A generation of system engineers has grown up who’ve never had to go to a data center as part of their job. It’s easy to forget that while cloud computing offers an abstraction over physical servers, they do still exist behind the scenes — more of them than ever before.

There are hardly any companies anymore that host all of their IT infrastructure on premises, but many enterprises have reasons to continue managing physical servers as part of their infrastructure. On the other hand, virtualization solutions with all their benefits and possible trade-off took wide adoption in all segments, and VMware is a clear market leader in enterprise virtualization.
This is the next part of the Kubernetes on-premises series about the challenges of operating cloud native applications in enterprise data centers.
If you’ve followed our posts about Banzai Cloud’s CNCF certified Kubernetes distribution, PKE, you may know that it supports bare metal and VMware from the beginning.
Our need for standardization made us go a step further: Banzai Cloud Pipeline support for automated creation and management of PKE clusters on VMware vSphere is ready!
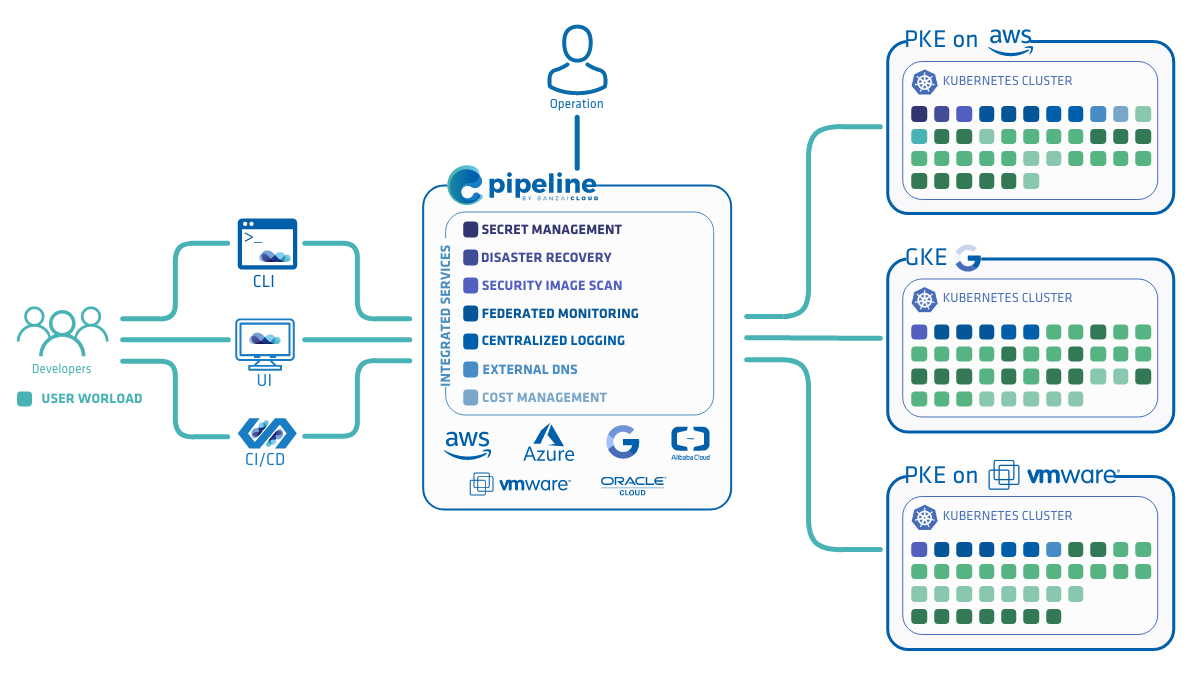
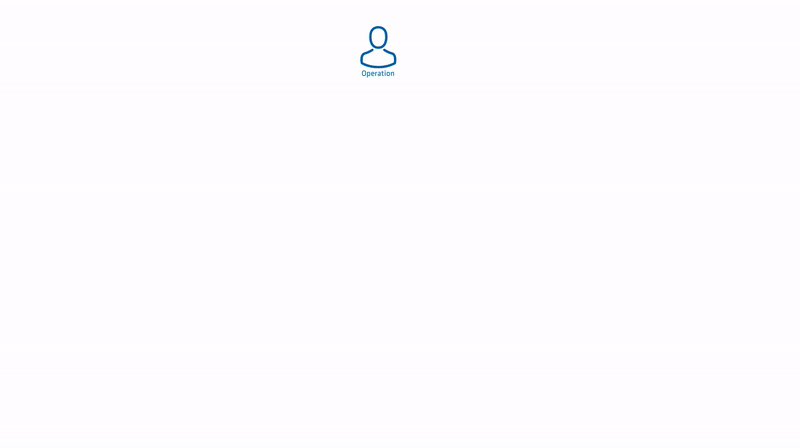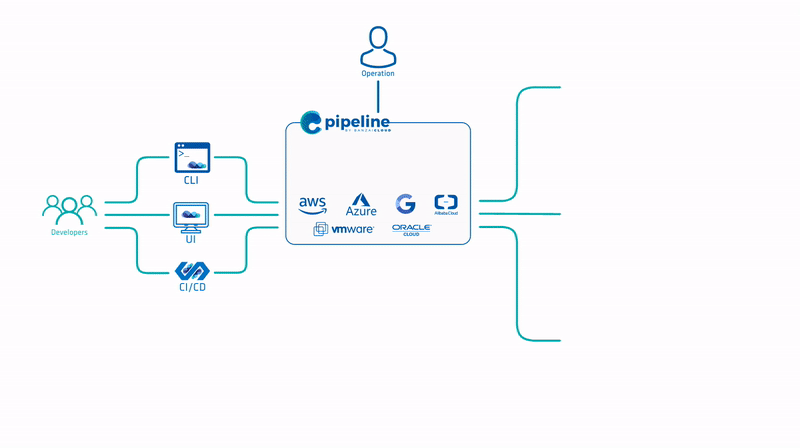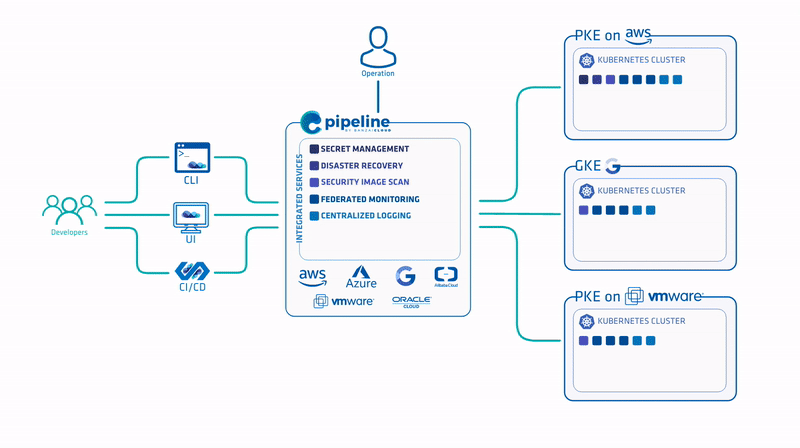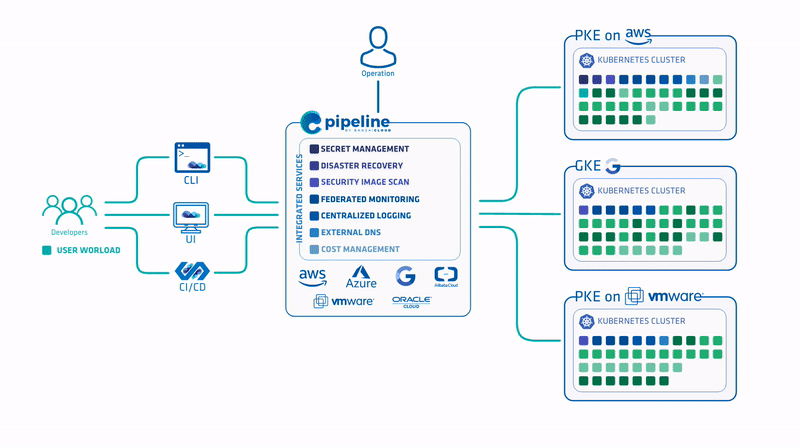
Pipeline has been a key enabler of multi- and hybrid-cloud strategies (across major cloud providers, including Amazon, Azure, Google and on-premise environments (VMware and bare metal)), providing both a unified cockpit for operations and a high level of workflow and workload portability for developers across major cloud and datacenters - in four different ways.
A hybrid cloud is a composition of two or more distinct cloud infrastructures (private, community, or public) that remain unique entities, but are bound together by technology that enables data and application portability (e.g., cloud bursting for load balancing between clouds).
vSphere overview 🔗︎
VMware’s server virtualization solution is called vSphere. The core of the solution is ESXi, the hypervisor responsible for the virtualization itself, basically everything needed to run virtual machines on a single stand-alone physical machine. ESXi alone is also called vSphere.
