






Last year Alibaba joined CNCF and announced plans to create their own Kubernetes service - Alibaba ACK. The service was luanched more than a year ago, with its stated objective to make it easy to run Kubernetes on Alibaba Cloud without needing to install, operate, and maintain a Kubernetes control plane.
At Banzai Cloud we are committed to providing support for Kubernetes on all major cloud providers, thus one of our priorities was to enable Alibaba Cloud’s Container Service for Kubernetes in Pipeline and take the DevOps experience to the next level by turning ACK into a feature-rich enterprise-grade application platform. At the same time, some Pipeline users are working in highly regulated markets with region based deployment constraints (e.g. the ability to deploy applications in the China region).
The currently supported cloud providers by Pipeline are: Alibaba Cloud ACK Amazon AWS EC2 Amazon AWS EKS Microsoft Azure AKS Google Cloud GKE
Given some Alibaba Cloud and Kubernetes knowledge, Alibaba ACK is already a smooth “I need a Kubernetes cluster” experience and Pipeline builds on top of this with additional features, such as:
- Secure and centralized logging
- Secure and centralized monitoring
- Bank-Vaults, which brings Vault based enterprise-grade security to Alibaba ACK clusters
- The concept of node pools, a new feature for Alibaba Cloud introduced by Pipeline
- The ability to link resource requirements such as CPU, memory, GPU or network performance and let Telescopes recommend a diverse set of cost-optimized Kubernetes infrastructures
- Deploy applications with ease using Pipeline’s API
- Seamless and automated DNS management provided to all services deployed to Alibaba ACK
- Last but not least, a Cloud agnostic workflow and workload definition - switching between any of the providers, reuse of existing flows, etc. This list is far from complete, please check out our posts for all the features that come with Pipeline.
When it comes to creating Alibaba ACK clusters, Pipeline reduces users’ concerns to only two things:
- Alibaba credentials securely stored in Vault
- Desired cluster layout: master instance type, node instance type, node count
The following diagram shows the various components that Pipeline pre-loads into the created cluster to provide the above mentioned rich feature set to users:
