At Banzai Cloud we are building a feature rich enterprise-grade application platform, built for containers on top of Kubernetes, called Pipeline. We have always been committed to supporting Kubernetes and our container based application platform on all major providers, however, we are also committed to making portability between cloud vendors easy, seamless and automated.
Accordingly, this post will highlight a few important aspects of a multi-cloud approach we learned from our users, and the open source code we developed and made part of the Pipeline platform.
Kubernetes and multi-clouds 🔗︎
According to The 2018 State of the Cloud Survey 81% of enterprises use multiple clouds. We see a similar pattern within our userbase, with a slight twist - we use and deploy workloads to Kubernetes with Pipeline to multiple providers within one organization, but in all cases Kubernetes is the most frequent common denominator.
We Kubernetes users have the luxury to think in terms of K8s and containers and let the system handle most of the infrastructure. However, once you have a Kubernetes system in the cloud, there are lots of application specific configurations which should be part of deployment but are cloud specific.
We’ve deliberately left out hybrid clouds from this post as it’s a pretty large topic which we will cover at a later date. For now, please note that Pipeline does support federated clusters and can
adoptKubernetes clusters regardless of their location (excepting transport level access and security prerequisites).
Move with the flow - workflow portability 🔗︎
First of all, you need a Kubernetes cluster in one of your preferred cloud providers. The cluster can be created before a workload is deployed, or as part of a workload deployment (e.g. a CI/CD pipeline). Pipeline supports both - it creates Kubernetes clusters on all major providers through a unified interface. The list of the currently supported cloud providers and Kubernetes distributions are:
With Pipeline we make your cloud workflow portable, and by using the same API, SDK we make choosing or switching between providers transparent and easy.
How do we do it? Well, it’s no magic trick; we’ve coded all the necessary provider specific components and abstracted them into Pipeline. We use Kubernetes operators for cloud specific operations at runtime or direct cloud API calls for static or predefined ops.
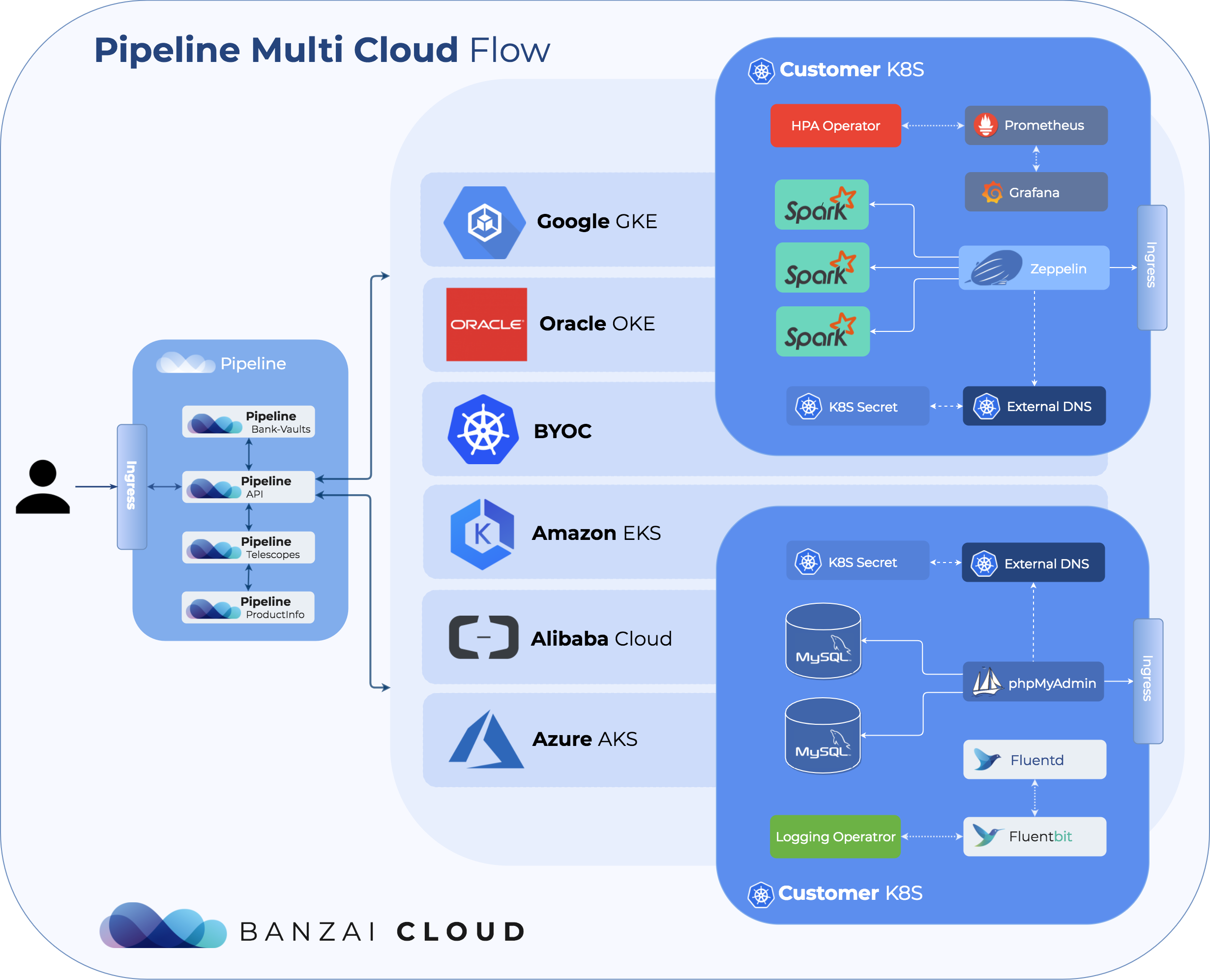
Cluster infrastructure and layout recommendations 🔗︎
We have two systems, Telescopes and Cloudinfo that recommend Kubernetes cluster infrastructures on multiple cloud providers based on requested resources (CPU, memory), instance type attributes (network, GPU, I/O, etc) and price (spot, on-demand or reserved).

