This is a copy of a guest post we published on the Hashicorp blog about how we use Vault with Kubernetes.
At Banzai Cloud, we’re building a feature rich platform as a service on Kubernetes, called Pipeline. With Pipeline, we provision large, multi-tenant Kubernetes clusters on all major cloud providers, such as AWS, GCP, Azure and BYOC, and deploy all kinds of predefined or ad-hoc workloads to these clusters. We needed a way for our users to log in and interact with protected endpoints and, at the same time, provide dynamic secrets management support, while simultaneously providing native Kubernetes support for all our applications. After several proof-of-concept experiments, we chose Hashi Corp Vault. In this post, we’d like to discuss how we use Vault, and provide technical insight into the options it provides us.
Pipeline API and Vault
Interactions with Pipeline occur primarily through a RESTful API (CLIs and UIs use the API). We decided to secure that API using OAuth2 with JWT bearer tokens. The main benefit of OAuth2 is that we don’t have to store user credentials, so users can use their existing accounts with their preferred provider. Also, JWT tokens are self-contained, allow stateless authentication, and access protected resources based on scopes. Nevertheless, these tokens don’t live forever and need to be revokable, be whitelisted, to work with Kubernetes, and to be capable of being pushed to different cloud providers in a multi-tenant way. For our use case, Vault was a perfect fit.
First of all, we use Vault’s Kubernetes Auth Method integration to authenticate Vault using a Kubernetes Service Account Token. Pipeline uses Vault to lease ServiceAccount JWT tokens, to enable all other applications running in the same Kubernetes cluster to call Vault, and to use tightly scoped tokens with various TTLs. These revokable and whitelisted tokens are stored in Vault’s Key/Value Secret Engine. Every time a user interacts with the Pipeline API, we check these tokens using Vault’s built-in cache, so performance is never affected.
In this particular scenario, we are storing OAuth2 JWT bearer tokens using the Key/Value Secret Engine, however, we also integrated, and are using, several other pluggable Vault engines: for Secret Engines we use Databases to generate the dynamic credentials, and SSH to dynamic SSH into hosts: for Auth Methods we use Kubernetes and GitHub.
For an overview of how we use Vault as a central component of our Auth flow, please check the diagram below.
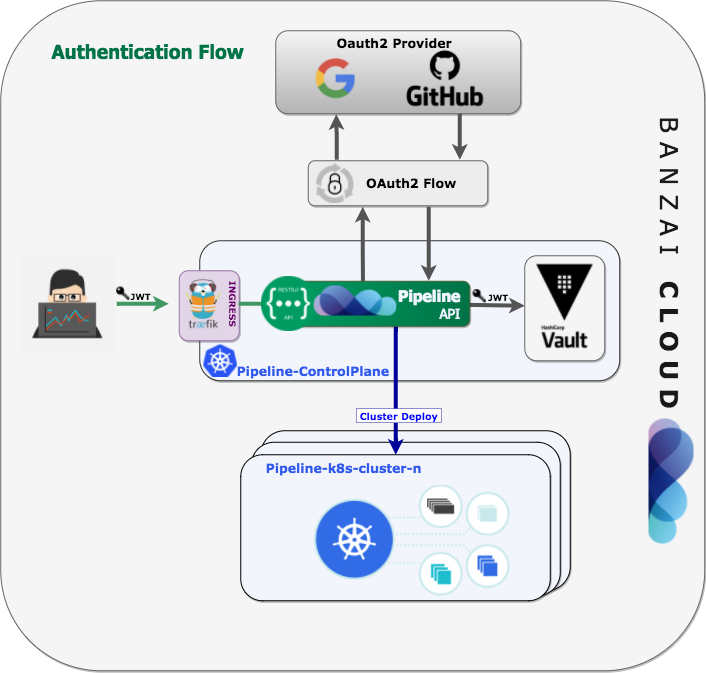
For further technical details on securing an API deployed to Kubernetes with Vault, read our post Authentication and authorization of Pipeline users with OAuth2 and Vault.
Dynamic credentials
Once the inbound API calls are secured using JWT Bearer tokens, lets see how Pipeline deploys applications to Kubernetes with credentials. These applications, and the cluster itself, are dynamic, scaled, removed, or re-scheduled based on different SLAs. One thing clustered applications usually have in common is that they interact with other applications to exchange (sensitive) data. For simplicity’s sake, lets look at this from the perspective of applications connecting to databases. Connecting to a database almost always requires passwords or certificates, so users must pass these to the application code through configurations. First and foremost, handling credentials manually and storing them in configurations or files is generally less secure. Second, we make a habit of educating, pushing end users towards more secure solutions in which they will never have to pass said credentials. All our deployments are orchestrated through Helm charts, and, unfortunately, we’ve often seen how credentials are generated or passed into charts during deployments.
