






Enterprises often use multi-tenant and heterogenous clusters to deploy their applications to Kubernetes. These applications usually have needs which require special scheduling constraints. Pods may require nodes with special hardware, isolation, or colocation with other pods running in the system.
The Pipeline platform allows users to express their constraints in terms of resources (CPU, memory, network, IO, etc.). These requirements are turned into infrastructure specifications using Telescopes. Once the cluster nodes are created and properly labeled by Pipeline, deployments are run with the specified constraints automatically on top of Kubernetes.
In this post we discuss how taints and tolerations, node affinity and pod affinity, anti-affinity work and can be used to instruct the Kubernetes scheduler to place pods on nodes that fulfill their special needs.
In a follow up post we will go into the details of how the Pipeline platform uses these and allows use of the underlying infrastructure in an efficient, automated way.
Taints and tolerations 🔗︎
This Kubernetes feature allows users to mark a node (taint the node) so that no pods can be scheduled to it, unless a pod explicitly tolerates the taint. Using this Kubernetes feature we can create nodes that are reserved (dedicated) for specific pods. E.g. pods which require that most of the resources of the node be available to them in order to operate flawlessly should be scheduled to nodes that are reserved for them.
In practice tainted nodes will be more like pseudo-reserved nodes, since taints and tolerations won’t exclude undesired pods in certain circumstances:
- system pods are created with toleration settings that tolerate all taints thus can be scheduled onto any node. This is by design, as system pods are required by the Kubernetes infrastructure (e.g.
kube-proxy) or by the Cloud Provider in case of managed Kubernetes (e.g. on EKS theaws-nodesystem pod). - users can’t be stopped from deploying pods that tolerate “wrong” taint thus, beside system pods, pods other than desired ones may still run on the reserved nodes
Let’s see taints and tolerations in action 🔗︎
I’ve set up a 3 node EKS cluster with Pipeline.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-101-21.us-west-2.compute.internal Ready <none> 1h v1.10.3
ip-192-168-165-61.us-west-2.compute.internal Ready <none> 1h v1.10.3
ip-192-168-96-47.us-west-2.compute.internal Ready <none> 1h v1.10.3
$ kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
kube-system aws-node-glblv 1/1 Running 0 1h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-system aws-node-m4crc 1/1 Running 0 1h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-system aws-node-vfkxn 1/1 Running 0 1h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-system kube-dns-7cc87d595-wbs7x 3/3 Running 0 2h 192.168.103.173 ip-192-168-101-21.us-west-2.compute.internal
kube-system kube-proxy-cr6q2 1/1 Running 0 1h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-system kube-proxy-p6t5v 1/1 Running 0 1h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-system kube-proxy-z8hkv 1/1 Running 0 1h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-system tiller-deploy-777677b45c-m9n27 1/1 Running 0 1h 192.168.112.21 ip-192-168-96-47.us-west-2.compute.internal
$ kubectl get ds --all-namespaces -o wide
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR
kube-system aws-node 3 3 3 3 3 <none> 2h aws-node 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon-k8s-cni:1.1.0 k8s-app=aws-node
kube-system kube-proxy 3 3 3 3 3 <none> 2h kube-proxy 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/kube-proxy:v1.10.3 k8s-app=kube-proxyThere are two daemonset system pods: aws-node and kube-proxy running on every single node. There are two normal pods kube-dns-7cc87d595-wbs7x and tiller-deploy-777677b45c-m9n27 the former running in node ip-192-168-101-21.us-west-2.compute.internal and the latter on ip-192-168-96-47.us-west-2.compute.internal.
Let’s taint node ip-192-168-101-21.us-west-2.compute.internal that hosts the kube-dns-7cc87d595-wbs7x pod and the daemonset system pods.
$ kubectl describe node ip-192-168-101-21.us-west-2.compute.internal
Name: ip-192-168-101-21.us-west-2.compute.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=m4.xlarge
beta.kubernetes.io/os=linux
failure-domain.beta.kubernetes.io/region=us-west-2
failure-domain.beta.kubernetes.io/zone=us-west-2a
kubernetes.io/hostname=ip-192-168-101-21.us-west-2.compute.internal
pipeline-nodepool-name=pool1
Annotations: node.alpha.kubernetes.io/ttl=0
volumes.kubernetes.io/controller-managed-attach-detach=true
CreationTimestamp: Wed, 29 Aug 2018 11:31:53 +0200
Taints: <none>
Unschedulable: false
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
OutOfDisk False Wed, 29 Aug 2018 13:45:44 +0200 Wed, 29 Aug 2018 11:31:53 +0200 KubeletHasSufficientDisk kubelet has sufficient disk space available
MemoryPressure False Wed, 29 Aug 2018 13:45:44 +0200 Wed, 29 Aug 2018 11:31:53 +0200 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Wed, 29 Aug 2018 13:45:44 +0200 Wed, 29 Aug 2018 11:31:53 +0200 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Wed, 29 Aug 2018 13:45:44 +0200 Wed, 29 Aug 2018 11:31:53 +0200 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 29 Aug 2018 13:45:44 +0200 Wed, 29 Aug 2018 11:32:19 +0200 KubeletReady kubelet is posting ready status
...
...
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system aws-node-vfkxn 10m (0%) 0 (0%) 0 (0%) 0 (0%)
kube-system kube-dns-7cc87d595-wbs7x 260m (6%) 0 (0%) 110Mi (0%) 170Mi (1%)
kube-system kube-proxy-z8hkv 100m (2%) 0 (0%) 0 (0%) 0 (0%)
...$ kubectl taint nodes ip-192-168-101-21.us-west-2.compute.internal my-taint=test:NoSchedule
node "ip-192-168-101-21.us-west-2.compute.internal" tainted
$ kubectl describe node ip-192-168-101-21.us-west-2.compute.internal
Name: ip-192-168-101-21.us-west-2.compute.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=m4.xlarge
beta.kubernetes.io/os=linux
failure-domain.beta.kubernetes.io/region=us-west-2
failure-domain.beta.kubernetes.io/zone=us-west-2a
kubernetes.io/hostname=ip-192-168-101-21.us-west-2.compute.internal
pipeline-nodepool-name=pool1
Annotations: node.alpha.kubernetes.io/ttl=0
volumes.kubernetes.io/controller-managed-attach-detach=true
CreationTimestamp: Wed, 29 Aug 2018 11:31:53 +0200
Taints: my-taint=test:NoSchedule
Unschedulable: false
...
...
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system aws-node-vfkxn 10m (0%) 0 (0%) 0 (0%) 0 (0%)
kube-system kube-dns-7cc87d595-wbs7x 260m (6%) 0 (0%) 110Mi (0%) 170Mi (1%)
kube-system kube-proxy-z8hkv 100m (2%) 0 (0%) 0 (0%) 0 (0%)
...The format of a taint is <key>=<value>:<effect>. The <effect> instructs the Kubernetes scheduler what should happen to pods that don’t tolerate this taint.
We can distinguish between two different effects:
- NoSchedule - instructs Kubernetes scheduler not to schedule any new pods to the node unless the pod tolerates the taint.
- NoExecute - instructs Kubernetes scheduler to evict pods already running on the node that don’t tolerate the taint.
In the example above we used my-taint=test:NoSchedule and we can see that the node has been tainted and, according to the NoSchedule effect, already running pods have not been touched.
Now let’s taint the same node with the NoExecute effect. We expect to see the kube-dns pod evicted and aws-node and kube-proxy to stay as these are deamonset system pods.
$ kubectl taint nodes ip-192-168-101-21.us-west-2.compute.internal my-taint=test:NoExecute
node "ip-192-168-101-21.us-west-2.compute.internal" tainted
$ kubectl describe node ip-192-168-101-21.us-west-2.compute.internal
Name: ip-192-168-101-21.us-west-2.compute.internal
...
...
Taints: my-taint=test:NoExecute
my-taint=test:NoSchedule
...
...
Non-terminated Pods: (2 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system aws-node-vfkxn 10m (0%) 0 (0%) 0 (0%) 0 (0%)
kube-system kube-proxy-z8hkv 100m (2%) 0 (0%) 0 (0%) 0 (0%)
...
...We can see that the kube-dns pod was stopped and started on a different node ip-192-168-165-61.us-west-2.compute.internal:
$ kubectl get pod --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
kube-system aws-node-glblv 1/1 Running 0 2h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-system aws-node-m4crc 1/1 Running 0 2h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-system aws-node-vfkxn 1/1 Running 0 2h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-system kube-dns-7cc87d595-cbsxg 3/3 Running 0 5m 192.168.164.63 ip-192-168-165-61.us-west-2.compute.internal
kube-system kube-proxy-cr6q2 1/1 Running 0 2h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-system kube-proxy-p6t5v 1/1 Running 0 2h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-system kube-proxy-z8hkv 1/1 Running 0 2h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-system tiller-deploy-777677b45c-m9n27 1/1 Running 0 2h 192.168.112.21 ip-192-168-96-47.us-west-2.compute.internalNow if we want to make the kube-dns pod to be schedulable on the tainted ip-192-168-101-21.us-west-2.compute.internal node we need to place the appropriate toleration on the pod.
Since the kube-dns pod is created through a deployment we are going to place the following toleration into the deployment’s spec:
$ kubectl edit deployment kube-dns -n kube-system
...
spec:
...
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- key: "my-taint"
operator: Equal
value: "test"
....As we can see, the kube-dns pod is still running on node ip-192-168-165-61.us-west-2.compute.internal instead of the tainted ip-192-168-101-21.us-west-2.compute.internal even though we set the appropriate toleration for it.
