






Banzai Cloud is happy to announce that it is an Amazon EKS Platform Partner.
Last year Amazon joined CNCF and announced plans to create their own Kubernetes service - Amazon EKS. The service has been launched this June, with the objective to make it easy for you to run Kubernetes on AWS without needing to install, operate, and maintain your own Kubernetes control plane.
At Banzai Cloud we are committed to provide support for Kubernetes on all major cloud providers for our users thus one of our priority was to enable Amazon EKS in Pipeline and take the DevOps and user experience to the next level by turning EKS into a feature rich enterprise-grade application platform.
The list of the currently supported cloud providers by Pipeline are: Amazon AWS EC2 Amazon AWS EKS Microsoft Azure AKS Google Cloud GKE
To appreciate the ease of managing Amazon EKS clusters with Pipeline let’s look at what it entails to launch an Amazon EKS cluster according to the official EKS documentation:
- AWS credentials
- Create an IAM role that Kubernetes can assume to create AWS resources
- Create Amazon EKS Cluster VPC for your cluster
- Take note of the SecurityGroups value for the security group that was created
- Take note the VpcId for the subnets that were created
- Take note the SubnetIds for the subnets that were created
- Create your Amazon EKS Cluster
- Configure kubectl for Amazon EKS
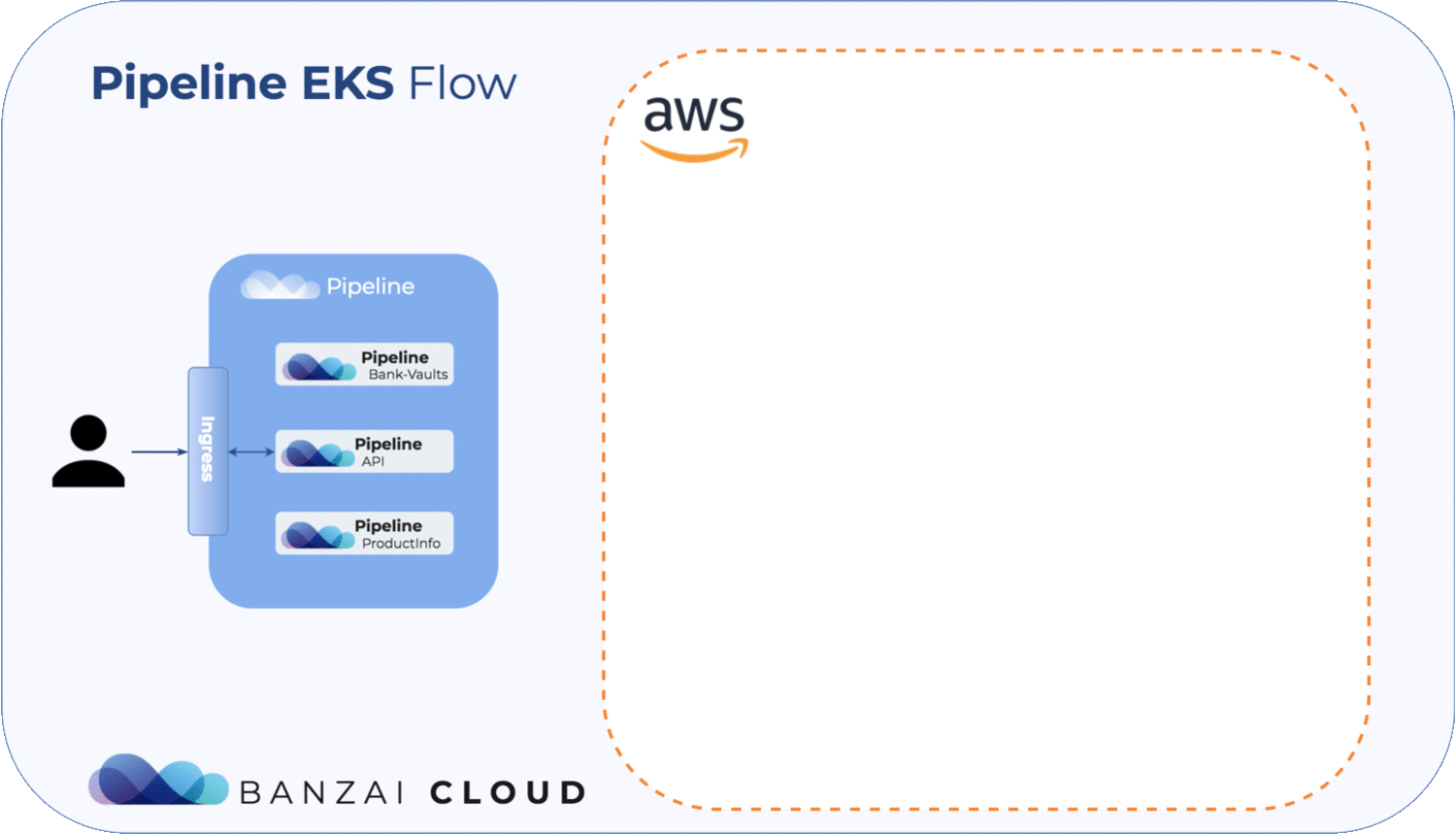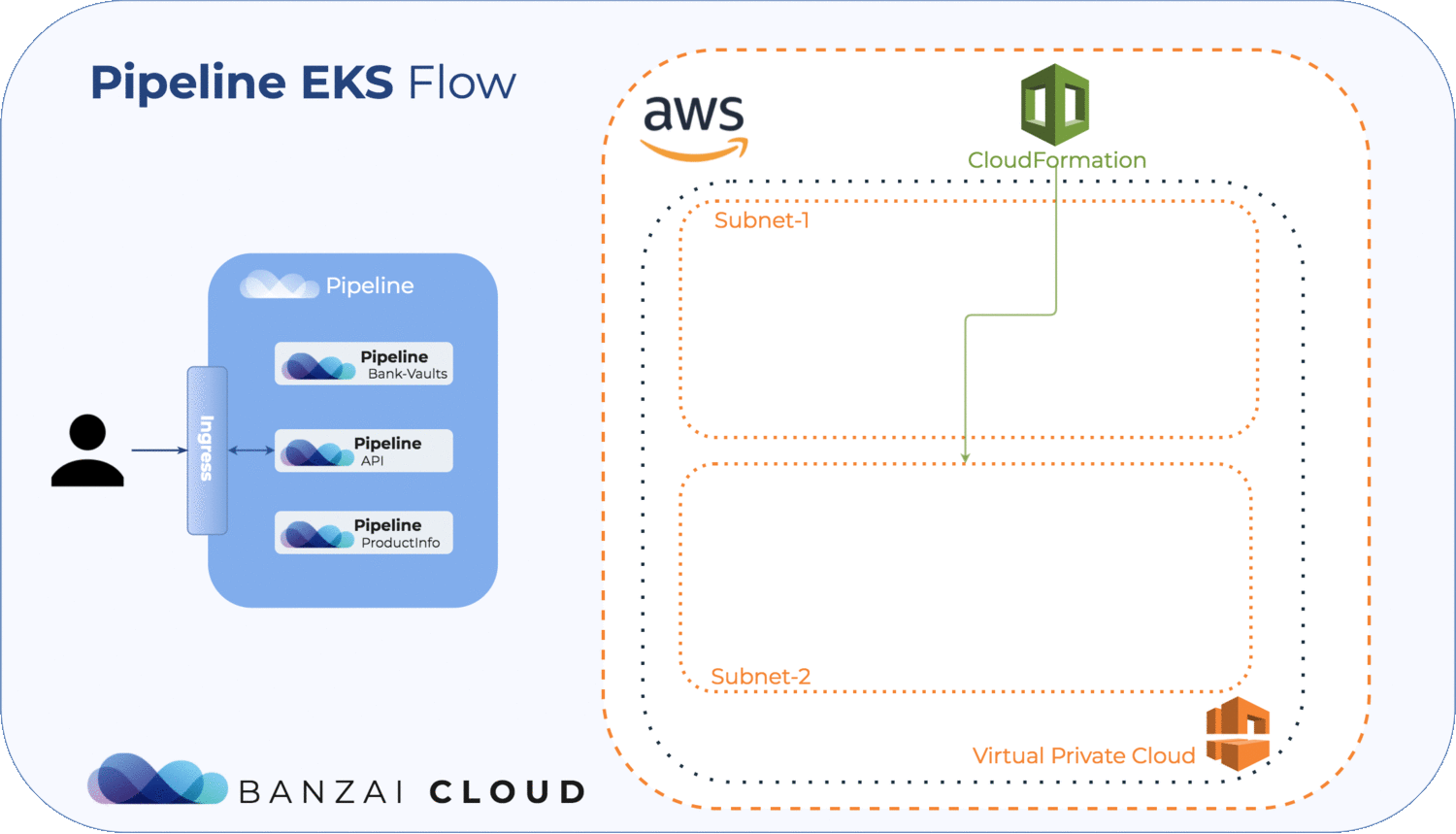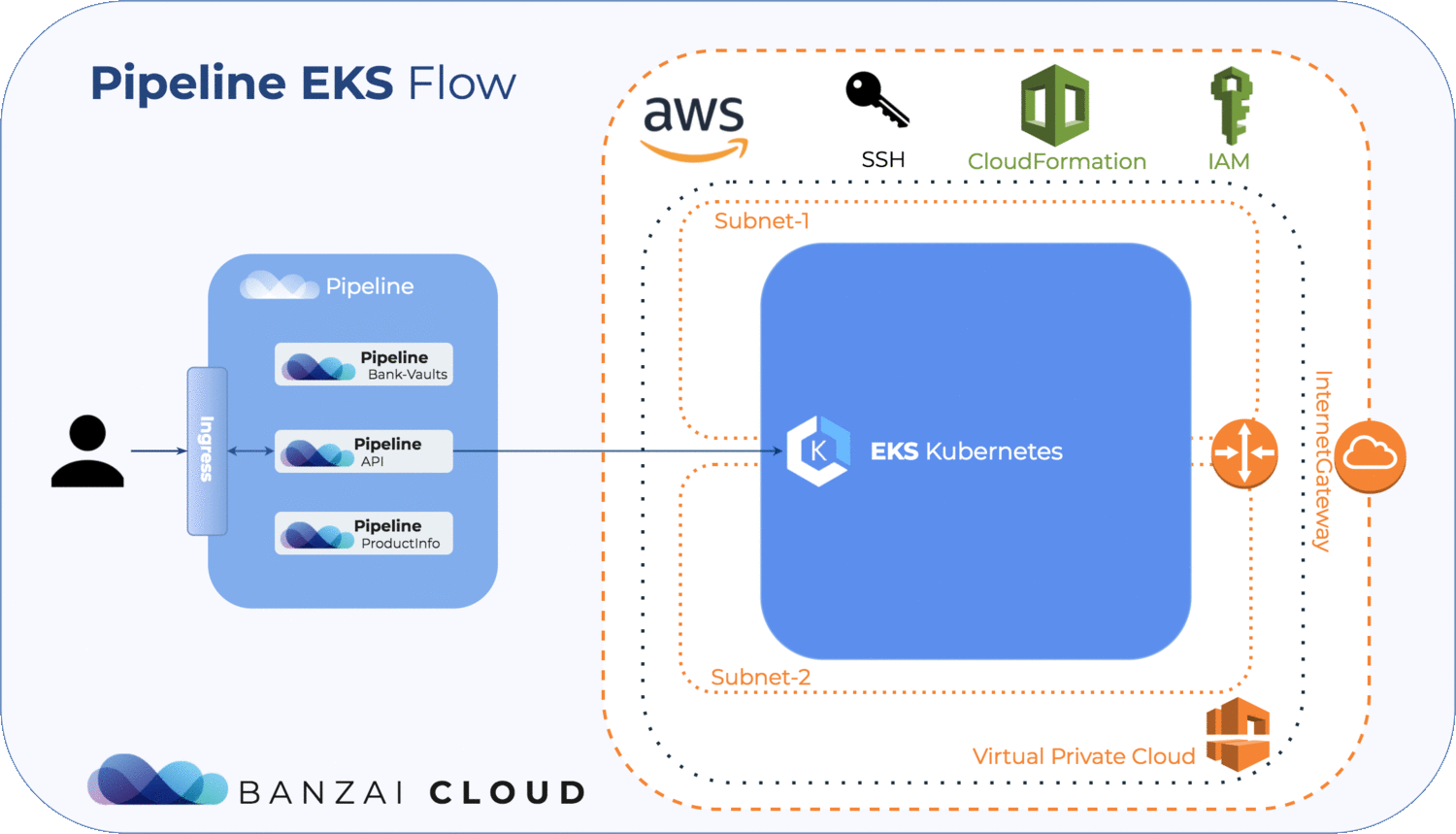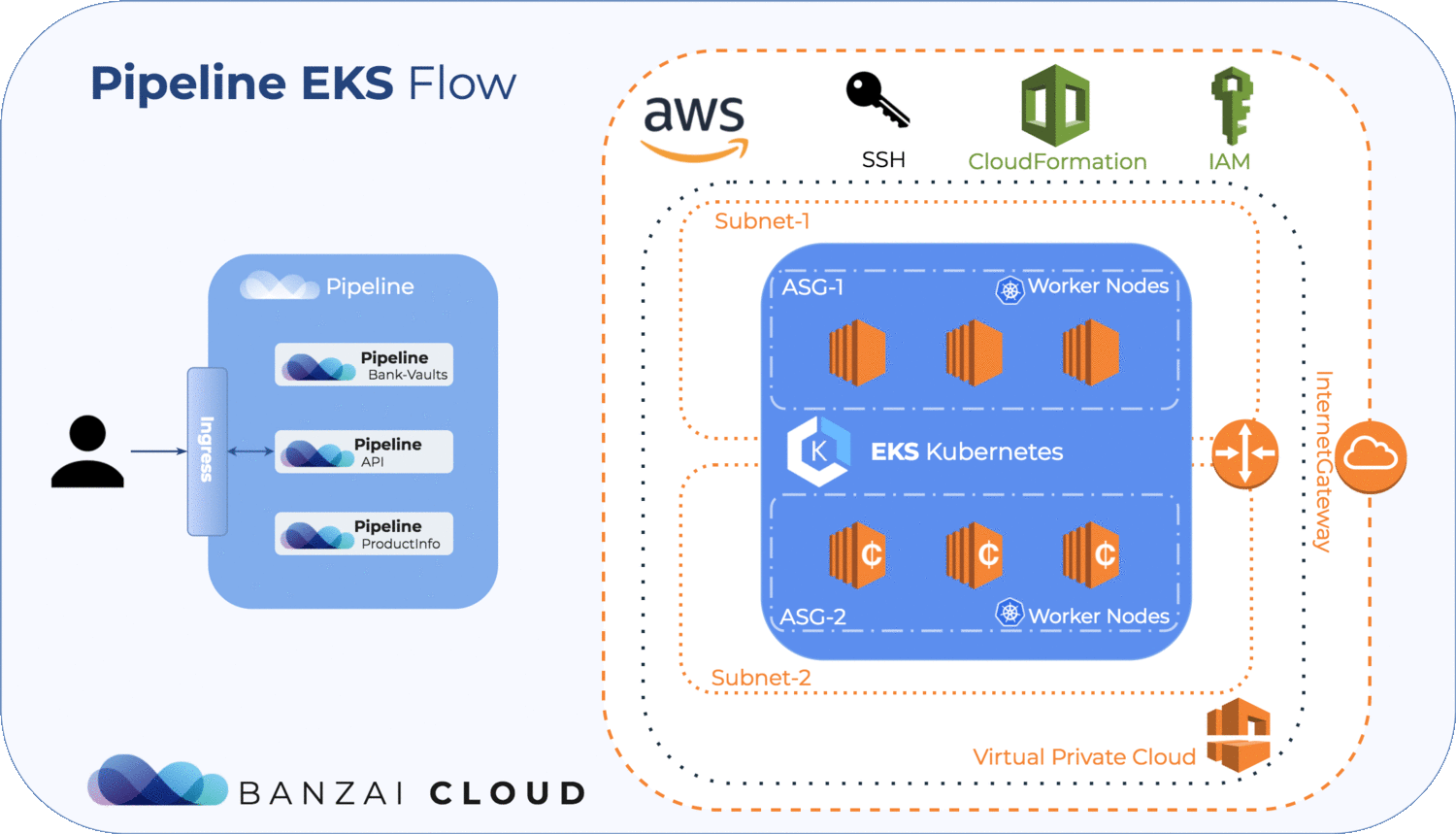
- Launch and configure Amazon EKS Worker Nodes
- Create K8s configuration map to enable worker nodes to join your cluster
- Create default Storage Class
Before reaching step 6 to create your Amazon EKS cluster there are quite a few rather manual steps that needs to be performed upfront. Once done with step 6 all the user has is a Kubernetes cluster with only master nodes, there are no worker nodes that would run applications deployed to the cluster. The user has to perform additional steps to get worker nodes up and running and have a complete K8s cluster ready to run your applications.
