






tl;dr: 🔗︎
The Supertubes approach to handling Kafka ACLs in Kubernetes provides a clearer way of seeing what’s actually happening by introducing a logical separation of ACL components under the names:
KafkaACL,KafkaRoleandKafkaResourceSelector.
That way we get reusable parts that help maintain the system in the long term, allowing us to handle ACLs with a declarative approach, and overcoming the difficulties inherent in handling ACLs in a Kubernetes environment.
The Why 🔗︎
We rely on Istio service mesh to be the foundation of our Supertubes Kafka clusters because it provides seamless security checks for traffic between Kafka components and clients from outside the cluster. It accomplishes this automatically, through mutual TLS authentication with builtin certificate rotation and management, and is actually faster than Kafka’s builtin TLS implementation.
For further benefits of running Kafka inside an Istio service mesh check our The benefits of integrating Apache Kafka with Istio blog post.
In an environment like this, handling Kafka ACLs can be difficult.
While you could use kafka-acls.sh, the traditional solution, over time it can be difficult to operate a Kafka cluster inside a Kubernetes cluster and keep the ACLs up to date.
When working in such an environment, there are two ways to set ACLs.
You can set them from outside of Kubernetes, meaning you will have to setup a certificate in order to maintain access to the cluster. Or you can set them from inside the cluster by executing into a pod that already contains kafka-acls.sh, which isn’t ideal either from a usability perspective.
To complicate things, ACLs are difficult to follow. We wanted something that separates
- What somebody can access
- When somebody has access to it
- and Who the somebody is that we’re giving permissions to.
Before getting into the nitty-gritty, let’s take a look at the following example ACL configurations for the Kafka Schema Registry.
If we used kafka-acls.sh, for instance, we would have to execute the following commands against our cluster.
bin/kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \
--add --allow-principal 'User:schema-registry' --allow-host '*' \
--producer --consumer --topic _schemas --group schema-registry
bin/kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \
--add --allow-principal 'User:schema-registry' --allow-host '*' \
--operation DescribeConfigs --topic _schemas
bin/kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \
--add --allow-principal 'User:schema-registry' --allow-host '*' \
--operation Describe --topic _schemas
bin/kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \
--add --allow-principal 'User:schema-registry' --allow-host '*' \
--operation Read --topic _schemas
bin/kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \
--add --allow-principal 'User:schema-registry' --allow-host '*' \
--operation Write --topic _schemas
bin/kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \
--add --allow-principal 'User:schema-registry' --allow-host '*' \
--operation Describe --topic __consumer_offsets
bin/kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \
--add --allow-principal 'User:schema-registry' --allow-host '*' \
--operation Create --cluster kafka-cluster
So what we are doing here exactly?
Quite a few things are happening here.
First, we have set both consumer and producer access to the topic _schemas and consumer group schema-registry for the User:schema-registry service principal. So far so good.
In the second through fifth commands, we set DescribeConfigs, Describe, Read, and Write permissions to the same topic.
Lastly, we set Describe to the __consumer_offsets topic, alongside the Create operation for the kafka cluster.
As you can see, with some repetition configuring ACLs quickly becomes a relatively labor-intensive job, which is the perfect way to make typos and mistakes - something we absolutely do not want when talking about security.
Let’s take a look at how we would solve this problem.
We provide a way that is not just declarative - in line with the GitOps and the Configuration as Code trends of today - but is also easier to maintain, since we provide many reusable shortcuts in the form of KafkaRoles and KafkaResourceSelectors.
KafkaResourceSelectors - Beginning the What 🔗︎
Let’s start with figuring out what we’re trying to protect with the authorization.
This is something that’s getting used very frequently, over and over again. Just think about the example given above.
We used the topic __schemas five times over the course of seven commands, and that was just one principal.
Elevating this topic into its own CR gives us the flexibility to reuse it, not just making our lives easier but making the solution more error resilient as well.
