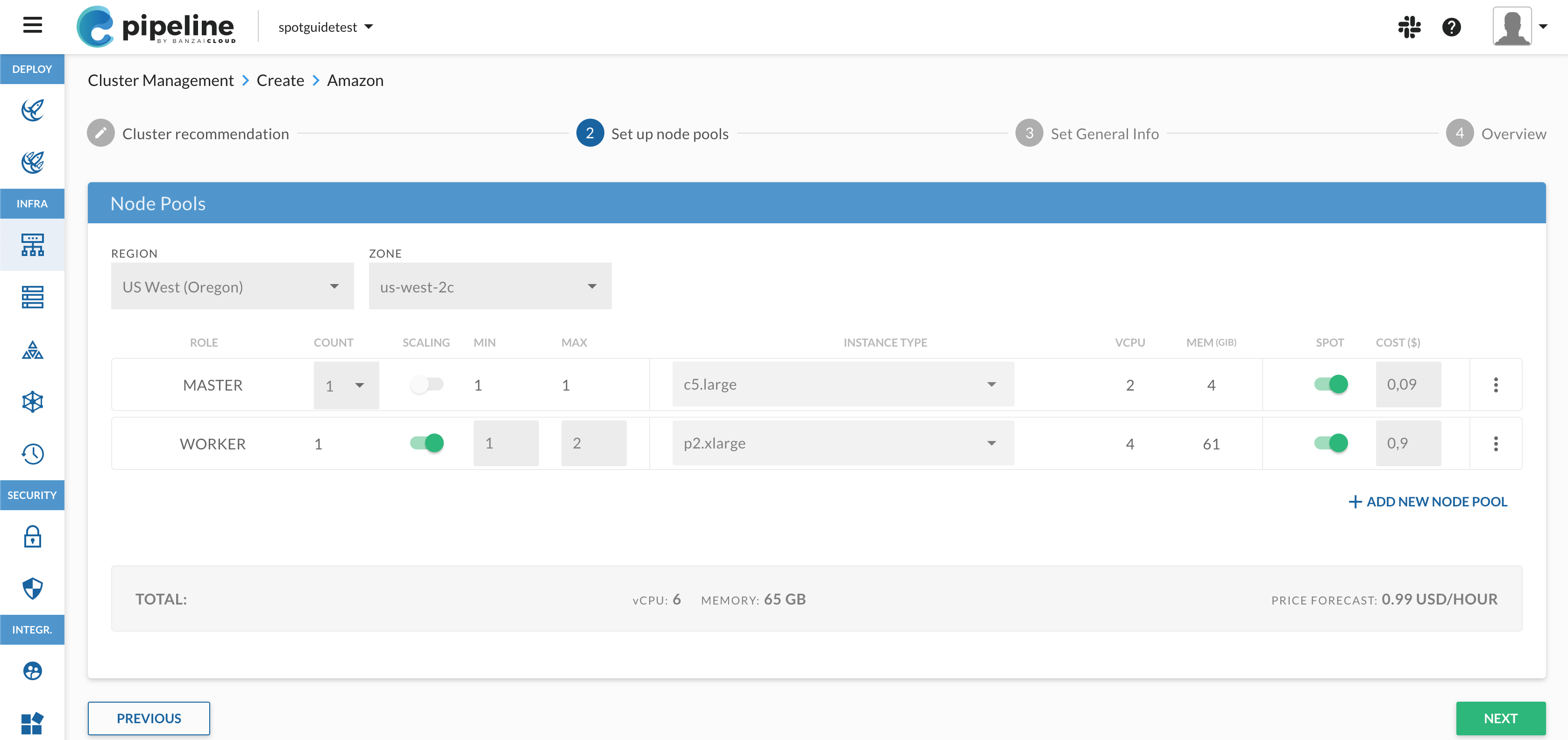
PKE (Pipeline Kubernetes Engine), EKS and GKE clusters started with Pipeline can have spot/preemptible and on-demand instances mixed. Such a cluster can be very volatile, instances - and therefore pods and deployments - can come and go, so it’s usually risky to run workloads or services on these type of clusters. However clusters started with Pipeline have some special watchguards and features that help achieve a higher availability while still benefiting from the lower cost of spot instances.
