






A few weeks back we released Telescopes, our Kubernetes cluster layout recommender application. That application has evolved quite a bit, and in this post we’ll provide insight into some its new features and recent changes.
Cloud cost management series:
Overspending in the cloud
Managing spot instance clusters on Kubernetes with Hollowtrees
Monitor AWS spot instance terminations
Diversifying AWS auto-scaling groups
Draining Kubernetes nodes
tl;dr: 🔗︎
- We added new features to Telescopes to provide support for blacklisting or whitelisting instance types
- Recommendation accuracies can now be checked
- There is now support that allows asking cloud instance types for CPU, memory and network performance.
- Cloudinfo is the best place to find the information you need about cloud providers, and supported instance types have been updated.
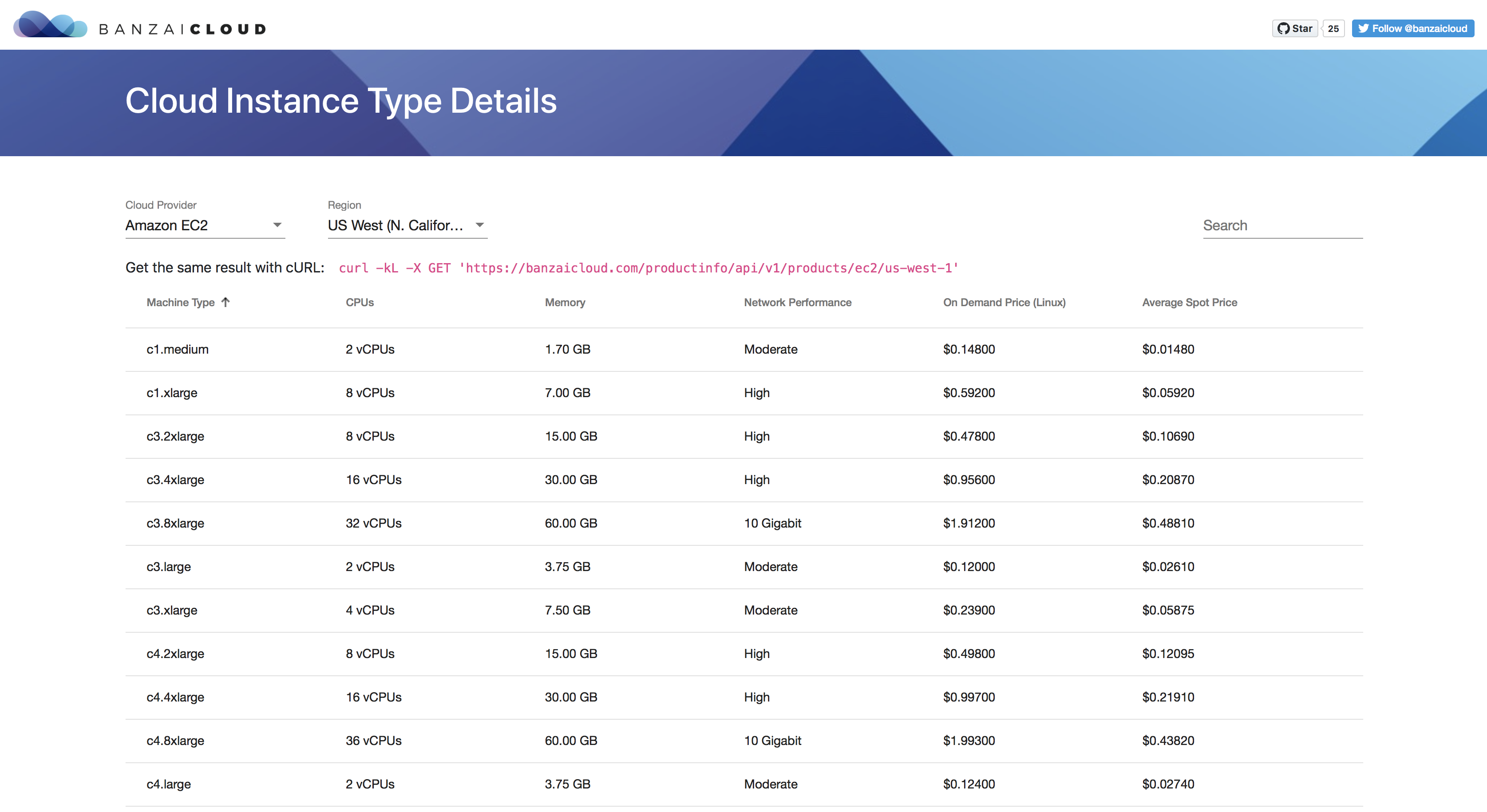
Recent changes 🔗︎
When we started using Telescopes and added basic support for a couple of new cloud providers (GCE, Azure), it became obvious that the recommendation logic needed to be separated from cloud product information retrieval. Moreover, the recommendation logic itself had to be cloud agnostic.