KafkaResourceSelectors are filters for one or more Kafka Resources of the same type. These types can be any of the following:
topicfor when you would like to apply them to Kafka topicsgroupfor consumer groupstransactionalIdwhen you want to ensure a single writer- and
clusterwhen you want to impact the whole cluster
Here are some examples:
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaResourceSelector
metadata:
name: schemas-topic
namespace: kafka
spec:
type: topic
name: _schemas
pattern: literal
Here, we’re selecting the topic named _schemas. By saying that the pattern is literal we’re making the determination that it should be an exact match for the name field.
You can also use pattern prefixed to suggest that the name field act as a prefix, creating even more versatile selectors by grouping together multiple topics in the process simultaneously.
This is especially handy if you have a lot of smartly named topics, and you don’t want to create a selector for every single one of them.
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaResourceSelector
metadata:
name: consumer-offsets-topic
namespace: kafka
spec:
type: topic
name: __consumer_offsets
pattern: literal
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaResourceSelector
metadata:
name: schema-registry-group
namespace: kafka
spec:
type: group
name: schema-registry
pattern: literal
ResourceSelectors are a tool that help us to keep from repeating ourselves over and over again, every time we’d like to refer to a Kafka resource.
They also provide a centralized place to modify and track all our resources handled by ACL.
With a simple
kubectl get KafkaResourceSelector
command we can see how quickly which resource is covered by our ACLs, making it easy to spot if we’re missing something.
KafkaRoles - Providing the When 🔗︎
Roles have been part of access control systems for years. We don’t have to look very hard for an example, since Kubernetes RBAC works in practically the same way.
It builds on the common principle we discussed in KafkaResourceSelectors, easing our job by encouraging reusability and helping us make the process more clear, followable, and therefore highly maintainable.
KafkaRoles provide a way to easily group multiple ACL permissions into one single reusable resource.
Let’s look at our examples:
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaRole
metadata:
name: consumer
spec:
topic: # operations on topics
allow:
- read
- describe
group: # operations on consumer groups
allow:
- read
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaRole
metadata:
name: producer
spec:
topic:
allow:
- write
- describe
- create
transactionalId:
allow:
- write
- describe
consumer and producer permissions are so frequently necessary that kafka-acls.sh has built-in flags to handle them.
We wanted to take the next step and provide a way to create your own custom groups of ACL operations.
The two KafkaRoles listed above consumer and producer are deployed by default when you install Supertubes, meaning they’re ready to use, and you do not have to manually apply them to the cluster.
In spec you can specify your allow and deny permissions under the same four resource types listed in ResourceSelectors:
topicgrouptransactionalIdcluster
Also, it’s important to note that roles are not mandatory. They are a reusable tool to ease headaches that might arise from overuse of copy-paste design patterns, saving you from a handful of bugs in the long run but also helping you keep a tight grip on access control to your Kafka cluster.
Imagine one day wanting to add a read operation to all producers. Unlike with kafka-acls.sh, you just have to add read under the producer role, and it will automatically get propagated to every KafkaACL CR that references it.
So how does all this come together?
