






Security series:
Authentication and authorization of Pipeline users with OAuth2 and Vault Dynamic credentials with Vault using Kubernetes Service Accounts Dynamic SSH with Vault and Pipeline Secure Kubernetes Deployments with Vault and Pipeline Policy enforcement on K8s with Pipeline The Vault swiss-army knife The Banzai Cloud Vault Operator Vault unseal flow with KMS Kubernetes secret management with Pipeline Container vulnerability scans with Pipeline Kubernetes API proxy with Pipeline
Pipeline is quickly moving towards its as a Service milestone, after which the Pipeline PaaS will be available to early adopters and as a hosted service (current deployments are all self-hosted). The hosted version, like many PaaS offerings, will be a multitenant service. The resource and performance isolation of tenants will be handled by an underlying platform/core building block, Kubernetes (we’ll cover this topic in another post). In this blogpost we’re going to talk about authentication authn and authorization authz in Pipeline, and briefly touch on the topics of SSO as well as the security of internal Kubernetes cluster communications, using the same mechanisms.
Authentication using OAuth2 tokens 🔗︎
For Authentication we’re going to use OAuth2 by delegating user authentications to the service that hosts a user’s account. There are plenty of OAuth2 identity providers out there: GitHub, Google, Facebook, Azure Active Directory, Twitter and Salesforce are the largest. There is currently support for Pipeline in GitHub, mainly due to the fact that our CI/CD component is triggered by GitHub events, but we also use a very flexible QOR package that supports major providers as a plugin. Adding support for the providers listed above is a simple matter of making configuration changes (excepting changes to oldschool usernames/passwords). The main benefit of this solution is that we don’t have to store any user credentials and our users can use their existing accounts on these sites to access our service. The OAuth2 flow is laid out in the picture, below. When a user opens Pipeline, they have to log in with GitHub first, in order for a user record to be created in the RDBMS - the REST endpoint for that is: https://$HOST/auth/login.
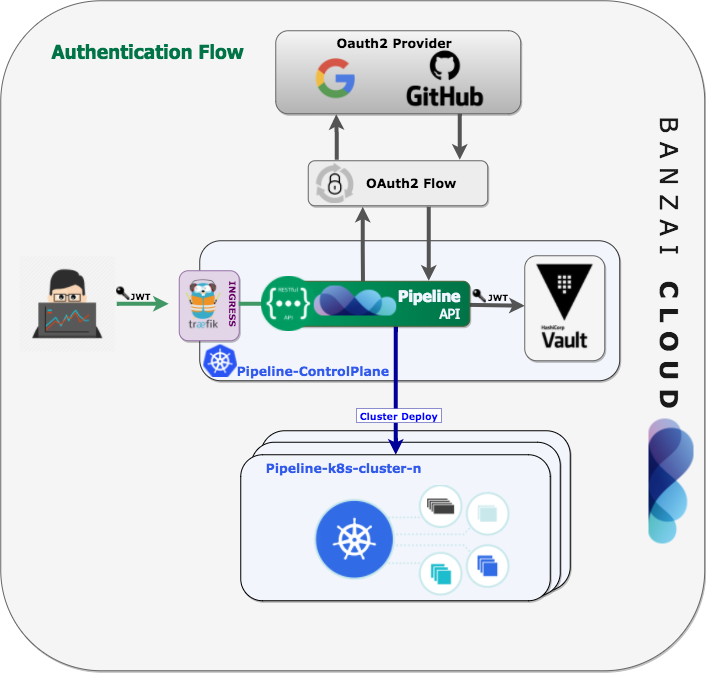
After we receive the user’s information from GitHub we create a user profile in our database with a generated user ID; we already use GORM and luckily QOR Auth does too. After successfully logging in, a session cookie is stored in the user’s browser session. With this cookie the user is authorized to navigate through the Pipeline API, though this is not an ideal user case. Most interactions with the Pipeline API are through automation and code interactions, so an Access (Bearer) Token is more appropriate. Token creation is possible at the
https://$HOST/api/v1/token REST endpoint, and the returned JSON contains the token for sequential access:
{
