






Amid a growing number of increasingly sophisticated cyber attacks, enterprises are searching for ways to enable security wherever possible, in order to protect their data in transit and at rest. Big data processing is no exception; security is a very broad topic and to cover it in its entirety would be beyond the scope of this post. Instead, we will focus exclusively on those security capabilities that Spark on Kubernetes provides (by Spark on Kubernetes, we mean when Spark uses Kubernetes as an external cluster manager for creating and running executors).
This post covers some of the security features of the Spark Spotguide - the easiest way to run and operate Apache Spark on Kubernetes - uses.
The spark-submit command 🔗︎
Users submit their Spark application for execution by using the spark-submit command. When Kubernetes is being used as an external cluster manager, the spark-submit command interacts with the Kubernetes API server directly to create the driver pod. The spark-submit command either uses the current kubeconfig or settings passed through spark.kubernetes.authenticate.submission.*'s configuration to authenticate with the Kubernetes API server.
RBAC should be enabled on the Kubernetes cluster along with correctly set up privileges for whichever user is running the spark-submit command. The required minimum set of privileges is for watching, creating, deleting and updating Kubernetes resources (e.g pods, services, etc) in the namespace where the Spark application will run.
Local storage encryption 🔗︎
Spark on Kubernetes supports encryption of temporary data written to local storage, which can be enabled by passing
--conf spark.io.encryption.enabled=trueThe driver and executor pods will run until the Spark application completes. While the application is running anyone can exec into these pods and read the contents of their temporary files, unless local storage encryption is enabled.
SSL public endpoints 🔗︎
While Spark does support setting up SSL for its public endpoints (Web UI and Spark History Server), there is at least one alternative worth mentioning; since we are on Kubernetes, it’s recommended that we expose the endpoints through ingress. Additionally, many ingress controllers provide SSL out-of-the-box for endpoints exposed through ingress.
Authentication and encryption of communication between Spark processes 🔗︎
This security feature is not available in the current version of Spark 2.4 on Kubernetes. However, work has been done to enable it, SPARK-26194, and is expected to be released with Spark 3.0.0.
In order to support our users and their security requirements, Banzai Cloud backported this implementation to Spark 2.4.3 and built a Docker image which is available on Dockerhub:
banzaicloud/spark:v2.4.3.194banzaicloud/spark-py:v2.4.3.194banzaicloud/spark-r:v2.4.3.194
Note that the Spark image published by Banzai Cloud also includes the following additions:
SPARK-26194 generates a key for each application run, and distributes these keys to executor pods. This key is used for encrypting/decrypting the RPC communication between driver and executors, using an AES based symmetric encryption algorithm from the Apache Commons Crypto library.
Let’s take a deeper look into SPARK-26194 to help us understand how the encryption key is generated within the driver and then distributed to executor pods.
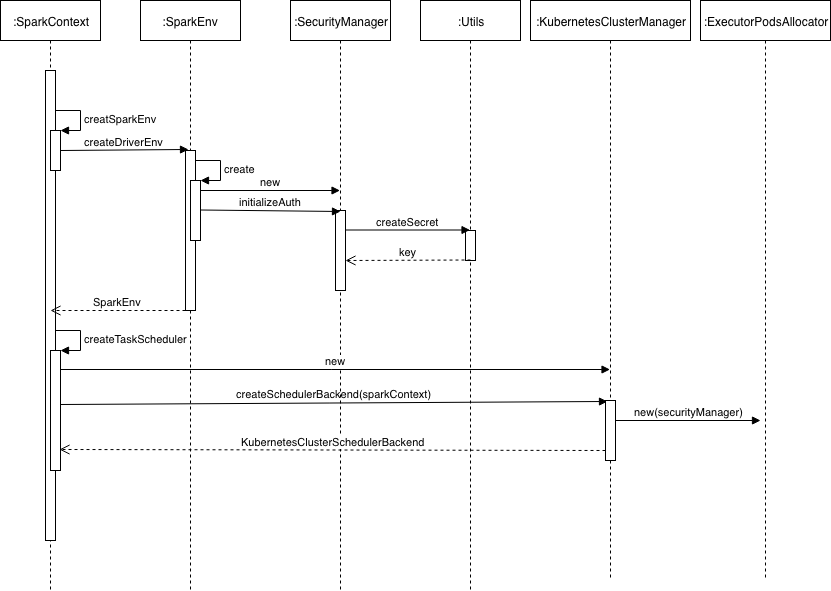
The flow diagram above shows how the driver generates an encryption key and passes it to the ExecutorPodsAllocator instance, through which the driver indirectly requests executor pods.