KafkaACL - Providing the Who 🔗︎
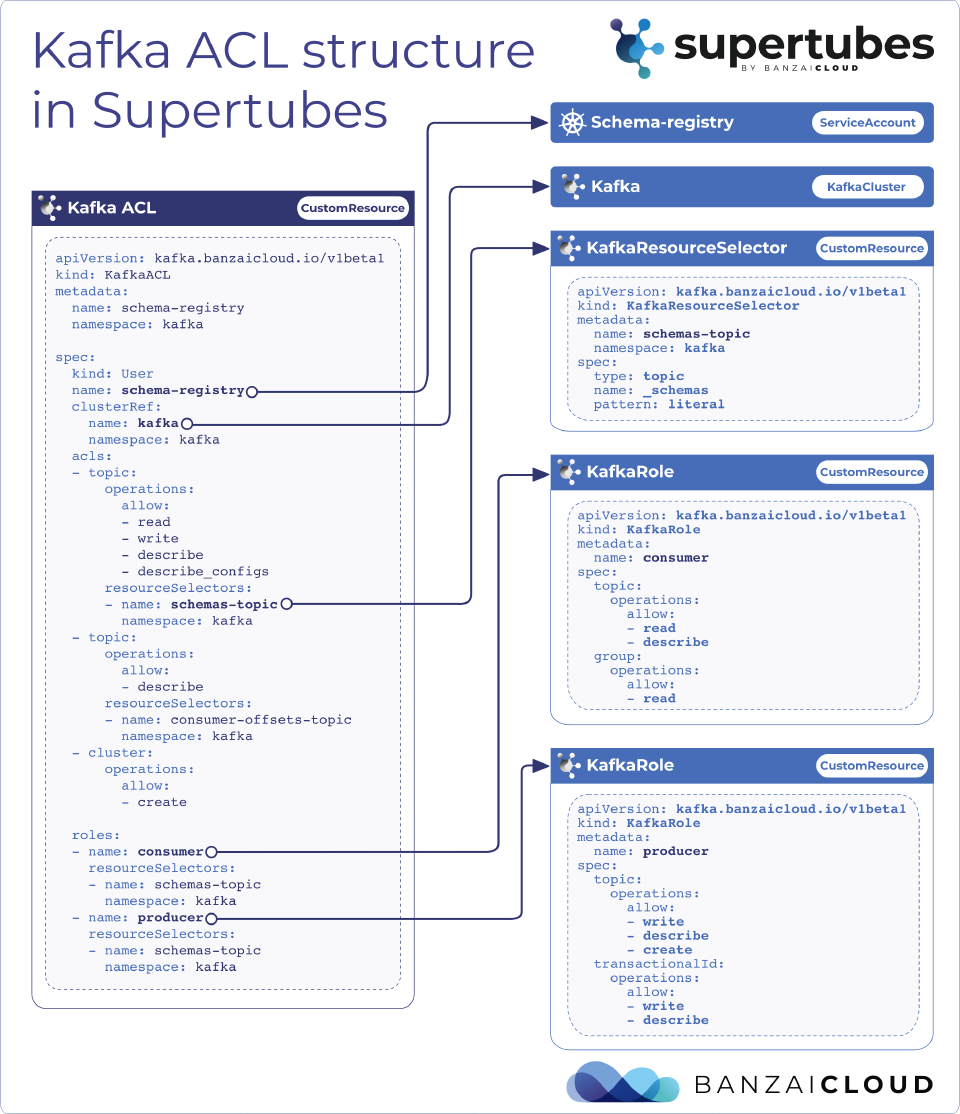
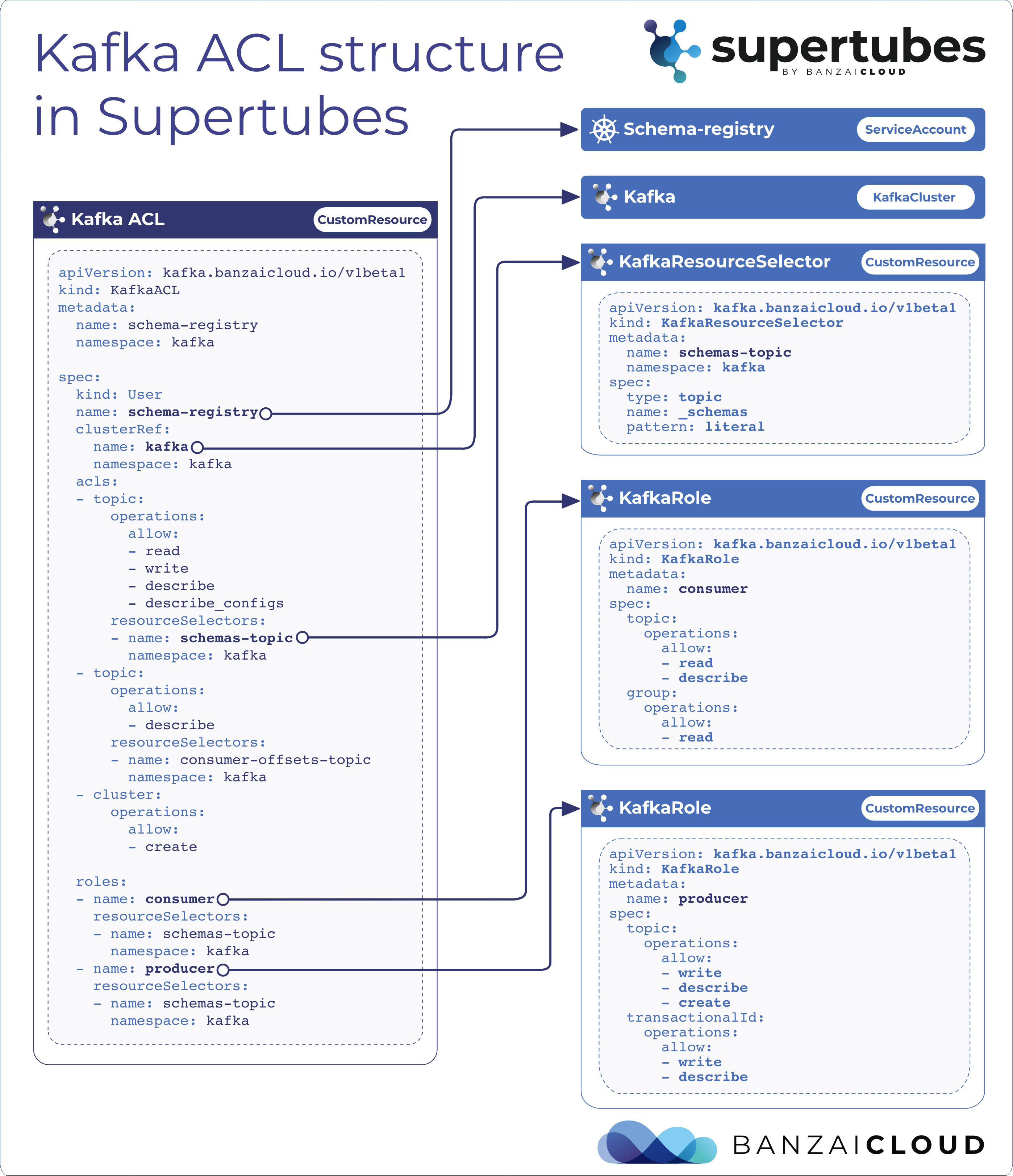
The KafkaACL custom resource is at the heart of this system; it provides a binding between a subject and the two other components we’ve discussed, KafkaRole and KafkaResourceSelector.
Through it, you can tell a system which principal you would like to apply to the permissions defined in Role,
and which kafka resource you’d like to grant access to through ResourceSelector.
Let’s take a look.
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaACL
metadata:
name: schema-registry
namespace: kafka
spec:
kind: User
name: schema-registry
clusterRef:
name: kafka
namespace: kafka
acls:
- topic:
operations:
allow:
- read
- write
- describe
- describe_configs
resourceSelectors:
- name : schemas-topic
namespace: kafka
- topic:
operations:
allow:
- describe
resourceSelectors:
- name : consumer-offsets-topic
namespace: kafka
- cluster:
allow:
- create
roles:
- name: consumer
resourceSelectors:
- name: schemas-topic
namespace: kafka
- name: schema-registry-group
namespace: kafka
- name: producer
resourceSelectors:
- name: schemas-topic
namespace: kafka
That’s a lot of YAML, but it’s really quite simple, so stay with me. If we go through spec, the first thing we have to provide is the subject of the ACL.
kind: User
name: schema-registry
Here, you need to give a kind which is User or anything else that the configured Kafka authorizer (see authorizer.class.name kafka config for details) supports, then a name, which should be the exact name of the service account we’d like to give the permissions to.
Wait, service account?
Yes. Basically, we authenticate Kafka clients using their Kubernetes namespaces and service accounts. The power of combining Kafka, Istio, and Kubernetes really shines through here, sprinkled with some WebAssembly Envoy filters. The best part is that you don’t actually need to know the minutiae of how this works, because Supertubes handles all of it behind the scenes for you. If that piqued your curiosity and you want to know more, check out our previous blog that goes into more detail.