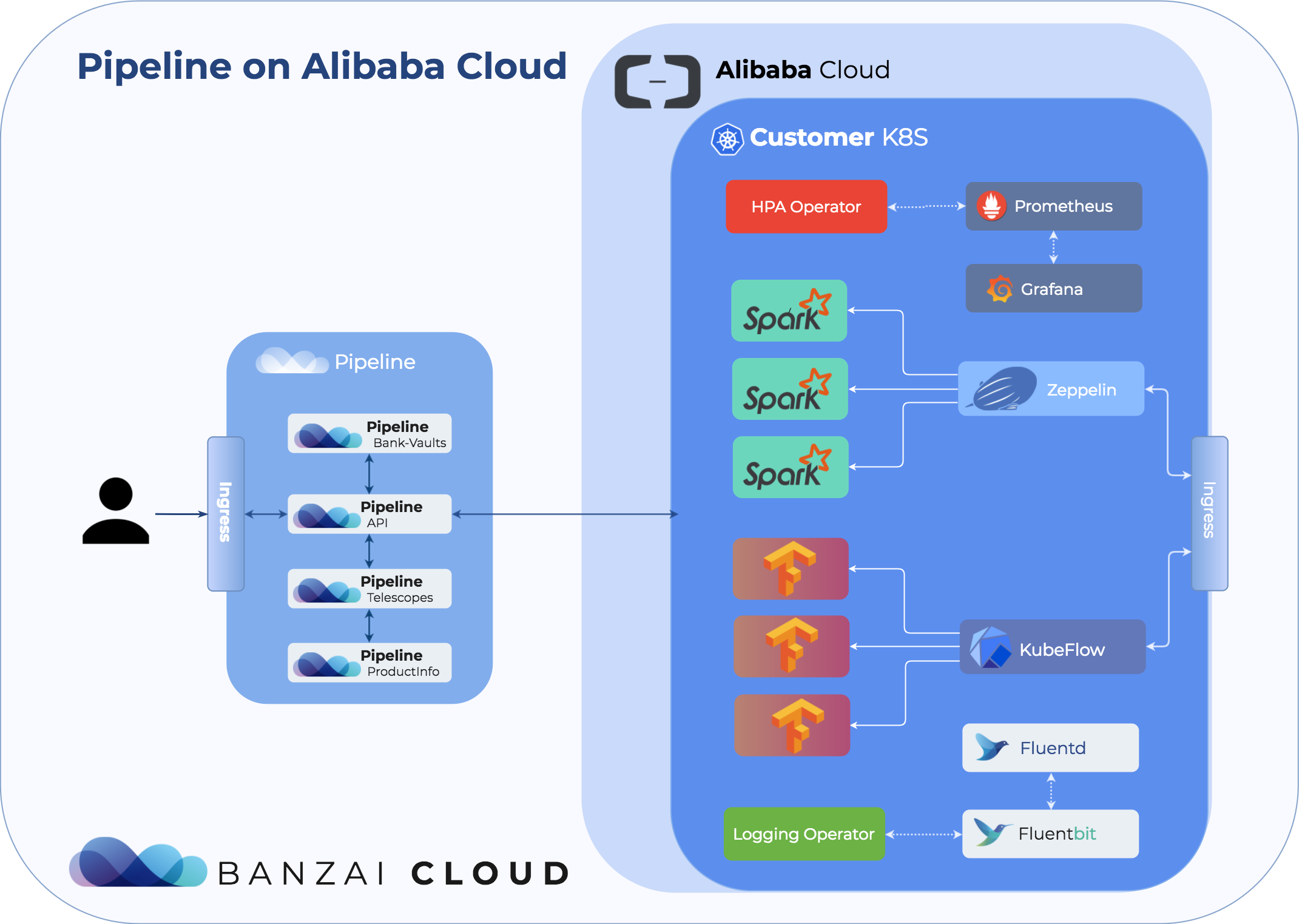
Try it out 🔗︎
Create an Alibaba ACK cluster with Pipeline 🔗︎
We have a Postman collection which also contains the Alibaba examples shown below for calling Pipeline, but for visual purposes cURL commands are shown in this blog post.
Prerequisites 🔗︎
The Alibaba credentials that will be used to create the Alibaba ACK cluster must be registered in Pipeline first:
curl -X POST \
http://{{url}}/api/v1/orgs/{{orgId}}/secrets \
-H 'Authorization: Bearer {{token}}' \
-H 'Content-Type: application/json' \
-d '{
"name": "my-alibaba-secret",
"type": "alibaba",
"values": {
"ALIBABA_ACCESS_KEY_ID": "{{your_alibaba_access_key_id}}",
"ALIBABA_ACCESS_KEY_SECRET": "{{your_alibaba_access_key_secret}}"
}
}'
- your_alibaba_access_key_id : Alibaba access key id of the RAM user used for creating Alibaba ACK cluster
- your_alibaba_access_key_secret : Alibaba secret access key of the RAM user used for creating Alibaba ACK cluster
The above REST request stores the passed in Alibaba credentials as a secret in Vault using Bank-Vaults for secure storage. Security is an important consideration for us and we take it seriously. You can find out more about how we handle security here.
The response will contain the id of the secret. We will use this id in subsequent requests where a secret_id is required and the credential is securely injected into the Alibaba client from Vault.
Create Alibaba ACK cluster 🔗︎
curl -X POST \
http://{{url}}/api/v1/orgs/{{orgId}}/clusters \
-H 'Authorization: Bearer {{token}}' \
-H 'Content-Type: application/json' \
-d '{
"name":"alibabacluster-{{username}}-{{$randomInt}}",
"location": "eu-central-1",
"cloud": "alibaba",
"secretId": "{{secret_id}}",
"properties": {
"acsk": {
"regionId": "eu-central-1",
"zoneId": "eu-central-1a",
"masterInstanceType": "ecs.sn1ne.large",
"masterSystemDiskCategory": "cloud_efficiency",
"nodePools": {
"pool1": {
"count": 1,
"image": "centos_7",
"instanceType": "ecs.sn1ne.large",
"systemDiskCategory": "cloud_efficiency"
}
}
}
}
}
'If we look at the fields the user has to provide in the create cluster request, we can see that the user is required to think of, and provide, only the location of the Alibaba ACK cluster for it to be created in, the size of the cluster, and the type of the nodes and features to be enabled. The rest is taken care of by Pipeline.
