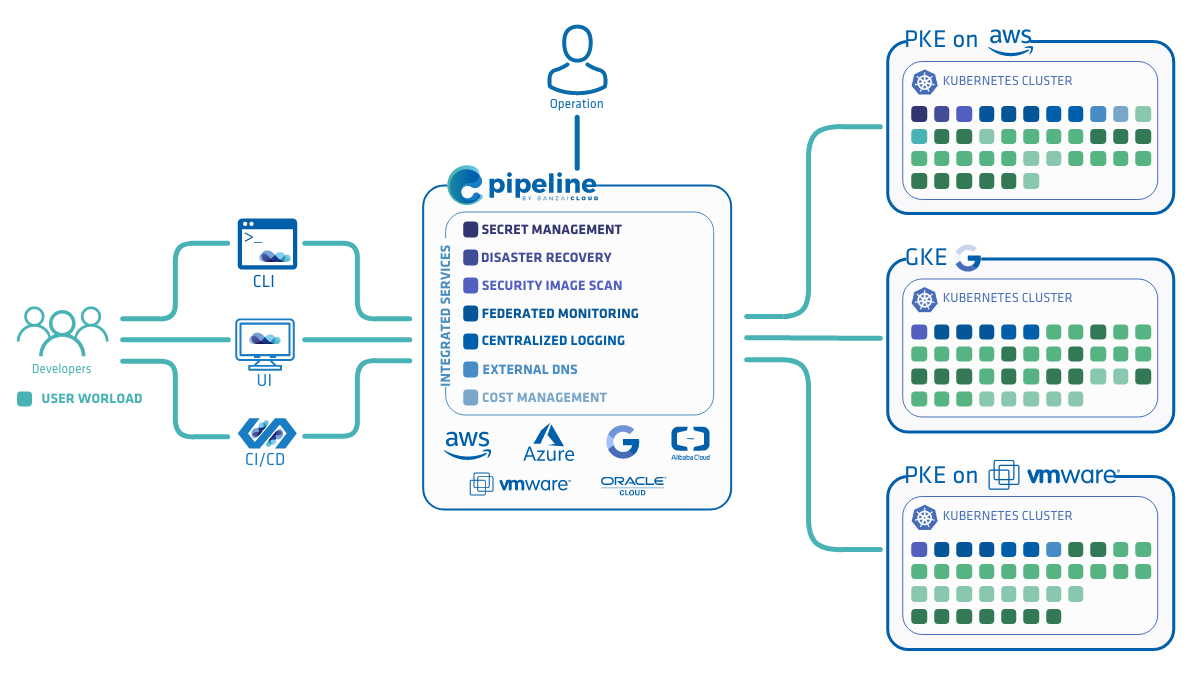
If you’re a frequent reader of this blog, you may have already seen a “short” description of what our platform does. It usually goes something like this:
Banzai Cloud Pipeline is a solution-oriented application platform which allows enterprises to develop, deploy and securely scale container-based applications in multi- and hybrid-cloud environments.
We frequently elaborate on this by providing a list of key features:
Banzai Cloud Pipeline leverages best-of-breed cloud components, such as Kubernetes and adds a unified system architecture that enables a highly productive, yet flexible environment for developers and operations teams alike. Enterprise-grade security - multiple authentication backends, fine-grained authorization, dynamic secret management, autoscaling, backups and restores, vulnerability scans, static code analysis, CI/CD, and more - are tier zero features of Pipeline, and support a rich set of ready-to-deploy application environments from language run-times, through data analytics to machine learning workloads.
We’d love a shorter tag line and if you come up with something snappy, we’re happy to hear it (we’ll send you a T-shirt if we like it). Meanwhile, we’ve decided that what we lack in brevity, we can make up for by writing one extra-long article that tries to explain our vision for this platform and the philosophy behind it. Ready?
Note: The Pipeline CI/CD module mentioned in this post is outdated and not available anymore. You can integrate Pipeline to your CI/CD solution using the Pipeline API. Contact us for details.
Why are we building a platform on top of Kubernetes? Isn’t Kubernetes, itself, a platform? 🔗︎
Well, one’s platform is another’s component… We noticed that while there was a strong push within enterprises to adopt Kubernetes and Cloud Native technologies, most struggled with the inherent complexity of such a task. They either ended up spending tens of man-years of effort on features that were necessary but not differentiating (e.g. integrating security, logging, monitoring, etc.), or they decided to stick with what they already knew for as long as possible. We also noticed that, while there was a whole slew of components and frameworks on the market, none of them were going far enough toward creating a unified, open, well-architected and well-implemented solution that would radically simplify the process of going Cloud Native for their users.
