One of the key features of our container management platform, Pipeline, and our CNCF certified Kubernetes distribution, PKE, is their ability to seamlessly form and run federated clusters across multi- and hybrid-cloud environments. While users of the Pipeline platform often have different requirements depending on whether they take a single or multi-cloud approach, they’re usually built around two key features:
- Multi-cloud application management
- Backyards, an Istio-based automated service mesh for multi- and hybrid-clouds
Today, we’re happy to announce that we’ve added support for Kubernetes federation v2, which is being made available as a beta feature in the Pipeline platform.
As we briefly touched on in our multi-cluster/multi-cloud deployment post, we’ve made it easier to manage application lifecycles via the introduction of cluster groups across multiple clusters/clouds. However, the focus, then, was mostly on deployments. With Kubernetes federation v2 we’ve extended this ease of management to K8s resources, ingress, services and more.
tl;dr: 🔗︎
- We’ve added cluster federation with KubeFed to Pipeline, creating a way to distribute any Kubernetes resource, and to expose services and ingresses via DNS.
- Keep reading if you want to better understand the similarities and differences between Pipeline’s multi-cluster deployment and our Istio operator-based service mesh topologies.
- Pipeline simplifies and automates the setup of federated clusters, deploys a federation control plane, and adds or removes member clusters from a given federated topology.
- We’ll also give you a working example of how to deploy our Satellite application into a federated cluster that spans across three different clouds.
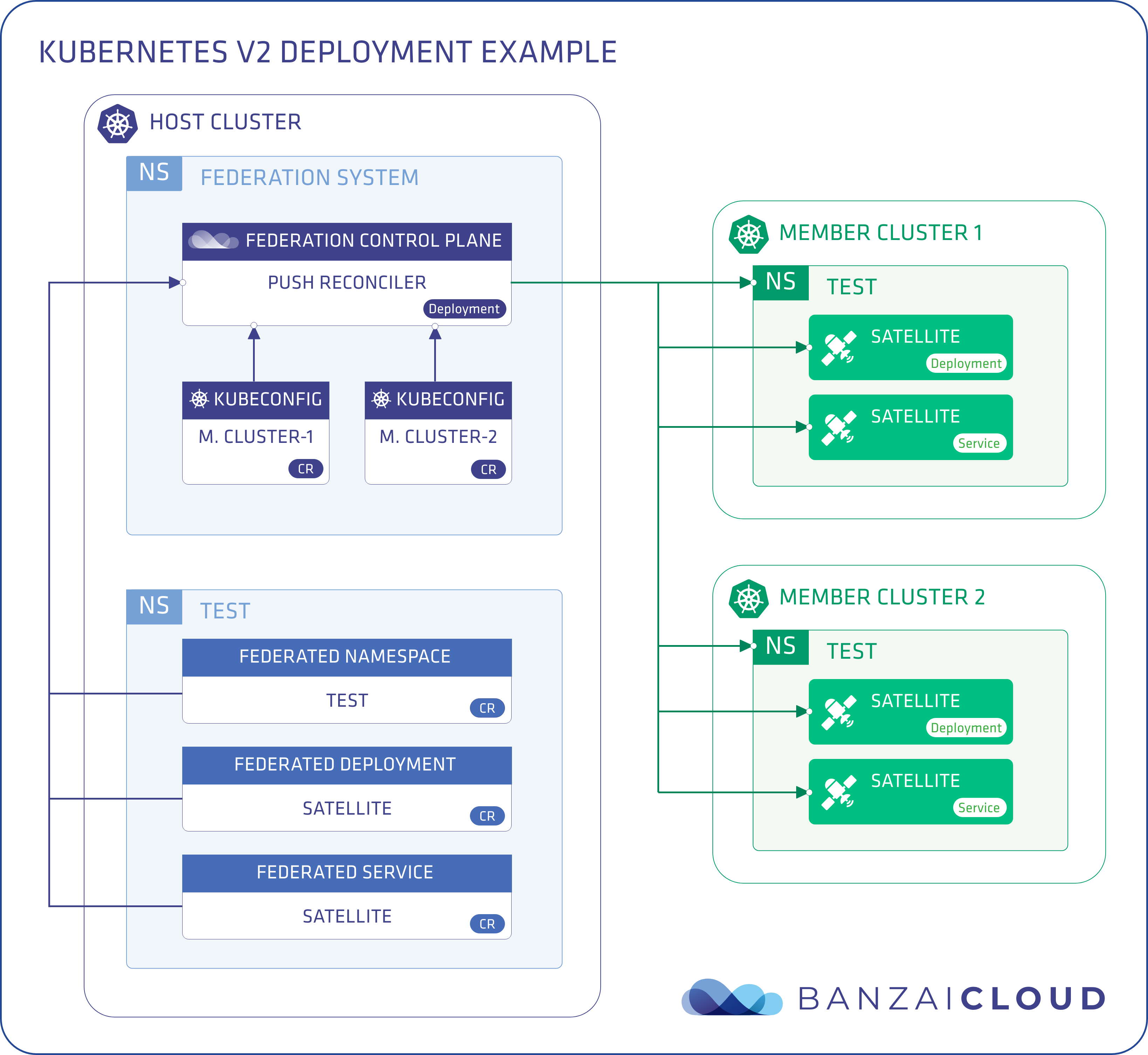
Introducing KubeFed v2 🔗︎
KubeFed v2 is the official Kubernetes cluster federation implementation. It allows users to coordinate the configurations of multiple Kubernetes clusters on the basis of a single set of APIs from within a Host cluster.