The Pipeline platform automates all these steps for the user. Moreover if any of these steps fail it will automatically rollback previous steps, thus not leaving behind unused resources. Beside automating the above steps Pipeline is empowering users with a whole set of additional features like:
- Bank-Vaults brings Vault-based enterprise grade security to Amazon EKS clusters
- Secure and centralized logging and monitoring out of the box for infrastructure and deployments
- The concept of heterogenous node pools
- The ability to think resource requirements such as CPU, memory, GPU or network performance and let Telescopes recommends a diverse set of cost optimized Kubernetes node pool layouts
- Spot price support
- Deploy applications with ease using Pipeline’s API
- Seamless and automated DNS management is provided to all services deployed to Amazon EKS
- Auto-scaling for Amazon EKS clusters and the deployed applications
- Cloud agnostic workflow and workload definitions - switch between any of the providers and reuse your existing flows
to name a few. This list is far from complete, please check out our posts for all the features that come with Pipeline.
When it comes to create Amazon EKS cluster, Pipeline reduces user’s concern only to two things:
- AWS credentials securely stored in Vault
- Desired cluster layout: node instance types, min/max/desired node count organized into one or more nodepools
Try it out 🔗︎
Create an Amazon EKS cluster with Pipeline 🔗︎
Pre-requisites 🔗︎
The AWS credentials that will be used to create the Amazon EKS cluster must be registered in Pipeline first:
curl -X POST \
http://{{url}}/api/v1/orgs/{{orgId}}/secrets \
-H 'Authorization: Bearer {{token}}' \
-H 'Content-Type: application/json' \
-d '{
"name": "my-amazon-secret",
"type": "amazon",
"values": {
"AWS_ACCESS_KEY_ID": "{{your_aws_access_key_id}}",
"AWS_SECRET_ACCESS_KEY": "{{your_aws_secret_access_key}}"
}
}'
- your_aws_access_key_id : AWS access key id of the IAM user used for creating Amazon EKS cluster
- your_aws_secret_access_key : AWS secret access key of the IAM user used for creating Amazon EKS cluster
The above REST request stores the passed in AWS credentials as a secret in Vault using Bank-Vaults as it must be stored securely. Security is an important topic for us and we take it seriously. You can find out more on how we handle security here.
The response will contain the id of the secret. We will use this id in subsequent requests where a secret_id is required and the credential is securely injected into the AWS client from Vault.
Create Amazon AKS cluster 🔗︎
curl -X POST \
http://{{url}}/api/v1/orgs/{{orgId}}/clusters \
-H 'Authorization: Bearer {{token}}' \
-H 'Content-Type: application/json' \
-d '{
"name":"ekscluster-1",
"location": "us-west-2",
"cloud": "amazon",
"secretId": "{{secret_id}}",
"properties": {
"eks": {
"version": "1.10",
"nodePools": {
"pool1": {
"instanceType": "m4.xlarge",
"spotPrice": "0.2",
"autoscaling": true,
"minCount": 1,
"maxCount": 2,
"count": 1
},
"pool2": {
"instanceType": "m4.large",
"spotPrice": "0",
"autoscaling": false,
"count": 1
}
}
}
}
}
'
If we look at the fields the user has to provide in the create cluster request we can state that the user doesn’t have to deal with IAM role, VPC, Subnets etc. The user is required to think of and provide only the location the Amazon EKS cluster to be created in, the size of the cluster, type of the nodes and features (spot price, cluster autoscaling) to be enabled. All the rest is taken care by Pipeline.
- secret_id - this is
idof the secret in Vault that contains the AWS credentials to be used for provisioning all the resources needed for creating the Amazon EKS cluster
- location - currently Amazon EKS service is enabled only in two locations:
us-east-1andus-west-2. Amazon will enable EKS service in all regions over time - nodePools - list of node pools that will be available for the worker nodes of the cluster
- autoscaling - controls wether cluster autoscaling is enabled for the particular node pool
- spotPrice - specify value
>0 forspotinstances to be used and=0 foron demandinstances
It worth explaining a bit more on the autoscaling field to have a good understanding what it controls. This enables autoscaling of the number of nodes in the node pool using Kubernetes cluster autoscaler. The minCount and maxCount defines the boundaries for the number of nodes in the node pool, while the count specifies the initial node count. Beside cluster autoscaling Pipeline makes possible for users to enable Horizontal Pod Autoscaling for deployments as well. We store all Amazon EKS and deployment metrics in Prometheus which Horizontal Pod Autoscaler can feed metrics from to drive the autoscaling.
