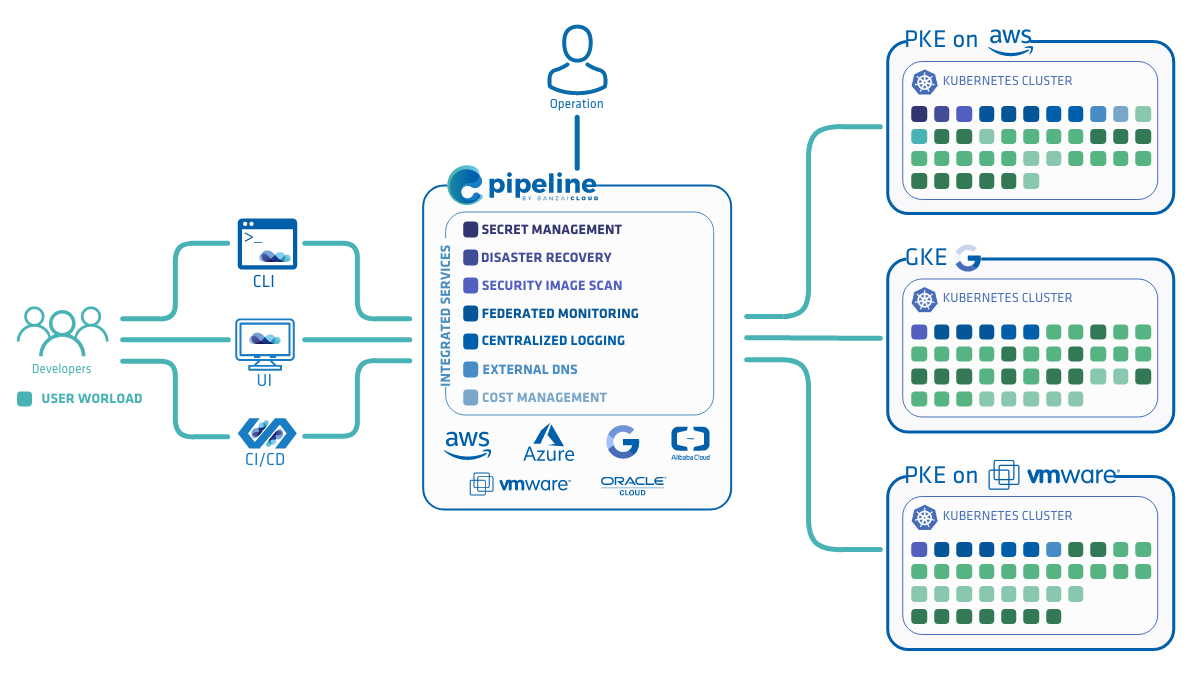
We are delighted to announce our tech preview of Banzai Cloud Pipeline 2.0, the hybrid any-cloud platform.

A little under a year ago we released the first commercial version of Banzai Cloud Pipeline and made it available for development and PoCs by launching our Try Pipeline initiative. Banzai Cloud Pipeline 1.0 was the first incarnation of our vision for a productive and flexible multi-cloud container management platform (now supporting five public clouds and on-prem datacenters). Since then, we’ve been working with customers to extend use-cases and refine the features that Pipeline supports. One major area of focus has been hybrid clouds, wherein we wanted to create a seemless operational experience for a concept that had a lot of underlying complexities. The rest of the use-cases were broadly related to three main areas: flexibility, cost optimization, and compliance.
Hybrid clouds — multiple options, one platform 🔗︎
The Pipeline platform allows enterprises to run their workloads in single-, multi- or hybrid-cloud environments. Any application which can be deployed to Kubernetes is able to run on these different environments without modifications. When creating hybrid clouds, a single approach does not cover all use-cases. Banzai Cloud Pipeline 2.0 supports four different ways of enabling customers’ hybrid-cloud use-cases.
- Cluster groups
- Backyards, an Istio-based automated service mesh for multi and hybrid clouds
- Federated resource and application deployments built on Kubernetes federation v2
- Cloud Fusion — the industry’s first hybrid-cloud Kubernetes cloud controller (tech preview supports AWS, Azure and vSphere)
Cloud Fusion, the hybrid Kubernetes cloud controller manager 🔗︎
Cloud Fusion brings a cost and complexity-effective hybrid cloud solution to our customers, without requiring that they invest in additional technologies (e.g. Istio, kubefedv2) and their related tooling. Cloud Fusion is part of our CNCF certified Kubernetes distribution, PKE, as well as the Pipeline container management platform.