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE
aws-node-glblv 1/1 Running 0 3h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
aws-node-m4crc 1/1 Running 0 3h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
aws-node-vfkxn 1/1 Running 0 3h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-dns-6848d77f98-vvkdq 3/3 Running 0 2m 192.168.145.180 ip-192-168-165-61.us-west-2.compute.internal
kube-proxy-cr6q2 1/1 Running 0 3h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-proxy-p6t5v 1/1 Running 0 3h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-proxy-z8hkv 1/1 Running 0 3h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
tiller-deploy-777677b45c-m9n27 1/1 Running 0 3h 192.168.112.21 ip-192-168-96-47.us-west-2.compute.internalThis is expected as the toleration allows the pod to be scheduled to a tainted node (it tolerates it) but doesn’t necessary mean that the pod will actually be scheduled there.
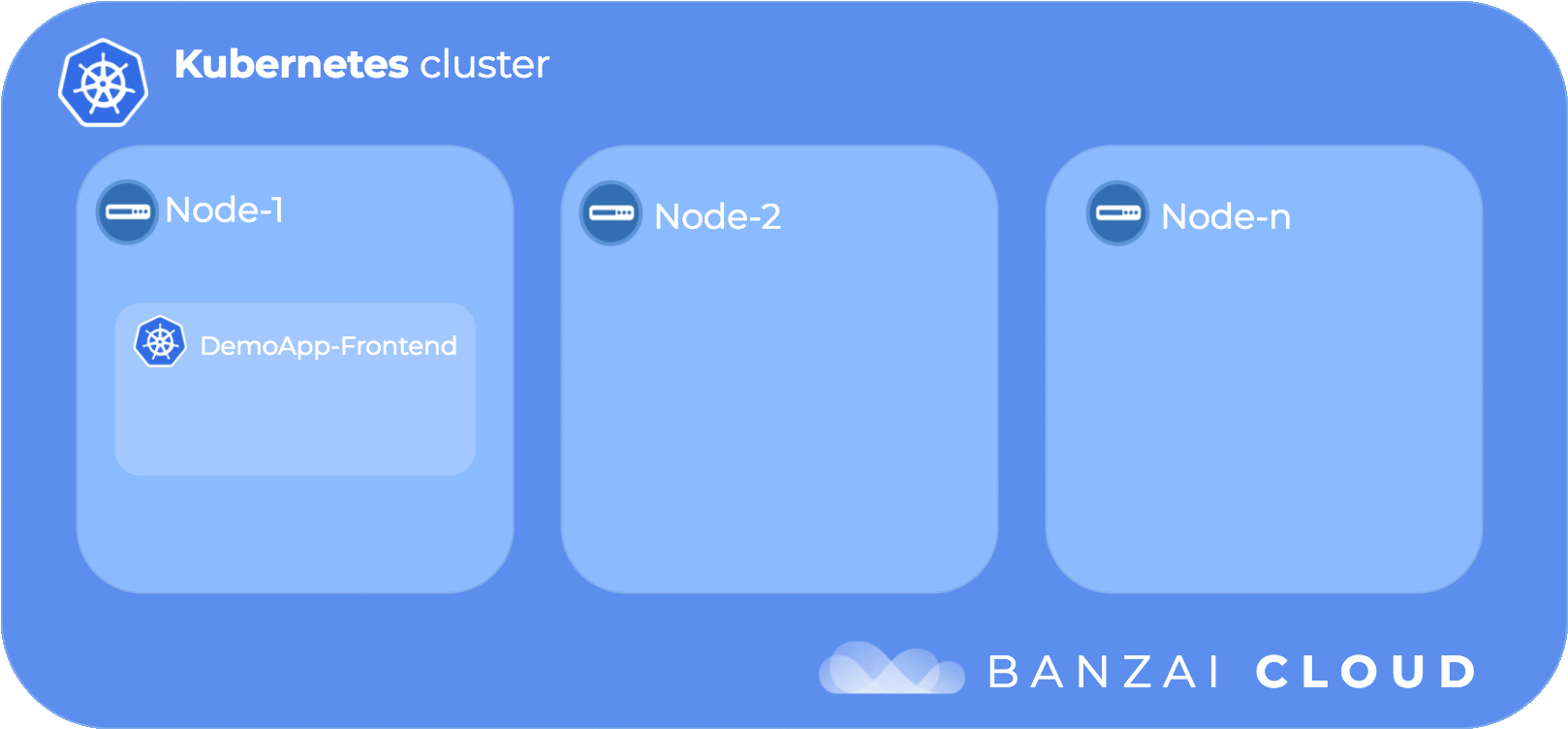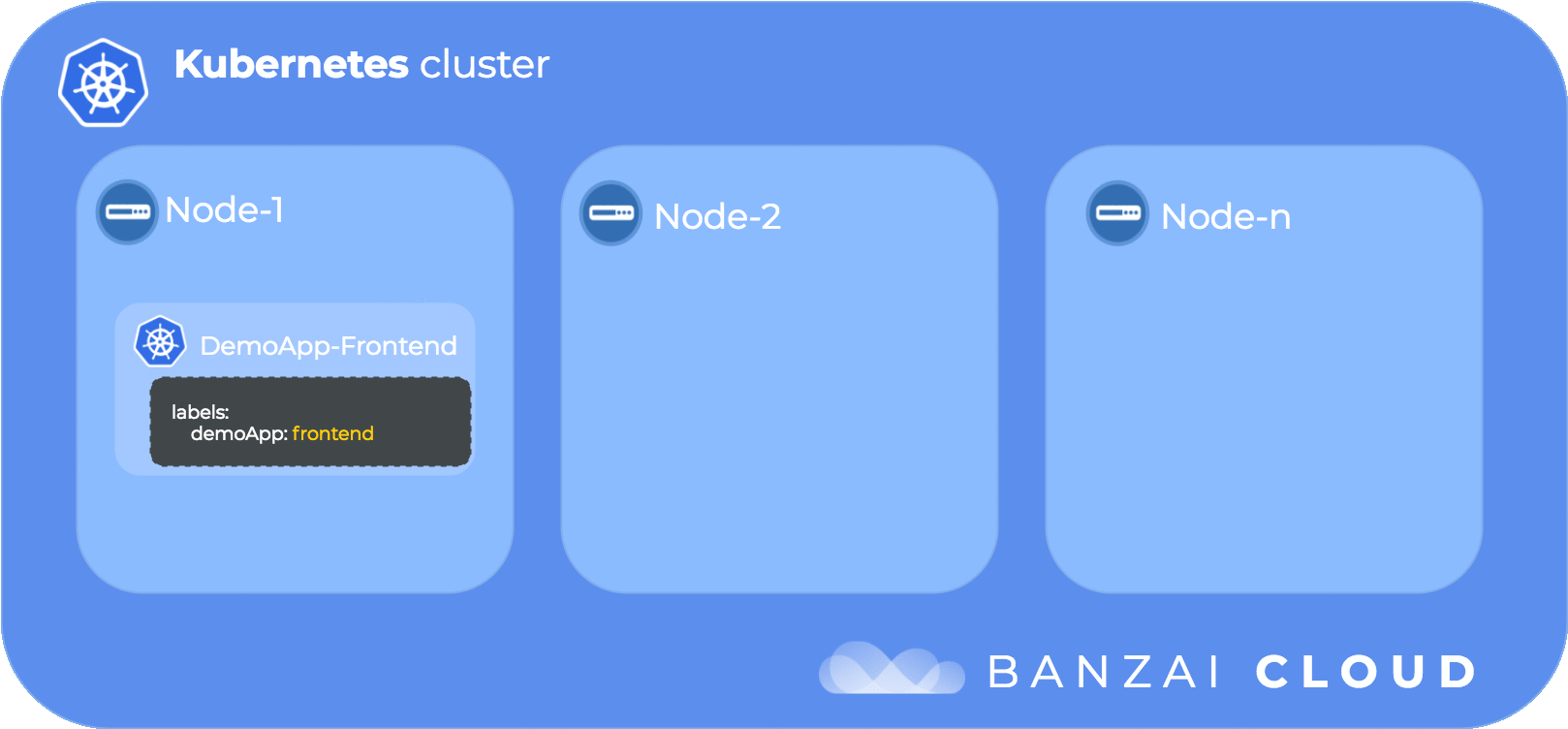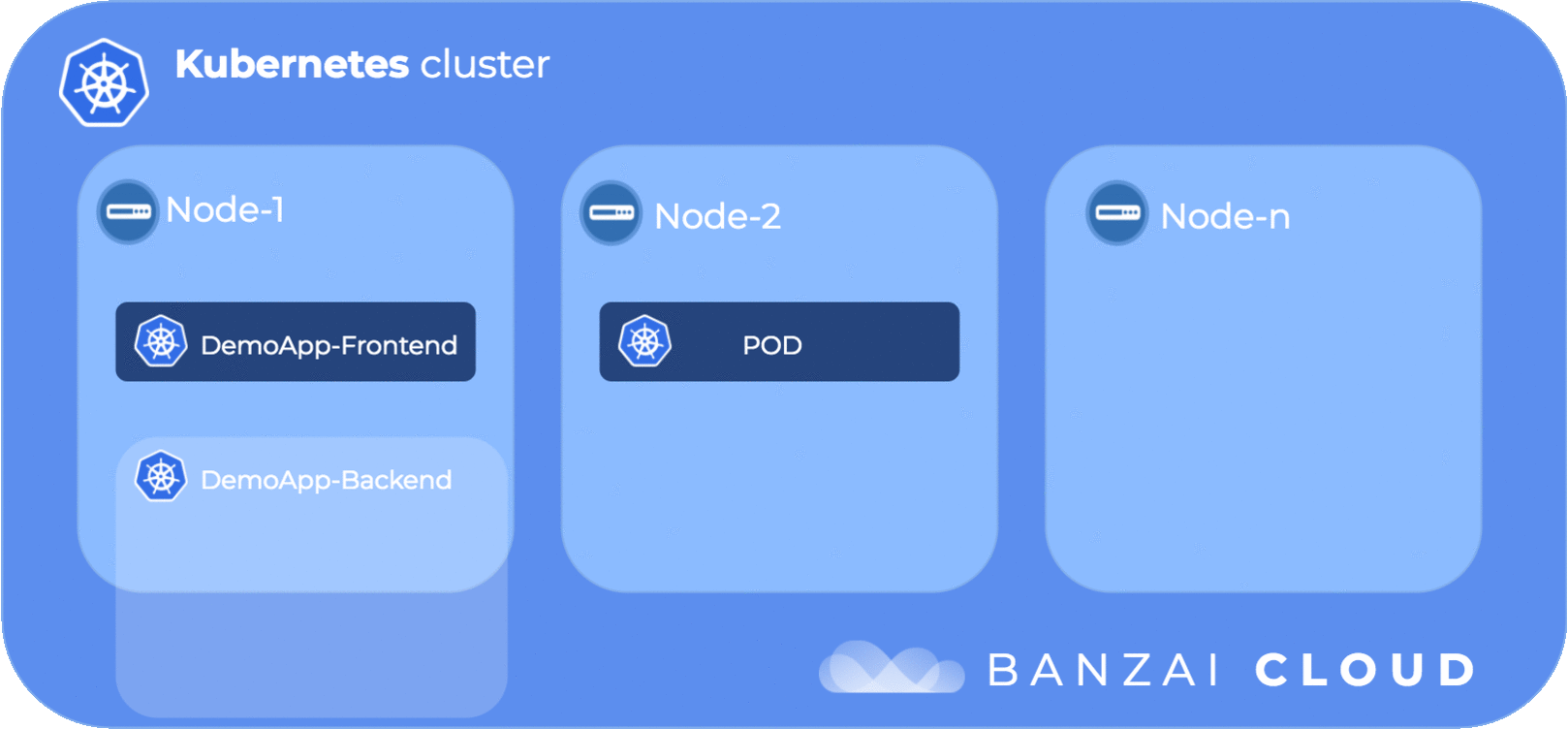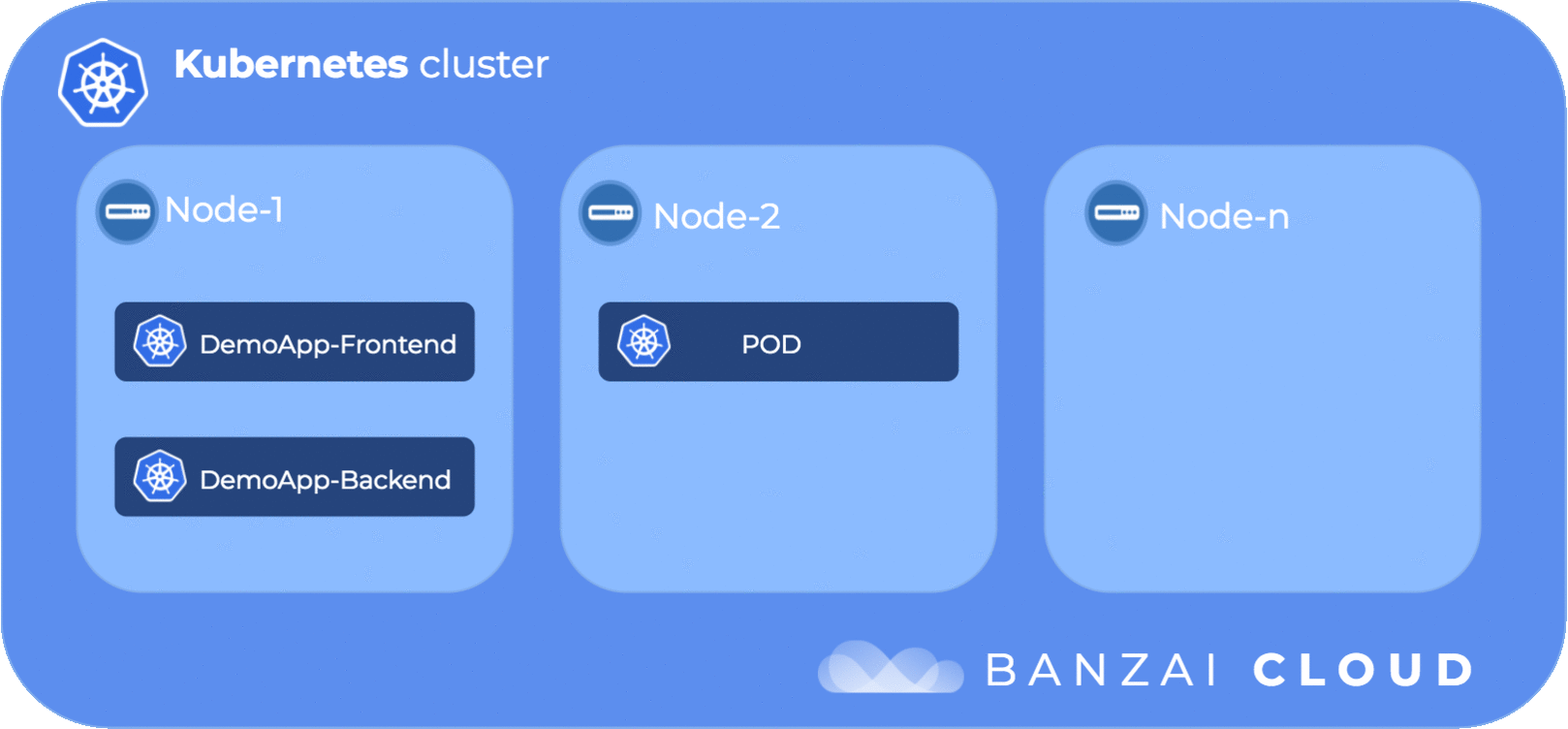
We can conclude that taints and tolerations are better used in those cases wherein we want to keep pods away from nodes, excepting a few select nodes.