To use a bunch of physical machines as virtualization hosts together, vCenter is the way to go. It exposes a similar API to ESXi’s, but the end user doesn’t need to care much about virtualization hosts in this case.
This abstraction level is much lower than the one IaaS providers typically offer, which on the other hand means more tasks but more flexibility for the in-house ops team. There are countless cloud managers that could build on vSphere clusters as a virtualization backend (most of them based on OpenStack), but they are losing significance, while not being famous for eliminating infrastructure operation tasks other than day-to-day VM administration.
Let’s take a look at the main entities in vCenter that are interesting from our point of view.
vCenter manages virtual machines, which are basically a descriptor of a VM instance, with dependent or independent disks, and metadata that specifies their virtual hardware. They can be placed in resource pools, or directly on clusters. Clusters have a number of virtualization hosts registered, on which virtual machines can be placed by the distributed resource scheduler (DRS) or manually. Resource pools are logical units within a cluster, while clusters are placed in logical units called datacenters.
Virtual machines and templates (which are basically VMs with a flag that prevents them from powering on) are organized in a cluster- and resource pool independent hierarchy within datacenters: VM folders, also known as blue folders.
Shared storage is handled in another hierarchy within datacenters: datastores (VMFS file systems) mounted on one or more hosts can be registered standing alone, or forming datastore clusters. The latter is a collection of datastores where disk images can be distributed by the storage DRS based on capacity and performance considerations.
Launching virtual machines in vSphere typically involves the following steps:
- Cloning (the specification and the disks of) an existing template into a new virtual machine in a cluster or resorce pool, on a datastore or datastore cluster.
- Customization of virtual hardware resources, like setting different count of VCPUs or memory, changing networks, etc.
- Powering up the VM.
- Waiting for the VMware agent running on the VM to report its IP address.
Networking 🔗︎
One of the goals of our current efforts was to take advantage of the PKE architecture and workflow already used with AWS and Azure.