- Telescopes is used to recommend a diverse set of node pools. It is useful to decrease the chance of interruption of a large chunk of instances at once by mixing the instances in different spot-markets.
- Cloudinfo to supply up to date service and price details across 6 providers.
- Deployments are scheduled in the cluster to have a configurable/fixed percentege of replicas always on on-demand instances, so even in the case of a serious spot instance outage, the deployment remains available with a reduced number of replicas. This is achieved using a custom Banzai Cloud Kubernetes scheduler that takes node labels and specific pod annotations into account when running the predicates against nodes.
- Metrics about spot-related events are collected into a federated Prometheus through Pipeline and different exporters, fulfillment times or current market prices.
- Spot instance replacements are taken care of by Hollowtrees.
As seen about there is a high separation of concern - each open source components above can be used independently of each other within your projects - however they are glued together to provide these strong SLAs in the Banzai Cloud Pipeline platform.
We’ve already had some posts about Telescopes and Hollowtrees. Today we’ll focus on how we handle spot instance terminations.
Termination notices 🔗︎
The first step of dealing with vanishing nodes from a cluster is to detect the termination, hopefully before it actually happens. Fortunately both EC2 and GCP provides termination notices for instances that will be taken away by exposing that information on the internal instance metadata endpoint. EC2 gives notice 2 