- The user submits a Spark application with spark-submit. This will create a driver pod on Kubernetes.
- The Spark driver initialization flow creates a
SparkContextand a driver specificSparkEnvinstance.SparkEnvholds aSecurityManagerinstance which is initialized with an autogenerated encryption key through the invocation of itsinitializeAuthmethod. - The driver’s
SparkContextalso gets a reference to theKubernetesClusterSchedulerBackendinstance, which is responsible for provisioning executor pods on Kubernetes. KubernetesClusterSchedulerBackendcontains a reference toExecutorPodsAllocator, which will have been initialized with theSecurityManagerinstance of the driver that stores the autogenerated encryption key.
The following diagram shows how an encryption key is stored by the SecurityManager instance of a driver, and is then distributed to its executors.

- When a new executor is needed,
ExecutorPodsAllocatoris engaged by the driver to provision an executor pod. This, in turn, invokesKubernetesExecutorBuilderto build the pod spec for the executor.KubernetesExecutorBuilderreceives theSecurityManagerof the driver which stores the autogenerated encryption key. This key is added into the executor pod spec as the value of the_SPARK_AUTH_SECRETenvironment variable. - Each executor pod started by the driver receives the encryption key via that
_SPARK_AUTH_SECRETvariable. Executors have their ownSecurityManagerinstance, which picks up the encryption key from_SPARK_AUTH_SECRET.
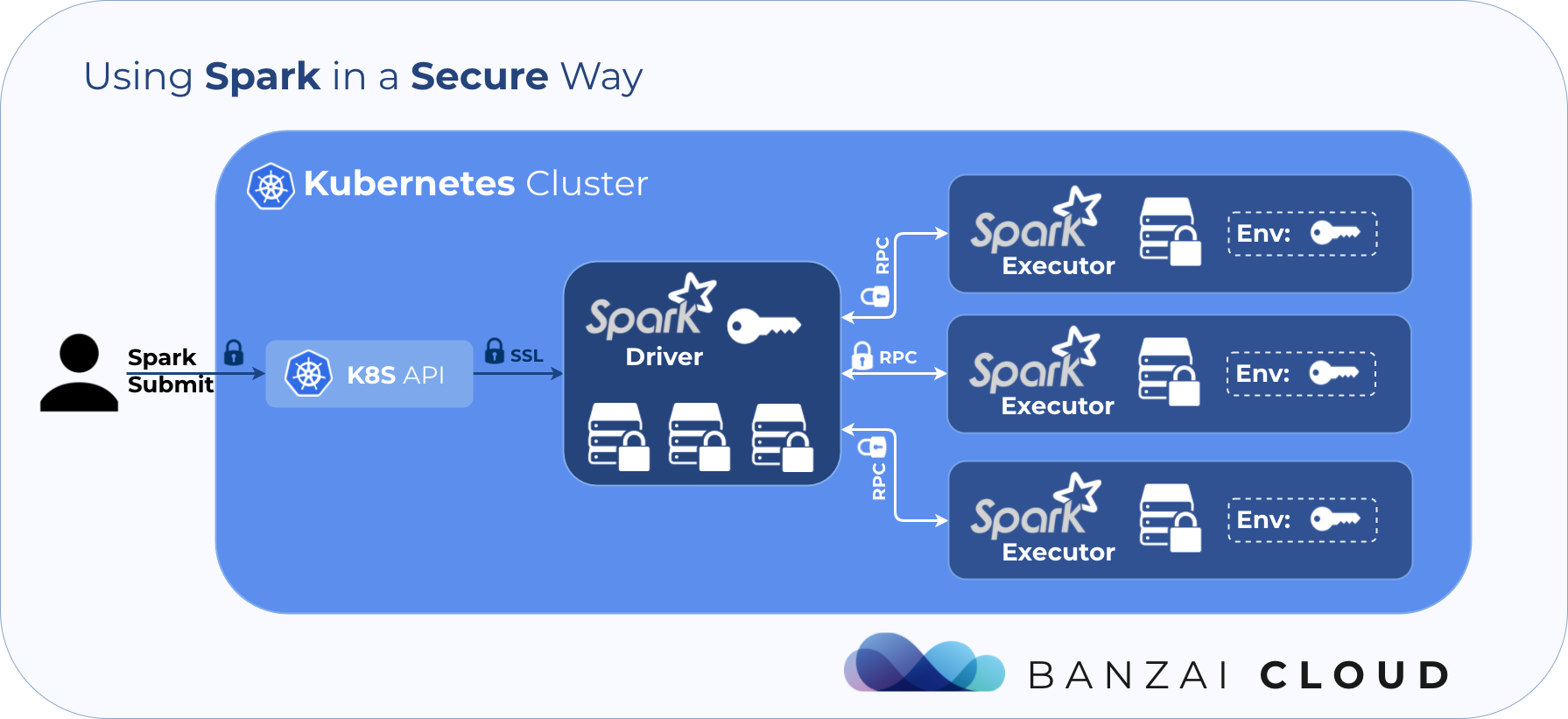
Since the key is distributed to executors through environment variables in the pod, this can be read by anyone who has view access to pods, until the Spark application finishes and all its executors quit. In order to avoid this, Kubernetes RBAC must be set up so that such access to the pod spec in the namespace where the Spark application is running is granted only to a few selected service accounts. SPARK-26301 represents an attempt to improve on this solution. However, it doesn’t solve the real problem, which is how to protect the shared key, so there’s still room for improvement.