The following diagram illustrates the flow of taints and tolerations:
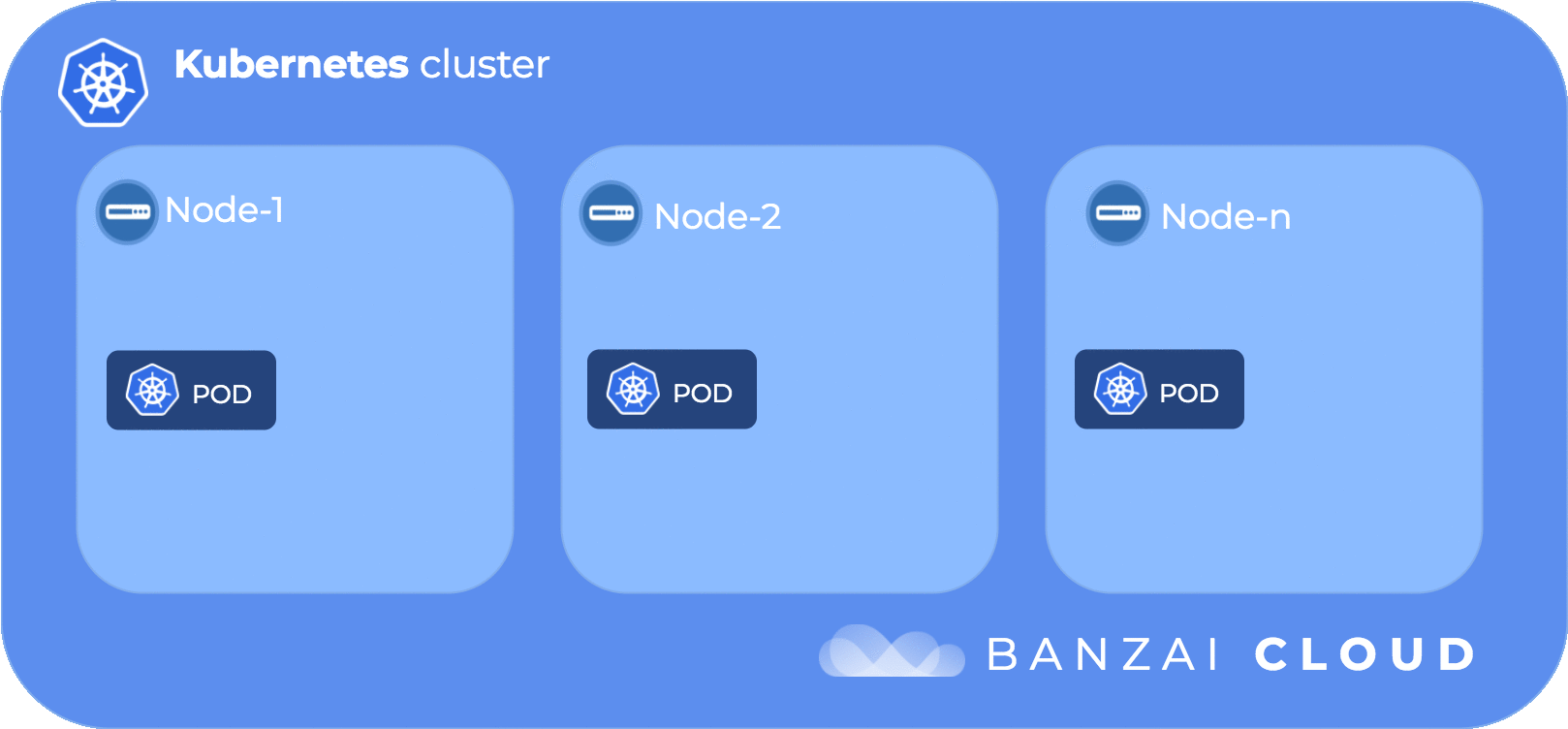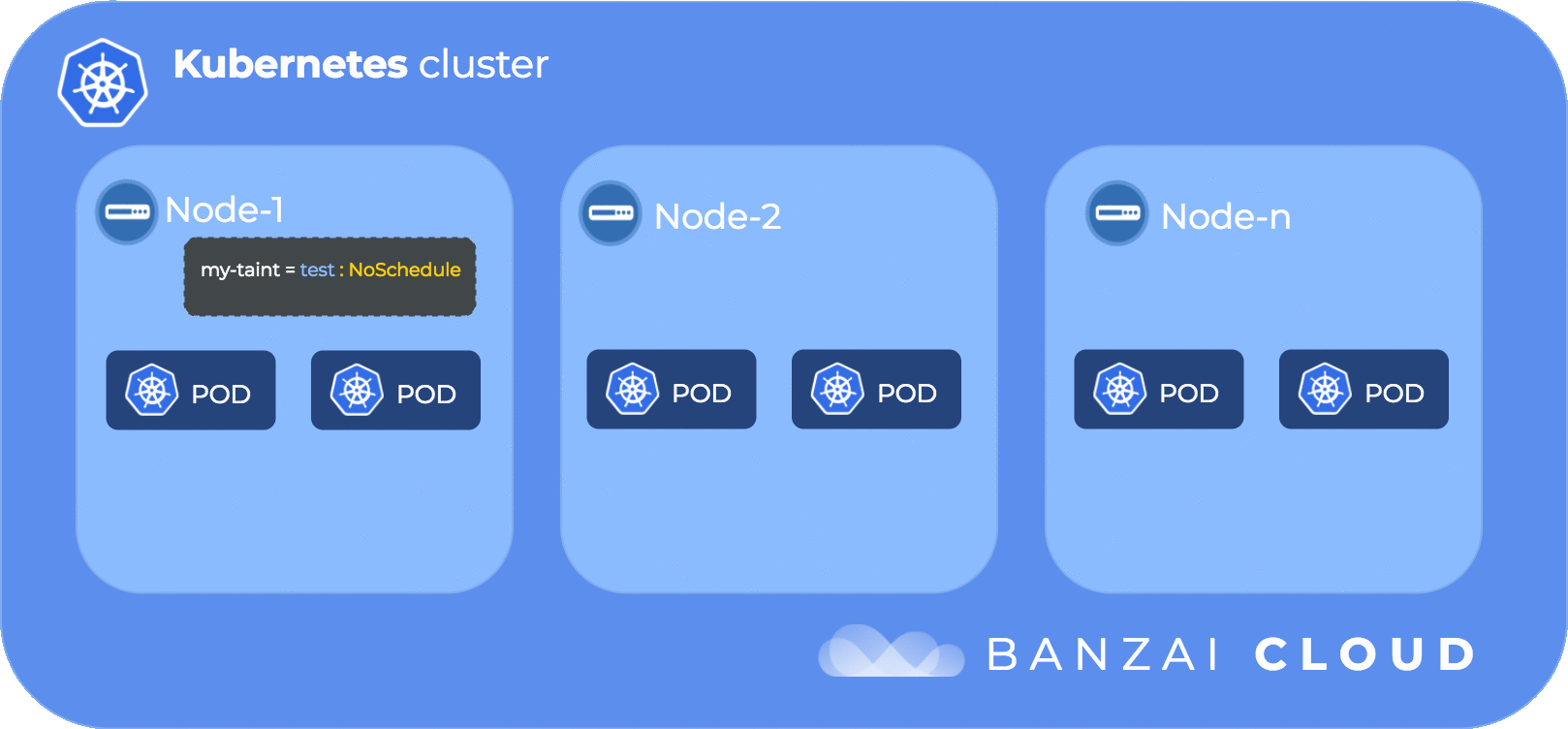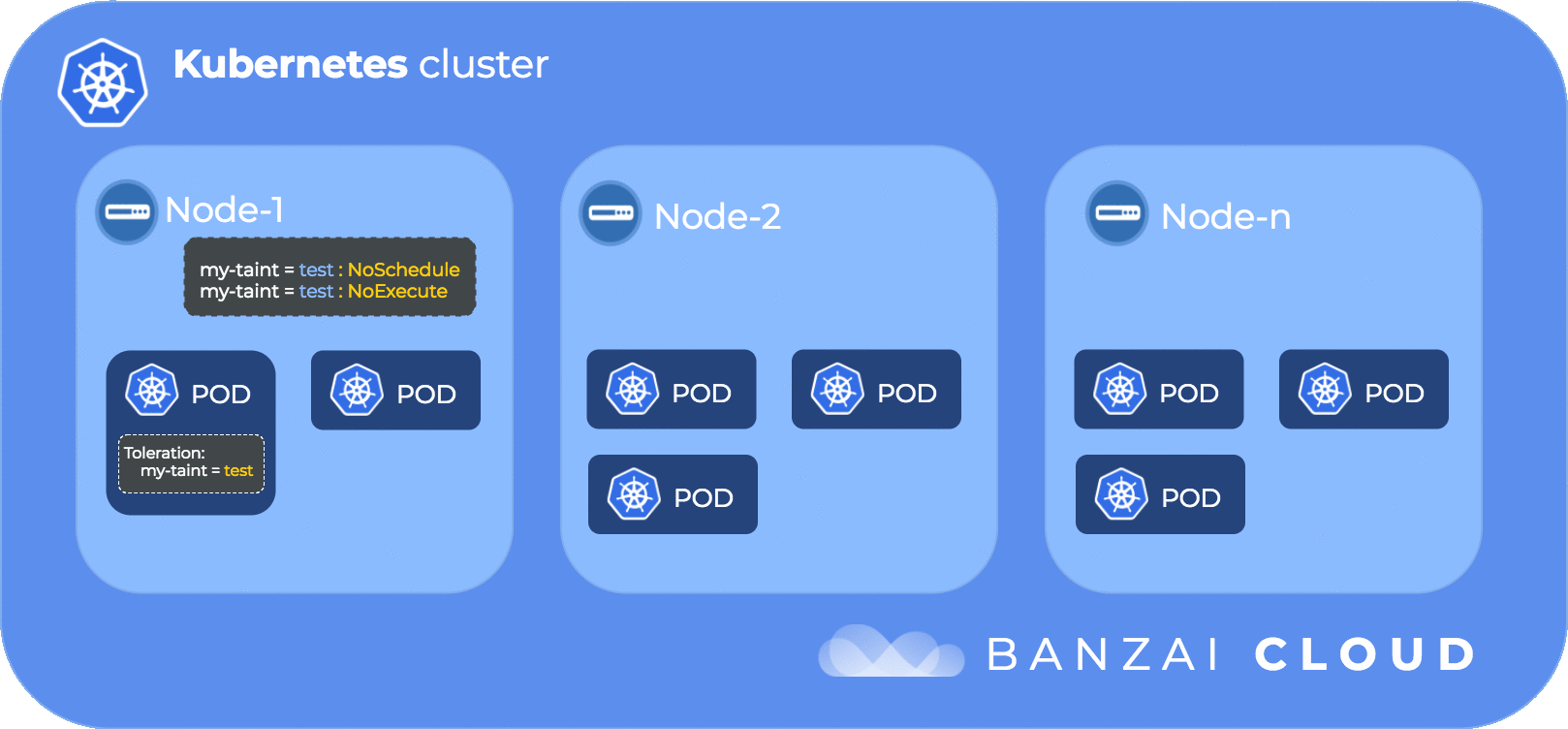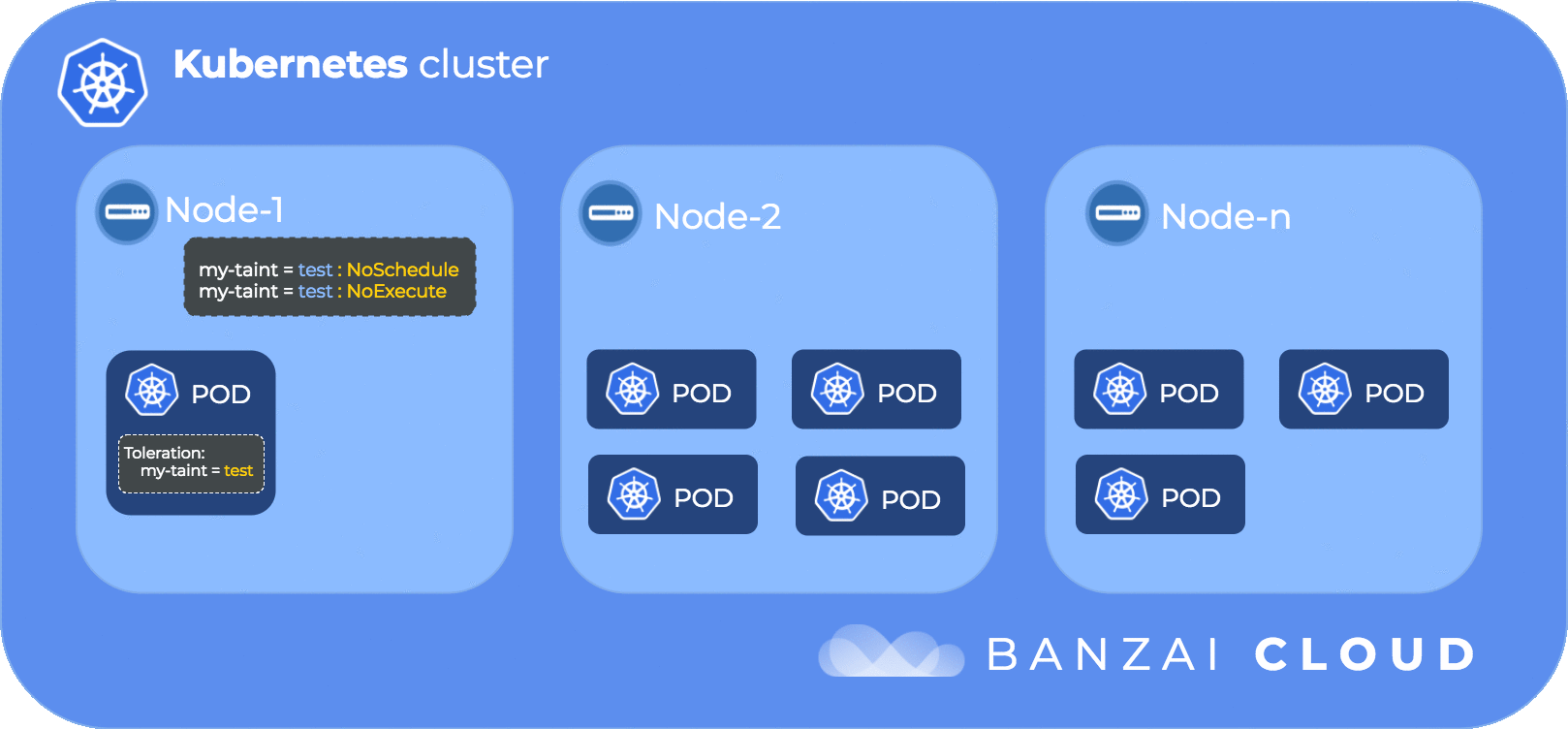
In order to get the kube-dns pod scheduled to a specific node (in our case ip-192-168-101-21.us-west-2.compute.internal) we need to delve into our next topic node affinity
Node affinity 🔗︎
To get pods to be scheduled to specific nodes Kubernetes provides nodeSelectors and nodeAffinity. As nodeAffinity encompasses what can be achieved with nodeSelectors, nodeSelectors will be deprecated in Kubernetes thus we discuss nodeAffinity here.