minutes before the instance shuts down, Google gives us only 30 seconds heads-up to handle the situation.
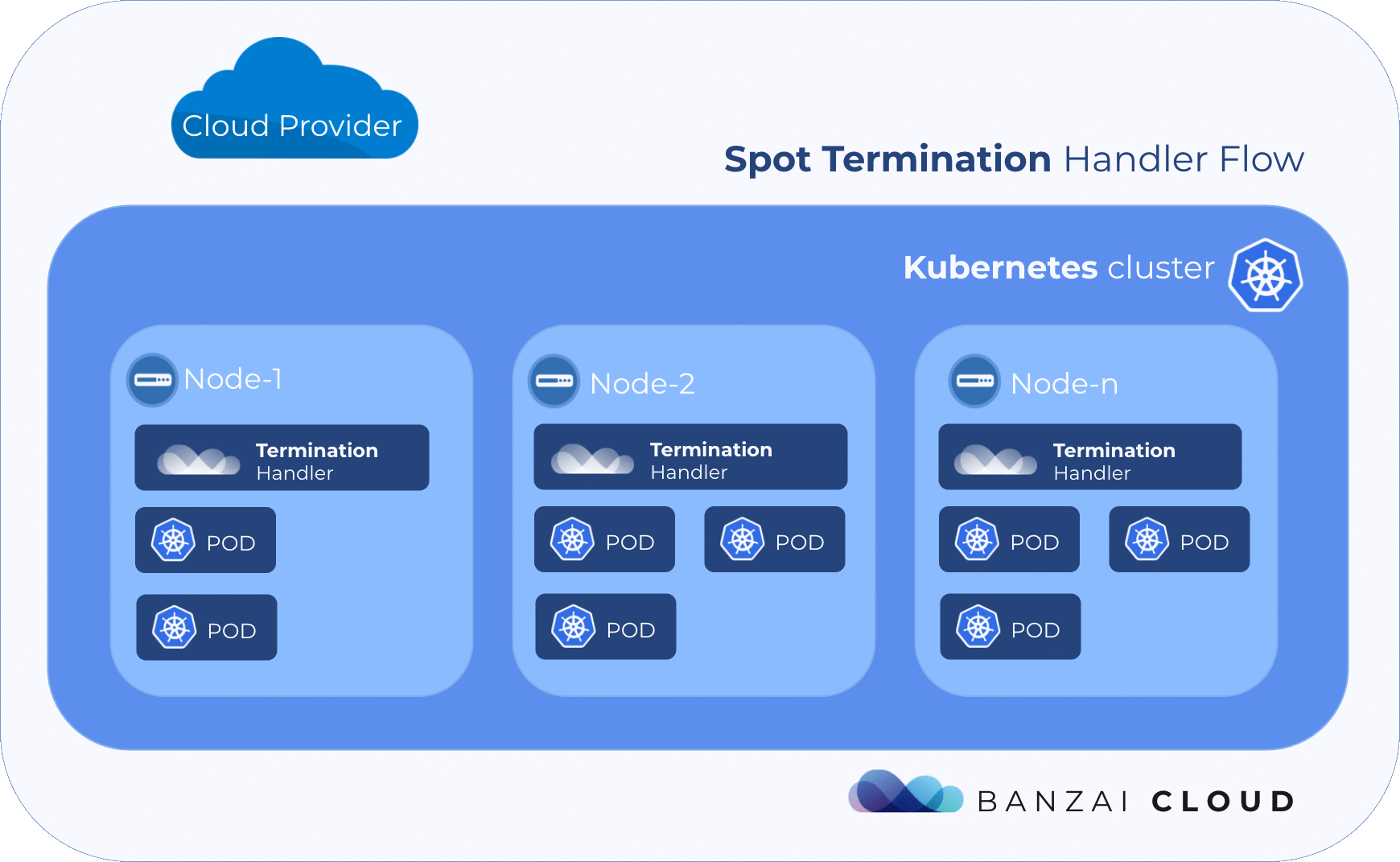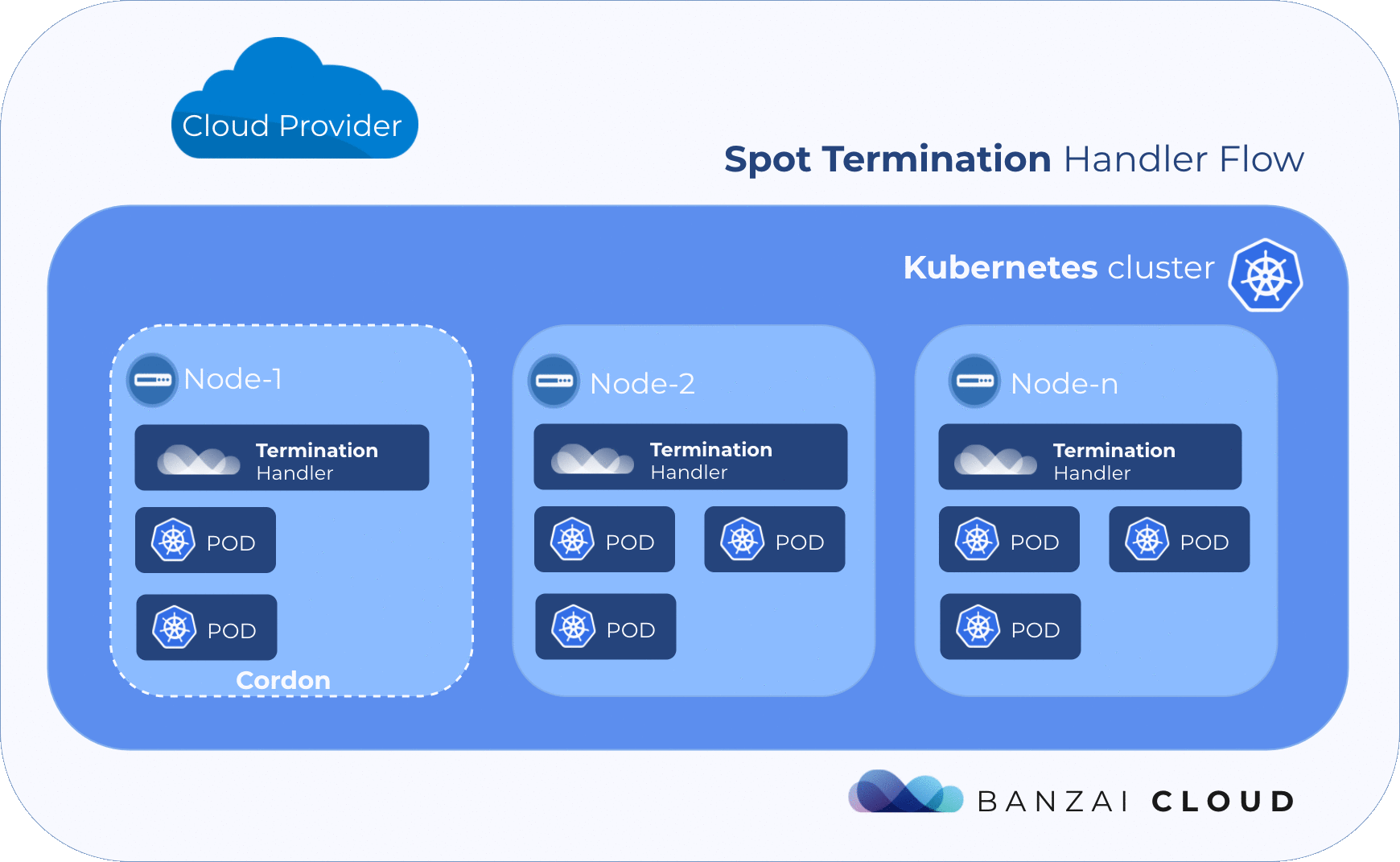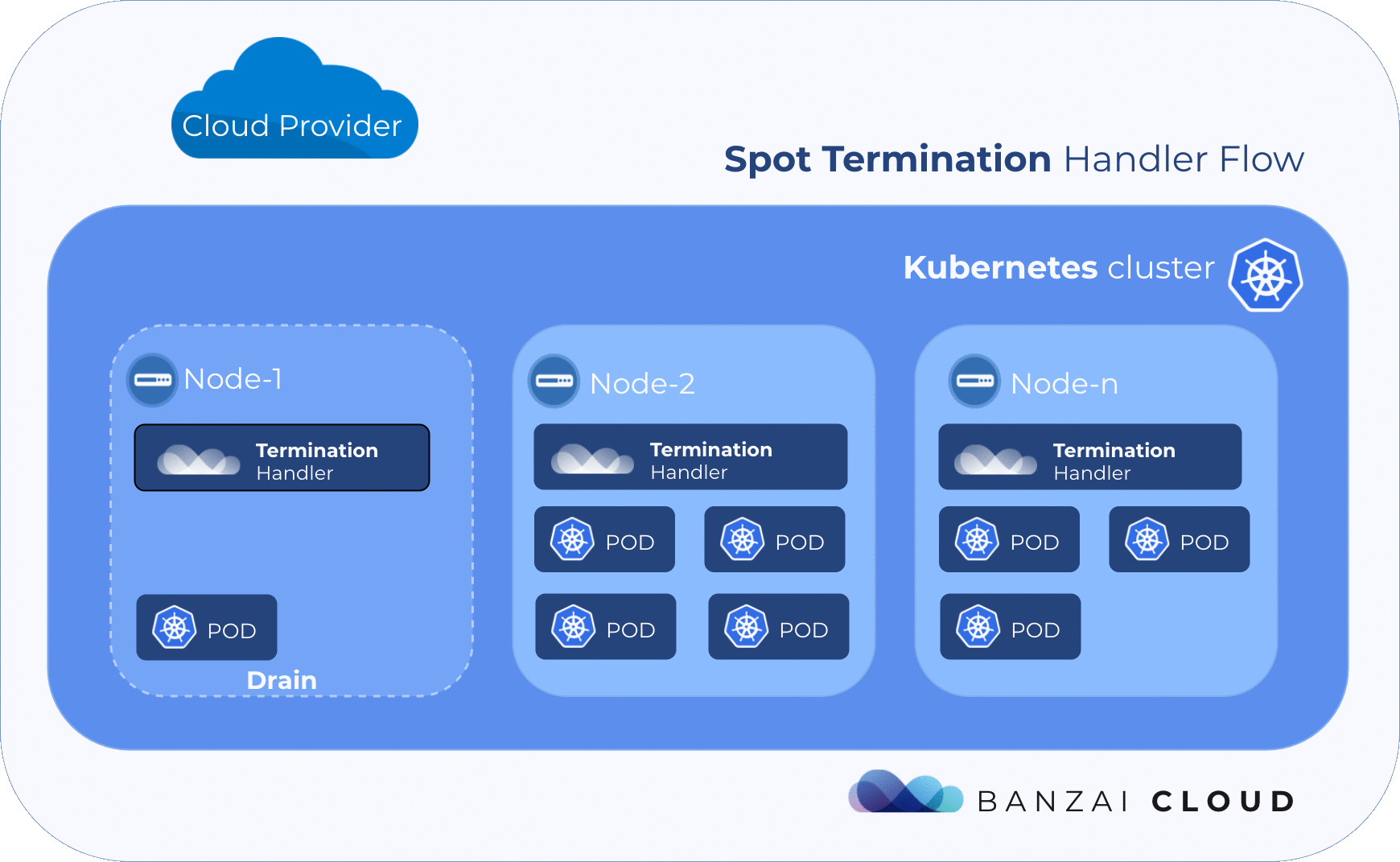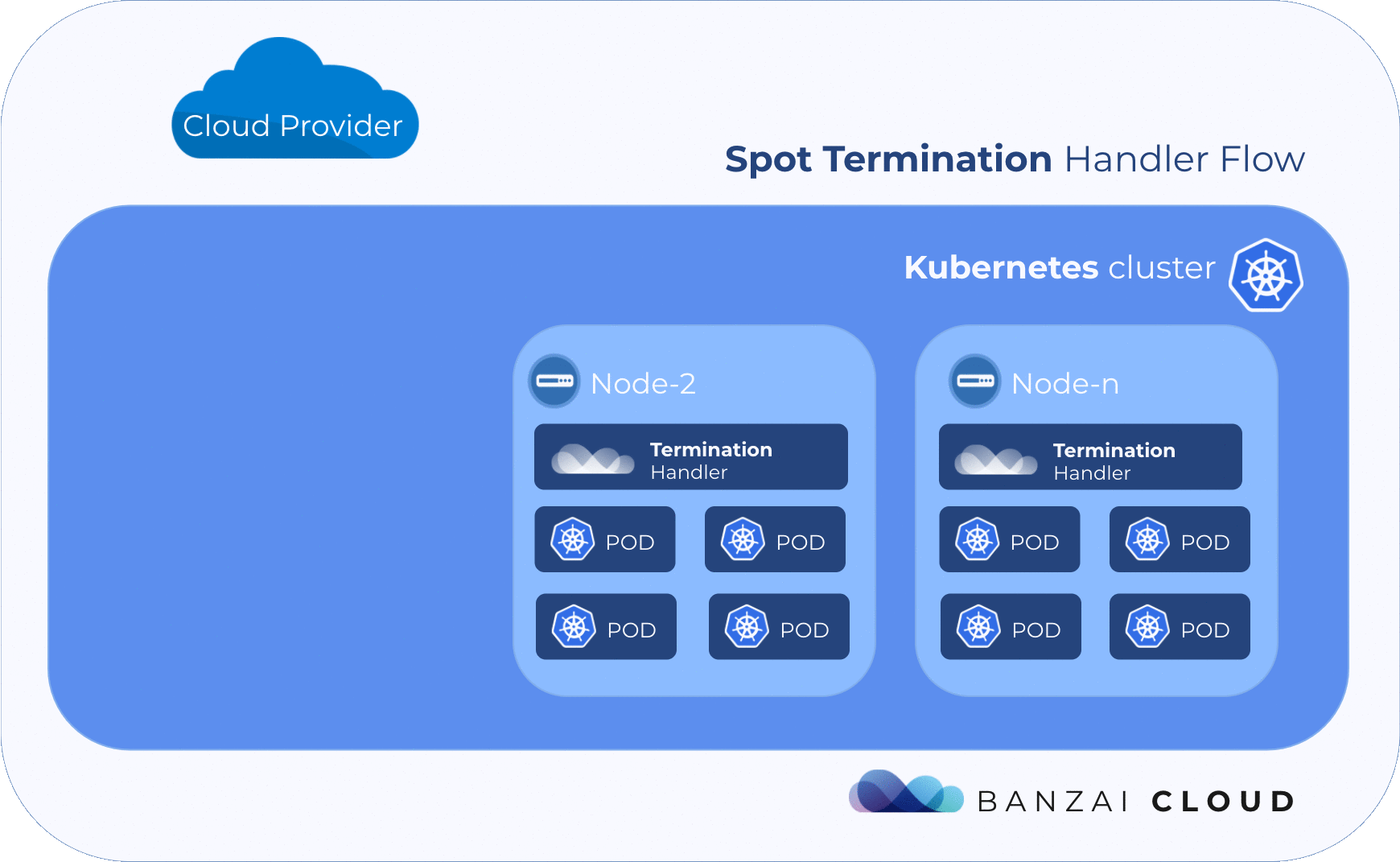
Spot Termination Handler 🔗︎
Kubernetes has built-in resiliency and fault toleration, which is a good fit for these instances. If a node is taken away, the Kubernetes cluster will survive, and the pods that were running on that node will be rescheduled to other nodes so life can go on.