We visualized two user-types: at one end of the spectrum there were users who were purely application focused, with limited ops skills and who would rather not deal with ops at all, and at the other end were users who already had an ops team but wanted to increase the level of standardization between their teams to make their work more efficient. In our minds, both required the same, rich foundation but focus on features at different levels in the stack. We combined a large number of building blocks in an opinionated way to provide a foundation that we believe works best for our use-cases. There are, of course, mechanisms that change default settings and customize behavior but ultimately, a platform becomes useful only if it correctly makes fundamental decisions on behalf of its users, shutting down certain superfluous or redundant ways of accomplishing the same tasks.
Listing all of our platform’s features would make for an even longer blog post, so I’ll just give you the highlights.
- Use your favorite cloud provider: you can spin up Kubernetes clusters on Amazon, Azure, or Google (additional support for Digital Ocean, Bring your own Kubernetes, and the Banzai Cloud Kubernetes distribution for hybrid and on-prem clusters is in private alpha right now)
- Multi-dimensional autoscaling (cluster and applications) based on custom metrics
- A secure, Kubernetes-native CI/CD system
- Option to save costs with spot and preemptible instances while maintaining SLAs
- Secure storage of secrets (cloud credentials, keys, certificates, passwords, etc.) in Vault
- Direct injection of secrets into pods (bypassing K8s secrets)
- Unified storage API
- Security scans throughout the whole of a deployment’s lifecycle
- Disaster recovery with periodic backups and the ability to do full cluster state restores
- Centralized log collection and federated monitoring to give insight into your applications
- Easy to use dashboards
- Integration with enterprise services like Docker registries, Git, AAA or SIEM providers (Active Directory, LDAP, OpenID, Gitlab, GitHub Enterprise, etc.)
- Custom and configurable K8s schedulers
- Spotguides: run Spark, Zeppelin, NodeJS, MySQL, Spring, etc.
nativelyon K8s and automatically benefit from all of the above
It’s hard to make a complete list of all the features offered by the Banzai Cloud Pipeline platform, so we suggest you to try it out and let us know what you think.
We started working on Pipeline over a year ago, guided by our vision of what a next-generation application platform should look like. As our user community rapidly expanded, the vision became a mission: to build a platform that lets enterprises focus on the applications they want to build, and to minimize the amount of effort they have to put into their infrastructure. Banzai Cloud Pipeline is the result.
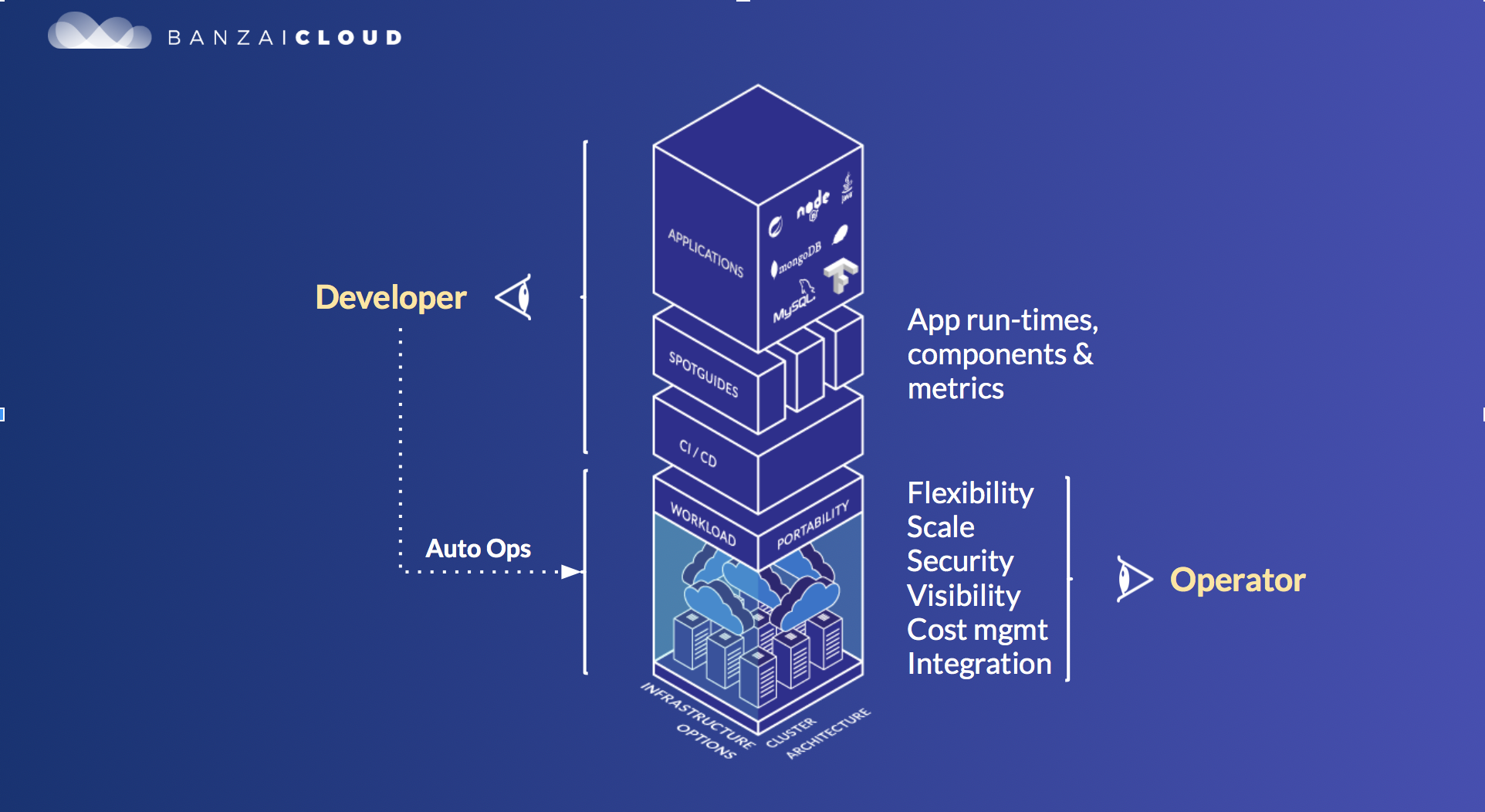
Banzai Cloud’s vision and mission 🔗︎
