






Cloud cost management series:
Overspending in the cloud
Managing spot instance clusters on Kubernetes with Hollowtrees
Monitor AWS spot instance terminations
Diversifying AWS auto-scaling groups
Draining Kubernetes nodes
A few months ago we posted on this blog about overspending in the cloud. We discussed how difficult it is to keep track of the vast array of instance types and pricing options offered by cloud providers, especially on AWS with spot pricing. That means that companies often spend more in the cloud than necessary. So we’ve come up with a solution, the addition of a new component to the Pipeline infrastructure that helps select the ideal instance type for a job. First, we’ve added support for spot instance based clusters, wherein it is very difficult to discern the best cluster layout, one that’s simultaneously highly available (by having diverse instance types) and, on the other hand, still affordable.
Spot instances on AWS or preemptible ones on Google Cloud are useful for fault-tolerant workloads, in which it doesn’t matter if (some of) the instances are terminated. When using spot instances, it is very important to deploy a cluster with diversified instance types, and to manage the cluster lifecycle to keep the cluster available, even when a number of instances are subtracted from the cluster.
Once the recommended cluster is launched by Pipeline, Hollowtrees will make sure to keep that cluster safe from (spot and preemptible) instance terminations
If you’re not familiar with spot instances, make sure to read this blog post first, which recaps the lifecycle of spot instances and describes the different ways of requesting spot instances. Or, for an even more in-depth guide, read the corresponding part of the AWS documentation.
The Banzai Cloud cluster recommender, Telescopes is a standalone project in the Pipeline ecosystem. It is responsible for recommending a cluster layout consisting of node pools, but it won’t start instances on the cloud provider. It is up to the user to start the instance types and node pools that were returned in the response. Of course, Pipeline is integrated with Telescopes, and it is able to process that output and turn the recommended node pools into Kubernetes nodepools, and to start a cluster on that basis.
In this post we’ll cover the current API of the recommender and discuss some frequently asked questions about it.
Quick start 🔗︎
If you’d like to try out our cluster recommender, you should check out that project and run a go build.
There are different ways to configure the recommender, but it should work out of the box if it’s running with ./cluster-recommender.
You may want to enable debug logging to see what’s happening during the recommendation.
./cluster-recommender --help
Usage of ./cluster-recommender:
-listen-address string
The address to listen on for HTTP requests. (default ":9090")
-log-level string
log level (default "info")
-product-info-renewal-interval duration
Duration (in go syntax) between renewing the ec2 product info. Example: 2h30m (default 24h0m0s)
-prometheus-address string
http address of a Prometheus instance that has AWS spot price metrics via banzaicloud/spot-price-exporter. If empty, the recommender will use current spot prices queried directly from the AWS API.
API calls 🔗︎
POST: api/v1/recommender/:provider/:region/cluster 🔗︎
Currently, this is the only API endpoint supported by the project, and it returns a recommended cluster layout on a specific provider in a specific region, which contains on-demand and spot priced node pools. Recommendations are based on diversification and the assignation of price scores to the available instance types. For now, the recommendation notes the number of CPUs and amount of memory available in the instance types, but we’re planning to add support for different filters, like GPUs, I/O, and network performance.
Request parameters:
sumCpu: requested sum of CPUs in the cluster (approximately)
sumMem: requested sum of Memory in the cluster (approximately)
minNodes: minimum number of nodes in the cluster (optional)
maxNodes: maximum number of nodes in the cluster
onDemandPct: percentage of on-demand (regular) nodes in the cluster
zones: availability zones in the cluster - specifying multiple zones will result in the recommendation of a multi-zone cluster
sameSize: determines whether the resulting instance types should be similarly sized, or can be completely diverse
Example with cURL 🔗︎
curl -sX POST -d '{"provider":"ec2", "sumCpu": 100, "sumMem":200, "sumGpu":0, "minNodes":10, "maxNodes":30, "sameSize":true, "onDemandPct":30, "zones":[]}' "localhost:9092/api/v1/recommender/ec2/eu-west-1/cluster" | jq .
