Yes, we opensourced yet another Kubernetes operator for Apache Kafka. This might seem bizarre, considering the alternatives that are already available (they exist but there are not too many), so you may be wondering, ‘Why?’ Well, keep reading and we’ll tell you: from design gaps and features we believe are necessary to operate Kafka on K8s, through my personal fix for Envoy, to some of our specific usage scenarios.
tl;dr 🔗︎
So to return to our initial question, ‘Why?’
- We could not find another operator which really matched our customer usage patterns when running large Kafka clusters on-prem, and in multi and hybrid-cloud environments.
- The nearest we got to finding such an operator (that was open source) was written in Java, and we prefer working in Golang (we wanted to contribute back the features we needed).
- We believe the other operators out there have some fundamental design flaws, which we were not willing to accommodate.
- We opensourced an Apache Kafka operator built in Golang.
- The Pipeline platform builds on top of the operator and allows us to run and operate managed Kafka as a service across all supported platforms.
- As a side effect of working on some complex operators like Koperator , Istio or Vault, we opensourced a Kubernetes objectmatcher library to help avoid unnecessary Kubernetes object updates.
Ok, that just about does it for complaints and excuses; let’s move on to some real technical content. If you’d like to see the operator in action make sure you try out the Pipeline Platform, the easiest way to run Kafka on Kubernetes deployed to multiple clouds or on-prem with the Kafka Spotguide - Zookeeper, pre-configured Prometheus monitoring, Kafka security, centralized log collection, external accees and lots more are out of the box services.
Overview 🔗︎
Apache Kafka is an open-source distributed streaming platform, and some of the main features of the Koperator are:
- the provisioning of secure and production ready Apache Kafka clusters