"token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhdWQiOiJodHRwczovL3BpcGVsaW5lLmJhbnphaWNsb3VkLmNvbSIsImV4cCI6MzAzMzYwMzI2MDA3MzQyMDAwMCwianRpIjoiMTMxOGQ0YTktMzI1ZS00YTNhLWFmNTctZjc0ZTRlODc5MTY1IiwiaWF0IjoxNTE2ODAxNjMwMDM2NzA5MDAwLCJpc3MiOiJodHRwczovL2JhbnphaWNsb3VkLmF1dGgwLmNvbS8iLCJzdWIiOiIxIiwic2NvcGUiOiJhcGk6aW52b2tlIn0.pMQrGyhc8H4Mn7CnmhfNAUv9pxecgymOWjIIi5MwCHA"
}
Now if you store this token, for example, in a variable within a shell, you can use cURL to call the protected parts of the API:
$ export TOKEN="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhdWQiOiJodHRwczovL3BpcGVsaW5lLmJhbnphaWNsb3VkLmNvbSIsImV4cCI6MzAzMzYwMzI2MDA3MzQyMDAwMCwianRpIjoiMTMxOGQ0YTktMzI1ZS00YTNhLWFmNTctZjc0ZTRlODc5MTY1IiwiaWF0IjoxNTE2ODAxNjMwMDM2NzA5MDAwLCJpc3MiOiJodHRwczovL2JhbnphaWNsb3VkLmF1dGgwLmNvbS8iLCJzdWIiOiIxIiwic2NvcGUiOiJhcGk6aW52b2tlIn0.pMQrGyhc8H4Mn7CnmhfNAUv9pxecgymOWjIIi5MwCHA"
$ curl -v -H "Authorization: Bearer $TOKEN" http://localhost:9090/api/v1/status
{"No running clusters found.":200}
JWT for Bearer token 🔗︎
Some of you have probably already noted the token’s format - it’s a JWT token which is the perfect format for a Bearer token. Note that JWT is based on the RFC 7519 standard. The main benefit of JWT is that it’s self-contained, which allows for stateless authentication. The server’s protected routes will check for a valid JWT in the Authorization header and, if it’s present, the user will be allowed to access protected resources based on the token’s scopes field.
JWT is stateless unless you want users to have the ability to revoke the generated tokens immediately (so as not to have to wait until the token expires). To revoke JWT tokens you must maintain a blacklist and a whitelist wherein you store all revoked or valid tokens, respectively. The question is, then: How to do we that and stay fast enough (e.g.: sans RDBMS queries) without creating a security risk when somebody finds the tokens in plaintext format in a Key-Value store?
Vault them all 🔗︎
You can install Vault to Kubernetes using our Helm chart
For the reasons just discussed, we chose HashiCorp’s Vault. However, there was another major contribution to our decision to standardize via Vault: Vault’s seamless integration with the Kubernetes Authentication API. After starting Vault, the Kubernetes auth backend has to be enabled and configured, then Vault can lease tokens to use its API based on ServiceAccount JWT tokens. This enables other applications running in the same Kubernetes cluster to call Vault. That way we can use tightly scoped tokens with various TTLs.
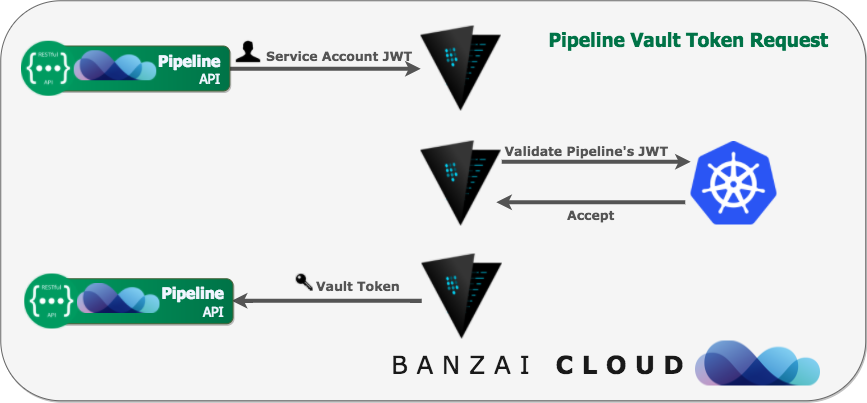
Now that Pipeline has initiated its token with Vault, it can start to store/lock-up JWT user tokens. When the user sends the JWT via the Authorization HTTP header, Pipeline validates its integrity (i.e. to make sure it hasn’t been changed or corrupted) and, after that, it extracts the user’s and token’s IDs from it, since every JWT issued by us has a unique UUID. With these two IDs, we’re provided with unique paths in Vault’s key-value store that corresponds to each token (we are currently using Vault’s general Key/Values-based Secret Backend mounted at secret/):
vault write secret/32412/971aa3a5-36d4-43f5-992f-68051092ccff jwt="eyJhbGciOi..."
