






A few months ago the Kubernetes Operator SDK was released with one of its goals being the conversion of human operational knowledge into code. At Banzai Cloud we’ve been contributors and early adopters of this technology, since it provides a better standardized method of automating our processes and allows us to dramatically ease the lives of our customers. We are building a feature rich enterprise-grade application platform, built for containers on top of Kubernetes, called Pipeline, wherein we endeavour to automate the DevOps experience and the lifecycle of deployments. By default we collect metrics for all deployments done with Pipeline - using Prometheus - and autoscale them. However, our customers bring their own deployments to the platform as well (beside the default, supported ones). This open source component gives them a way to set up autoscaling without having to modify their deployment charts or deploy HPA; we have automated the whole process for them.
Horizontal Autoscaling on custom metrics 🔗︎
In the last post from our scaling series on Kubernetes we discussed how to autoscale Kubernetes deployments.
Kubernetes supports three different kind of autoscalers - cluster, horizontal and vertical.
Autoscaling Kubernetes clusters
Vertical pod autoscaler
Horizontal pod autoscaler
To quickly recap, in order to autoscale, you will need to create a HorizontalPodAutoscaler resource, which must be included in your Helm chart as well. Needless to say that, if we check the official Helm chart repository, most of the available charts don’t support autoscaling without modifications. However, some include the HorizontalPodAutoscaler resource definitions.
tl;dr: 🔗︎
You may not want to, or be able to edit a Helm chart in order to add an autoscaling feature. Nearly all charts supports custom annotations, so we believe it’s a good idea to setup autoscaling just by adding a few simple annotations to your deployment.
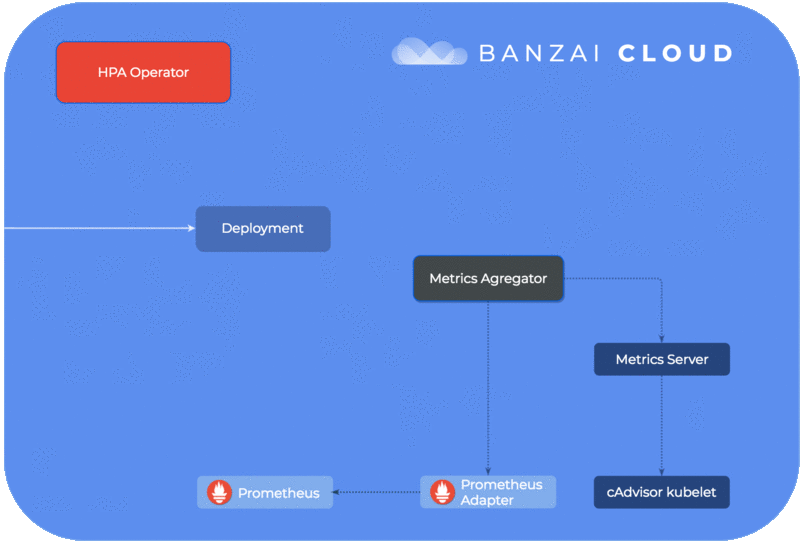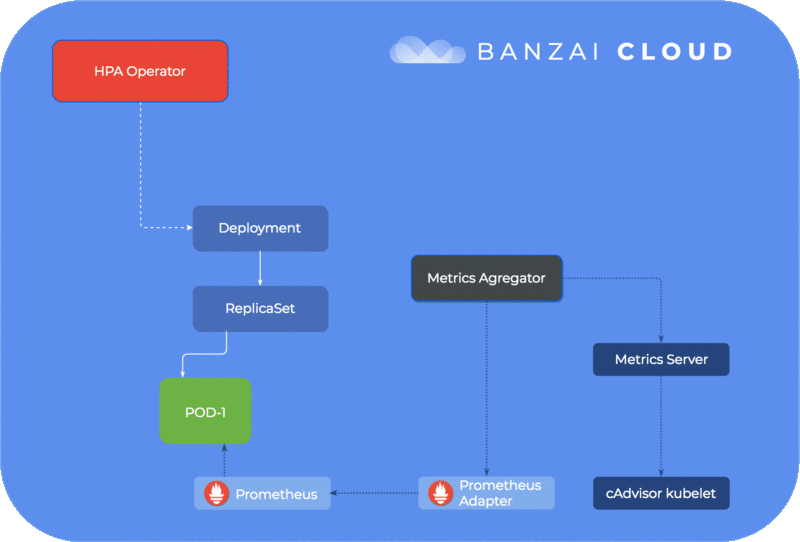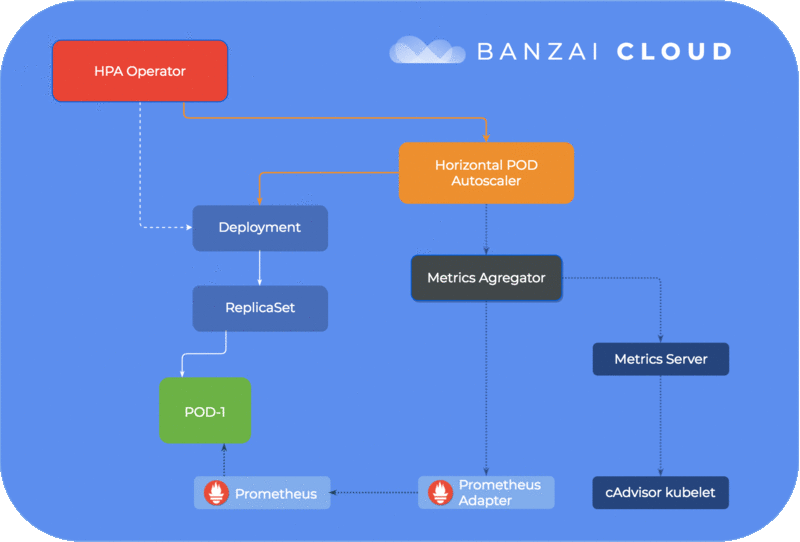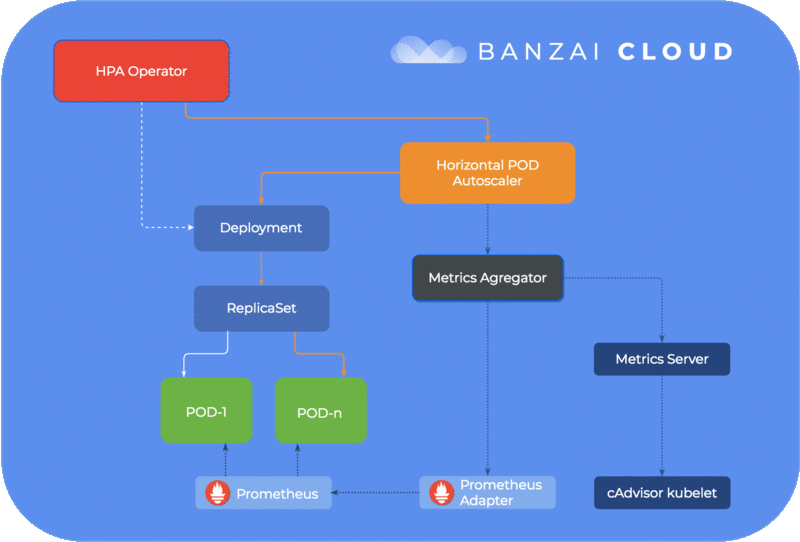
We have open sourced a Horizontal Pod Autoscaler operator. This operator watches for your Deployment or StatefulSet and automatically creates a HorizontalPodAutoscaler resource, should you provide the correct autoscale annotations.
Autoscale by annotations 🔗︎
Autoscale annotations can be placed:
-
directly on Deployment / StatefulSet:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: example labels: annotations: autoscale/minReplicas: "1" autoscale/maxReplicas: "3" autoscale/cpu: "70" -