With node affinity we can tell Kubernetes which nodes to schedule to a pod using the labels on each node.
Let’s see how node affinity works 🔗︎
Since node affinity identifies the nodes on which to place pods via labels, we first need to add a label to our node.
$ kubectl edit node ip-192-168-101-21.us-west-2.compute.internal
labels:
...
test-node-affinity: test
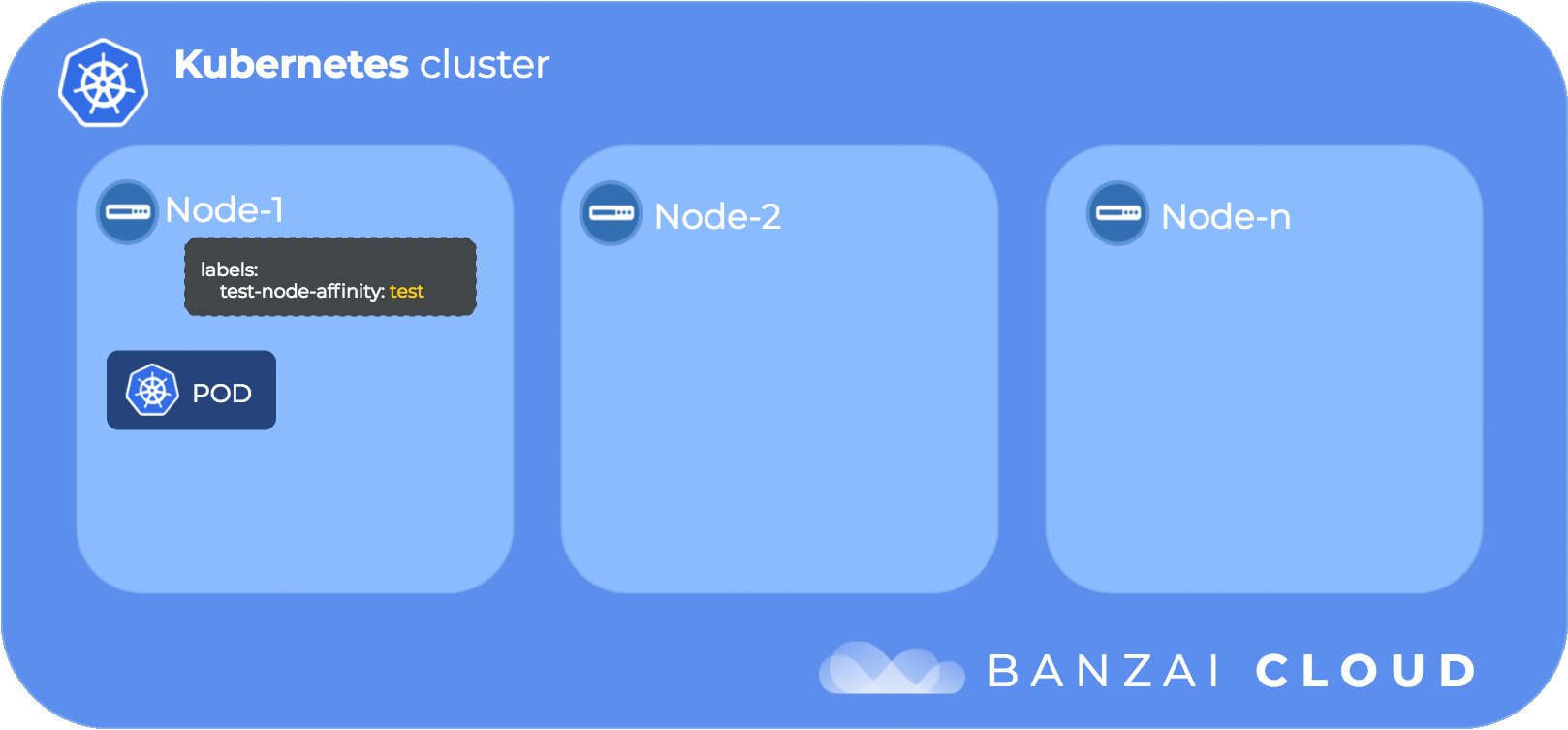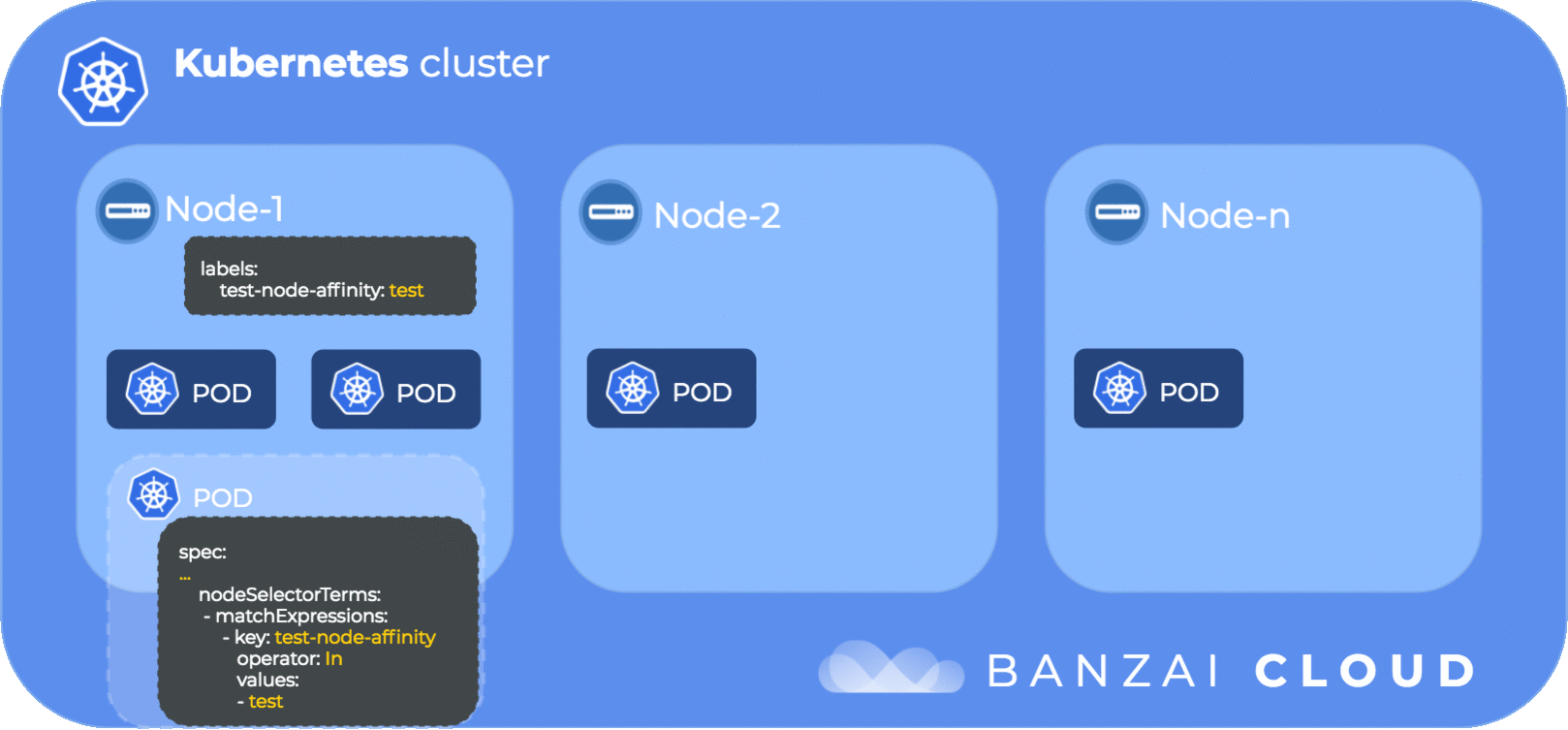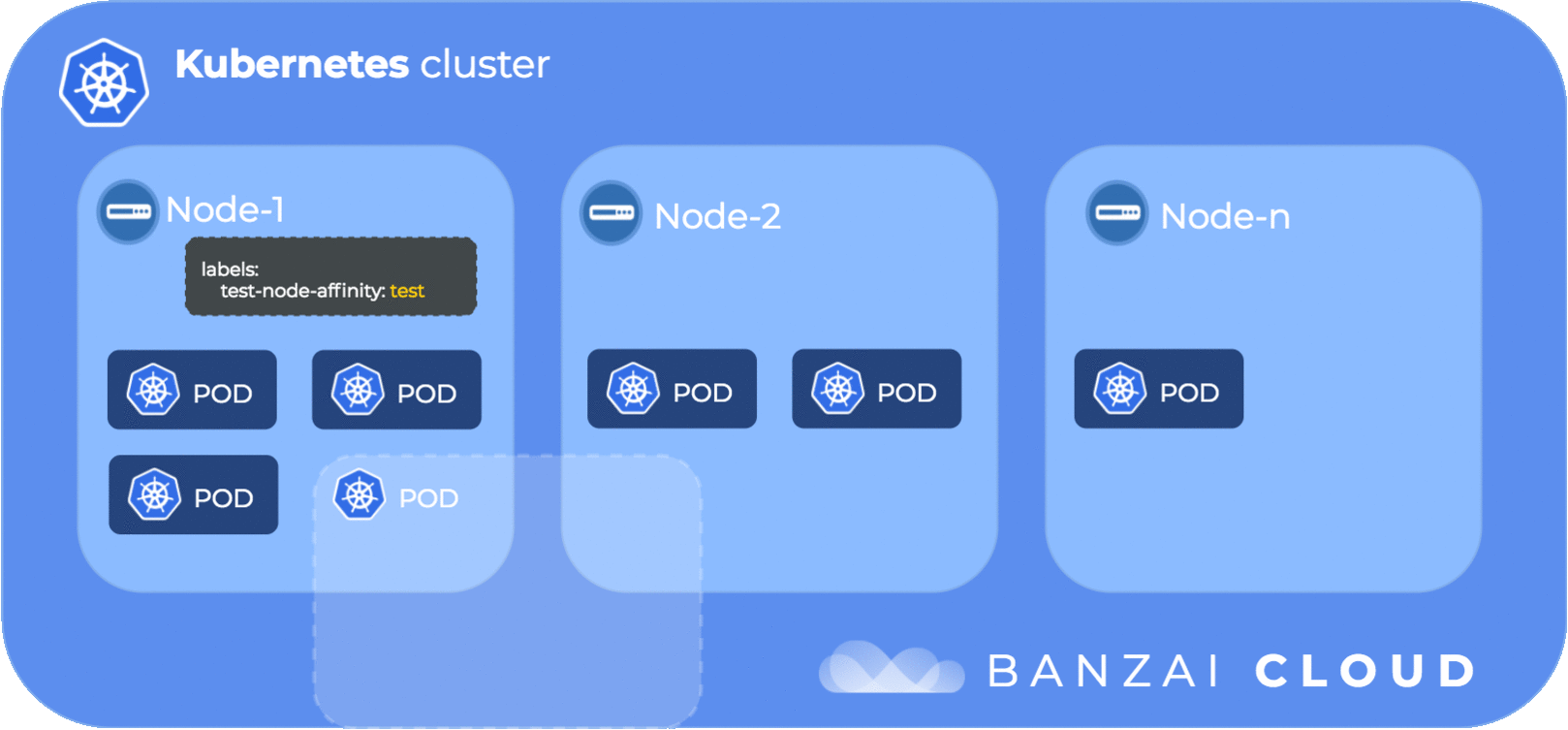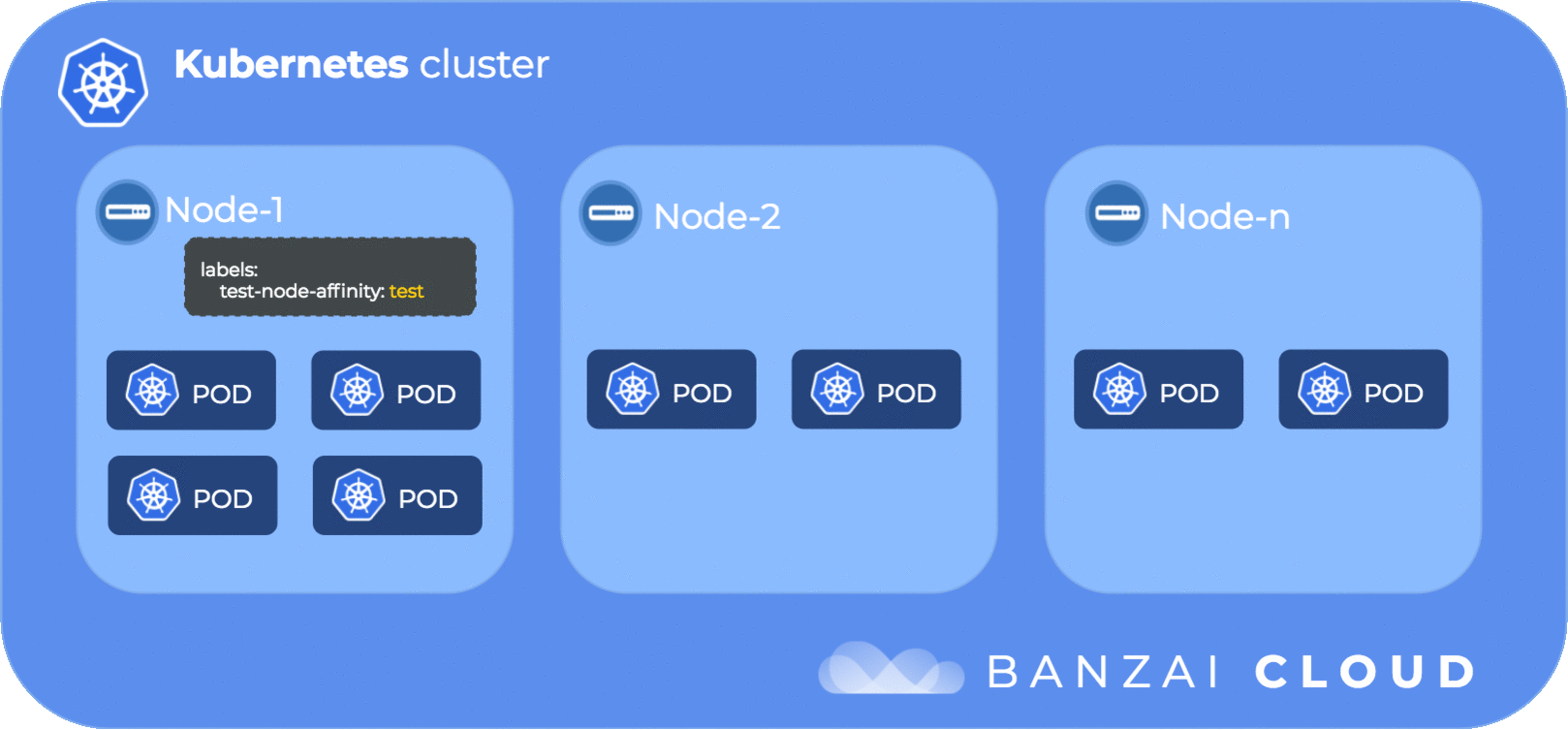
...Set node affinity for kube-dns so it selects the node that has the test-node-affinity: test label:
$ kubectl edit deployment kube-dns -n kube-system
spec:
...
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: test-node-affinity
operator: In
values:
- test
...Notice requiredDuringSchedulingIgnoredDuringExecution which tells the Kubernetes scheduler that:
requiredDuringScheduling- the pod must be scheduled to node(s) that match the expressions listed undermatchExpressionsIgnoredDuringExecutionindicates that the node affinity only applies during pod scheduling, it doesn’t apply to already running pods
Note: requiredDuringSchedulingRequiredDuringExecution is not supported yet (Kubernetes 1.11) thus, if a label on a node changes pods that don’t match, the new node label won’t be evicted, but will continue to run on the node.
Once we bounce our pod we should see it being scheduled to node ip-192-168-101-21.us-west-2.compute.internal, since it matches by node affinity and node selector expression, and because the pod tolerates the taints of the node.
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE
aws-node-glblv 1/1 Running 0 4h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
aws-node-m4crc 1/1 Running 0 4h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
aws-node-vfkxn 1/1 Running 0 4h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-dns-669db795bb-5blv2 3/3 Running 0 3m 192.168.97.54 ip-192-168-101-21.us-west-2.compute.internal