- fine grained broker configuration support
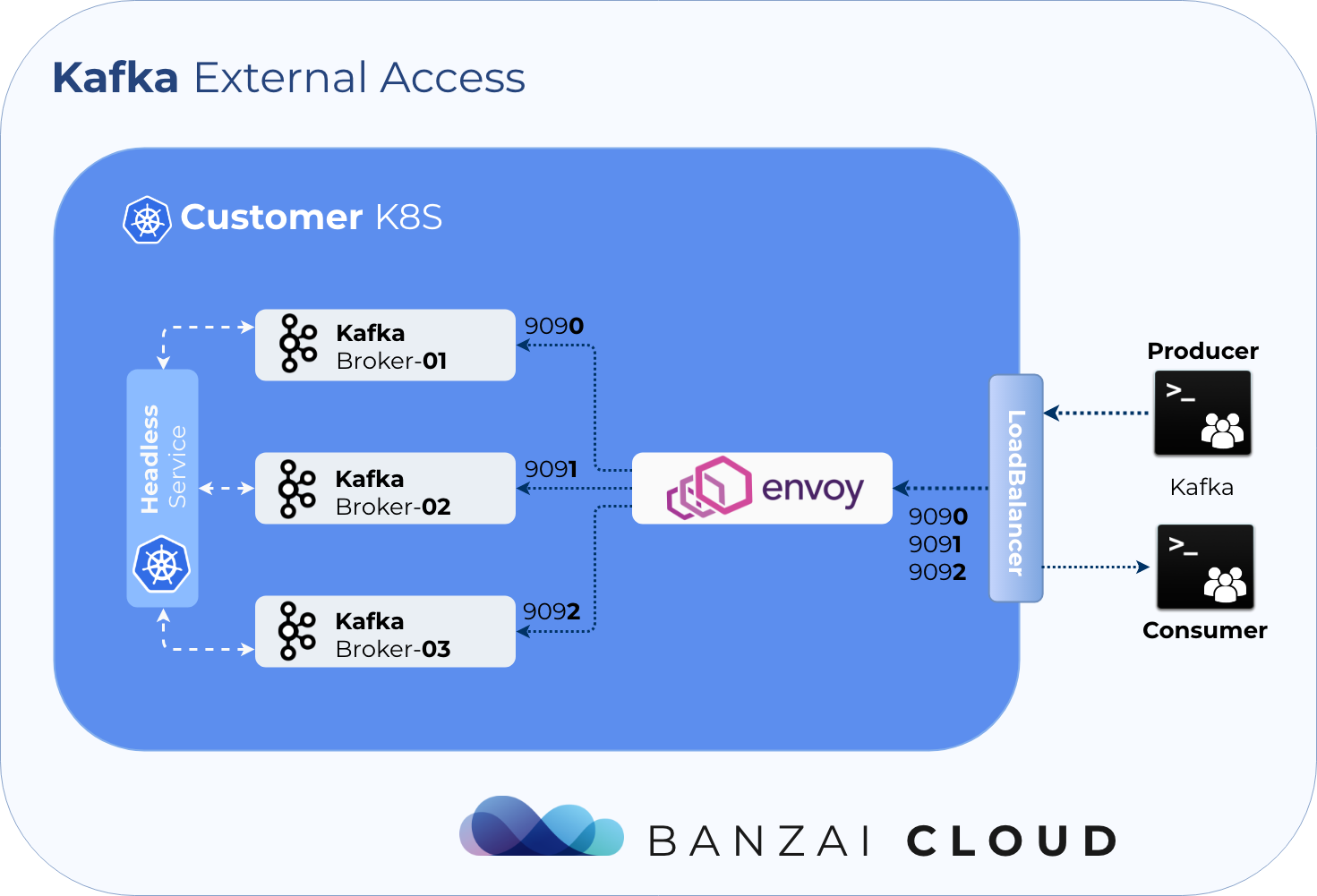
- advanced and highly configurable External Access via LoadBalancers using Envoy
- graceful Kafka cluster scaling and rebalancing
- monitoring via Prometheus
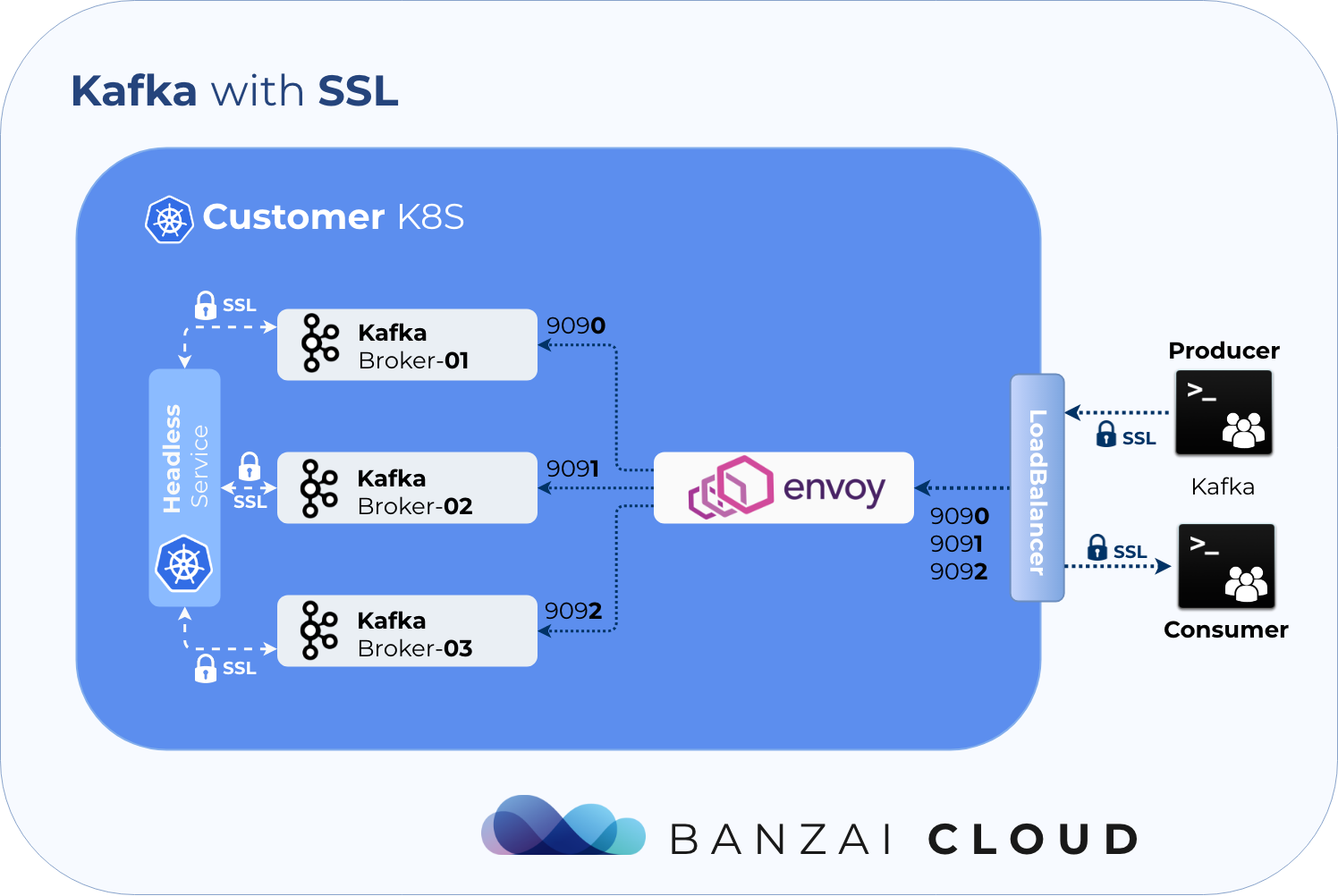
- encrypted communication using SSL
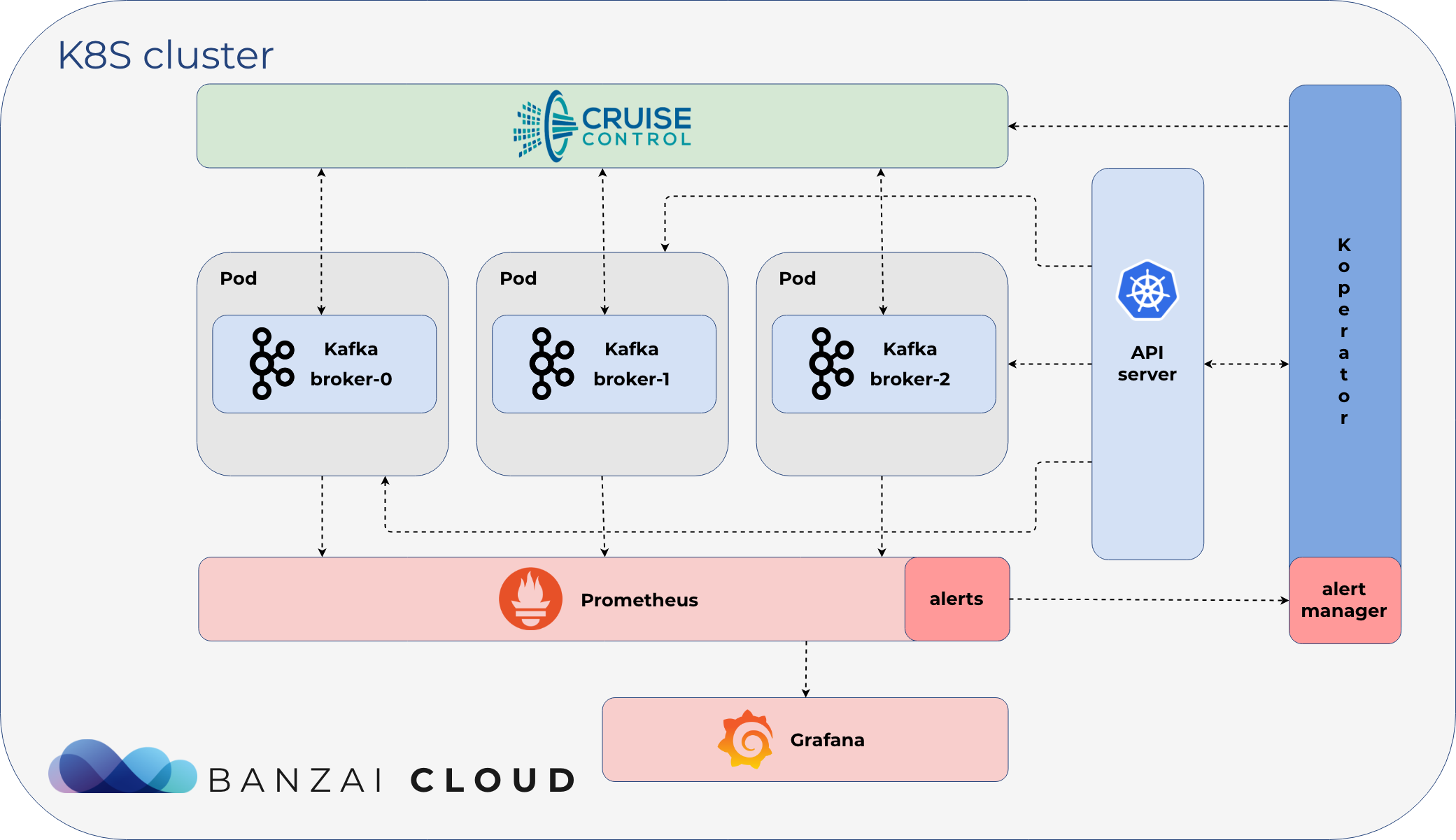
- automatic reaction and self healing based on alerts (plugin system, with meaningful default alert plugins) using Cruise Control
Motivation 🔗︎
At Banzai Cloud we are building a Kubernetes distribution, PKE, and a hybrid-cloud container management platform, Pipeline, that operate Kafka clusters (among other types) for our customers. Apache Kafka predates Kubernetes and was designed mostly for static on-premise environments. State management, node identity, failover, etc all come part and parcel with Kafka, so making it work properly on Kubernetes and on an underlying dynamic environment can be a challenge.