One possible method of addressing this problem is to store the key that’s been generated by the driver in Vault, and then inject the shared key into the executors in such way that it is not visible through the pod spec or the command line arguments of the executor process. Injecting secrets taken from Vault directly into pods is already solved. For details see this post. All that’s left for us to do is to arrange for the generated secrets to be stored in Vault.
RPC communication in action 🔗︎
Let’s see what happens when authentication and encryption is enabled. These can be enabled by passing:
--conf spark.authenticate=true \
--conf spark.network.crypto.enabled=true \to the spark-submit command.
Get the driver pod of the submitted application:
$ kubectl get pods --selector=spark-role=driver
NAME READY STATUS RESTARTS AGE
spark-example-1559202236166-driver-rpq5f 1/1 Running 0 2m14sExec into the driver container:
$ kubectl exec -it spark-example-1559202236166-driver-rpq5f bashInside the container we install tools that we’re going to use to watch network traffic:
$ apk update
$ apk add ngrepRun ngrep to watch communication on port 7078 that is used for driver-executor communication:
$ ngrep port 7078What we end up seeing is a lot of gibberish chars:
.@..b.._{...Rd..0#....A5.....,...1..x'y...........ne..Z......I_...y.W[.<.......Q..4(.-Ej ...d......Z..........#....;..O...gM.x.]h....
V.......,(.nv..z.M..2.qA...b.(}=.T..B...<.b..^..!.........A*...U..%.I.J....#.y>Z..`...."....2/.p+974W.)....:...C..9.k.v.U4H.+J|.b....
..Y1.-....^..h,#!...l../..:...^.a9.."h..?.pb.[.W.1.0...q.....=.....}.IT..@..w.*3.$..L...gL.0.Zf.A.Q...]HOZ1..7.t....}..&Qt.....I..7..
.{.:....1...l.}u.,~..<..H.:E...fD.........Qg.z..X.k[....(........%Mt.5g..|]...GKE(.....2..NY...0....+...U....$....$...!.`.!.$x.......
