






At Banzai Cloud we continue to work hard on the Pipeline platform we’re building on Kubernetes. We’ve open sourced quite a few operators already, and even recently teamed up with Red Hat and CoreOS to begin work on Kubernetes Operators using the new Operator SDK, and to help move human operational knowledge into code. The purpose of this blog will be to take a dive deep into the PVC Operator.
If you’re looking for a complete guide on how to use the
Operator SDK, or if you’re just interested inKubernetes Operators, please check our comprehensive guide.
If you are interested in our other Operators, you should take a look at our earlier blog posts:
Prometheus JMX Exporter Operator
Wildfly Operator
Vault Operator
Introducing the PVC Operator 🔗︎
Persistent Volume handling in Kubernetes can become messy, especially when the Kubernetes cluster is created in a managed cloud environment.
Wondering what the heck Kubernetes Persistent Volume and StorageClasses are, exactly? No worries, we’ve already described them in another blogpost.
Managed Kubernetes providers like Azure or Google create a default StorageClass, but what happens if that default option does not meet your requirements. There are two alternatives:
- Create Helm charts which are cloud provider specific.
- Use the Banzai Cloud PVC Operator that handles the StorageClass creation for your requirements.
How the PVC Operator does its magic: 🔗︎
Determining a cloud provider 🔗︎
To be cloud agnostic, the operator must first determine the cloud provider. To do that, the operator uses the Satellite service which is available for 6 cloud providers. This server doesn’t just provide the origin of the cluster but also gives us the important information required to, for example, create a Storage Account in Azure. Metadata server access differs slightly on each cloud provider.
Creating a StorageClass specific to your needs 🔗︎
The operator parses the submitted Persistent Volume Claim, and, if it does not contain spec.storageClassName, the operator will simply ignore the request and use the default instead. On the other hand, if that field has been set, it will determine the correct volume provisioner and create the appropriate StorageClass.
To fully understand how that works, let’s walk through an example:
Imagine that we want create an Application (Tensorflow) which requires a ReadWriteMany volume and that our selected provider is Azure. Assume that we’ve already installed the PVC Operator from Banzai Cloud and submitted the Persistent Volume Claim. The operator then determines the cloud provider and figures out what the ideal storage provider is, AzureFile. Creating an AzureFile backed StorageClass requires a Storage Account inside Azure within the same resource group, as well as some meta information (e.g. subscriptionId, location). The operator takes care of all this on the fly.
For supported storage providers please check the GitHub page of the project.
A few features worth mentioning 🔗︎
NFS as storage provisioner 🔗︎
NFS stands for Network File System. It allows us to access files over a computer network, and this project allows the use of NFS inside Kubernetes. The PVC Operator uses it in order to create a NFS backed StorageClass.
For an NFS provisioner, the operator needs to create an NFS server deployment and service that handles traffic. This deployment has one cloud provider backed ReadWriteOnly volume, which is distributed to other entities by the server, so it is usable as a ReadWriteMany volume. This comes in handy when cloud provisioned ReadWriteMany volumes are slow.
To request the NFS backed StorageClass, please use StorageClass names which contain nfs.
Creating an Object Store Bucket 🔗︎
You may be wondering whether this operator registers as a Custom Resource. It does, and a CRD is used to create Object Store Buckets on different cloud providers. Currently, only Google is supported, but we’re working on adding support for all major providers.