There is a basic difference between the abstraction level of cloud provider’s computing API and vCenter. In case of a cloud provider, we can rely on some common standards or default, which may not fit all user’s requirements, but can be used to start with, or to show the capabilities of Pipeline. That’s the case with networking: it might not be a perfect solution for production use cases, but we can automatically create a VPC for our clusters, which just works given that we get permission to do so. Of course, most real users do already have a VPC, or will create it for the specific use case, and of course, they can select it during cluster creation.
There is no such standard way that would allow us to create managed networks with properly configured internet access in a general on-premises infrastructure. Even if the virtualization environment allows creating some kind of networks on the fly, they usually depend on the configuration of other network devices like switches, routers or firewalls. This isn’t needed either, because VM templates in vSphere do already have an associated network, which we can use directly.
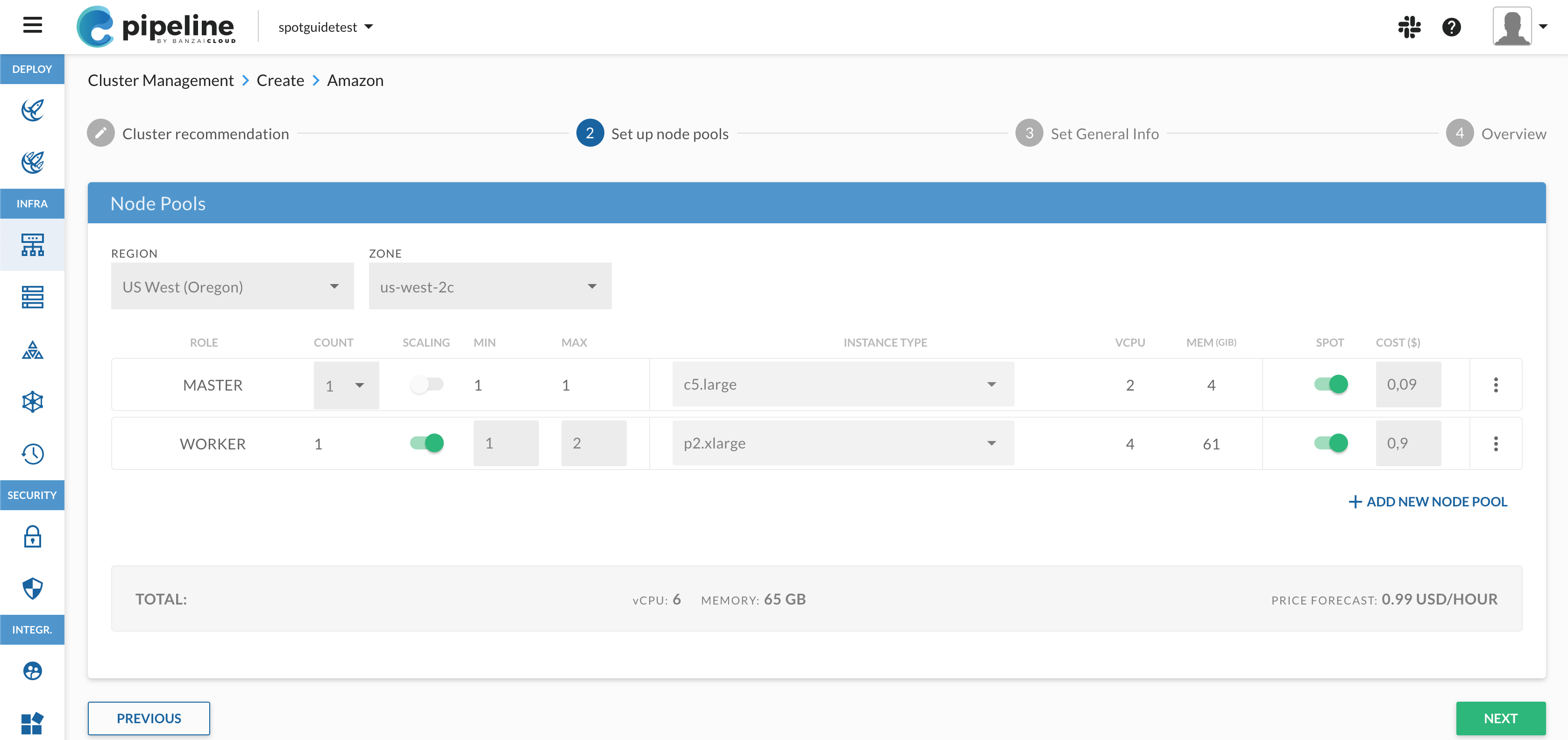
Node pools 🔗︎
Another important difference is that vSphere provides an API to manage virtual machines, but doesn’t include facilities like auto-scaling groups or scale sets. Virtual machines in vSphere are however more persistent compared to the approach of cloud providers, which is ensured by different features that keep individual virtual machines running in case of failures.
This lead us to implement a naive solution in Pipeline that ensures the desired number of virtual machines during the creation and scaling of clusters instead of passing this task to an external component.
Image 🔗︎
At cloud providers we have public images for cluster nodes, which provide a shortcut for users who want to try Pipeline. Even in cloud environment, many of our customers use custom images that meet their corporate standards or requirements.
Our automated image generation tools based on Packer support vSphere too, so we can easily work with customers to generate the image that fits their needs.
The image doesn’t have to contain a pre-installed PKE, we can use any template that contains a supported OS, and fulfills our basic requirements: to run the VMware agent which reports the acquired IP address of the machine back to vSphere, and to execute the cloud-init script passed through VMware’s guestinfo. Fortunately the latter is now working quite reliably — you may remember the days when attaching CD images with cloud-init configuration seemed reasonable.
Putting together 🔗︎
Let’s see how the most interesting part of a cluster’s workflow, the creation works.