Since Vault is already a core part of Pipeline, and Vault supports dynamic secrets, we’ve decided to make dynamic secrets an out-of-the-box solution for all our supported deployments. The advantages of using dynamic secrets are already described in Why We Need Dynamic Secrets, an excellent blog post by Armon Dadgar. In a nutshell, in order to harden security each application receives a dedicated credential for each requested service, this credential belongs only to the requesting application and has a fixed expiry time. Because the credential is dedicated, it is possible to track down which application accessed the service, and when. It is easy to revoke credentials, because they are centrally managed with Vault.
Since Pipeline runs on Kubernetes, we can apply Kubernetes Service Account-based authentication to get Vault tokens, which we can later exchange for a MySQL credential (username/password), based on our configured Vault role. See the following diagram for further details about this sequence of events:
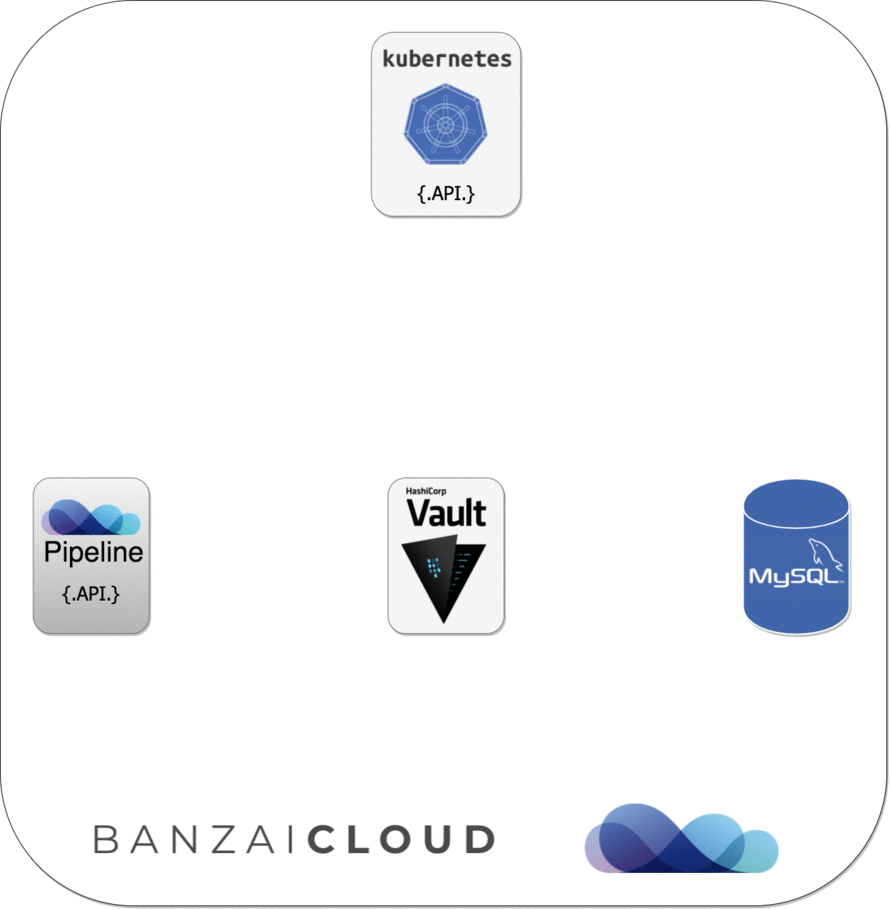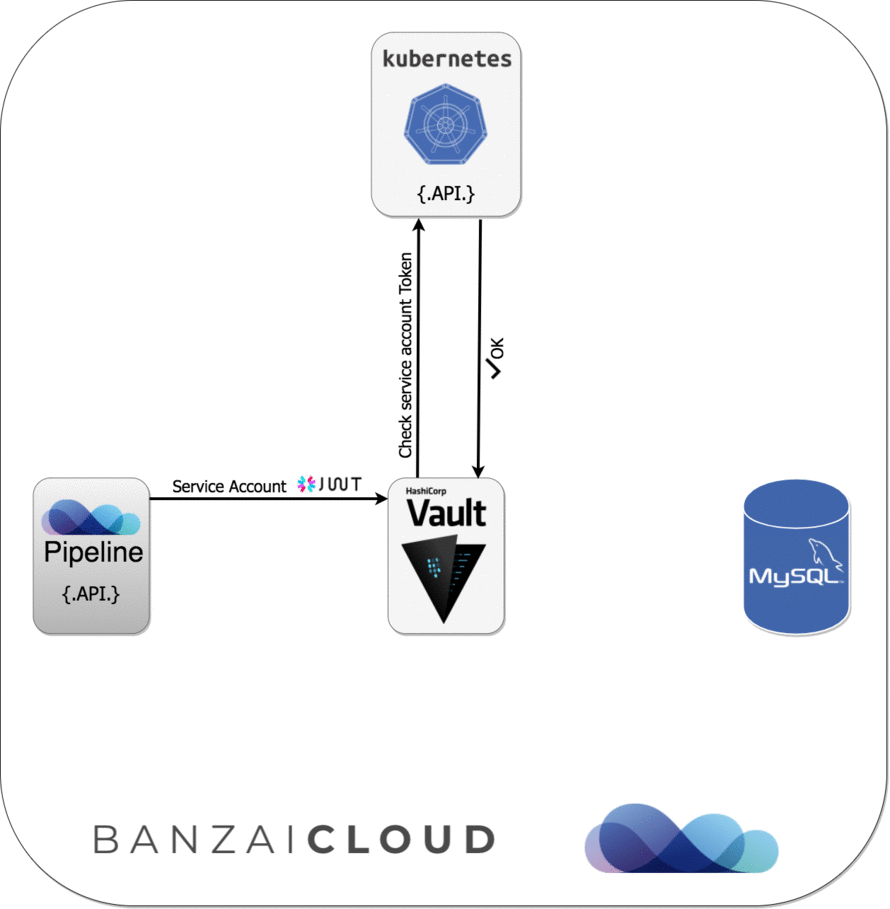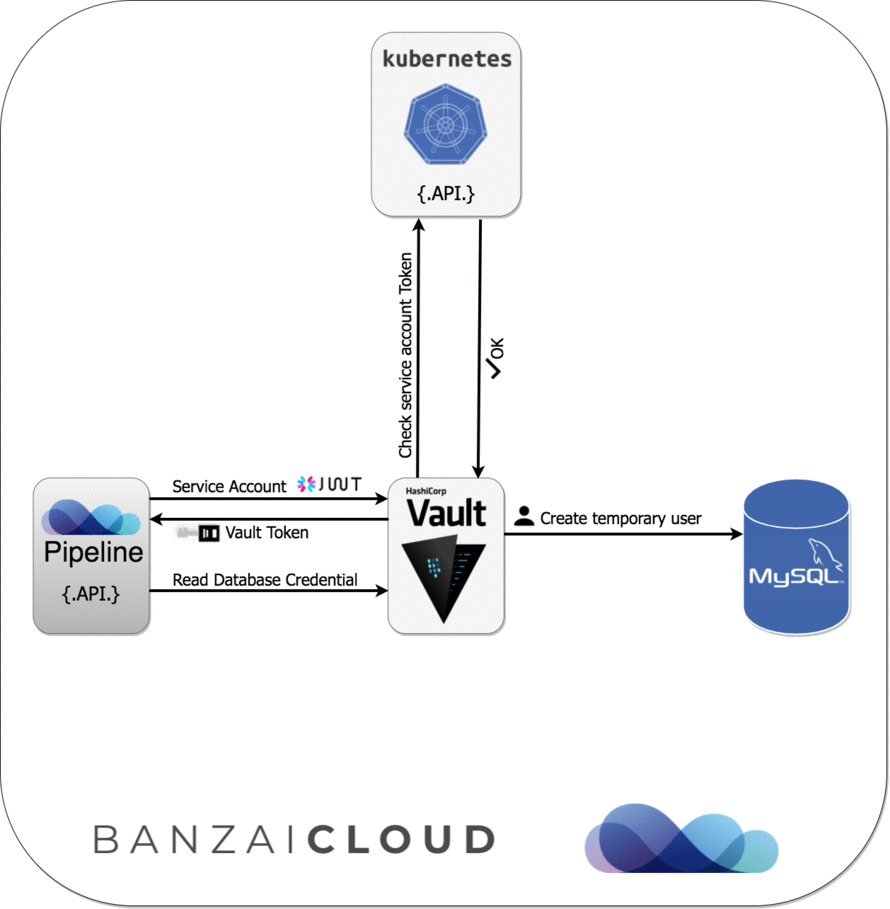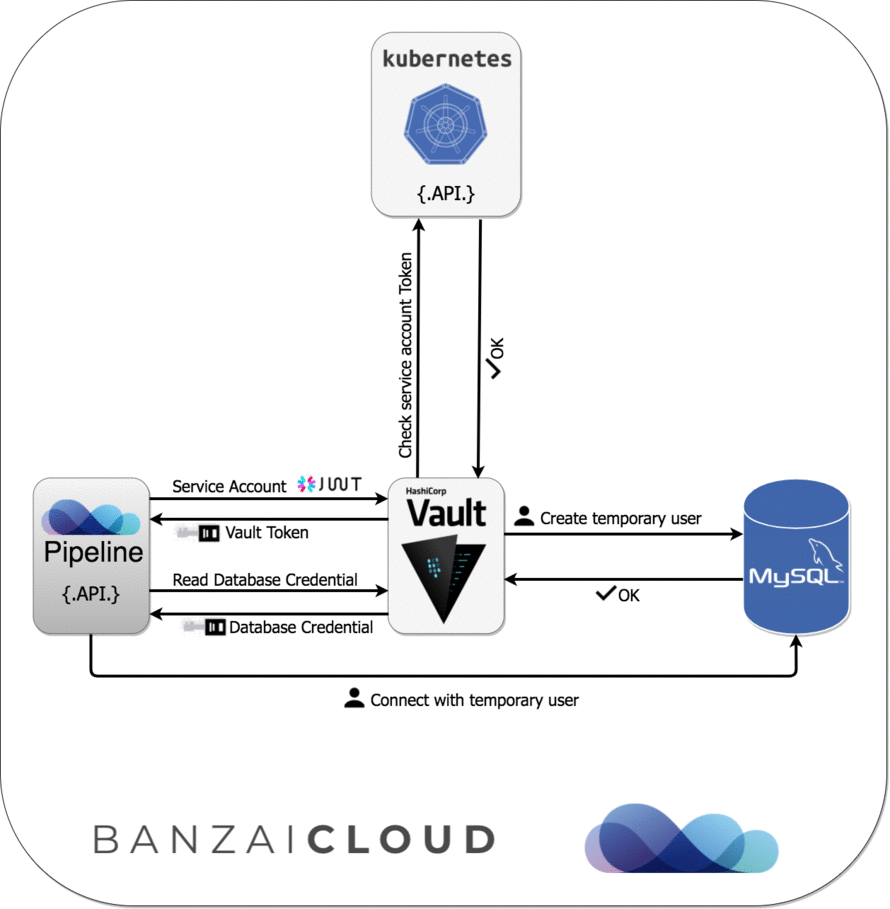
As you can see, Pipeline was able to connect to MySQL simply because it is running with the configured Kubernetes Service Account, and without being required to type a single username/password during the configuration of the application.