Path and key names are not obfuscated or encrypted in Vault, but since only the IDs are stored in the path nothing especially secret is stored as plain text. This unique approach has two benefits:
-
First, we can easily list the tokens issued to a user with the following command (of course, we’re using the Vault Go Client, and these examples are strictly for purposes of demonstration):
vault list secret/32412 -
Second, we’re not storing all the keys inside the value part of a key. Otherwise, it would be possible to lose or generate extra data during concurrent API calls that touch the same key (a race condition would exist in such cases):
Writing to a key in the kv backend will replace the old value; sub-fields are not merged. https://www.vaultproject.io/docs/secrets/kv/index.html
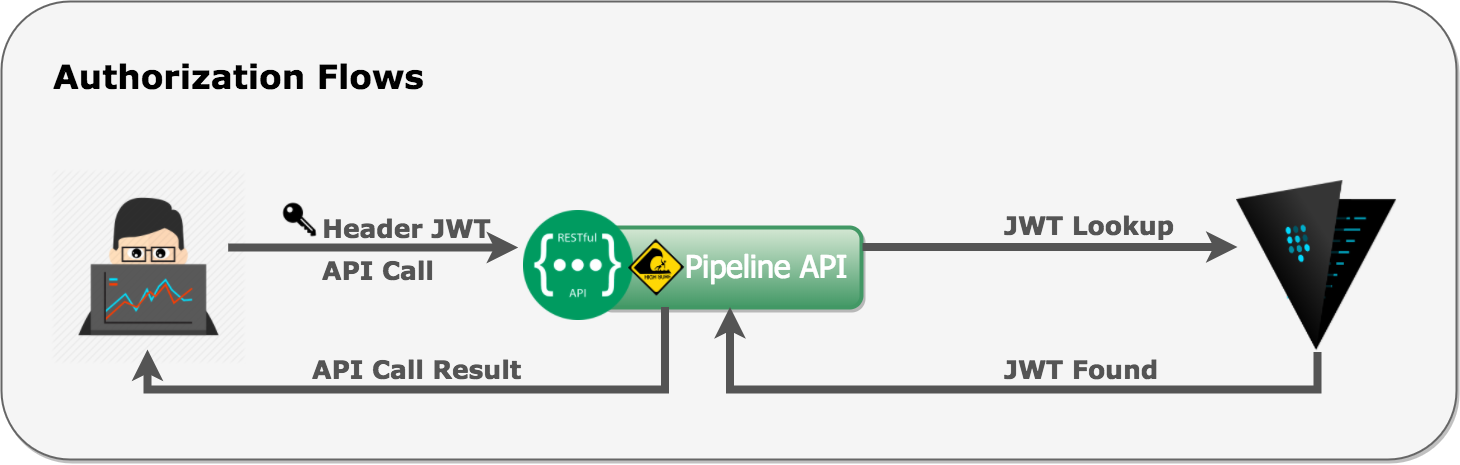
The number of Vault lookups executed this way can be reduced later by employing an in-memory cache, inside the Pipeline process with expiring LRU keys, in front of the Vault lookups (with a short TTL of course, respecting invalidation as quickly as possible).
Learn by the code 🔗︎
The code implementing this authentication and authorization mechanism can be found in our open sourced GitHub repository.
We hope that this first post on security has been useful; follow-up posts will discuss other components running inside the Pipeline PaaS, as well as Kubernetes, via OAuth2 tokens.
Learn more about Bank-Vaults:
- Secret injection webhook improvements
- Backing up Vault with Velero
- Vault replication across multiple datacenters
- Vault secret injection webhook and Istio
- Mutate any kind of k8s resources
- HSM support
- Injecting dynamic configuration with templates
- OIDC issuer discovery for Kubernetes service accounts
- Show all posts related to Bank-Vaults