Startups begin with a mission, underpinned by a vision of the future. These represents two sides of the same coin - a mission primarily refers to the reason for a startup’s existence, whereas a vision is a description of the startup as it appears in a successful version of the future. It was no different for us at Banzai Cloud. We founded our company with a diverse group of technical experts - developers, architects, DevOps experts, and system operators that shared one thing in common: all of us had been running very large containerized applications since the early days of Docker and Kubernetes (a few of us actually wrote container orchestration layers before Swarm and Kubernetes were released).
We believed strongly that Kubernetes was going to be the kernel that all future distributed applications would be based on. So, when we sat down to start to design our own platform, Banzai Cloud Pipeline, our guiding star was that we knew we were going to build on top of Kubernetes. But along with all the positives it brings, Kubernetes comes with a lot of subtleties and a steep learning curve for enterprises.
A core principle of the Pipeline platform is to make those technologies that we deploy as simple and straightforward to use as possible. This enables enterprises to adopt and leverage our technologies, which, in turn, creates a self-perpetuating cycle of improvement and adoption. Along the way, we’ve defined a few must-haves:
Kubernetes everywhere 🔗︎
We took a cloud-first, datacenter-second approach. Our reasoning was simple: we could move extremely quickly on the cloud, receive widespread adoption and align with cloud-oriented trends as they appeared in the enterprise. Simultaneously, we began work on our own Kubernetes distribution, to be able to bring these technologies to on-prem datacenters. Our objective was not to compete with pure-play K8s distributions, but to make available a unified solution that works across multiple clouds and on-prem deployments. This means that, for us, on-prem Kubernetes is just one (but a very important) part of the problem we need to solve in order to integrate our control plane, security mechanisms, unified logging/monitoring infrastructure, etc. Our goal is to catapult enterprises toward hybrid cloud deployments, allowing them to scale up from their datacenters to the cloud of their choice, but, at the same time, providing them with a unified view of their systems. On Banzai Cloud Pipeline, cloud-based clusters are just a natural extension of on-premise datacenters, not a segmented part of yet another infrastructure silo.
Observability for all 🔗︎
The platform provides developers and operators with different sets of features, but one feature they both require is the ability to gain insight into what’s happening inside deployments, applications and within the infrastructure. Our framework is built using several Pipeline operators, federated Prometheus, Thanos, Grafana and Fluent components. Pipeline gives you insight into what’s happening in your clusters out-of-the-box, and all logs and metrics are securely collected and persisted at a centralized location.