- secret_id - the
idof the secret in Vault that contains the Alibaba credentials to be used for provisioning all the resources needed for creating the Alibaba ACK cluster
- location - the location of the Alibaba ACK cluster
- nodePools - lists node pools that will be available for the worker nodes of the cluster (currently only one node pool is supported on Alibaba)
- masterInstanceType - specifies which instance type to use for Kubernetes masters (3 masters will be created)
- masterSystemDiskCategory - specifies which disk type to use for Kubernetes masters
Beside cluster autoscaling Pipeline also makes it possible for users to enable Horizontal Pod Autoscaling for deployments. We store all Alibaba ACK and deployment metrics in Prometheus which Horizontal Pod Autoscaler can feed metrics from to drive the autoscaling.
You can find out more about the cluster autoscaling created with Pipeline by reading through these posts.
Cluster created
We can verify on the Alibaba Cloud console whether the cluster was created.
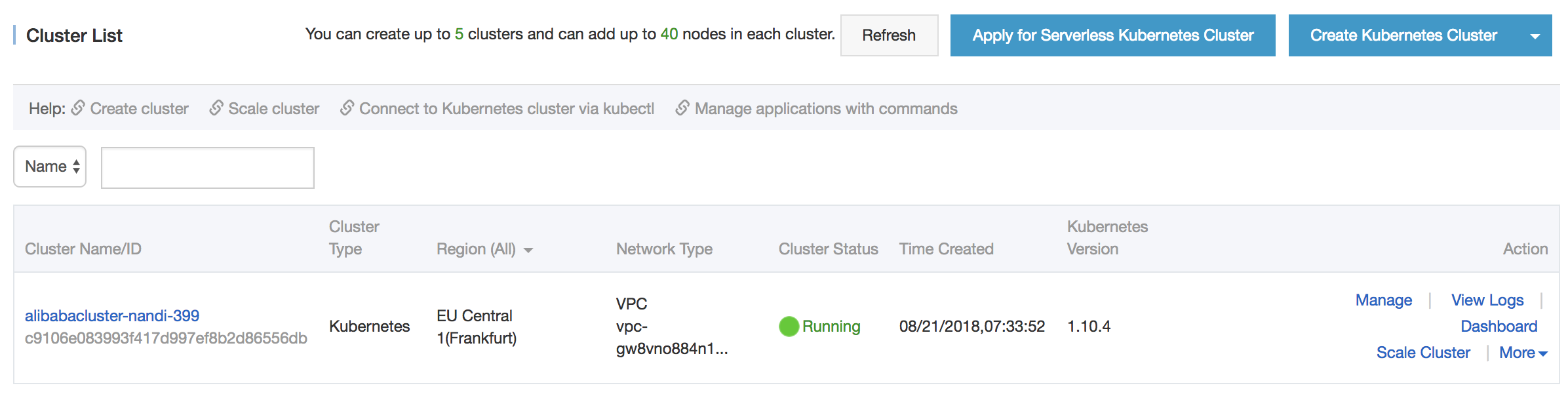
Currently, the Alibaba console only shows the state of the Kubernetes API server. We can verify the list of ECS instances that make up the cluster by searching for instances that have the cluster name in their name.