Secret management 🔗︎
In any workflow there are secrets to be managed. A portion of these secrets are cloud provider access credentials - a very provider specific approach (varies from username/password, p12 files to tokens). We store these credentials in Vault via Bank-Vaults for referral with id - and turn them into the appropriate secret, correspondent to the provider. The API can dynamically and securely injects the appropriate credentials for the given cloud.
Object storage 🔗︎
Often, our users need access to, or need to create blob storage. Accordingly, we have abstracted the provider specific code, so, when users request access or manage buckets, we convert the requests into appropriate cloud provider specific code with Pipeline’s object store package.
Workload portability 🔗︎
Once we have a portable solution to the problem of flow and the ability to bring up or switch Kubernetes clusters on different providers, our focus shifts to portable and cloud agnostic deployments. The good news is that this is easily accomplished via the same operator based approach. Using Banzai Cloud operators you can write your deployment in a cloud agnostic way; you request buckets, or autoscaling features, DNS zones, persistent volume claims etc., and we turn those requests into cloud specific API calls.
DNS 🔗︎
Most of the cloud providers have their own DNS service. Luckily, a DNS provider is a DNS provider anywhere and it’s cloud agnostic by nature. Integrating all of them seemed like an inelegant solution, so we chose Route53 as our DNS provider and, for all Kubernetes ingress rules, we automated DNS setup on all providers with entries managed by Pipeline’s DNS service.
Autoscaling 🔗︎
We use deployment annotations and Pipeline turns these into properly configured vertical, horizontal or cluster autoscalers. You are required only to specify, for example, the min/max node counts within a nodepool - and we then turn those into actual cloud instances.
Persistent volume claims and object storage 🔗︎
Pipeline identifies the cloud provider and, given a PV claim, determines the right volume provisioner and creates the appropriate cloud specific StorageClass. It also manages buckets, a cloud agnostic version of object storage based on claims. It is not necessary to change Helm charts when switching between cloud providers, since our PVC operator does all the heavy lifting for you.
Secrets 🔗︎
Application secrets on Kubernetes are usually stored as K8s secrets. We did not find that approach to be adequately secure (base64), so all application secrets deployed with Pipeline are stored in Vault. We support all cloud providers as a storage backend of Vault (we actually contributed both Alibaba’s and Oracle’s).
Node pools 🔗︎
GKE used noodpools and we liked that idea so much, we applied the same concept to all the other cloud providers we support in order to be able to create heterogeneous clusters, even to providers which do not support heterogeneous clusters by default. A node pool is a subset of node instances within a cluster that all have the same configuration. Beyond the master and service node pool, Pipeline can add an arbitrary number of node pools to a cloud based Kubernetes cluster, each with different configurations - e.g. nodepool 1 is local SSD, nodepool 2 is spot or preemptible based, 3 contains GPUs - these configurations are turned into actual cloud specific instances by Pipeline.
Information flow 🔗︎
Given clusters and deployments that are ready and operating on any Pipeline supported provider, the next logical step is to make sure that these deployments use a common transport layer when they need to interact. Beside the standard, business as usual transport layers, wherein a more sophisticated message delivery is required, we have our own Kafka version which can be operated on any cloud provider and Kubernetes cluster using etcd instead of Zookeeper. Zookeeper was notoriously bad whenever it crossed availability zones on AWS, whereas our approach works like a charm with Raft.
Data portability? 🔗︎
Data has the most gravitational drag. In short, we don’t have a good solution to this problem. Our users usually launch clusters where their primary data store resides, and we don’t see any reason why this might change in the near future. Doing compute on one provider while data is on another provider is not cost effective and raises the question of latency. While this is technically doable - providers either have an S3-like API or we can use Minio - we don’t do this yet. If this changes and, through our Pipeline users, we learn a better of way accomplishing this, we will share it in a post like this one. All ideas are welcome.
If you’d like to learn more about Banzai Cloud check out our other posts in the blog, the Pipeline, Hollowtrees and Bank-Vaults projects.