or on
spec.template.metadata.annotations:apiVersion: extensions/v1beta1 kind: Deployment ... spec: replicas: 3 template: metadata: labels: ... annotations: autoscale/minReplicas: "1" autoscale/maxReplicas: "3" autoscale/cpu: "70"
The Horizontal Pod Autoscaler operator takes care of creating, deleting, updating HPA, in other words syncing with your deployment annotations.
Annotations explained 🔗︎
All annotations must be prefixed with autoscale. It is required that you specify minReplicas/maxReplicas and at least one metric to be used for autoscale. You can add Resource-type metrics for CPU & memory and Pods-type metrics.
Let’s see what kind of annotations we can use to specify metrics:
-
autoscale/cpu: "{targetAverageUtilizationPercentage}"- adds a Resource-type metric for the CPU with targetAverageUtilization set as specified, where targetAverageUtilizationPercentage should be an integer value between [1-100] -
autoscale/memory: "{targetAverageValue}"- adds a Resource-type metric for memory with targetAverageValue set as specified, where targetAverageValue is a Quantity. -
autoscale.pod/custom_metric_name: "{targetAverageValue}"- adds a Pods-type metric with targetAverageValue set as specified, where targetAverageValue is a Quantity.
To use custom metrics from Prometheus, you have to deploy
Prometheus AdapterandMetrics Server, which we explored in detail in our previous post about using HPA with custom metrics.
Quick usage example 🔗︎
Let’s pick Kafka as an example chart, from our curated list of Banzai Cloud Helm charts. The Kafka chart by default doesn’t contains any HPA resources, however, it allows specifying Pod annotations as params, so it’s a good place to start. Now let’s see how we might add a simple CPU-based autoscale rule for Kafka brokers through the addition of some simple annotations:
- Deploy operator
helm install banzaicloud-stable/hpa-operator
- Deploy Kafka chart, with autoscale annotations
cat > values.yaml <<EOF
{
"statefullset": {
"annotations": {
"autoscale/minReplicas": "3",
"autoscale/maxReplicas": "8",
"autoscale/cpu": "60"
}
}
}
EOF
helm install -f values.yaml banzaicloud-stable/kafka
- Check if HPA is created
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
kafka StatefulSet/kafka 3% / 60% 3 8 1 1m
Happy Autoscaling!
Learn more about the different types of autoscaling features supported and automated by the Banzai Cloud Pipeline platform platform:
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.