The approach of KubeFed v2 is fundementally different from that of the first version of federation; instead of creating new resources and an API server, it builds and uses custom resources extensively.
KubeFed is configured from two types of information:
- A type configuration that indicates which API types KubeFed should handle, and is stored in FederatedTypeConfig.
- A cluster configuration that determines which clusters KubeFed should target, stored in KubeFedCluster and KubeFedConfig
A Host cluster runs the KubeFed control plane, which contains a KubeFedConfig and a KubeFedCluster resource for each member cluster. All federated resources are deployed to the Host and replicated from there to the federation’s member clusters. The recommended way to install KubeFed is to deploy it with the official Helm chart. Once you have it up and running, you can add or remove clusters, enable types, and federate resources using the kubefedctl utility.
Basically, the KubeFed control plane runs a variety of different controllers, depending on the configuration of features which can be enabled or disabled via FeatureGates. Let’s take a brief look at these features.
PushReconciler - Resource distribution across federated clusters 🔗︎
KubeFed can federate any Kubernetes resource, including custom resources that use the type configuration mentioned above. Within type configurations there exist three fundamental concepts:
- Templates define the representation of a common resource across clusters
- Placements define which clusters a resource will appear in
- Overrides define per-cluster, field-level variation that apply to the template
When you enable the federation of a Kubernetes resource you will get a FederatedTypeConfig, indicating how KubeFed should handle that resource, and a Custom Resource Definition, describing how the Kubernetes API server should handle the federated resource.
Let’s take a look at an example of a FederatedDeployment:
apiVersion: types.kubefed.k8s.io/v1beta1
kind: FederatedDeployment
metadata:
name: test-deployment
namespace: test
spec:
template:
<< DEPLOYMENT SPEC >>
placement:
clusters:
- name: cluster2
- name: cluster1
clusterSelector:
matchLabels:
region: eu-west-1
overrides:
- clusterName: cluster2
clusterOverrides:
- path: spec.parallelism
value: 2
In the placement section you can either explicitly name member clusters, or use a clusterSelector to select clusters based on various labels. This is similar to the Kubernetes labels selectors that we’re already familiar with. In the overrides section you can either use explicit field overrides, or, if you need something more sophisticated, Json patches.
PushReconciler automatically pushes out any changes in the federated resource to all member clusters selected for placement. However, if there should be a mismatch between the desired state described in the federated resource and the actual state of a replicated resource - like in the event of having accidentally deleted a replicated resource from one of the member clusters - it will automatically re-sync the resource to reflect that desired state.
Federated resources are namespace-scoped. KubeFed can be configured to scope globally or for a given namespace. If the latter, the control plane watches only it’s own namespace, and all the resources that we’d like to federate must be placed there. If its scope is global, we can place the federated resources in any namespace, but we will first need to create a FederatedNamespace to distribute our namespace. The chosen namespace on the Host cluster has to then be created, before the federated resources can be deployed.
CrossClusterServiceDiscovery and FederatedIngress 🔗︎
Multi-Cluster Ingress DNS gives us the ability to programmatically manage the DNS resource records of Ingress objects through ExternalDNS integration. If this feature is enabled, KubeFed will be watching for Service & Ingress resources and will register them in ExternalDNS. All we need to do is to create a Domain resource describing our domain, and a ServiceDNSRecord (or IngressDNSRecord if we have Ingress resources) to link our exampleDomain to the exampleService. You can see an example of this, below:
apiVersion: multiclusterdns.kubefed.k8s.io/v1alpha1
kind: Domain
metadata:
# Corresponds to <federation> in the resource records.
name: exampleDomain
# The namespace running the KubeFed control plane.
namespace: federation-system
# The domain/subdomain that is set up in your external-dns provider.
domain: example.try.pipeline.banzai.cloud
apiVersion: multiclusterdns.kubefed.k8s.io/v1alpha1
kind: ServiceDNSRecord
metadata:
# The name of the sample service.
name: exampleService
# The namespace of the sample deployment/service.
namespace: test
spec:
# The name of the corresponding `Domain`.
domainRef: exampleDomain
recordTTL: 300
Once we submit these, KubeFed will create a DNSEndpoint object that lists DNS names and targets. ExternalDNS should be configured to watch for DNSEndpoint resources. We can find more detailed information about this in the KubeFed user guide.