You can find out more about the cluster autoscaling created with Pipeline by reading through these posts.
Cluster created
We can verify on the Amazon console whether the cluster was created.
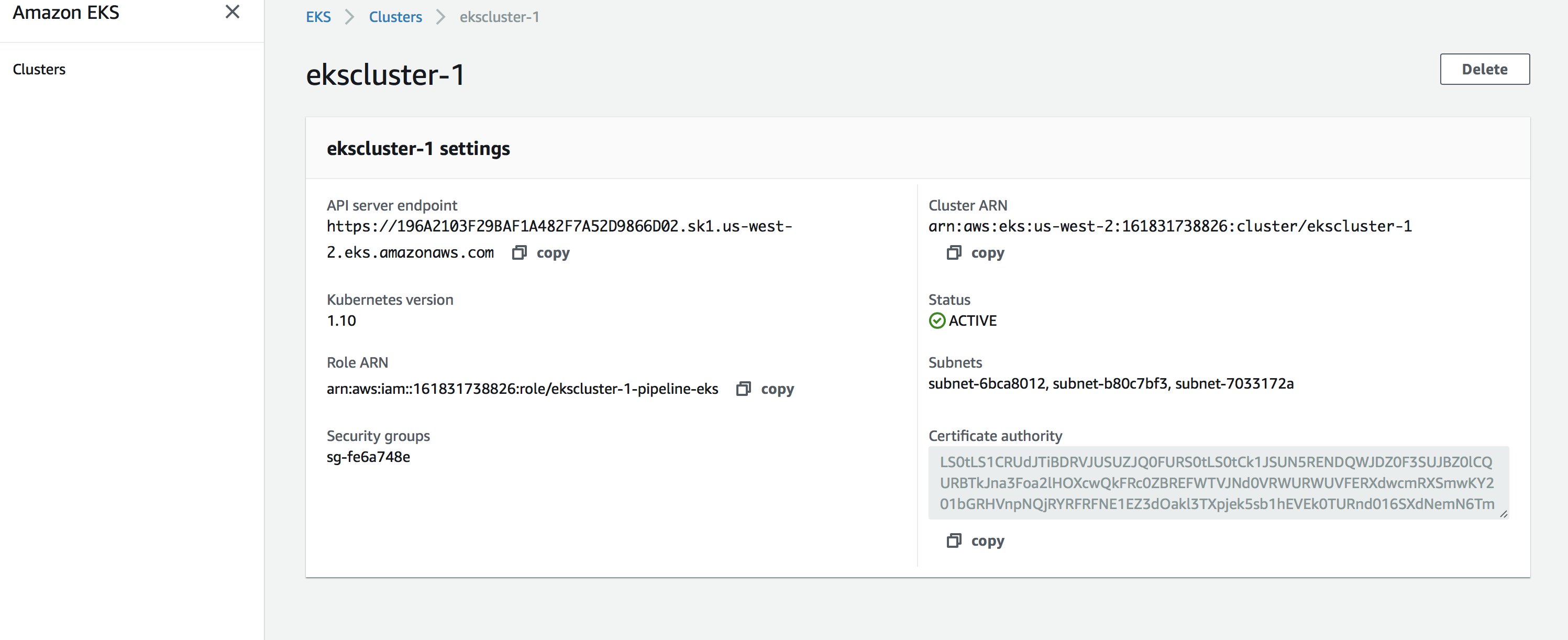
Currently Amazon console shows only the state of the Kubernetes API server. We can verify the list of EC2 instances that makes up the cluster by searching for instances that have the cluster name in their name.


Amazon Stacks
Pipeline uses CloudFormation templates and direct AWS API calls to provision all the resources needed for setting up an Amazon EKS cluster. The instantiated stacks and their parameters can be investigated on Amazon Console by filtering on the cluster name.