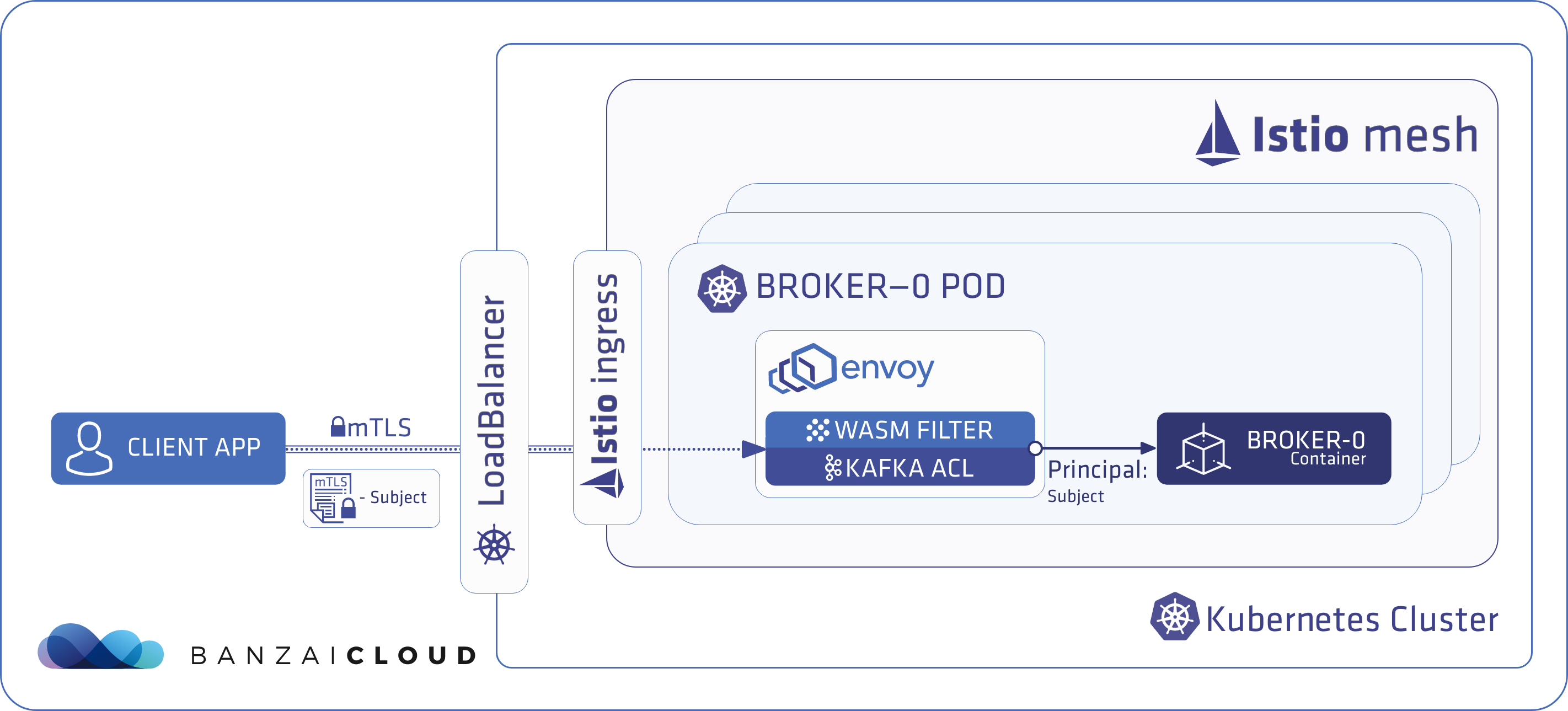
Back to our example. The next thing you have to do is determine which KafkaCluster you’d like to bind the ACL to.
A lot of our users use multiple Kafka clusters on a single Kubernetes cluster, which helps you separate ACLs from each other.
clusterRef:
name: kafka
namespace: kafka
Then comes the lion’s share of the YAML.
acls:
- topic:
operations:
allow:
- read
- write
- describe
- describe_configs
resourceSelectors:
- name : schemas-topic
namespace: kafka
- topic:
operations:
allow:
- describe
resourceSelectors:
- name : consumer-offsets-topic
namespace: kafka
- cluster:
allow:
- create
acls let you define inline permissions for your principal. Seem familiar? It’s the same way we define them in KafkaRoles.