Sample response:
{
"Provider": "aws",
"zones": [
"eu-west-1a",
"eu-west-1b",
"eu-west-1c",
],
"NodePools": [
{
"VmType": {
"Type": "c5.xlarge",
"AvgPrice": 0.07325009009008994,
"OnDemandPrice": 0.19200000166893005,
"Cpus": 4,
"Mem": 8,
"Gpus": 0
},
"SumNodes": 8,
"VmClass": "regular"
},
{
"VmType": {
"Type": "m1.xlarge",
"AvgPrice": 0.03789999999999985,
"OnDemandPrice": 0.3790000081062317,
"Cpus": 4,
"Mem": 15,
"Gpus": 0
},
"SumNodes": 4,
"VmClass": "spot"
},
{
"VmType": {
"Type": "m2.2xlarge",
"AvgPrice": 0.05499999999999986,
"OnDemandPrice": 0.550000011920929,
"Cpus": 4,
"Mem": 34.20000076293945,
"Gpus": 0
},
"SumNodes": 4,
"VmClass": "spot"
},
{
"VmType": {
"Type": "m2.4xlarge",
"AvgPrice": 0.10999999999999972,
"OnDemandPrice": 1.100000023841858,
"Cpus": 8,
"Mem": 68.4000015258789,
"Gpus": 0
},
"SumNodes": 2,
"VmClass": "spot"
},
...
]
}
Connection to the Pipeline infrastructure 🔗︎
The recommender does not start VMs on any cloud provider, it only recommends a cluster layout with specific types. Pipeline is responsible for starting clusters with multiple node pools in the Banzai Cloud infrastructure. The Recommender API recommends a cluster setup in the Pipeline client (UI + CLI), and that recommendation can be customised by the client before sending a cluster create request.
But that’s only part of the bigger picture. After a properly diversified cluster is started, it must be maintained. Spot instances can be taken away by the cloud provider or their price can change, so the cluster may need to be modified while running. This work is done by Hollowtrees, which keeps spot instance based clusters stable over their entire lifecycle. If one or more spot instances are terminated, Hollowtrees will ask the recommender to find substitutes based on the current layout.