Note that, if you enable and use federation in Pipeline, all these configurations and all the heavy lifting is done for you, automatically.
SchedulerPreferences - Dynamically schedule workloads based on custom preferences 🔗︎
This a generic feature, which allows us to write our own workload Scheduler. Currently, there’s only one implementation ReplicaSchedulingPreference; we have a JobScheduler coming soon, which will manage the scheduling of Jobs across clusters.
ReplicaSchedulingPreference provides an automated mechanism for the distribution and maintenance of the total number of replicas for Deployment, or of ReplicaSet-based federated workloads, on federated clusters. This is based on high level user preferences, which include the semantics that pertain to the weighted distribution and limits (min and max) of distributing these replicas. These preferences also include semantics that allow the dynamic redistribution of replicas. Note that, in some cases, replica pods will remain unscheduled in certain clusters (for example, due to insufficient resources in that cluster).
Deploying KubeFed with Pipeline 🔗︎
We previously introduced the notion of Cluster Groups in our post about Multi-cluster deployments. If you need to brush up on the subject, go ahead and do so now. One important aspect of a Cluster Group is that we can add, enable and disable different Cluster Group Features. Currently, Pipeline supports three Cluster Group Features:
These are Cluster Group Features, they simply operate on different Kubernetes resources; at a very high level, these group multiple Kubernetes clusters across single, multi or hybrid-cloud environments and greatly simplify their creation, management and operation.
To continue in this theme, a Cluster Group Feature can be enabled or disabled on a Cluster Group, or can be given custom properties, with only a few simple words. The Pipeline API is generic, and, if we wanted to extend and create a new feature, all we would have to do is to implement a FeatureHandler wherein we would be notified about Cluster Group changes.
Once we’ve created our cluster group, we’ll need to know/specify which one is to be the Host cluster, and leave all the other properties set to their defaults. It’s as simple as that.
POST {{pipeline_url}}/api/v1/orgs/:orgId/clustergroups/:clusterGroupId/features/:featureName
{
"hostClusterID": <<clusterID>>,
"targetNamespace": "federation-system",
"globalScope": true,
"crossClusterServiceDiscovery": true,
"federatedIngress": true,
"schedulerPreferences": true
}
hostClusterID is the only mandatory property. The others are all optional. You can see their default values, above.
By default all features are enabled, and the control plane is watching for all namespaces (globalScope: true).
The targetNamespace is the namespace where KubeFed will be deployed and watching for federated resources, in case globalScope: false.
Pipeline takes care of installing the Federation Control Plane on the Host cluster, joining the Member clusters (adding kubeconfigs, and doing all the other things we would have to do manually using kubefedctl), and configuring the ExternalDNS deployment to watch for DNSEndpoint resources.
To use crossClusterServiceDiscovery and federatedIngress features, we need a running ExternalDNS deployment. Pipeline takes care of installing and configuring ExternalDNS for you.
Pipeline attaches the following labels to joined clusters by default:
- clusterId id of the cluster in Pipeline
- cloud amazon/google/oracle/azure
- distribution pke/eks/gke
- location usually the region of the cluster, i.e. us-east
- groupName name of the cluster group
You can - of course - add your own labels, then use them in the placement selector for federated resources.
Pipeline will create federated versions of these basic resource building blocks: namespace, clusterrole, clusterrolebinding, serviceaccount, secret, configmap, service, ingress, replicaset, job, deployment.
The Host cluster will be part of the federation by default, as it must be a member of the cluster group. Should we modify our Cluster Group by moving clusters in or out, they will be automatically joined/unjoined to/from federation. This is done automatically by Pipeline, behind the scenes. When moving a cluster out, distributed resources will remain there, unless you explicitly remove them from the cluster by modifying their placement. If a cluster rejoins the federation, the controller will catch up and re-sync its resources.
Should you disable the federation feature in the cluster group, first, all clusters will be unjoined, then all DNS records and federated resources deleted, then all KubeFed related Custom Resource Definitions removed. Finally, the Helm chart will be removed and the ExternalDNS reconfigured.