{..%.........B.u6....> .(5|N]i.U ...#......a..".&.(...:..j...G.Iq....,?{.7.....x.....:N.v....Q.......h...0k.ym....k<.1..X...&E[.._..h
..Y...>.7!eF...b]..(.[He.OSt.w^.j0....h..W....r.]Y.V...B/......Im.g...g.h.We......k.o.l..A......Z.....v.ihHc..pWJ.=m.........>4X..8..
/.."M....._@R.-.,[..U..s.}..H{...6~..N.s..X......L.W..O...........M........j....g....1..z(X.cNU_..2...QL...X.+.Vq....v...{._.#.....[.
\........GB.&BCV..1b.C.6...].r{.z....ZlV..._..P.....B._;..NY.....p?}..1...._^!x.I.z...V.'......X8...y..s1N...O....6.....^.L.gvR.WW.1/
.c&......5.S..q...x..f..A...........M./W.80....SoP.......k0....D......E............VNb7/[jSCu....E.6....KF..k....$.<.^..Z.Z..4*.?.cH.
.h.I.t...i./..:].......a.y.....s.*}..G...{.. ..K....H.....BN.X..s.[1x....7.....A?..U.d..J.y-....5.......X.>.....>..V'lZ.v*9.8....T.w.
}/b..p..N.O.W.....:>BaR.Z.?YcMfo.H~O#..p?q.2.....!._..E...-dd..J..Q<.+#v.MK...^.Q.m...K...C.xB...i.w.~&<..AD..."...U...OC.~..'..5.-..
.n....#.8.&a1zLA_....z...!...S.6m7....kf9FP...s(......h..p........g..c...(#0.\o$|@.K.,..y.*..I...6..s.f...`....(7...f4..F$.{.[.r.\`.\
...g....N[r...n....8.....RZ.....7......*.%../$v.C..Q....{.xF.'.....f6.............kfR.kG`mO...j(.h...{.U...m.6.a2_.....*.....0^...i..
./(%..,h.....8.T....W......f...[...h.9.................R.8.(`.*K.G..|..V../-K...]wO...3[....N..d. ..vL.....gNow run the same but with:
--conf spark.authenticate=false \
--conf spark.network.crypto.enabled=false \This time, the traffic is readable:
...0spark-example-1559202970243-driver-svc.spark.svc......CoarseGrainedScheduler....sr.Lorg.apache.spark.scheduler.cluster.CoarseGrai
nedClusterMessages$StatusUpdate.>..-..2...J..taskIdL..datat.*Lorg/apache/spark/util/SerializableBuffer;L..executorIdt..Ljava/lang/Str
ing;L..statet..Lscala/Enumeration$Value;xp........sr.(org.apache.spark.util.SerializableBuffer.a.mQ.)....xpw.....xt..1sr..scala.Enume
ration$Val.ig....O...I..scala$Enumeration$Val$$iL..nameq.~..xr..scala.Enumeration$Valuebi|/.!.Q...L..$outert..Lscala/Enumeration;L..s
cala$Enumeration$$outerEnumq.~..xpsr..org.apache.spark.TaskState$.6..{.m....L..FAILEDq.~..L..FINISHEDq.~..L..FINISHED_STATESt. Lscala
/collection/immutable/Set;L..KILLEDq.~..L..LAUNCHINGq.~..L..LOSTq.~..L..RUNNINGq.~..xr..scala.Enumerationu.....Y....I..nextIdI..scala
$Enumeration$$bottomIdI..scala$Enumeration$$topIdL..ValueOrdering$modulet."Lscala/Enumeration$ValueOrdering$;L..ValueSet$modulet..Lsc
ala/Enumeration$ValueSet$;L..nextNamet..Lscala/collection/Iterator;L..scala$Enumeration$$nmapt..Lscala/collection/mutable/Map;L..scal
a$Enumeration$$vmapq.~..xp............pppsr. scala.collection.mutable.HashMap...........xpw..............xsq.~..w..............sr..ja
va.lang.Integer.......8...I..valuexr..java.lang.Number...........xp....sq.~..q.~..q.~......psq.~......sq.~..q.~..q.~......psq.~......
sq.~..q.~..q.~......psq.~......q.~..sq.~......sq.~..q.~..q.~......psq.~......sq.~..q.~..q.~......pxq.~.!q.~..sr.#scala.collection.imm
utable.Set$Set4....Qm.....L..elem1t..Ljava/lang/Object;L..elem2q.~.%L..elem3q.~.%L..elem4q.~.%xpq.~..q.~.!q.~..q.~..q.~..q.~.#q.~..q.