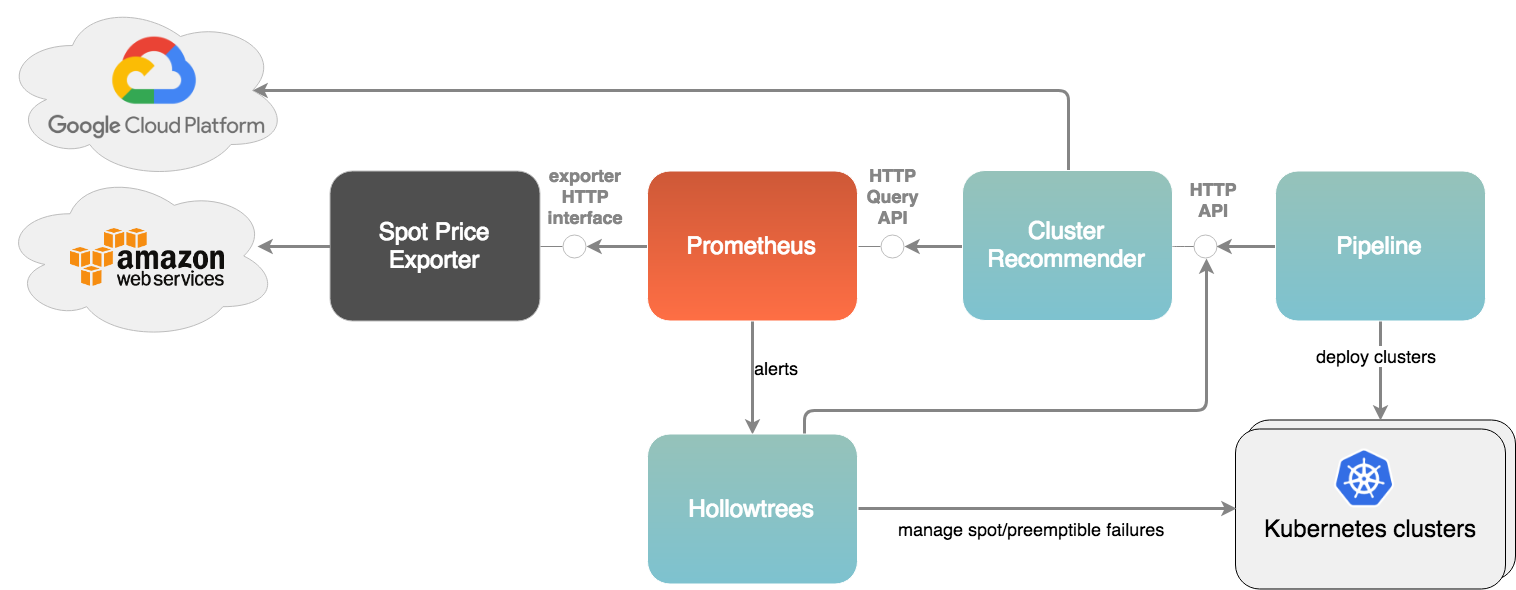
Note: there is now support for Google Cloud and Azure as well
FAQ 🔗︎
1. How do I configure my AWS credentials with the project?
This project uses standard AWS SDK for Go, so credentials can be configured via environment variables and shared credential files, or via AWS instance profiles. To learn more about configuring credentials, read the Specifying Credentials section of the SDK documentation.
2. Why do I see messages like DEBU[0001] Getting available instance types from AWS API. [region=ap-northeast-2, memory=0.5] when starting the recommender?
After the recommender starts, it takes ~2-3 minutes to cache all the product information (like instance types) from AWS.
AWS releases new instance types and regions quite frequently and occasionally changes on-demand pricing.
It is necessary to keep this info up-to-date without having to modify it manually every time something changes on the AWS side.
After the initial query, the recommender will parse this information from the AWS Pricing API once per day.
The frequency of this querying and caching is configurable in the -product-info-renewal-interval switch, and is set to 24h by default.
3. What happens if the recommender cannot cache AWS product info?
If caching fails, the recommender will try to reach the AWS Pricing List API on the fly whenever a request is sent, and will cache the resulting information. If that fails as well, the recommendation will return an error.
4. What kind of AWS permissions do I need to use?
The recommender queries the AWS Pricing API to keep up-to-date on info about instance types, regions and on-demand pricing. You’ll need IAM access as described here in example 11 in the AWS IAM docs.
If you don’t use Prometheus to track spot instance pricing, you’ll also need to be able to access the spot price history from the AWS API with your IAM user.
That means giving permission to ec2:DescribeSpotPriceHistory.
5. How are spot prices determined?
Spot prices can be queried from two different sources. You can use Prometheus with our spot price exporter configured, or you can use the recommender without Prometheus. If you select the latter, spot prices will be queried from the AWS API, which will be the basis of that recommendation.
6. What is the advantage of using Prometheus to determine spot prices?
Prometheus includes a time series database and is rapidly becoming the de-facto monitoring solution of the cloud native world.
When using the Banzai Cloud spot price exporter, spot price history is collected as time series data that
can be queried for averages, maximums and predictions.
It paints a more complete picture than, say, relying on a single spot price that can spike or dive.
You can fine tune your query with the -prometheus-query switch, if you want to change the way spot instance prices are scored.
Spot price averages from the last week are queried, and instance types are sorted, based on this score.
7. What happens if my Prometheus server cannot be reached, or if it doesn’t have the necessary spot price metrics?
If the recommender fails to reach the Prometheus query API, or it couldn’t find proper metrics, it will fall back to querying the current spot prices from the AWS API.
8. How is this project different from EC2 Spot Advisor and Spot Fleet?
The recommender is similar to the EC2 Spot Advisor. It also recommends different spot instance types for diverse clusters. But the EC2 Spot Advisor has no externally available API, is only available from the AWS Console, and only to create Spot Fleets. We wanted to build an independent solution wherein the recommendation would be used in a way that doesn’t require Spot Fleets. We’ve kept Kubernetes in mind - primarily while building our PaaS, Pipeline - and Kubernetes doesn’t support Spot Fleets out of the box for starting clusters (via Kubicorn, kops or any other tool) or for autoscaling. Instead, it uses standard Auto Scaling Groups for node pools, and that model fits our recommendations perfectly. We also wanted to include on-demand instances to keep some part of the cluster completely safe. And although EC2 is currently the only supported platform, we’d like to add support for Google Cloud and other providers as well.