KubeFed vs multi-cluster deployment vs Istio 🔗︎
You may be asking yourself, why do I need Federation if I already have Multi-cluster deployments in Pipeline? Why not use the Backyards (now Cisco Service Mesh Manager)-based multi-cluster/cloud Service Mesh? What, exactly, is Cross Cluster Discovery?
Well, both multi-cluster deployments and KubeFed help to distribute resources across clusters. In the Pipeline platform we give you multiple ways of doing this, and let you, the customer, decide which one fits best. Nevertheless, allow us to highlight some of the differences between them.
| KubeFed | Multi-cluster deployment | |
|---|---|---|
| Reconciliation | auto | manual |
| Placement Granularity level | resource | Helm chart |
| Running Control Plane | yes | no |
| Other features | SchedulerPreferences | - |
Multi-cluster deployment is currently Helm-based, and, as is the case with any Helm deployment, once deployed, it won’t keep your resources in sync automatically. In other words, there’s no auto reconcile. KubeFed, on the other hand, keeps your resources in sync but this comes at a cost. You need an active control plane running on a Host cluster to watch resources in all of your member clusters, continuously.
During a multi-cluster deployment, you can distribute Helm charts, but with KubeFed you can decide the placement of each resource by using labels, moving resources automatically, or triggering moves via cluster label changes.
CrossClusterServiceDiscovery is useful in regards to Service Mesh, particularly if you want your services to be reachable from the outside. You can also achieve DNS-based fail-over and some simple load-balancing along with it. Should you require more sophisticated load-balancing and fail-over rules, you can disable the CrossClusterServiceDiscovery feature, and use exclusively KubeFed for resource replication, and then use Backyards (now Cisco Service Mesh Manager) in the same cluster group. That is to say, you can use both Istio and KubeFed in parallel.
Showtime - federating a deployment and service with Pipeline 🔗︎
Let’s use our Satellite application as a simple but useful example deployment. Satellite is a Golang library and RESTful API that determines a host’s cloud provider with a simple HTTP call.
We use Satellite quite a lot at Banzai Cloud, when writing cloud agnostic code. To read more about it, read this post.
We’ve chosen Satellite so that when we’re trying out different DNS endpoints - see above - we can see right away the cloud provider that hosts the Kubernetes cluster our request was directed to.
-
Create three Kubernetes clusters on different clouds: Amazon, Azure & Google.
In this step we’ll create one Kubernetes cluster on AWS, one on Azure and one on Google. On AWS and Azure, we prefer to use our own lightweight CNCF certified Kubernetes distribution, PKE, and, on Google, we’ll create a GKE cluster. The Pipeline platform automates all these for you and supports five clouds and six different Kubernetes distributions. As a matter of fact, it’s possible to import any Kubernetes distribution into Pipeline.