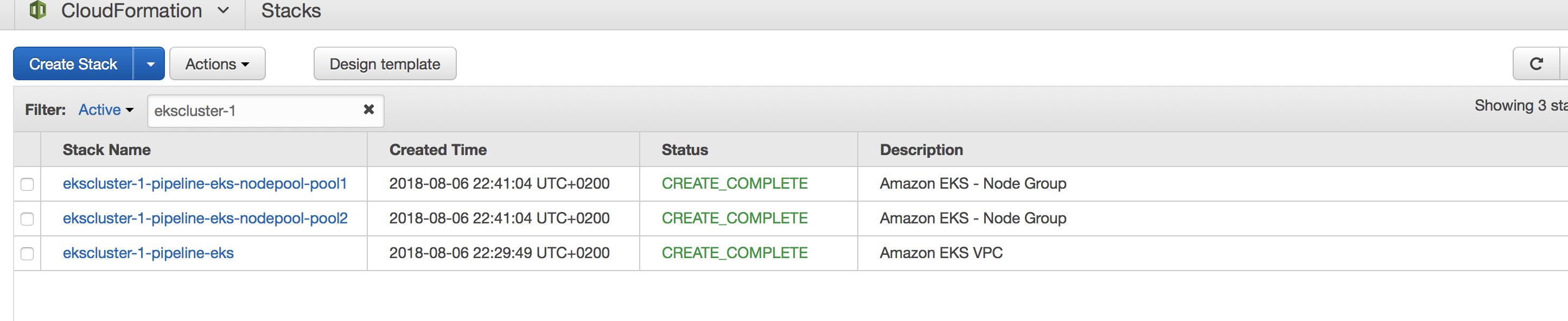
Access to cluster
In order to start using the cluster with kubectl we need the cluster config. The cluster config can be retrieved through Pipeline using:
curl -X GET \
http://{{url}}/api/v1/orgs/{{orgId}}/clusters/{{clusterId}/config \
-H 'Authorization: Bearer {{token}}' \
-H 'Content-Type: application/json' \Save the retrieved cluster config to a file and point $KUBECONFIG environment variable to it such as kubectl command will use this config by default.
There is one more step required here as Amazon EKS clusters use IAM to provide authentication to the cluster through the AWS IAM Authenticator for Kubernetes. If your kubectl client doesn’t support AWS IAM Authenticator follow these instructions to install aws-iam-authenticator.
Now we can verify the list of nodes that joined the Kubernetes cluster using kubectl:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-172-255.us-west-2.compute.internal Ready <none> 9m v1.10.3
ip-192-168-188-41.us-west-2.compute.internal Ready <none> 10m v1.10.3Similarly we can check running pods:
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default pipeline-traefik-7df789b479-557r8 1/1 Running 0 7m
kube-system autoscaler-aws-cluster-autoscaler-559df64965-6qv8f 1/1 Running 3 7m
kube-system aws-node-dc2fv 1/1 Running 1 10m
kube-system aws-node-df2p7 1/1 Running 0 10m
kube-system dashboard-kubernetes-dashboard-5f657df58f-vrgb5 1/1 Running 0 7m
kube-system kube-dns-7cc87d595-wx998 3/3 Running 0 16m
kube-system kube-proxy-x56xj 1/1 Running 0 10m
kube-system kube-proxy-x5rbv 1/1 Running 0 10m
kube-system tiller-deploy-777677b45c-8gpn5 1/1 Running 0 10m