9. Will this project start instances on my behalf on my cloud provider?
No, this project will never start instances. It only uses the cloud credentials to query region, instance type and pricing information. The API response is a cluster description built from node pools of different instance types. It is the responsibility of the user to start and manage autoscaling groups based on those responses. The Pipeline and Hollowtrees projects can help with that.
10. How does the recommender decide which instance types to include in the recommendation?
The recommender will list one node pool that contains on-demand (regular) instances. The instance type of the on-demand node pool is determined by price, the CPU/memory ratio, and the min/max cluster size in the request. For spot type node pools: all instance types in the region are assigned a price score based on Prometheus or AWS API info, and are then sorted by that score. Depending on the cluster’s size the first N types are returned. Then the number of instances is calculated so as to have pools of roughly equivalent size in terms of sum CPU/memory.
11. Why do I see node pools with SumNodes=0 in the recommendation?
Those instance types are the next best recommendations after node pools that contain instances in the response, but it’s not necessary to further diversify our cluster with them.
Because responses are only recommendations and won’t start instances on the cloud provider, it’s possible to fine tune those recommendations before creating a cluster.
That means a user can remove recommended node pools (e.g. they don’t want burstable instance types, like t2) and can add new ones.
If they want to add new node pools (e.g. instead of recommended ones), it makes sense for them to include one of the 0-sized node pools and to increase the node count from there.
12. How are availability zones handled?
Requested availability zones must be sent in the API request. When listing multiple zones, responses contain multi-zone recommendations, and all node pools in those responses are meant to span multiple zones. Having different node pools in different zones is not supported. Because spot prices may be different across availability zones, instance type price scores are averaged across those zones.
13. Is there a Google Cloud implementation?
Not yet, but we’re planning to release one in the near future.
14. If there’s no bid pricing on Google Cloud, what will the recommender take into account?
Even if there’s no bid pricing, Google Cloud can take your preemptible VMs away at any time, so it makes sense to diversify your node pools and minimize the risk of losing all your instances at once. Also, Google Cloud VM types are relatively complex - there are standard, high-memory, high-cpu instances in different sizes, as well as special VM types, like shared-core and custom machine types, not to mention GPUs - so it makes sense to have our recommendations take these things into account. Managing a long-running cluster built from preemptible instances is a difficult task, which we’re working on simplifying as part of the Hollowtrees project.
15. How is this project related to Pipeline?
Pipeline is able to start clusters with multiple node pools. This API is used in the Pipeline UI and CLI to recommend a cluster setup and to make it easy for a user to start a properly diversified spot instance based cluster. The recommender itself does not start instances, but is the responsibility of Pipeline. These recommendations can be customized on the UI and CLI before sending cluster create requests to Pipeline.
16. How is this project related to Hollowtrees
This project is only capable of recommending a static cluster layout that can be used to start a properly diversified spot cluster. After the cluster is started it still needs to be managed. Spot instances can be taken away by the cloud provider or their prices can change, so the cluster may need to be modified while running. This maintenance work is done by Hollowtrees, which keeps spot instance based clusters stable during their entire lifecycle. When some spot instances are taken away, Hollowtrees will ask the recommender to find substitutes based on the current layout.
17. What happens when the spot price of one of the instance types rises after my cluster has started running?
That’s beyond the scope of this project, but Hollowtrees is able to handle that situtation. Follow the link above, for more information.
18. Is this project production ready?
Not yet. To make this project production ready, we need the following:
- cover the code base with unit tests
- authentication on the API
- API validations
19. What’s on the project roadmap in the near future?
Our first priority is to stabilize the API and to make it production ready (see above). Other than that, these are the things we’re planning to add soon:
- GPU support
- filters for instance type I/O performance, network performance
- handle the sameSize switch to recommend similar types
- Google Cloud Preemptible instances
If you’d like to learn more about Banzai Cloud, check out our other posts on this blog, the Pipeline, Hollowtrees and Bank-Vaults projects.