Accordingly, product retrieval has been extracted into a separate project. This new project is also responsible for bringing provider specific product details to the same representation. Telescopes has access to this information via a generated rest client.
As a consequence of the above change, cloud credentials are not necessary for Telescopes, so these have been removed from the application (starting the application has been simplified).
To support enterprise users and Pipeline, we added OAblacklistuth2 bearer token based support to Telescopes. This change requires that two other components also be running: one component that is able to emit bearer tokens (eg.: Banzai Cloud’s Pipeline), the other, a Vault instance that securely handles sensitive information (bearer tokens in this case). For more information, read our blog series on security. This complicates starting Telescopes quickly a bit. For non-production use, however, there is the --dev-mode flag that passes the application at start and disables authentication.
Apart from these “organizational” changes, we refined the manner in which cluster recommendations may be requested; the recommendation request has been extended to support blacklist and whitelist for virtual machines. It is possible to request clusters that don’t contain virtual machines in the blacklist, and clusters that only contain virtual machines in the whitelist.
We made an effort to take into account network performance when recommending clusters; it is now possible to specify the desired network performance category in recommendation requests. For the time being, we’ve settled on four categories (low, medium, high and extra), but we’ll refine these further based on information/usage patterns as they emerge.
We’ve extended recommendation requests to control whether burstable instances are allowed in recommended clusters.
One major improvement we’ve added is that recommendation accuracy information is embedded in every recommendation response. Requested resources can be compared to the recommended cluster so that the user has a sense of the recommendation’s correctness. Recommendation accuracy also contains pricing information, so users are provided with early cost information.
Check the swagger description of the Telescopes API for the exact details, here
What’s next? 🔗︎
We have lots of new features on the docket to add to Telescopes. We plan to offer more options for fine grained cluster recommendations such as support for GPU, I/O resources.
As stated earlier, Telescopes recommends cluster layouts in a cloud agnostic way, and Pipeline is responsible for managing (creating, updating, deleting) clusters, and is cloud agnostic. One of the most exciting features we plan to add is support for comparison of cluster recommendations on different providers. This outstanding feature will allow customers to choose the provider that best fits their needs.
A simple use case 🔗︎
Let’s imagine a case in which we have an application, and we pretty much know the resources that are needed for it to run properly (this information may be available from previous usage analysis or/and monitoring). Now, the operators are thinking of moving the application in the cloud, and they want to explore what possibilities are available on the market before they make a decision. Let’s also imagine that they don’t have exhaustive knowledge of product details pertaining to available cloud providers. Application operators can use Telescopes to help make the right choice.
As an example, let’s suppose that the resource requirements for the imaginary application are: at least 8 CPUs, at least 10G memory, at most 4 nodes and a medium network performance. Half of the nodes are allowed to be spot priced nodes (these costs can be improve significantly as the onDemandPct decreases - however these nodes may be lost - Banzai Cloud Pipeline and Banzai Cloud Hollowtrees address this problem). These resource requirements are comprised by the json-s posted to Telescopes:
Request cluster recommandation on ec2:
curl -sLX POST \
http://localhost:9095/api/v1/recommender/ec2/eu-west-1/cluster \
-d '{
"sumCpu": 8,
"sumMem": 10,
"minNodes": 1,
"maxNodes": 4,
"onDemandPct": 50,
"networkPerf": "medium"
}'Request cluster recommandation on gce:
curl -X POST \
http://localhost:9095/api/v1/recommender/gce/europe-west1/cluster \
-d '{
"sumCpu": 8,
"sumMem": 10,
"minNodes": 1,
"maxNodes": 4,
"onDemandPct": 50,
"networkPerf":"medium"
}'Let’s check and compare responses:
Recommendation response for ec2:
{
"provider": "ec2",
"nodePools": [
{
"vm": {
"type": "t2.xlarge",
"avgPrice": 0.0605,
"onDemandPrice": 0.2016,
"cpusPerVm": 4,
"memPerVm": 16,
"gpusPerVm": 0,
"burst": true,
"networkPerf": "Moderate",
"networkPerfCategory": "medium"
},
"sumNodes": 1,
"vmClass": "regular"
},
{
"vm": {
"type": "m1.xlarge",
"avgPrice": 0.0379,
"onDemandPrice": 0.379,
"cpusPerVm": 4,
"memPerVm": 15,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "High",
"networkPerfCategory": "medium"
},
"sumNodes": 1,
"vmClass": "spot"
},
// the "empty" nodepools are truncated!!!