To create a bucket, submit the following Custom Resource:
apiVersion: "banzaicloud.com/v1alpha1"
kind: "ObjectStore"
metadata:
name: "test"
spec:
name: "googlebucket"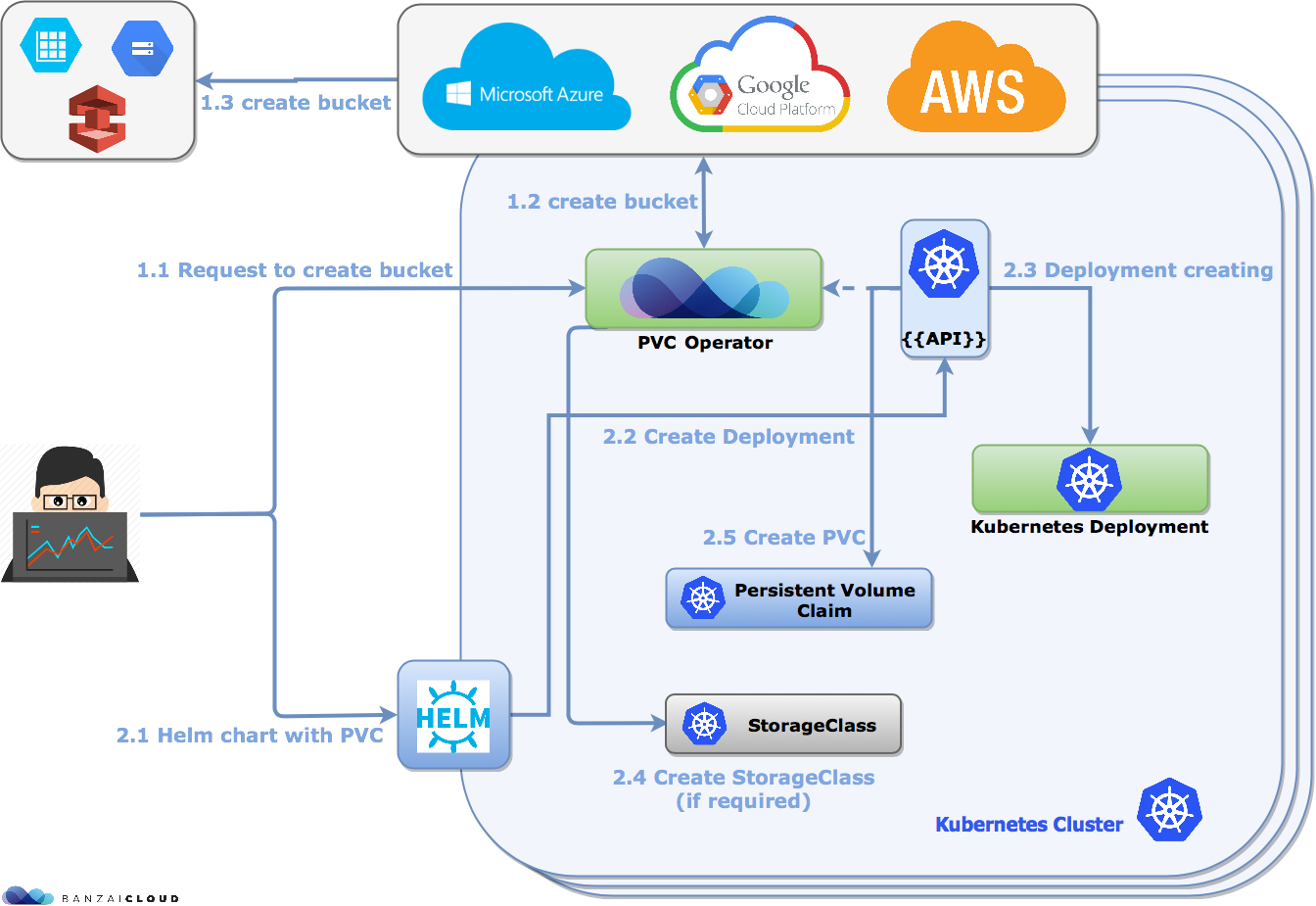
Try it out 🔗︎
Let’s give it a whirl. We’ll be using the Spark Streaming application from this blog. This application requires a persistent volume, which will be created by the PVC Operator. Also we are going to install a Spark History Server, which requires a bucket. The bucket will also be created by our operator.
We won’t cover every detail of how to run this Spark application, since it is covered thoroughly in the blog mentioned above, but we’ll focus specifically on how the operator streamlines application submission.