kube-proxy-cr6q2 1/1 Running 0 4h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-proxy-p6t5v 1/1 Running 0 4h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-proxy-z8hkv 1/1 Running 0 4h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
tiller-deploy-777677b45c-m9n27 1/1 Running 0 4h 192.168.112.21 ip-192-168-96-47.us-west-2.compute.internalWhat if the
kube-dnsdoes not tolerate the taint on nodeip-192-168-101-21.us-west-2.compute.internal?
Well, the pod will remain in a Pending state as the node affinity Kubernetes scheduler tries to schedule it to a node that “rejects” the pod being scheduled.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 19s (x15 over 3m) default-scheduler 0/3 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 2 node(s) didn't match node selectorKeep in mind when using both taints and node affinity that it is necessary to set them carefully to avoid these types of situations.
Besides the requiredDuringSchedulingIgnoredDuringExecution type of node affinity there exists preferredDuringSchedulingIgnoredDuringExecution. The first can be thought of as a “hard” rule, while the second constitutes a “soft” rule that Kubernetes tries to enforce but will not guarantee.
The following diagram illustrates pod node affinity flow:
Pod affinity and anti-affinity 🔗︎
Pod affinity and anti-affinity allows placing pods to nodes as a function of the labels of other pods. These Kubernetes features are useful in scenarios like: an application that consists of multiple services, some of which may require that they be co-located on the same node for performance reasons; replicas of critical services shouldn’t be placed onto the same node to avoid loss in the event of node failure.
Let’s examine this through an example. We want to have multiple replicas of the kube-dns pod running while distributed across different nodes. While the Kubernetes scheduler may try to distribute the replicas over multiple nodes this may not an inevitability. Pod anti-affinity helps with this.
First, we change the kube-dns deployment to produce two replicas and remove the earlier set node affinity.