.....
],
"accuracy": {
"memory": 31,
"cpu": 8,
"nodes": 2,
"regularPrice": 0.2016,
"regularNodes": 1,
"spotPrice": 0.0379,
"spotNodes": 1,
"totalPrice": 0.2395
}
}Recommendation response for gce:
{
"provider": "gce",
"nodePools": [
{
"vm": {
"type": "n1-standard-2",
"avgPrice": 0.022000000000000002,
"onDemandPrice": 0.10460000000000001,
"cpusPerVm": 2,
"memPerVm": 7.5,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "4",
"networkPerfCategory": "medium"
},
"sumNodes": 2,
"vmClass": "regular"
},
{
"vm": {
"type": "n1-standard-2",
"avgPrice": 0.022000000000000002,
"onDemandPrice": 0.10460000000000001,
"cpusPerVm": 2,
"memPerVm": 7.5,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "4",
"networkPerfCategory": "medium"
},
"sumNodes": 2,
"vmClass": "spot"
},
// the "empty" nodepools are truncated!!!
.....
],
"accuracy": {
"memory": 30,
"cpu": 8,
"nodes": 4,
"regularPrice": 0.20920000000000002,
"regularNodes": 2,
"spotPrice": 0.044000000000000004,
"spotNodes": 2,
"totalPrice": 0.25320000000000004
}
}As you can see, the same resources are spread across different cluster layouts on the two providers, but both recommendations meet our requirements. Recommendations can be further refined in order to help operators decide on a provider (and cluster layouts). Keep reading to learn how Telescopes can be started locally and how to start telescoping cluster layouts.
Telescopes - deep dive 🔗︎
Let’s quickly try Telescopes locally.
Note: it’s assumed that you have a properly set up Go environment
First we need to start the Banzai Cloud Cloudinfo application. For this execute the commands listed below:
# check out the source code from GitHub
go get -d github.com/banzaicloud/cloudinfo
# cd to the checked out project's root folder
cd $GOPATH/src/github.com/banzaicloud/cloudinfo
# build the application with make - alternatively, find the command in the makefile and execute it
make build
# set the AWS credentials - you can skip these if you have the aws configuration set up at ~/.aws/credentials
export AWS_ACCESS_KEY_ID=<your aws access key>
export AWS_SECRET_ACCESS_KEY=<your aws secret access key>
./cloudinfo --provider=ec2The Cloudinfo application should start and listen for requests on port 9090 on localhost.
The status of Cloudinfo services can be checked with the following curl command (you’ll get the response status code 200, and the body “ok”):
curl -X GET http://localhost:9090/statusNow let’s start the application and point it to our started Cloudinfo service:
# check out the source code from GitHub
go get -d github.com/banzaicloud/telescopes
# cd to the checked out project's root folder
cd $GOPATH/src/github.com/banzaicloud/telescopes
# build the application with make, alternatively find the command in the makefile and execute it
make build
# you can omit the --cloudinfo-address, since Telescopes will connect to the default cloudinfo address (this is only to show the connection point to Cloudinfo)
./telescopes --dev-mode --cloudinfo-address=localhost:9090 --listen-address=:9095Warning: authentication is disabled in dev-mode, it’s not advisable to run Telescopes in production this way
The Telescopes application is up and it’s listening for requests on port 9095 on localhost.
The status of Telescopes can be checked with the following curl command (you’ll get the response status code 200, and the body “ok”):
curl -X GET http://localhost:9095/statusFinally we can issue recommendation requests.
Let’s start with a simple request:
These examples are requesting cluster recommendations on Amazon in the eu-west-1 region. These are reflected in the request path. Feel free to experiment with other providers and regions.
curl -sLX POST http://localhost:9095/api/v1/recommender/ec2/eu-west-1/cluster \
-d '{"sumCpu": 8, "sumMem": 10, "minNodes": 1, "maxNodes": 4, "onDemandPct": 50}' | jq .The requested cluster should have 8 CPUs, at least 10G memory, 1 to 4 nodes from which 50% should be “on demand” instances.
