

To evaluate the services Banzai Cloud One Eye (One Eye) offers, we recommend creating a test environment. This way you can start over any time, and try all the options you are interested in without having to worry about changes made to your existing environment, even if it’s not used in production.
Production installation is very similar, but you must exactly specify which components you want to use.
Prerequisites 🔗︎
Before deploying One Eye on your cluster, complete the following tasks.
-
Create a test cluster.
You need a Kubernetes cluster to test One Eye with. If you don’t already have a Kubernetes cluster to work with, create one with one of the following methods:
- Launch a cluster at one of the many cloud providers’ managed offerings at their console.
- Use KinD on your machine (make sure to increase the resource allocation of Docker for Mac).
-
(Optional) If you want to test One Eye in a multicluster environment, create one more cluster.
-
(Optional) To store your data for longer period, create an object store. If you are just running a quick test, you don’t necessarily need an object store.
You will need an object store. Thanos supports many types of object storage, see the official Thanos documentation for details.
-
Install the One Eye tool.
Install the One Eye command-line tool. You can use the One Eye CLI tool to install One Eye and other components to your cluster.
Note: The One Eye CLI supports macOS and Linux (x86_64). It may work on Windows natively, but we don’t test it.
-
Register for an evaluation version.
As you might know, Cisco has recently acquired Banzai Cloud. Currently we are in a transitional period and are moving our infrastructure. Contact us so we can discuss your needs and requirements, and organize a live demo.
-
Install the
one-eye-clipackage for your environment.
-
Set Kubernetes configuration and context 🔗︎
The command-line tool uses your current Kubernetes context, from the file named in the KUBECONFIG environment variable (~/.kube/config by default). Check if this is the cluster you plan to deploy the product by running the following command: kubectl config get-contexts
If there are multiple contexts in the Kubeconfig file, specify the one you want to use with the use-context parameter, for example: kubectl config use-context <context-to-use>
Deploy One Eye 🔗︎
After you have completed the Prerequisites, you can install One Eye on a single cluster.
Note: To use One Eye in a multicluster environment, you can add peer clusters later.
-
The following command installs the main One Eye components and their dependencies, including the Logging Operator, the Logging Extension, a Prometheus Operator, and the One Eye web interface.
one-eye installDuring the interactive mode, the One Eye CLI will help you configure your initial logging configuration.
-
Enter the name of the cluster, as you want it to be displayed on the One Eye UI and other components. By default, One Eye uses cluster name from the current KUBECONTEXT. After you enter the name, the main components of One Eye are installed.
? How should the cluster be referred to? my-demo-cluster ✓ crds ❯ resource created name=observers.one-eye.banzaicloud.io, apiVersion=apiextensions.k8s.io/... ✓ observer ❯ resource created name=one-eye, apiVersion=one-eye.banzaicloud.io/v1alpha1, ... ✓ logging-operator/readiness ❯ done ✓ logging-extensions/readiness ❯ done ✓ one-eye-ui/readiness ❯ done ✓ prometheus-operator ❯ reconciling ... -
Follow the on-screen instructions to configure a simple logging system.
? Configure persistent volume for buffering logs? No # apiVersion: logging.banzaicloud.io/v1beta1 kind: Logging metadata: name: one-eye spec: enableRecreateWorkloadOnImmutableFieldChange: true controlNamespace: default fluentbit: metrics: ... ? Edit the configuration in an editor? No ? Apply the configuration? Yes observer> resource created name: ... ? Create a new Flow? YesThe CLI will provide a template for the Logging resource with some basic configuration. You can edit this template and decide to apply it on the cluster or not. After applying the logging resource, continue to create an
Outputand aFlow. -
Configure an output. You can configure an S3 output, or a nullout output (the interactive mode supports only these outputs, you can configure other outputs in the Logging operator after you have finished the installation).
? What type of output do you need? s3 ? Select the namespace for your output default ? Use the following name for your output s3 ? S3 Bucket banzai-one-eye ? Region of the bucket eu-west-1 ? Configure authentication based on your current AWS credentials? Yes ? Save AKIXXXXXXXXXXXXXXXX to a Kubernetes secret and link it with the output Yes # Copyright © 2020 Banzai Cloud apiVersion: logging.banzaicloud.io/v1beta1 kind: Output metadata: name: s3 namespace: default spec: # Reference docs for the output configuration: # https://banzaicloud.com/docs/one-eye/logging-operator/plugins/outputs/s3 s3: s3_bucket: banzai-one-eye s3_region: eu-west-1 path: logs/${tag}/%Y/%m/%d/ aws_key_id: valueFrom: secretKeyRef: name: s3-6bcf key: awsAccessKeyId aws_sec_key: valueFrom: secretKeyRef: name: s3-6bcf key: awsSecretAccessKey ? Edit the configuration in an editor? No ? Apply the configuration? Yes observer> resource created name: s3...If you have your Amazon credential configured in your environment, the CLI will ask if you want to use them to access the bucket. When you choose yes the CLI will automatically create a Kubernetes secret with your Amazon Key and Secret. After specifying the bucket name and region the generated template is ready to be used (or customized). It includes the secret name and bucket information as well.