If you remember, we said that Roles are optional, and acls is exactly the reason why.
KafkaRoles are reusable sections of acls, so you can use them again somewhere else later, avoiding duplication in the process.
That being said, acls are still very useful; here we’re using them in one-off operations, so that we don’t need to create Roles with only one operation in them.
In resourceSelectors we can provide a list of selectors, telling the system What resource we are trying to bind the operations to.
Note that the cluster part is without a resourceSelector. That’s because, in this case, the clusterRef at the top of the CR is being used as an anchor for the operation.
Last but not least comes the optional part, providing a place where we can reference and use our KafkaRoles CRs.
Notice that Roles are without a namespace, so you can reuse them across your other KafkaClusters.
roles:
- name: consumer
resourceSelectors:
- name: schemas-topic
namespace: kafka
- name: producer
resourceSelectors:
- name: schemas-topic
namespace: kafka
In the diagram below you can see how it all comes together.
Remember, both consumer and producer roles are on the cluster and are ready to be used when you install Supertubes. The only thing you have to do is set the authorizer in your KafkaCluster CR
readOnlyConfig: |
authorizer.class.name=kafka.security.authorizer.AclAuthorizer
allow.everyone.if.no.acl.found=false
and create the KafkaACL and the KafkaResourceSelector CRs. The latter, of course, is reusable,
and helps you out in the long run.
One thing that you might have noticed is that this solution provides no way of setting a host field where you can specify the IP from which the principal can access resources. The reason for that is simple if you think about it.
In Kubernetes, pods do not have a permanent IP address; they move around the cluster constantly and in accordance with a variety of factors, mainly resource allocation quotas and what the Scheduler thinks is the best place in any given moment for the pod. But that’s great! One of the reasons we love Kubernetes is this kind of flexibility, and the fact that the vast majority of the time, we don’t even have to think about IPs in the cluster - making our job that much easier.
Filtering on the client IP address is also not that great an idea if the client comes from outside the cluster.
IPs can be spoofed, making it easy to walk around the problem.
So what can we do?
Istio provides many ways of denying a client’s access to the service mesh, in the process denying access to the Kafka cluster as well. The ultimate solution relies on certificates for authentication of the client. We already do that, but currently it only works the one way. We can give certificates to trusted clients, but Istio does not support revoking those certificates as of right now. Until Istio provides support for certificate revocation lists, we can instead, as a work around, set the expiration of a given certificate to as soon as possible and renew it only when required - a good security practice in its own right.
What’s next 🔗︎
The feedback we get from our customers and from the community is overwhelmingly positive. I’d like to thank all of you for reaching out to us and sharing your thoughts and helping to shape the future of Supertubes in ways we hadn’t even begun to think about. We are not done yet though, and are continuously improving and developing new features and capabilities. We always have new ideas that we’re eager to show you. Here is a little sneak peek of what’s next on our roadmap:
- Observability and management UI leveraging Istio telemetry data and the ability to drill down into the route cause of anomalies. Thanks to Istio we can provide data and telemetry about the state of the Kafka cluster that wasn’t previously possible.
- Envoy protocol filter-based audits as an extension of the Envoy Kafka protocol filter
About Supertubes 🔗︎
Banzai Cloud Supertubes (Supertubes) is the automation tool for setting up and operating production-ready Apache Kafka clusters on Kubernetes, leveraging a Cloud-Native technology stack. Supertubes includes Zookeeper, the Koperator , Envoy, Istio and many other components that are installed, configured, and managed to operate a production-ready Kafka cluster on Kubernetes. Some of the key features are fine-grained broker configuration, scaling with rebalancing, graceful rolling upgrades, alert-based graceful scaling, monitoring, out-of-the-box mTLS with automatic certificate renewal, Kubernetes RBAC integration with Kafka ACLs, and multiple options for disaster recovery.