-
Create Cluster Federation
In the Pipeline UI choose Cluster Federation, which will bring you to a simple four step wizard. First, choose your Host cluster, then your members. Feel free to skip the second part of this step by creating a one member federation with only a single Host. Finally, you can target namespaces and enable features.
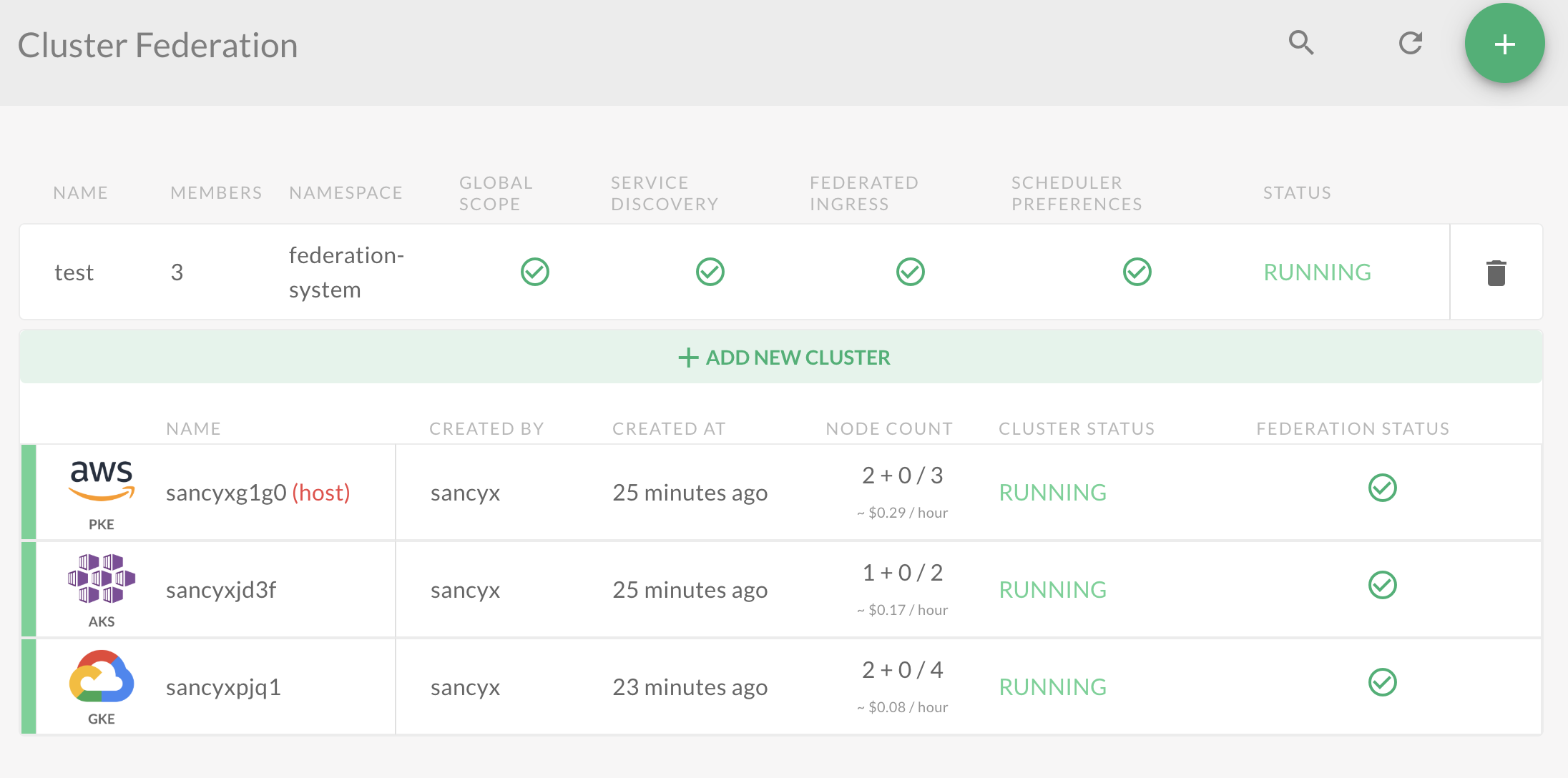
Should you inspect the API calls behind the UI wizard, you’ll find that there are two API calls: one to create a cluster group and a second to enable its federation feature.
We’re adding Cluster Group and Feature API availability through the Banzai CLI, so stay tuned
-
Download the config of the Host cluster, in order to deploy resources with
kubectl. -
Create the test namespace.
kubectl create ns test -
Create the federated namespace, then federate deployments and services
kubectl create -f https://raw.githubusercontent.com/banzaicloud/kubefed/demo-examples/example/demo/federatednamespace.yaml kubectl create -f https://raw.githubusercontent.com/banzaicloud/kubefed/demo-examples/example/demo/federateddeployment.yaml kubectl create -f https://raw.githubusercontent.com/banzaicloud/kubefed/demo-examples/example/demo/federatedservice.yaml -
Create a DNS domain object then a DNSService record:
kubectl create -f https://raw.githubusercontent.com/banzaicloud/kubefed/demo-examples/example/demo/dnsdomain.yaml kubectl create -f https://raw.githubusercontent.com/banzaicloud/kubefed/demo-examples/example/demo/dnsservicerecord.yaml -
Check and make sure the
DNSEndpointresource was created, and take a look at its contents:kubectl get dnsendpoints.multiclusterdns.kubefed.k8s.io -n test -o yamlYou should see multiple endpoints for each service/cluster pair, one with region, one with region and location, and one DNS endpoint that contains the IP addresses of all the clusters.
-
Verify that Satellite is available on all the listed endpoints, for example:
http://satellite.test.satellite.svc.sancyx.try.pipeline.banzai.cloud/satellite
The response will contain the cloud provider the request was routed through for the federated deployment.
That’s all. It’s been quite a long post, already, and a bit of an information overdose. This is just the first release of our KubeFed-based federation support for Pipeline and there’s lots more to come. As usual we are working hard on making the Pipeline platform the most complete and feature reach multi-/hybrid-cloud platform. Therefore, if you have any questions or suggestions, don’t hesitate to contact us.
Now that we are familiar with Kubernetes Federation v2, lets get into the details of Replica scheduling with Kubernetes federation.