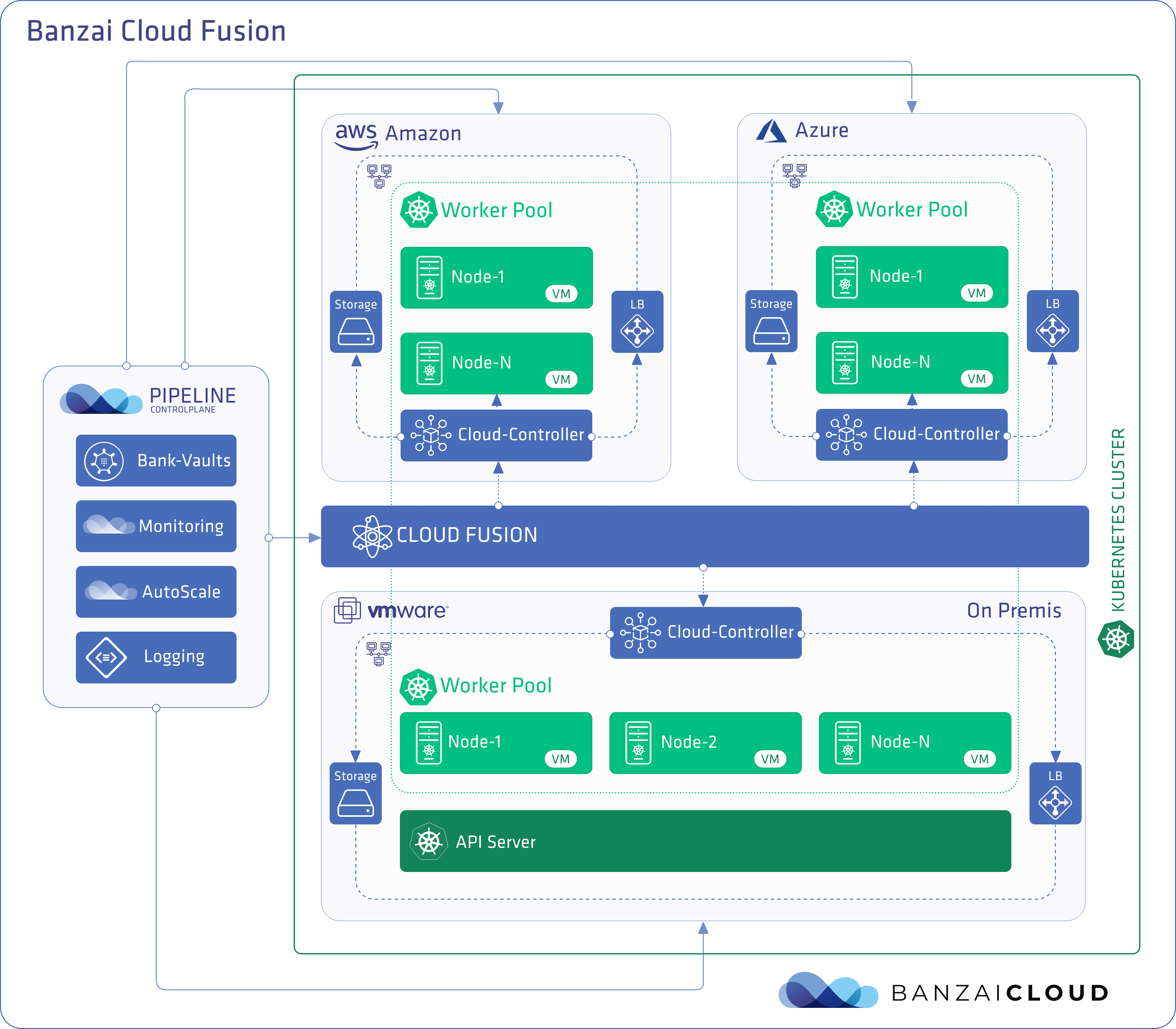
A fraction of Pipeline and PKE users were (and are) running legacy systems on-premise, and wanted to scale out their Kubernetes clusters into the cloud. They didn’t need to build new Kubernetes clusters in the cloud, but to expand their existing on-premise clusters with additional nodes running in the cloud. While we already supported multiple hybrid options, this new requirement posed a significant technological challange, due to pre-existing limitations within Kubernetes.