~..q.~......pProtecting data in transit and at rest 🔗︎
Data being processed by Spark applications may reside outside the Kubernetes cluster, so it’s equally important to protect it while it’s in transit and at rest. Always check what security options the storage provider has, and that the libraries Spark uses to access storage make use of these security options to ensure that data read/written by Spark is encrypted while it’s being transmitted over the wire and again at the storage level.
For example, if your data is stored in Azure Blob:
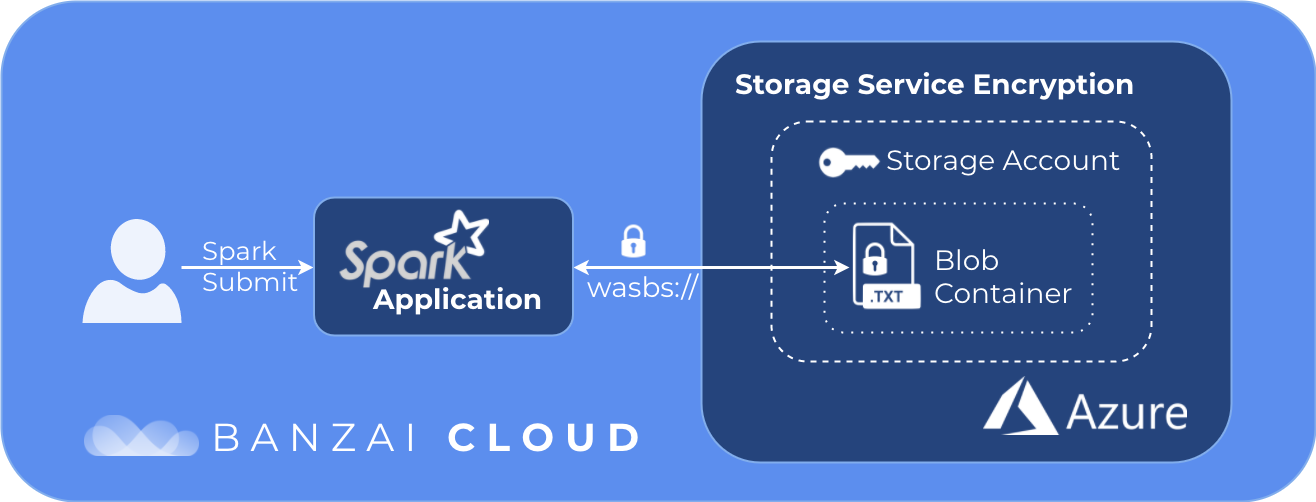
- Use storage account access keys to authenticate Spark when accessing data in the storage account
- Do not allow anonymous access to Azure Blob containers in the storage account
- Use Storage Service Encryption (enabled by default by Azure) to encrypt the data held by the storage account
- Configure Spark to use SSL when reading/writing data to Azure Blob
Here’s an example configuration that can be passed to spark-submit to access an Azure Blob data file:
- Specify the storage account access key to be used, when accessing data files in the storage account
spark.hadoop.fs.azure.account.key.<storage_account>.blob.core.windows.net=<storage_account_access_key>- Use
wasbs://protocol to ensure data is transmitted over HTTPS
wasbs://<azure_blob>@<storage_account>.blob.core.windows.net/<datafile_path>Takeaway 🔗︎
When reflecting on what we’ve covered in this post, one thing jumps out at me. It is important to look at security holistically, to take into account not just Spark as an isolated component, but the entirety of the environment, including its external dependencies; security options for all components must be utilized coherently in order to secure the whole system.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.