If you don’t have a Kubernetes cluster please create one. If you’re looking for a painless solution use Pipeline, a next generation platform with a focus on applications.
Use kubectl to create the PVC Operator:
kubectl create -f deploy/crd.yaml
customresourcedefinition "objectstores.banzaicloud.com" created
kubectl create -f deploy/operator.yaml
deployment "pvc-operator" createdNow create a bucket for the Spark History Server:
kubectl create -f deploy/cr.yaml
objectstore "sparkhistory" createdIf you follow the log of ‘pvc-operator’:
kubectl logs pvc-operator-cff45bbdd-cqzhx
level=info msg="Go Version: go1.10"
level=info msg="Go OS/Arch: linux/amd64"
level=info msg="operator-sdk Version: 0.0.5+git"
level=info msg="starting persistentvolumeclaims controller"
level=info msg="starting objectstores controller"
level=info msg="Object Store creation event received!"
level=info msg="Check of the bucket already exists!"
level=info msg="Creating new storage client"
level=info msg="Storage client created successfully"
level=info msg="Getting ProjectID from Metadata service"
level=info msg="banzaicloudsparkhistory bucket created"Create your Spark-related prerequisites:
- ResourceStaging Server
- Shuffle Service
- History Server
Configure History Server to point to the bucket we created, above. In our case it’s:
{
"name": "banzaicloud-stable/spark-hs",
"values": {
"app": {
"logDirectory": "gs://banzaicloudsparkhistory"
}
}
}- Build the NetworkWordCount example
- Don’t forget to port forward the RSS server
Then launch Spark:
bin/spark-submit --verbose \
--deploy-mode cluster \
--class com.banzaicloud.SparkNetworkWordCount \
--master k8s://<your kubernetes master ip> \
--kubernetes-namespace default \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.app.name=NetworkWordCount \
--conf spark.kubernetes.driver.docker.image=banzaicloud/spark-driver:pvc-operator-blog \
--conf spark.kubernetes.executor.docker.image=banzaicloud/spark-executor:pvc-operator-blog \
--conf spark.kubernetes.initcontainer.docker.image=banzaicloud/spark-init:pvc-operator-blog \
--conf spark.kubernetes.checkpointdir.enable=true \
--conf spark.kubernetes.checkpointdir.storageclass.name=checkpointdirsc \
--conf spark.driver.cores="300m" \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.shuffle.namespace=default \
--conf spark.kubernetes.resourceStagingServer.uri=http://localhost:31000 \
--conf spark.kubernetes.resourceStagingServer.internal.uri=http://spark-rss:10000 \
--conf spark.kubernetes.authenticate.submission.caCertFile=<your ca data path> \
--conf spark.kubernetes.authenticate.submission.clientCertFile=<your client cert path> \
--conf spark.kubernetes.authenticate.submission.clientKeyFile=<>your client key path> \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=gs://banzaicloudsparkhistory \
--conf spark.local.dir=/tmp/spark-local \
file:///<your path to word count example>/spark-network-word-count-1.0-SNAPSHOT.jar tcp://0.tcp.ngrok.io <your choosen ngrok port> file:///checkpointdirIf we check StorageClasses, we can see that the operator has already created one for Spark and that our PVC is bound:
kubectl get storageclass
NAME PROVISIONER AGE
sparkcheckpoint kubernetes.io/gce-pd 8m
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
spark-checkpoint-dir Bound pvc-a069a1c6-5a0f-11e8-b71f-42010a840053 1Gi RWO sparkcheckpoint 6mIf we check the Spark driver’s log, we can see that it puts logs in the bucket created with the above operator:
INFO KubernetesClusterSchedulerBackend:54 - Requesting a new executor, total executors is now 1
INFO KubernetesClusterSchedulerBackend:54 - Requesting a new executor, total executors is now 2
INFO EventLoggingListener:54 - Logging events to gs://banzaicloudsparkhistory/spark-03dc1b39d1df4d53895c490a16998698



