






Every major cloud provider offers a managed Kubernetes service that aims to simplify the provisioning of Kubernetes clusters in its respective environment. The Banzai Cloud Pipeline platform has always supported these major providers - AWS, Azure, Google, Alibaba Cloud - turning their managed k8s services into a single solution-oriented application platform that allows enterprises to develop, deploy and securely scale container-based applications in multi-cloud environments. While this was very appealing from the outset, we quickly realized there was demand among our enterprise users to implement more sophisticated use cases that were limited by our initial approach. Our next step, moving from the cloud into our customers’ data centers in on-premise and hybrid environments, necessitated the building of our own CNCF certified Kubernetes distribution, PKE.
In this post, we’ll discuss the challenges that arose from our decision to support users of Azure Kubernetes Service (AKS), as well as the addition of Azure support for our Kubernetes distribution.
-
Ability to configure API server - AKS doesn’t provide a way to configure/fine tune the K8s API server, so it is impossible to implement features like pod security policies and unified authn/authz.
-
Infrastructure resources stored in a given resource group under our control - AKS provisions a new resource group named
MC_<resourecgroup name>_<cluster name>_<location>for the infrastructure resources in the cluster. With enterprises where access rights are restricted to specific resource groups, you can create/update/delete clusters in their resource groups but not while simultaneously managing cluster infra resources directly, since those belong to a dynamically createdMC_<resourecgroup name>_<cluster name>_<location>resource group wherein admin access is limited. A subscription level administrator must be engaged to grant access to the newly created group, a potentially lengthy process. Users should be able to create clusters in such a way that all their infrastructure resources are stored in those resource groups wherein they have administrative privileges. -
Heterogenous clusters with highly available nodes - AKS implements node pools behind the scenes using availability sets, so there exists a certain level of tolerance for hardware failure. However, this tolerance may not meet the requirements of some enterprises, which can be remedied through the use of Azure availability zones.
-
A highly available load balancer capable of handling traffic for large clusters - AKS operates in tandem with the
Basic Azure Load Balancerto expose the public endpoints of load balancer-type Kubernetes services. TheBasic Azure Load Balancerhas no support for availability zones and cannot survive zone failure or perform cross-zone load balancing. Its backend pool can contain virtual machines from only a single availability set, which means it can’t load balance traffic directly to all the nodes of a heterogenous Kubernetes cluster with multiple pools. This limitation can lead to uneven load balancing in heterogeneous clusters, as previously described in this post. -
Passing the CIS security benchmark for Kubernetes - At Banzai Cloud we strive to enable a secure software supply chain which ensures that applications deployed with the Pipeline platform and Pipeline Kubernetes Engine are secure, without reducing developer productivity across environments (whether on-premise, multi-, hybrid-, or edge-cloud). While we have our own internal processes and protocols, as well as a dedicated security team working full time on hardening our application’s entire platform stack, we like to bolster our customers’ confidence using industry benchmarks, such as the CIS security benchmark for Kubernetes.
-
Hybrid-cloud support - Last but not least, beside multi-cloud deployments, we provide our enterprise customers with the ability to deploy services, not just across multiple clouds but across hybrid-clouds. Our users can now create hybrid deployments based on our open source Istio operator and the rest of our Pipeline magic, using PKE as their Kubernetes distribution across any of the cloud providers or virtualization and bare-metal operating systems we support, all while benefiting from an easy to use UI, CLI or API.
The Banzai Cloud Pipeline approach 🔗︎
When designing the Azure infrastructure for PKE, we took all of the above-mentioned limitations into consideration, alongside some edge cases and our Istio operator users’ CNI requirements, and decided to take a different approach to AKS.
Virtual machine scale set 🔗︎
Instead of availability sets, Pipeline and PKE use virtual machine scale sets as a backend for node pools. Virtual machine scale sets provide highly available VMs and support availability zones, in addition to the capabilities that availability sets typically provide. Our Kubernetes cluster autoscaler automatically upscales or downscales virtual machine scale set instances, based on the demands placed on them by workloads running in the cluster.
Standard Azure Load Balancer 🔗︎
We use the Standard Azure Load Balancer, since it supports multiple backend pools linked to multiple virtual machine scale sets and can cover all the nodes of a Kubernetes cluster - up to 1000 VM instances. The Standard Azure Load Balancer is zone-redundant and provides cross-zone load balancing.