The problem 🔗︎
Kubernetes uses control loops that run continuously to ensure that the current state of the cluster matches the desired state. This is done by using controllers and controller managers. The cloud-controller-manager is responsible for managing all controllers associated with the cloud providers.
Kubernetes has not been designed to run in heterogenous and hybrid environments, and when a mixture of (cloud) controllers are installed (due to a hybrid cloud environment), they step on each other’s toes. The end result is that various things break and nodes are removed from the cluster (stay tuned for a blog that goes into more detail on these issues).
The solution 🔗︎
We’ve built our own, Hybrid Cloud Controller, which installs and manages cloud controllers, CSI drivers and Load Balancers. This allows for seamless scaling between nodes, whether on-premise and in different clouds, and is accomplished in such a way that the end-user interacts with a only single Kubernetes cluster that straddles both data centers and clouds. Customers don’t need to manage multiple API servers and etcd clusters — as the new nodes will join the existing K8s cluster.
Today’s technical preview adds support for AWS, Azure, and vSphere, with support for additional cloud providers coming soon.
The following components are supported as of writing:
- Storage drivers: Amazon EBS, Amazon EFS, Azure Disk, vSphere Disk/vSan
- Load balancers: Amazon ELB, Amazon NLB, Azure Standard/Internal LB, MetalLB
Additional Pipeline features and changes 🔗︎
Bring your own Kubernetes 🔗︎
Additionally, Pipeline supports bringing your own Kubernetes and makes even a vanilla K8s installation into a production-ready platform by configuring and enabling federated monitoring, centralized log collection, security scans, multi-dimensional autoscaling, container registries, and more.
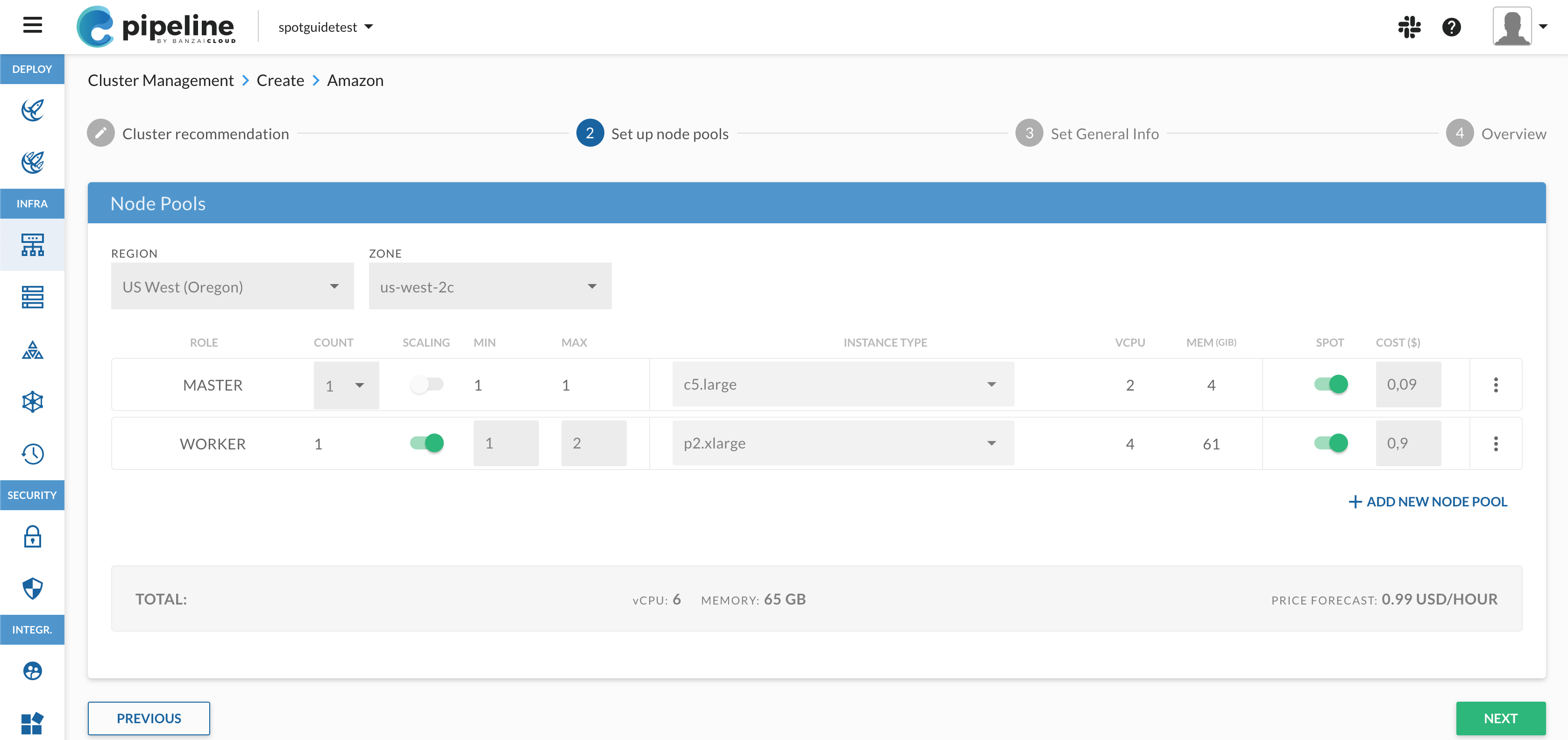
New cluster create flow 🔗︎
We enhanced the flow of cluster creation and made feature selection (installation and removal) a post cluster-create option. Under the hood, the cluster create flow has been rewritten so that it’s based on the Cadence workflow engine, in order to provide robust, reliable and restartable flows (read more here). Frequently, and especially while working with cloud provider-managed Kubernetes, the reliability of flow provisioning was beyond our control. However, with Cadance, we introduced meaningful cleanup and retries to hide and potentially recover from failures.