pipeline-infra pipeline-dns-external-dns-cddf5f778-t4vz7 1/1 Running 0 8mThe following diagram shows at high level the various components that Pipeline pre-loads into the created cluster to provide reach feature set to users like:
- centralized log collection
- monitoring using Prometheus
- autoscaling via cluster autoscaler and horizontal pod autoscaler
- DNS management
- secure secret store via Bank-Vaults
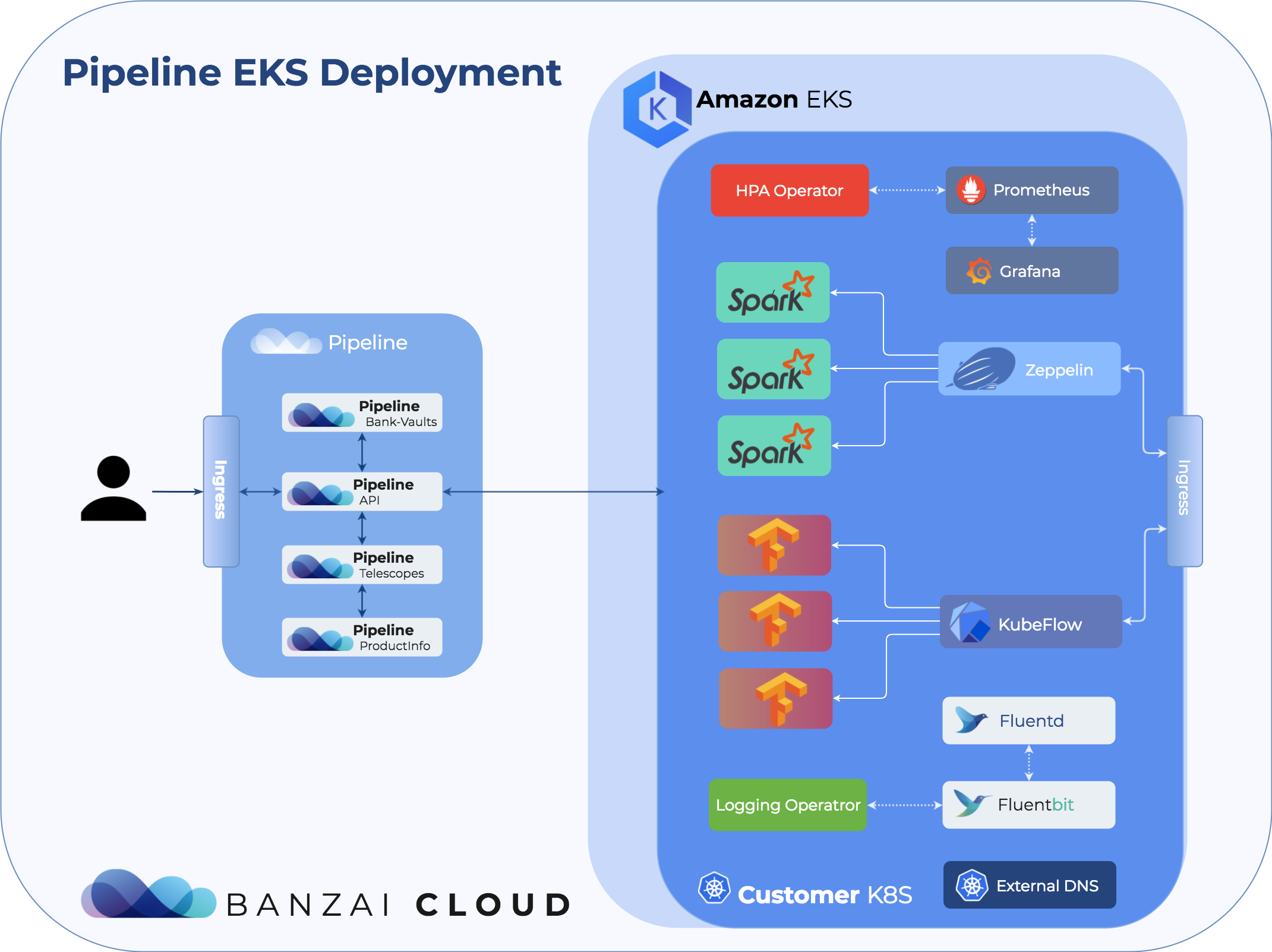
Further enhancements - the list continues
From the above we can see that Pipeline simplifies the provisioning of Amazon EKS cluster for users by doing the heavy lifting of creating VPC, subnets, IAM roles etc. Users have to only deal with cluster layout and cluster features.
With Cloudinfo we can query the available instance types per region and their prices through a REST API. This service provides the necessary information for Telescopes - a cluster instance types, and full cluster layout recommender engine. Telescopes based on predefined resource requirements such as CPU, memory, GPU or network performance, it recommends a diverse set of cost optimized Kubernetes node pool layouts.
For users its easier to think in terms resource needs of their deployments / applications and don’t deal with the cloud provider specific cluster layout at all. The initially provided cluster layout may not fit resource needs of the deployed applications over time and the cluster layout must be changed dynamically. Here comes into picture the autoscalers - as they receive cluster and application metrics from Prometheus to scale the cluster up/down appropriately while taking into account recommendations from Telescopes.
For more details on Telescopes check this post.
UI integration 🔗︎
We are finishing the first draft of the UI, with support for Amazon EKS - as a service - so stay tuned.