Infrastructure provisioning flow 🔗︎
Pipeline uses Cadence to execute Azure’s infrastructure provisioning and PKE’s installation flow. The flow is made up of activities that make low level azure-sdk API calls to provision Azure’s infrastructure resources. The use of low-level API calls instead of ARM templates gives us the fine-grained flexibility we need to re-run our steps over and over.
Pipeline provisions all infrastructure components within the resource group provided by the user.
- Create two separate
Network Security Groups: one for master nodes and one for worker nodes. This allows us to seperately control the security rules that apply to master and worker nodes.- Network security rules for master nodes:
- Allow inbound connections to the k8s API server on port 6443
- Allow SSH inbound connections
- Allow inbound/outbound connections from within the virtual network
- Allow inbound/outbound connections from/to Azure Loadbalancer
- Network security rules for worker nodes:
- Allow inbound/outbound connections from within the virtual network
- Allow inbound/outbound connections from/to the Azure Load Balancer
- Network security rules for master nodes:
- Create a
Virtual Networkfor the cluster’s nodes - Create a
Route Tablefor the virtual network - Create a
Subnetfor each node pool. Assign the master network security group to the subnet created for master nodes. The subnets created for the worker nodes share a single network security group created for them. - Create a
Public IPfor the k8s API server endpoint. - Create
Standard Azure Load Balancer- Attach the
Public IPto the Azure Load Balancer. - Create a backend pool for the master nodes.
- Create a load balancer rule that directs incoming traffic on port 6443 to the backend pool created for the master nodes.
- Create an inbound NAT pool that will be used in SSH connections to the master nodes via Azure Load Balancer. The worker nodes can be reached indirectly by using a master node as an SSH jump host.
- The Load Balancer is created such that its name matches the name of the k8s cluster.
- Attach the
- Generate an SSH key pair and store it securely in Vault.
- Create a
Virtual Machine Scale setfor each node pool.- Pass a user data script to each virtual machine scale set. This user data script is executed upon a VM instance’s initial boot and sets up k8s kubelets using the PKE tool.
- Each virtual machine scale set is created with a system assigned identity, in order to allow assignation of roles to VM instances. The kubelets running on these VMs will assume whatever role is assigned to the virtual machine scale set.
- Each virtual machine scale set receives a generated SSH public key, in order to allow SSH access to the nodes with a private key.
- Grant the owner role to the virtual machine scale set that corresponds to the master node pool on the resource group. This permits the k8s controller to create resources inside the resource group, such as public IPs and data disks.
- Grant the contributor role to the virtual machine scale set that corresponds to the worker node pools on the resource group.