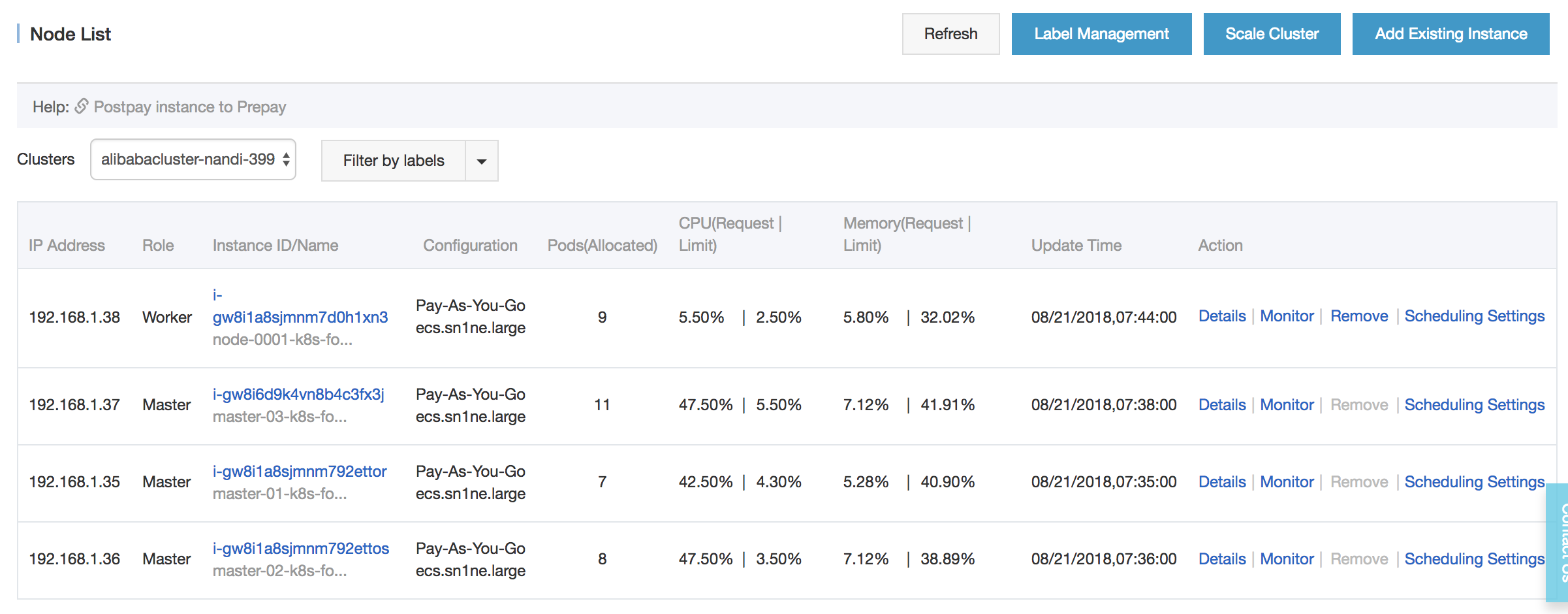
Access to cluster
In order to start using the cluster with kubectl we need the cluster config. The cluster config can be retrieved through Pipeline using:
curl -X GET \
http://{{url}}/api/v1/orgs/{{orgId}}/clusters/{{clusterId}/config \
-H 'Authorization: Bearer {{token}}' \
-H 'Content-Type: application/json' \Save the retrieved cluster config to a file and point $KUBECONFIG environment variable to it so that the kubectl command will use this config by default.
Now we can verify the list of nodes that have joined the Kubernetes cluster using kubectl:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
eu-central-1.i-gw8i1a8sjmnmcgicj1ek Ready master 1h v1.10.4
eu-central-1.i-gw8i1a8sjmnmcmffv7bx Ready <none> 1h v1.10.4
eu-central-1.i-gw8i6d9k4vn8g9t012uk Ready master 1h v1.10.4
eu-central-1.i-gw8i6d9k4vn8gbs154tp Ready master 1h v1.10.4Similarly we can check running pods:
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default pipeline-traefik-59f9b59859-44fbw 1/1 Running 0 18m
kube-system alicloud-application-controller-558549f66d-6fhr2 1/1 Running 0 22m
kube-system alicloud-disk-controller-86bc486f98-d2zxh 1/1 Running 0 22m
kube-system alicloud-monitor-controller-67c84c6bb9-5452x 1/1 Running 0 22m
kube-system cloud-controller-manager-lv65t 1/1 Running 0 22m
kube-system cloud-controller-manager-sjkkq 1/1 Running 0 22m
kube-system cloud-controller-manager-wjkgf 1/1 Running 0 22m
kube-system coredns-7997f8864c-f6v2r 1/1 Running 0 27m
kube-system coredns-7997f8864c-xrqcs 1/1 Running 0 27m
kube-system dashboard-kubernetes-dashboard-5f657df58f-gzb5z 1/1 Running 0 18m
kube-system default-http-backend-5f89bdffd5-xr5qs 1/1 Running 0 22m
kube-system flexvolume-4z78x 1/1 Running 0 22m
kube-system flexvolume-dw2kx 1/1 Running 0 22m
kube-system flexvolume-gfzj9 1/1 Running 0 20m
kube-system flexvolume-zvbcb 1/1 Running 0 22m
kube-system heapster-6c46f88458-ftvqh 1/1 Running 0 22m
kube-system kube-apiserver-eu-central-1.i-gw8i1a8sjmnmcgicj1ek 1/1 Running 0 27m
kube-system kube-apiserver-eu-central-1.i-gw8i6d9k4vn8g9t012uk 1/1 Running 0 24m
kube-system kube-apiserver-eu-central-1.i-gw8i6d9k4vn8gbs154tp 1/1 Running 0 21m
kube-system kube-controller-manager-eu-central-1.i-gw8i1a8sjmnmcgicj1ek 1/1 Running 0 26m
kube-system kube-controller-manager-eu-central-1.i-gw8i6d9k4vn8g9t012uk 1/1 Running 0 25m
kube-system kube-controller-manager-eu-central-1.i-gw8i6d9k4vn8gbs154tp 1/1 Running 0 21m
kube-system kube-flannel-ds-4vhfg 2/2 Running 1 20m
kube-system kube-flannel-ds-fgtbf 2/2 Running 1 22m
kube-system kube-flannel-ds-kpr7x 2/2 Running 1 22m
kube-system kube-flannel-ds-vsqll 2/2 Running 1 22m
kube-system kube-proxy-master-784g5 1/1 Running 0 22m
kube-system kube-proxy-master-8rg4s 1/1 Running 0 22m
kube-system kube-proxy-master-wgg8c 1/1 Running 0 22m