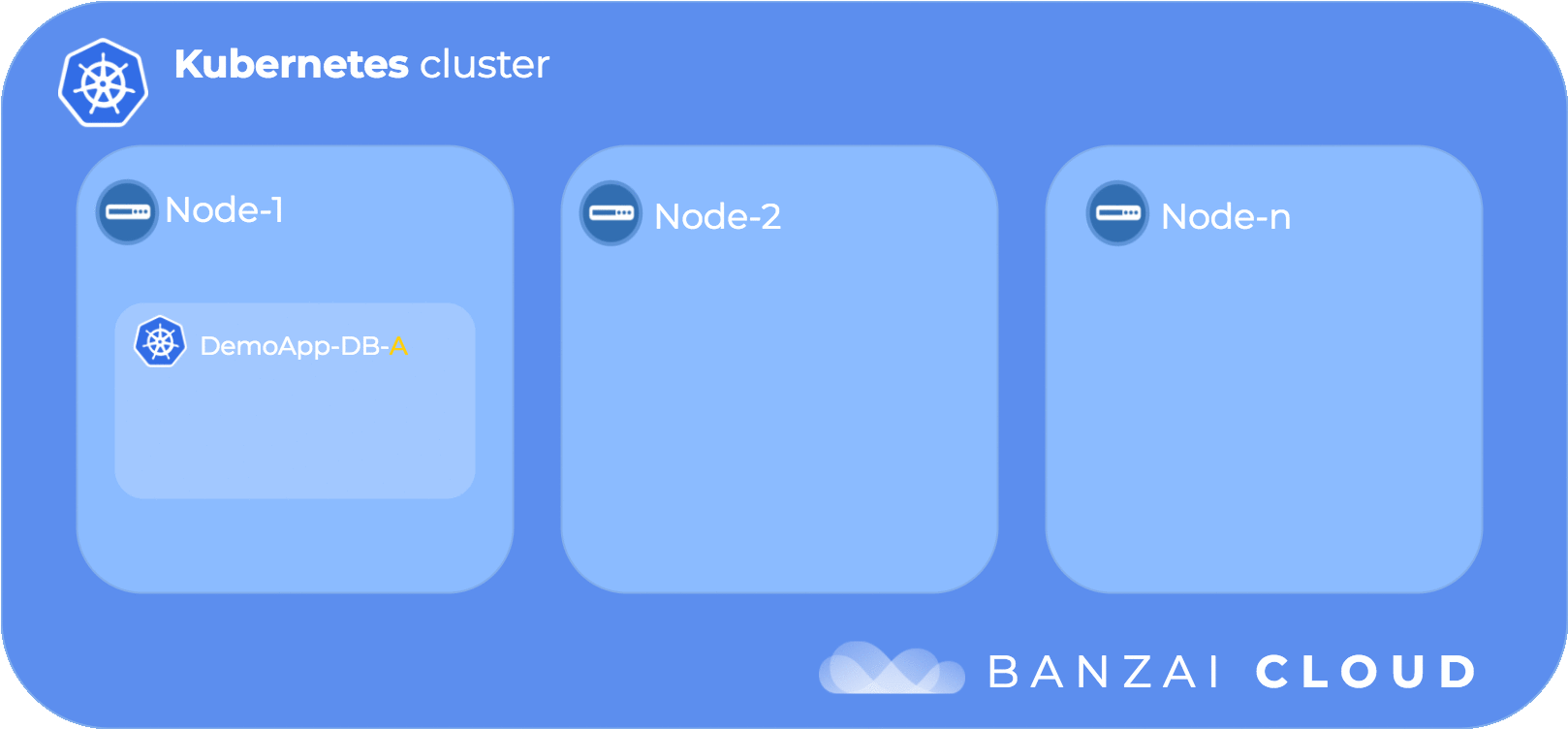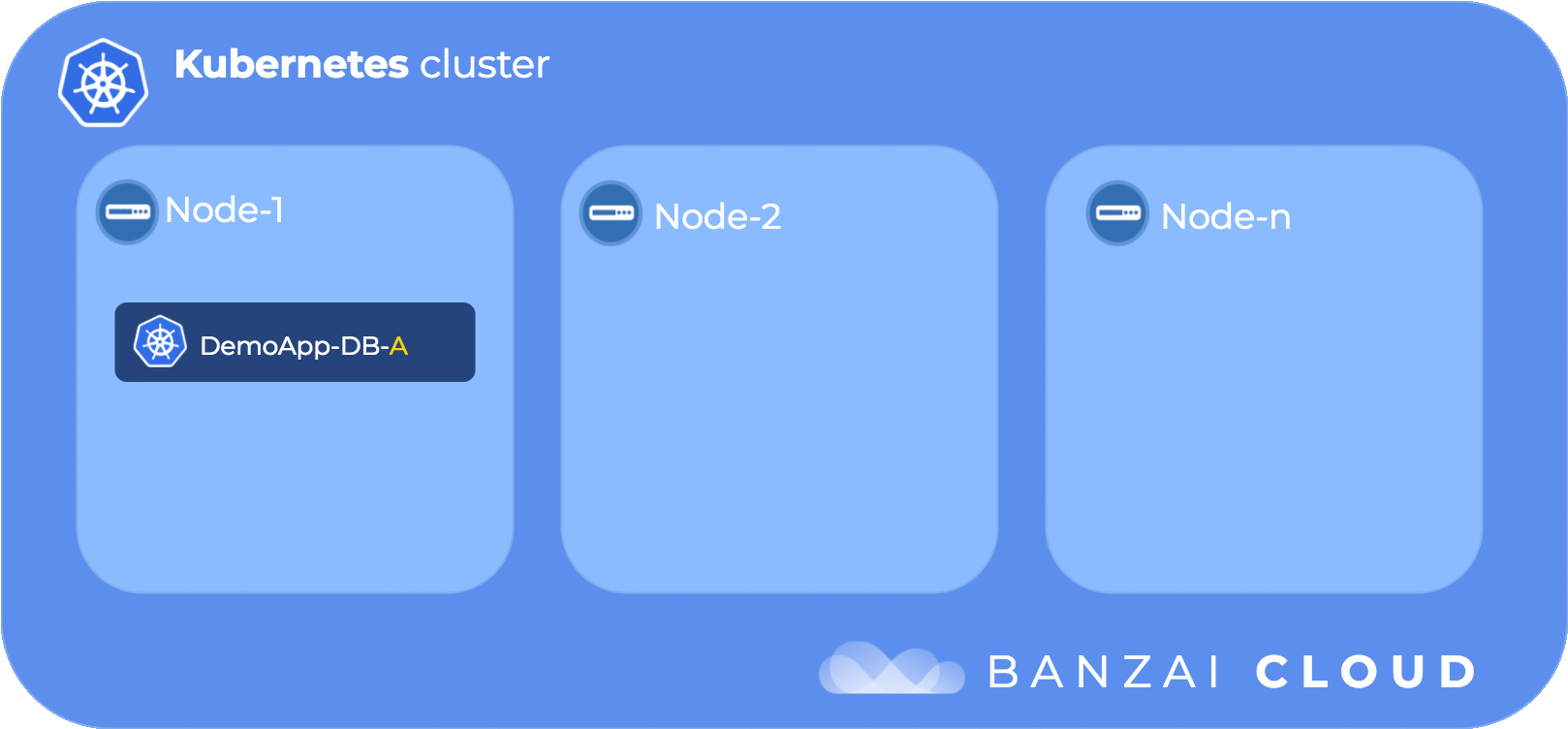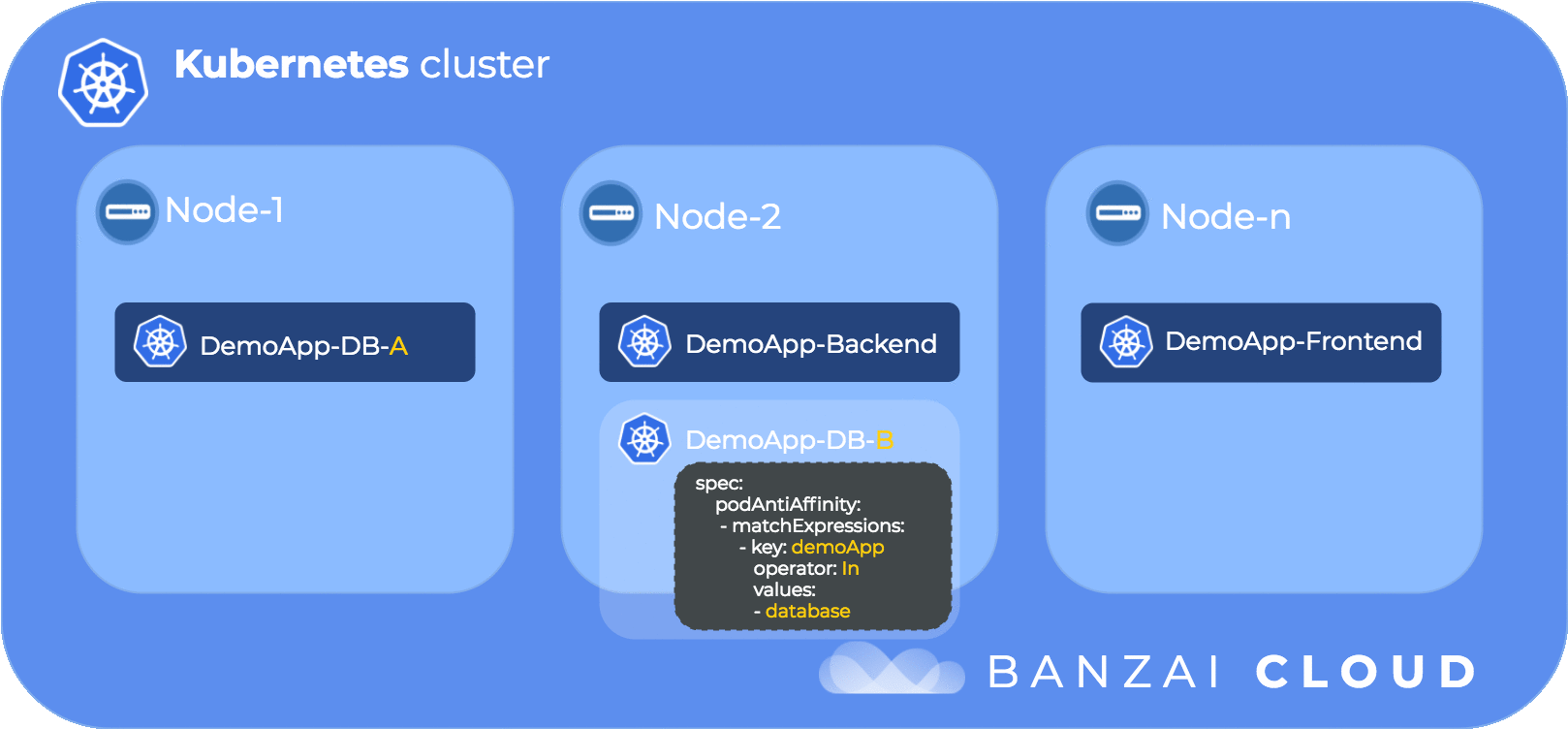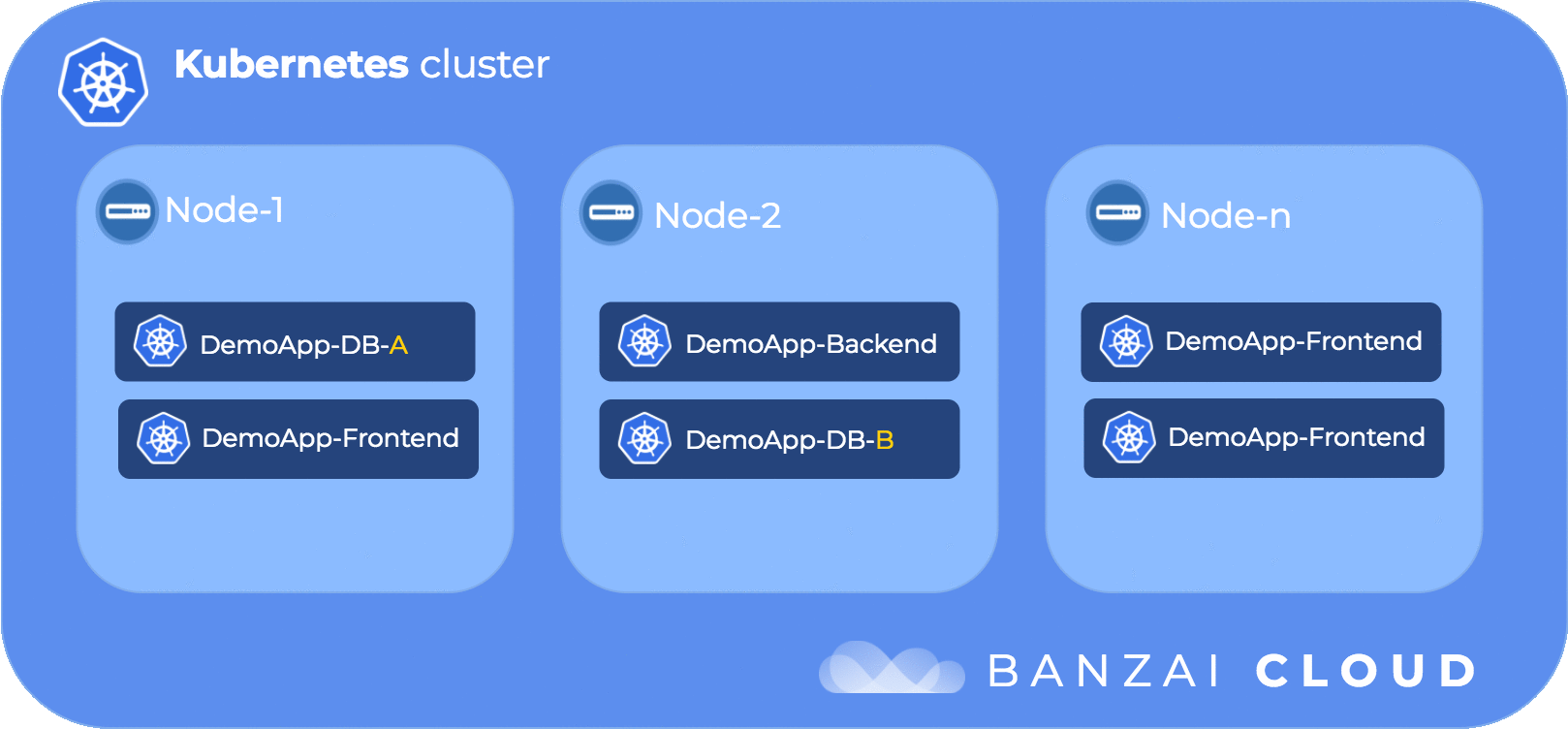
Pod anti-affinity requires topologyKey to be set and all pods to have labels referenced by topologyKey. (e.g the “kubernetes.io/hostname” label is set on each node by Kubernetes).
In case of requiredDuringSchedulingIgnoredDuringExecution only “kubernetes.io/hostname” is accepted as a value for topologyKey. Conceptually speaking, the topology key is the domain for which the matching rules are applied.
We set the label my-label: test on the pod which will be used to find pods, by label, within the domain defined by topologyKey.
$ kubectl edit deployment kube-dns -n kube-system
template:
metadata:
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
creationTimestamp: null
labels:
eks.amazonaws.com/component: kube-dns
k8s-app: kube-dns
my-label: test
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: my-label
operator: In
values:
- test
topologyKey: kubernetes.io/hostnameIn the above pod anti-affinity setting, the domain is defined by the kubernetes.io/hostname label of the nodes, which is the node where the pod runs, thus the labelSelector/matchExpressions is evaluated within the scope of a node. In a more human, readable format, a pod with the label my-label: test is only scheduled to node X if there is no other pod with the label my-label: test. This leads to pods with label my-label: test being placed on different nodes.
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE
aws-node-glblv 1/1 Running 0 6h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
aws-node-m4crc 1/1 Running 0 6h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
aws-node-vfkxn 1/1 Running 0 6h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-dns-55ccbc9fc-8xjfg 3/3 Running 0 11m 192.168.124.74 ip-192-168-96-47.us-west-2.compute.internal
kube-dns-55ccbc9fc-ms577 3/3 Running 0 11m 192.168.85.228 ip-192-168-101-21.us-west-2.compute.internal
kube-proxy-cr6q2 1/1 Running 0 6h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-proxy-p6t5v 1/1 Running 0 6h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-proxy-z8hkv 1/1 Running 0 6h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
tiller-deploy-777677b45c-m9n27 1/1 Running 0 6h 192.168.112.21 ip-192-168-96-47.us-west-2.compute.internalDistributing instances of the same pod to different nodes has advantages but may have drawbacks as well. For example, if there are not enough eligible nodes or available resources, not all desired replicas of the pod can be scheduled, thus consigning them to pending status. If this is not the desired outcome, then instead of using the requiredDuringSchedulingIgnoredDuringExecution hard rule the preferredDuringSchedulingIgnoredDuringExecution soft rule should be utilized.