The following diagram is a high level representation of Azure infrastructure for PKE provisioned by Pipeline.
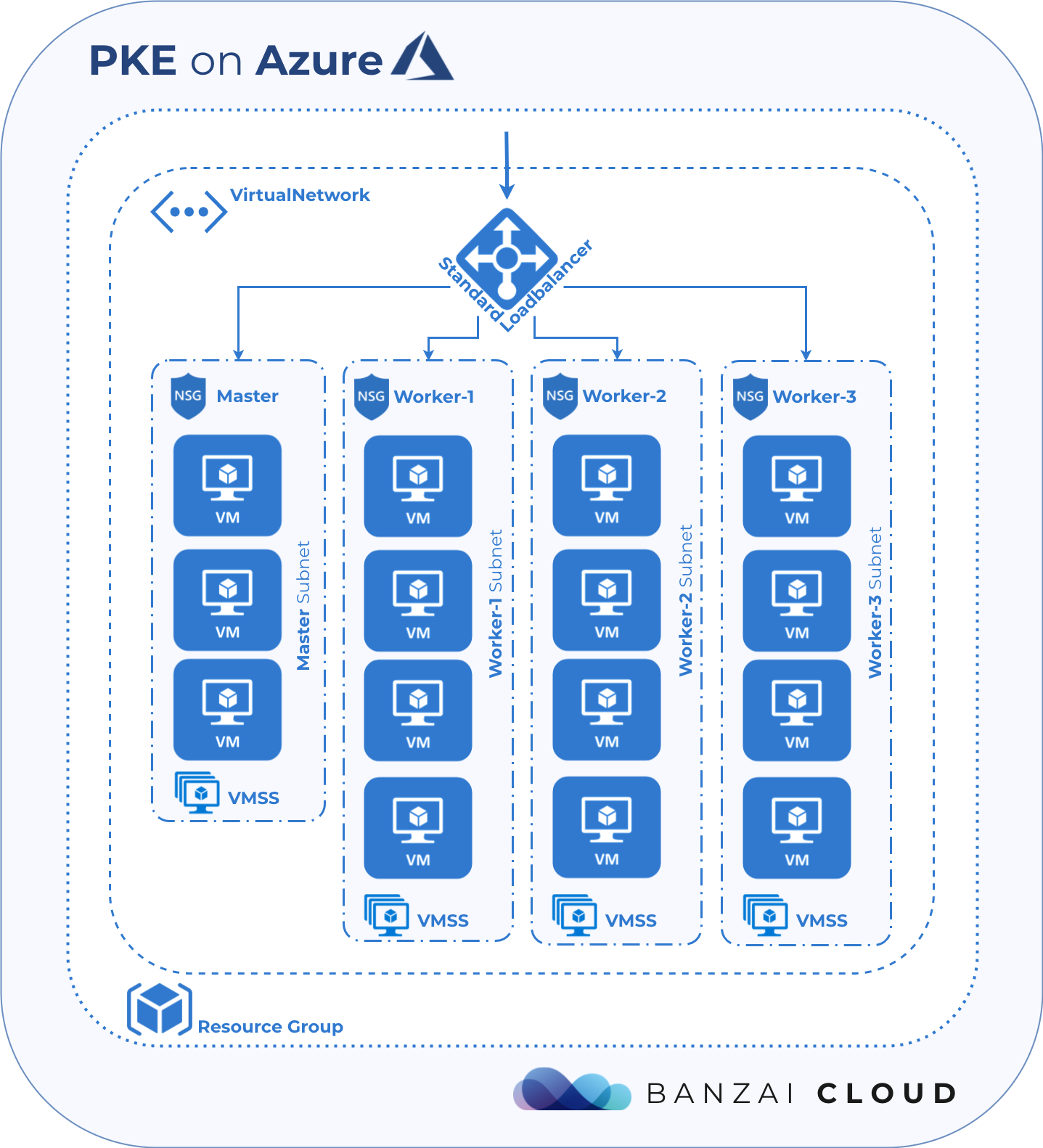
The user data script mentioned above passes information through config to Kubernetes, such as tenant id, resource group, virtual network, network security group used by workers, route table, cluster name, etc. This information is required by the k8s controller in order for it to identify, modify and create new infra resources inside the resource group.
Note that the Azure Load Balancer was created with the same name as the k8s cluster. We do this because the k8s controller or, more specifically, the service controller, searches for the Azure Load Balancer by cluster name when creating a public endpoint for a load balancer-type kubernetes service. If no Azure Load Balancer can be found, it will create a new one within the resource group, but otherwise will use the existing one. The service controller then provisions new public IPs within the resource group for each load balancer-type kubernetes service, and attaches them to the Azure Load Balancer. It also adds those security rules to the network security group that are used by worker nodes and the Azure Load Balancer to direct/allow incoming traffic into the pods behind the kubernetes service.
A k8s cluster can be deployed to a resource group, since reconciliation logic in the service controller may delete the public IPs that were created by another k8s cluster inside the same resource group, even though they were associated with the load balancer of another cluster.
Based on our preliminary investigation of this issue we beleive it is caused by shortcoming in how Kubernetes identifies the Azure public IP resources to be deleted.
Here is what we’ve found so far:
- The
ListPIPmethod returns all Azure public IPs in a resource group - azure_loadbalancer.go#L1350 - Checks the value of the
servicetag of the public IP - azure_loadbalancer.go#L1357 - If the value of the
servicetag matches the name of the kubernetes service (namespace/svcname) than the public IP belongs to that kubernetes service - This logic does not take into account the k8s cluster the public IP was created from thus in certain cases will operate on a public IP that belongs to a different k8s cluster running in the same resource group.
We’ll continue the investigation to see if there is a workaround that we can do to overcome this. In the same time we opened a GH issue in the Kubernetes repository.
Lets conclude this post here - as there was lots of technical deep dive into specifics of how we believe are doing differently (and hopefully better) than Azure AKS. In the next PKE on Azure posts we will follow up with some additional cloud agnostic details and benefits of PKE over Azure AKS - centralized log collection, federated monitoring, Vault based security, disaster recovery, security scans, multi-dimensional autoscaling and lots lots more. Icing on the cake will be a service mesh deployment across Azure, on-premise and AWS/Google - all within a few clicks on the UI and fully automated by Pipeline.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.