kube-system kube-proxy-worker-pbwd2 1/1 Running 0 20m
kube-system kube-scheduler-eu-central-1.i-gw8i1a8sjmnmcgicj1ek 1/1 Running 0 28m
kube-system kube-scheduler-eu-central-1.i-gw8i6d9k4vn8g9t012uk 1/1 Running 0 25m
kube-system kube-scheduler-eu-central-1.i-gw8i6d9k4vn8gbs154tp 1/1 Running 0 21m
kube-system monitoring-influxdb-999f4f948-lwcn6 1/1 Running 0 22m
kube-system nginx-ingress-controller-6b6687fdd6-fx4b6 1/1 Running 0 22m
kube-system nginx-ingress-controller-6b6687fdd6-w8kjn 1/1 Running 0 22m
kube-system tiller-deploy-b67846f96-nn7m6 1/1 Running 0 22m
pipeline-infra pipeline-hpa-hpa-operator-66bfb9866f-rmncf 1/1 Running 0 18mOpen-source contributions
The whole of Pipeline is open-source and during the Alibaba integration period other open-source projects have been impacted as well:
-
https://github.com/hashicorp/vault/pull/4783
-
https://github.com/aliyun/alibaba-cloud-sdk-go/issues/83
-
https://github.com/aliyun/alibaba-cloud-sdk-go/issues/82
-
https://github.com/aliyun/aliyun-oss-go-sdk/issues/110
One of the most important additions contributed in the interest of Pipeline integration was the Vault native Alibaba Object Storage Service support, which enables users to store secrets backed by OSS through its native API. You can read more about how we run Vault on Alibaba with full automatic unsealing support and with Alibaba OSS storage backend in this previous blog post. We’d like to highlight the quick resolution of issues we faced during integration work by the Alibaba engineering team - they regularly managed to fix issues on the Golang SDK in less than one business day.
Further enhancements - the list continues
With Cloudinfo we can query the available instance types per region and their prices through a REST API. This service provides the necessary information for Telescopes - a cluster instance types and full cluster layout recommender engine. Telescopes, which is based on predefined resource requirements such as CPU, memory, GPU or network performance, and recommends a diverse set of cost-optimized Kubernetes node pool layouts. To follow the progress of Alibaba support in Cloudinfo please subscribe to this issue.
For users, its easier to think in terms of the resource needs of their deployments/applications and not to deal with the cloud provider specific cluster layout at all. The initially provided cluster layout may not fit the resource needs of the deployed applications over time and the cluster layout must be changed dynamically. Enter autoscalers, which receive cluster and application metrics from Prometheus to scale the cluster up/down appropriately while taking into account recommendations from Telescopes.
For more details on Telescopes check this post.
Please note that the Alibaba Cloud Kubernetes support for some advanced scenarios is still a work in progress, and it can be tracked here.