Redesigned and enhanced features 🔗︎
The full list features supported by Pipeline 2.0 is too long to be included in this post. In the following section, I’d like to highlight those that have been redesigned and enhanced, compared to the previous release:
-
Observability:
- Monitoring: is now based on the Prometheus Operator, installing and configuring Prometheus, Alertmanager, Pushgateway and lots of exporters, with default dashboards and alerts for metrics coming from the infrastructure, Kubernetes and any deployed applications.
- Logging: is based on the Banzai Cloud Logging Operator, it installs and configures FluentBit and Fluentd. Some of its key features are:
- Namespace isolation
- Native Kubernetes label selectors
- Secure communication (TLS)
- Configuration validation
- Multiple flow support (multiply logs for different transformations)
- Multiple output support (store the same logs in multiple storage: S3, GCS, ES, Loki and more…)
- Multiple logging system support (multiple fluentd, fluent-bit deployment on the same cluster)
-
Security:
- Image scans
- Enforcement of security policies for deployments (based on image scan results)
- Vault-based secret management with Banzai Cloud Bank-Vaults
- Automatic secret injection
-
Autoscaling solutions:
- Custom metric (even external) based autoscaling for your cluster
- Autoscaling for deployments (HPA)
- Resources (VPA)
-
Cost-effective cluster management:
- New Cloudinfo API — what, where, and how much across five clouds
- Telescopes — cost effective Kubernetes infrastrcuture and layout recommendations
- Hollowtrees — a ruleset-based watchguard to keep spot/preemptible instance-based clusters safe (with predictive spot and preemtible instance termination management)
-
Additional significant new features:
- Container registry
- DNS zone management
- Scheduled cluster termination
- Storage management (install CSI drivers and configure storage classes)
Wrap-up 🔗︎
As you can see, there are a large number of changes that make Pipeline 2.0 better than ever: some visible, some hidden under the hood. We’ve been focusing on making Kubernetes-based hybrid-clouds incredibly simple to deploy and operate, as well as on refining support for our customers’ use-cases. We hope you enjoy the results! In the coming weeks we’ll be posting about the technologies behind Pipeline, so stay tuned.
If you are interested in a demo or if you are attending Kubecon San Diego, feel free to get in touch with us; we’re happy to chat!