However, it’s true that a cluster should be able to survive the loss of a node, but that can have some negative side effects. If there are unreplicated pods on a node that is taken away, its related services may be unavailable for awhile. Or, if there are application-level SLOs configured through a PodDisruptionBudget, they will not be taken into account. If a node is terminated without notice, the pods may not be terminated gracefully. The kubectl drain command is a good example of how to properly drain a node before it is taken away from the Kubernetes cluster, whether temporarily or permanently.
We created a unified cloud-aware solution to deal with the termination event. It leverages Satellite to determine the cloud provider it is running on. It is designed to run on every spot instance in the cluster and constantly watching for termination notices.
The purpose is twofold: provide Prometheus metrics about termination notices and cordon & drain the node it is running on when a termination notice is detected.
Let’s see what happens if a termination notices arrives 🔗︎
1time="2018-12-17T00:20:10Z" level=info msg="spot termination handler started" provider=amazon
2time="2018-12-17T00:20:10Z" level=info msg="prometheus metric endpoint registered" endpoint=/metrics plugin=prometheus-metrics
3time="2018-12-17T00:20:10Z" level=info msg="starting http server" port=":8081"
4time="2018-12-17T00:20:10Z" level=info msg="starting termination detector" plugin=termination-notifier provider=amazon
5time="2018-12-17T00:21:56Z" level=info msg="node termination notice arrived, draining with taint" instance=i-0d2aab13057917887 plugin=k8s-node-drainer
6time="2018-12-17T00:21:56Z" level=info msg="node cordoned successfully" node=ip-192-168-74-130.us-west-2.compute.internal plugin=k8s-node-drainer
7time="2018-12-17T00:21:57Z" level=info msg="node successfully tainted" node=ip-192-168-74-130.us-west-2.compute.internal plugin=k8s-node-drainerAs you can see in the log, when a termination notice is detected through the provider’s internal metadata the handler cordoned the node in the k8s cluster and tainted it with a specifiec taint with NoExecute effect, which basically instructed the Kubernetes scheduler to evict pods running on the node.
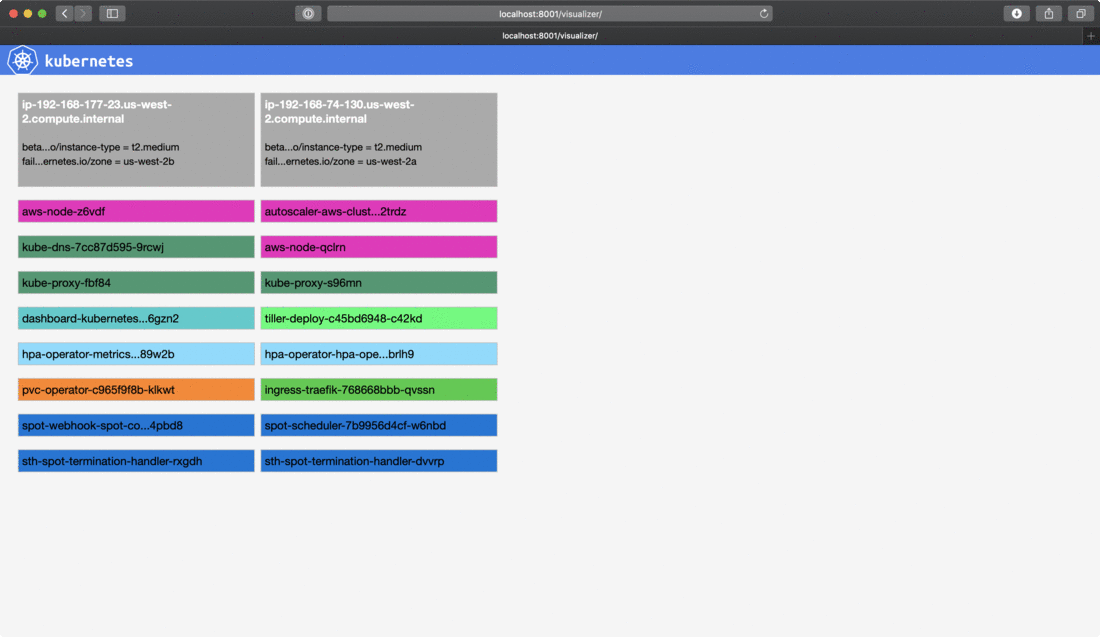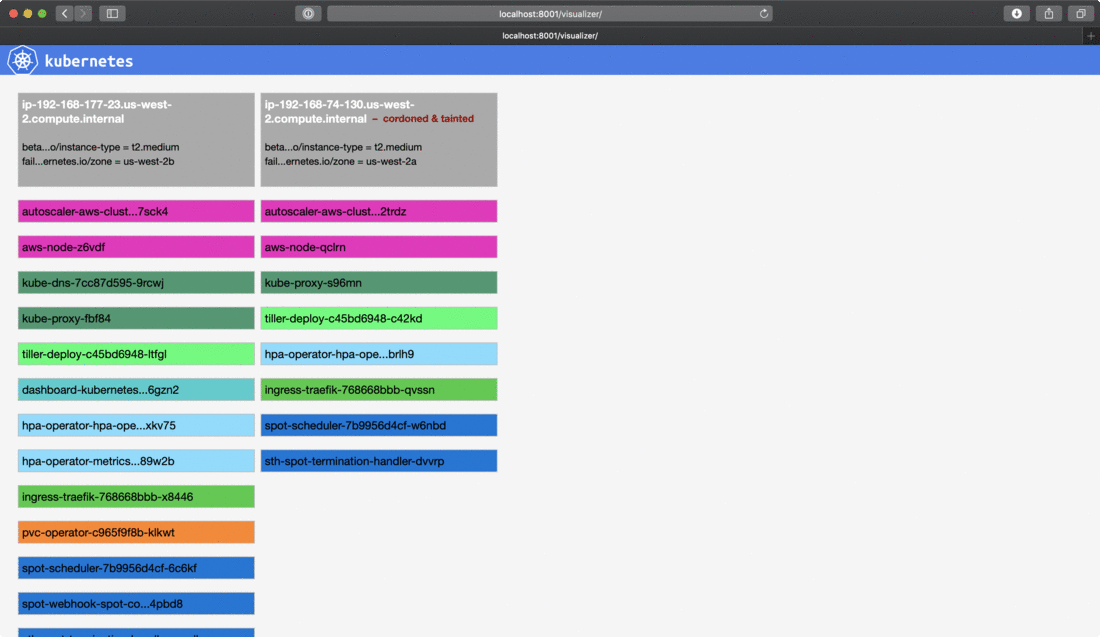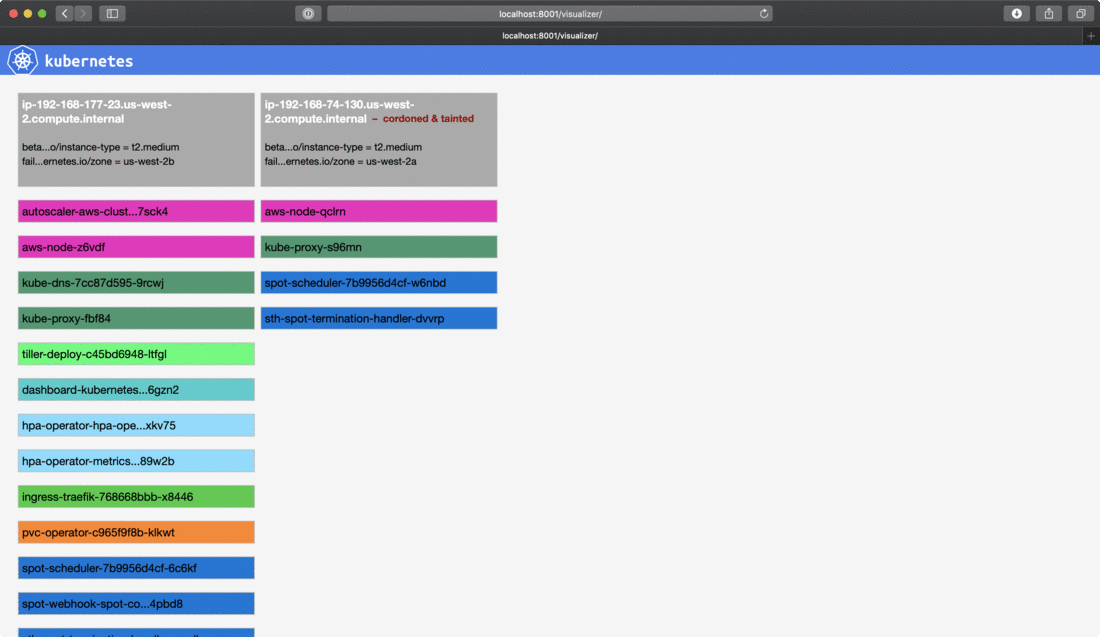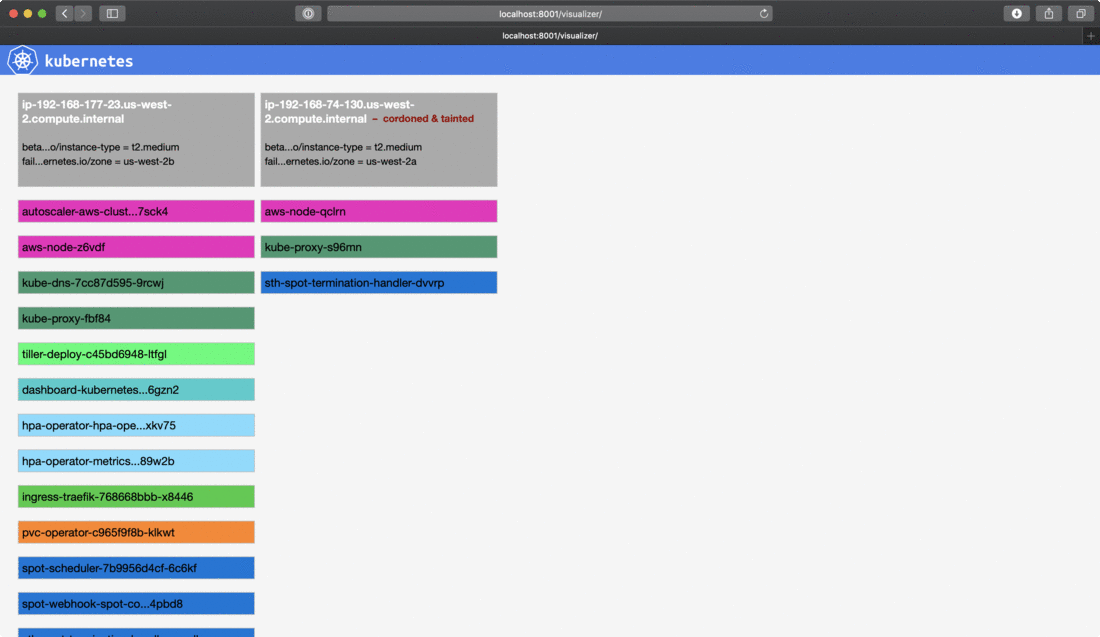
If you are interested what taints are, we already wrote a blog post about taints, tolerations and affinities a few weeks ago, and deep dive into how the Pipeline platform using these
The following metrics are exposed 🔗︎
# HELP sth_instance_metadata_service_available Metadata service available
# TYPE sth_instance_metadata_service_available gauge
sth_instance_metadata_service_available{instance_id="i-0d2aab13057917887"} 1
# HELP sth_instance_termination_imminent Instance is about to be terminated
# TYPE sth_instance_termination_imminent gauge
sth_instance_termination_imminent{action="",instance_id="i-0d2aab13057917887"} 1
# HELP sth_instance_termination_within_seconds Instance will be terminated within in seconds
# TYPE sth_instance_termination_within_seconds gauge
sth_instance_termination_within_seconds{action="",instance_id="i-0d2aab13057917887"} 56
The Prometheus metrics are propagated through Pipeline platform’s federated monitoring, which alerts Hollowtrees so it can take care of replacing the preempted node with other one(s) based on the current resource needs of the cluster and the current spot instance prices and availabilities of different instance types in different availability zones.