The code implementing the dynamic secret allocation for database connections and the Vault configuration described above can be found in our open source project, Bank-Vaults. For further technical details on how to use dynamic secrets for applications deployed to Kubernetes, check out this post.
Storing cloud provider credentials
Pipeline is built on Kubernetes and is cloud provider agnostic. We offer support for AWS, GKE and AKS (with more coming soon). In order to push K8s clusters and applications to the cloud, we need to perform a lot of cloud provider interactions using their APIs, for which we need certain cloud provider credentials and roles. This is a delicate matter, since end users have to trust that we’re storing these credentials in a safe way, while providing users with full control over when and how these credentials are revoked. We were not confident storing these credentials or roles in a database, so we decided to use a system specialized for storing secrets - again, hello Vault.
Dynamic SSH credentials
Once we push these applications to different providers, we’ll be providing full enterprise support for our end users. Again, note that these clusters are fully dynamic. Often, they are hybrid clusters and their underlying VMs change. The majority of the clusters we provision are based on spot or preemptible instances. Thus, changing VMs requires a high degree of dynamism. We have a system called Hollowtrees that securely runs spot instance-based Kubernetes clusters, through which we closely monitor the state of the spot instance markets. We react to spot instance terminations, and sometimes replace instances, by creating new instances with better price and stability characteristics. It’s not feasible, either for us and our customers, to have static SSH keys that access these clusters (especially when they can’t be dynamically revoked). At the same time, we need to access the VMs underneath Kubernetes for debugging purposes. Since many developers access them, and because VMs come and go all the time, we have to distribute access dynamically. For this purpose we decided to use Vault’s SSH Secret backend, which uses dynamic Client Key Signing to access remote VMs.
As you can see, Vault has several backends and engines already available. Using simple configurations and some code, most of the security features required by enterprises can be quickly implemented. To keep things concise and managable we’ll end this post here. However, we’ll keep on posting about how we seal and unseal Vault and a few other advanced scenarios in our forthcoming posts. Meanwhile please check out the open source code on our GitHub and make sure you go through our thorough tutorials and examples of how to use Vault.