At the time of writing this article, the response for the above request is:
{
"provider": "ec2",
"nodePools": [
{
"vm": {
"type": "t2.medium",
"avgPrice": 0.015,
"onDemandPrice": 0.05,
"cpusPerVm": 2,
"memPerVm": 4,
"gpusPerVm": 0,
"burst": true,
"networkPerf": "Low to Moderate",
"networkPerfCategory": "low"
},
"sumNodes": 2,
"vmClass": "regular"
},
{
"vm": {
"type": "t2.medium",
"avgPrice": 0.015,
"onDemandPrice": 0.05,
"cpusPerVm": 2,
"memPerVm": 4,
"gpusPerVm": 0,
"burst": true,
"networkPerf": "Low to Moderate",
"networkPerfCategory": "low"
},
"sumNodes": 2,
"vmClass": "spot"
},
{
"vm": {
"type": "m1.xlarge",
"avgPrice": 0.0379,
"onDemandPrice": 0.379,
"cpusPerVm": 4,
"memPerVm": 15,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "High",
"networkPerfCategory": "medium"
},
"sumNodes": 0,
"vmClass": "spot"
},
{
"vm": {
"type": "m1.large",
"avgPrice": 0.019,
"onDemandPrice": 0.19,
"cpusPerVm": 2,
"memPerVm": 7.5,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "Moderate",
"networkPerfCategory": "medium"
},
"sumNodes": 0,
"vmClass": "spot"
}
],
"accuracy": {
"memory": 16,
"cpu": 8,
"nodes": 4,
"regularPrice": 0.1,
"regularNodes": 2,
"spotPrice": 0.03,
"spotNodes": 2,
"totalPrice": 0.13
}
}As you can see there are multiple instance types in the response, and recommendation accuracy is pretty good. There are 4 nodes recommended from which 2 are “regular” (on demand instances) and 2 are spot instances. The memory is a bit above the requested limit.
Let’s imagine we don’t want burstable instances in our cluster; let’s repeat the recommendation with the following details:
curl -sLX POST http://localhost:9095/api/v1/recommender/ec2/eu-west-1/cluster \
-d '{"sumCpu": 8, "sumMem": 10, "minNodes": 1, "maxNodes": 4, "onDemandPct": 50, "allowBurst":false}' | jq .The request is modified so that it disallows burstable instances with the allowBurst attribute set to false
The result will look like this:
{
"provider": "ec2",
"nodePools": [
{
"vm": {
"type": "c5.large",
"avgPrice": 0.04033333333333333,
"onDemandPrice": 0.096,
"cpusPerVm": 2,
"memPerVm": 4,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "Up to 10 Gigabit",
"networkPerfCategory": "high"
},
"sumNodes": 2,
"vmClass": "regular"
},
{
"vm": {
"type": "m1.xlarge",
"avgPrice": 0.0379,
"onDemandPrice": 0.379,
"cpusPerVm": 4,
"memPerVm": 15,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "High",
"networkPerfCategory": "medium"
},
"sumNodes": 1,
"vmClass": "spot"
},
{
"vm": {
"type": "m1.large",
"avgPrice": 0.019,
"onDemandPrice": 0.19,
"cpusPerVm": 2,
"memPerVm": 7.5,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "Moderate",
"networkPerfCategory": "medium"
},
"sumNodes": 0,
"vmClass": "spot"
},
{
"vm": {
"type": "m2.2xlarge",
"avgPrice": 0.055,
"onDemandPrice": 0.55,
"cpusPerVm": 4,
"memPerVm": 34.2,
"gpusPerVm": 0,
"burst": false,
"networkPerf": "Moderate",
"networkPerfCategory": "medium"
},
"sumNodes": 0,
"vmClass": "spot"
}
],
"accuracy": {
"memory": 23,
"cpu": 8,
"nodes": 3,
"regularPrice": 0.192,
"regularNodes": 2,
"spotPrice": 0.0379,
"spotNodes": 1,
"totalPrice": 0.2299
}
}The accuracy of this request is again reflected in the recommendation details: there are 3 nodes recommended now (2 regular, 1 on demand), 8CPUs and, again, the memory is a bit more than what was requested.
Based on our recommendation results, we can further refine the request so that the recommended cluster more closely aligns with our requirements, eg.: blacklist or whitelist instance types, set network performance requirements, modify the node count, modify the on-demand percentage, etc.
Here is an example request, which demonstrates how these various attributes should be filled in the request json:
{
"sumCpu": 8,
"sumMem": 10,
"minNodes": 1,
"maxNodes": 4,
"onDemandPct": 50,
"allowBurst": false,
"excludes":["c5.large"], // these instance types will be excluded from the recommendation
"includes":["c5.xlarge"], // the recommendation will be limited to the instanxe types listed here
"networkPerf":"high" // the recommendation will be limited to this network performance
}Happy Telescoping!
If you’d like to learn more about Banzai Cloud, check out our other posts on this blog, the Pipeline, Hollowtrees and Bank-Vaults projects.