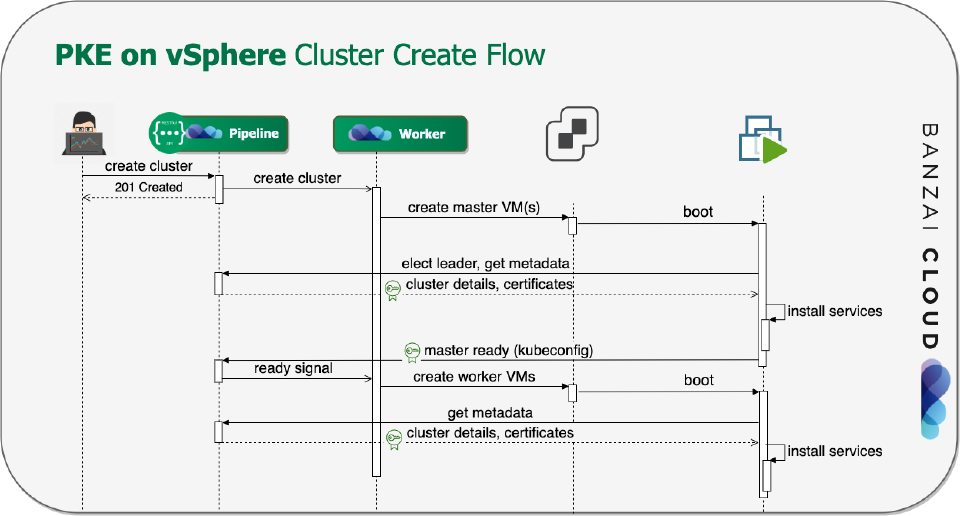

- We launch the needed number of master nodes as individual VMs.
- The nodes receive a cloud-init script that contains the cluster’s basic information—the Pipeline instance endpoint they belong to, and a JWT token that lets them make authenticated API calls to Pipeline.
- After that, the master nodes boot up, and the PKE installation begins.
- The first instance that comes up becomes the leader.
- Each master node fetches metadata, and, more importantly, the certificates generated by Pipeline with bank-vaults.
- After that, the PKE components are installed and configured.
- When the lead Kubernetes master is ready, it sends a node ready signal to Pipeline. The other masters wait for this event to join the cluster.
- All other worker nodepools are launched in a similar manner.
- Worker and follower master nodes request ephemeral Kubernetes bootstrap tokens from Pipeline, then join the cluster.
High availability 🔗︎
Kubernetes clusters have two important components that are needed to run anything else. These are the etcd which is responsible for the persistence of the resources, and the API server, which basically exposes the CRUD operations on this data over a REST interface. They are different in nature.
- Etcd is stateful, while includes the clustering solution which solves the basic load balancing and high availabilty requirements by the cooperation of the server and the client. Reliable clusters consist of odd number of nodes, and 3 of them is sufficient for most scenarios.
- The API server is stateless, so direct communication between its instances is not needed. It relies however on external solutions for load balanced or highly available behavior. Two instances are enough for most scenarios, while 3 of them perform a bit better in some failure scenarios if the accessibility of etcd is considered too.
We recommend three different HA models for different environments and requirements:
- Three dedicated master nodes running an etcd cluster, and three API server instances.
- Two API server instances backed by an external etcd cluster shared between multiple Kubernetes clusters.
- Three of the cluster nodes have shared responsibility: they run normal workload besides etcd and the API server.
As we discussed in our MetalLB post, unlike in the case of public cloud providers, we can’t rely on a standard network load balancer to access one of the healthy API servers. Moreover, our preferred Kubernetes LoadBalancer implementation can’t be used for essential cluster components beacuse of a chicken and egg situation (however there are some proposals for this).
We decided to use Keepalived to implement a floating IP that’s assigned to exactly one healthy master node every time. This can be easily combined or replaced with existing on-prem load balancer services (like F5’s solutions) or round-robin DNS.
All you have to do is to specify the IP address that the cluster can take, and optionally, the DNS name that’s directed to the virtual IP or the nodes either via a L3 or HTTPS load balancer, or round-robin DNS.
Kubernetes LoadBalancers 🔗︎
Kubernetes LoadBalancer services are implemented with MetalLB, which is automatically set up by Pipeline. We’ve discussed this earlier in detail.
Storage integration 🔗︎
Pipeline and PKE are able to set up a storage class based on independent disks in vSphere. This solution creates and attaches virtual disks to the node running the pod that wants to use a persistent volume, and takes care of its life cycle. All you have to do to use this is creating a VMware service account for this, and pass it as a Pipeline secret.
Conclusion 🔗︎
We can proudly state that we achieved a similar level of services in VMware environment that we can use at public cloud providers. This together with the Backyards service mesh makes hybrid cloud a real choice for organizations who want to have the advantages of both private and public cloud.
About PKE 🔗︎
Banzai Cloud Pipeline Kubernetes Engine (PKE) is a simple, secure and powerful CNCF-certified Kubernetes distribution, the preferred Kubernetes run-time of the Pipeline platform. It was designed to work on any cloud, VM or on bare metal nodes to provide a scalable and secure foundation for private clouds. PKE is cloud-aware and includes an ever-increasing number of cloud and platform integrations.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.