Let application developers focus on their applications 🔗︎
Most application developers we talk to aren’t all that interested in Kubernetes itself, and would very much like to have a fast-track way of deploying on top of K8s. To make developers’ lives easier, we’ve embraced several popular frameworks, such as Spark, Zeppelin, NodeJS, Tensorflow, and Spring (among others), and have instrumented them to work with all of Pipeline’s convenient features. Usually we accomplish this in a non-intrusive way (i.e. no code changes are required) or we generate and pre-package boilerplate code into an environment that we call spotguide. Maybe you’ve already noticed that we like surfing metaphors; ‘spotguides’ is yet another one.
When someone uses one of our spotguides, they don’t just get an application run-time but one that has been properly set up with a rich set of additional features:
- A GitHub repository that’s automatically wired into a Kubernetes native CI/CD pipeline
- The ability to create and build code artifacts, containers, K8s deployments and Helm charts
- Graceful error handling
- Graceful shutdown
- A structured JSON logger wired into the platform’s Fluent components to collect and securely move application logs to a centralized location (object stores, Elastic, etc.)
- Health checks (liveliness, readiness probes)
- Application metrics that are collected into a centralized (or federated) Prometheus cluster and stored in Thanos
- A Grafana dashboard for all relevant application metrics
How does this sound?
It represents our vision of what we think should be available by default on any productive developer platform. The user gets all of these features without having to write a single line of code, Kubernetes specific descriptors, or anything else. This leaves them free to focus on application code or business logic, push it to a Git repository, and let the Banzai Cloud Pipeline spotguides do the rest.
Money, money, money 🔗︎
The cost of running clusters can really add up. We felt that pain first-hand, and decided to do something about it. We put a lot of effort into designing the features of the Banzai Cloud Pipeline platform that bring the following capabilities to all of our users:
- Running on clusters in AWS spot and Google preemptible instances without compromising SLAs
- Being able to mix on-demand and spot instances
- Graceful handling of termination notices
- Rescheduling applications to maintain the continuous and healthy operation of clusters
- Understanding cloud provider (currently 6) specific pricing schema and services, and recommending cluster infrastructure layouts
- Multi-dimensional autoscaling for both applications and clusters
- Gracefully draining and replacing nodes
This is a relatively short list but it took a lot of effort to create and polish until it was production ready. We created thousands of clusters over 9+ months, and created several open source projects (Telescopes, Hollowtrees, CloudInfo, as well as several scaling Kubernetes operators and admission and mutating webhooks - all available on our GitHub) to make these features useable in production.
Security, Security, Security (and disaster recovery) 🔗︎
Software evolves quickly and infra code may become rapidly outdated, so today’s secure software can carry vulnerabilities into the future. The Banzai Cloud Pipeline platform aims to provide comprehensive lifecycle security for deployments, as well as automated infrastructure patching for all the users of our managed service. It:
- Catches container vulnerabilities at build time using the Banzai Cloud Pipeline CI/CD solution
- Blocks insecure deployments (containers) before they’re pushed to a Kubernetes cluster
- Manages container vulnerabilities (whitelist/blacklist, operations as removes, fallbacks, etc.)
- Periodically rescans Kubernetes deployments throughout the whole application lifecycle
- Raises alerts
Another enterprise requirement is the ability to recover from disasters. We are 100% certain that at some point sh*t hits the fan regardless of the level of preparation. The only real option is to be ready for when it does. To achieve this, the platform can perform periodic cluster and deployment backups (with filtering options) and when necessary recover deployments into existing clusters or create fresh ones.
Last but not least, we store all secrets as credentials, keys, certificates in Vault using our popular open source project, Bank-Vaults and bypass the whole Kubernetes secrets mechanism - which we don’t believe is secure enough.
We are here to support you 🔗︎
We’ve come a long way since we started the company, but, as they say, the ‘journey matters more than the destination’. Our current developer-oriented beta release is the first realization of our vision of what an enterprise Kubernetes platform should look like. Easy to use, flexible and automated!
With a team of 25+ (we are hiring) and with strong financial backing, we’re here to ease your Cloud Native journey on Kubernetes - whether it be #hybrid-cloud, #multi-cloud or #banzaicloud. We launched the shared beta platform free for developers, however, we have commercial products as well: one aimed at SaaS providers (dedicated control plane, managed service) and an enterprise package (enterprise features, dedicated control plane, a support-based subscription or a managed service).
Thank you for making it through this long post and please support us by starring our Pipeline GitHub repository, or by trying out the Banzai Cloud Pipeline platform for yourself.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.