Note: For details on configuring different output types, see the Logging Operator quick start guides.
-
Configure a logging flow. The basic template provides an empty flow. Customize the
matchsection and add filters from the supported filter list if needed.? Select the namespace for your flow default Available Outputs: [s3] ? Select an output s3 ? Give a name for your flow my-flow # apiVersion: logging.banzaicloud.io/v1beta1 kind: Flow metadata: name: my-flow namespace: default spec: filters: # tag normalizer changes default kubernetes tags coming from fluentbit to the following format: namespace.pod.container # https://banzaicloud.com/docs/one-eye/logging-operator/configuration/plugins/filters/tagnormaliser/ - tag_normaliser: {} match: # a select without restrictions will forward all events to the outputRefs - select: {} outputRefs: - s3 ? Edit the configuration in an editor? No ? Apply the configuration? Yes observer> resource created name: my-flow...After applying the yaml, the logs are flowing to the S3 bucket.
-
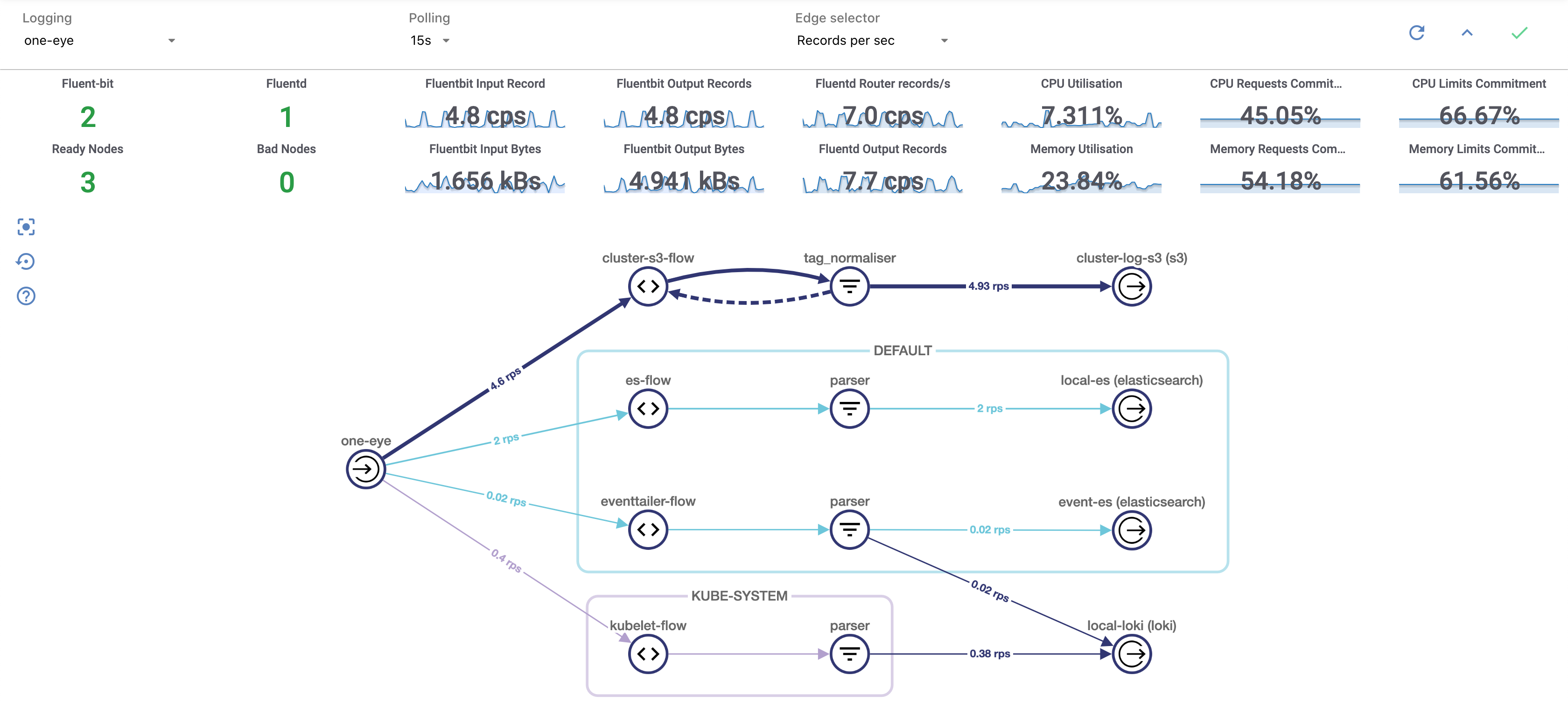
Connect to the One Eye Dashboard and review your logging infrastructure.
one-eye ingress connectThe One Eye UI opens in your browser.
Multicluster metrics 🔗︎
To use One Eye to collect metrics in a multicluster environment, follow the Multicluster quickstart guide to configure a peer cluster.