While the kube-dns deployment we have used so far in our examples may not be the best in terms of showing how pods can be colocated using pod affinity, we can still demonstrate how the deployment works. (A more relevant use case would be the running of pods on a distributed cache that should be collocated with pods using the cache)
The following diagram illustrates pod anti-affinity flow:
Pod affinity is similar to pod anti-affinity with the differences of the topologyKey not being limited to only kubernetes.io/hostname since it can be any label that consistently is placed on all pods.
$ kubectl edit deployment kube-dns -n kube-system
template:
metadata:
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
creationTimestamp: null
labels:
eks.amazonaws.com/component: kube-dns
k8s-app: kube-dns
my-label: test
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: my-label
operator: In
values:
- test
topologyKey: kubernetes.io/hostnameThe above pod affinity setting will cause our two kube-dns replicas to be placed on the same node. The question of which node is up to the Kubernetes scheduler (in this case it’s ip-192-168-165-61.us-west-2.compute.internal). If we wanted a specific node than the appropriate node affinity setting should have been placed onto the pod as well.
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE
aws-node-glblv 1/1 Running 0 6h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
aws-node-m4crc 1/1 Running 0 6h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
aws-node-vfkxn 1/1 Running 0 6h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
kube-dns-85945db57c-kk288 3/3 Running 0 1m 192.168.164.63 ip-192-168-165-61.us-west-2.compute.internal
kube-dns-85945db57c-pzw2b 3/3 Running 0 1m 192.168.157.222 ip-192-168-165-61.us-west-2.compute.internal
kube-proxy-cr6q2 1/1 Running 0 6h 192.168.96.47 ip-192-168-96-47.us-west-2.compute.internal
kube-proxy-p6t5v 1/1 Running 0 6h 192.168.165.61 ip-192-168-165-61.us-west-2.compute.internal
kube-proxy-z8hkv 1/1 Running 0 6h 192.168.101.21 ip-192-168-101-21.us-west-2.compute.internal
tiller-deploy-777677b45c-m9n27 1/1 Running 0 6h 192.168.112.21 ip-192-168-96-47.us-west-2.compute.internalThe following diagram illustrates the pod affinity flow:
Conclusion 🔗︎
Kubernetes provides building blocks to deal with various special scenarios with regards to deploying and running application components/services. In the next post we will describe the features that Pipeline provides to our user and how these rely on taints and tolerations, node affinity and pod affinity/anti-affinity, so stay tuned.