There are already several approaches to operating Kafka on Kubernetes, however, we did not find them appropriate for use in a highly dynamic environment, nor capable of meeting our customers’ needs. At the same time, there is substantial interest within the Kafka community for a solution which enables Kafka on Kubernetes, both in the open source and closed source space.
- Helm chart
- Yaml files
- Strimzi Kafka Operator
- Confluent operator
Join us as we take a deep dive into some of the details of the most popular pre-existing solutions, as well as our own:
| Banzai Cloud | Krallistic | Strimzi | Confluent | |
|---|---|---|---|---|
| Open source | Apache 2 | Apache 2 | Apache 2 | No |
| Maintained | Yes | No (discontinued) | Yes | N/A |
| Fine grained broker config support | Yes (learn more) | Limited via StatefulSet | Limited via StatefulSet | Limited via StatefulSet |
| Fine grained broker volume support | Yes (learn more) | Limited via StatefulSet | Limited via StatefulSet | Limited via StatefulSet |
| Monitoring | Yes | Yes | Yes | Yes |
| Encryption using SSL | Yes | Yes | Yes | Yes |
| Rolling Update | Yes | No | No | Yes |
| Cluster external accesses | Envoy (single LB) | Nodeport | Nodeport or LB/broker | Yes (N/A) |
| User Management via CRD | Yes | No | Yes | No |
| Topic management via CRD | Yes | No | Yes | No |
| Reacting to Alerts | Yes (Prometheus + Cruise Control | No | No | No |
| Graceful Cluster Scaling (up and down) | Yes (using Cruise Control) | No | No | Yes |
-if you find any of this information inaccurate, please let us know, and we’ll fix it
To StatefulSet or not to StatefulSet: and why it matters 🔗︎
Kafka is a stateful application. The first piece of the puzzle is the Broker, which is a simple server capable of creating/forming a cluster with other Brokers. Every Broker has his own unique configuration which differs slightly from all others - the most relevant of which is the unique broker ID.
All Kafka on Kubernetes operators use StatefulSet to create a Kafka Cluster. Just to quickly recap from the K8s docs:
StatefulSet manages the deployment and scaling of a set of Pods, and provide guarantees about their ordering and uniqueness. Like a Deployment, a StatefulSet manages Pods that are based on an identical container spec. Unlike a Deployment, a StatefulSet maintains sticky identities for each of its Pods. These pods are created from the same spec, but are not interchangeable: each has a persistent identifier that is maintained across any rescheduling.
How does this looks from the perspective of Apache Kafka?
With StatefulSet we get:
- unique Broker IDs generated during Pod startup
- networking between brokers with headless services
- unique Persistent Volumes for Brokers
Using StatefulSet we lose:
- the ability to modify the configuration of unique Brokers
- to remove a specific Broker from a cluster (StatefulSet always removes the most recently created Broker)
- to use multiple, different Persistent Volumes for each Broker
Koperator
uses simple Pods, ConfigMaps, and PersistentVolumeClaims, instead of StatefulSet. Using these resources allows us to build an Operator which is better suited for Apache Kafka.
With the Koperator you can:
- modify the configuration of unique Brokers
- remove specific Brokers from clusters
- use multiple Persistent Volumes for each Broker
Features 🔗︎
To highlight some of the features we needed and were not possible with the operators available, please keep reading (I know, I know, this post is getting long).
Fine Grained Broker Config Support 🔗︎
We needed to be able to react to events in a fine-grained way for each Broker - and not in the limited way StatefulSet does (which, for example, removes the most recently created Brokers). Some of the available solutions try to overcome these deficits by placing scripts inside the container to generate configs at runtime, whereas the Koperator ’s configurations are deterministically placed in specific Configmaps.
Graceful Kafka Cluster Scaling 🔗︎
Here at Banzai Cloud, we know how to operate Kafka at scale (we are contributors and have been operating Kafka on Kubernetes for years now). We believe, however, that LinkedIn has even more experience than we do. To scale Kafka clusters both up and down gracefully, we integrated LinkedIn’s Cruise-Control to do the hard work for us. We already have good defaults (i.e. plugins) that react to events, but we also allow our users to write their own.
External Access via LoadBalancer 🔗︎
The Koperator externalizes access to Kafka using a dynamically (re)configured Envoy proxy. Using Envoy allows us to use a single LoadBalancer, so there’s no need for a LoadBalancer for each Broker.
Communication via SSL 🔗︎
The operator fully automates Kafka’s SSL support. Users must provide and install the right certificate as a Kubernetes Secret, however, the Pipeline platform is capable of automating this process, as well.
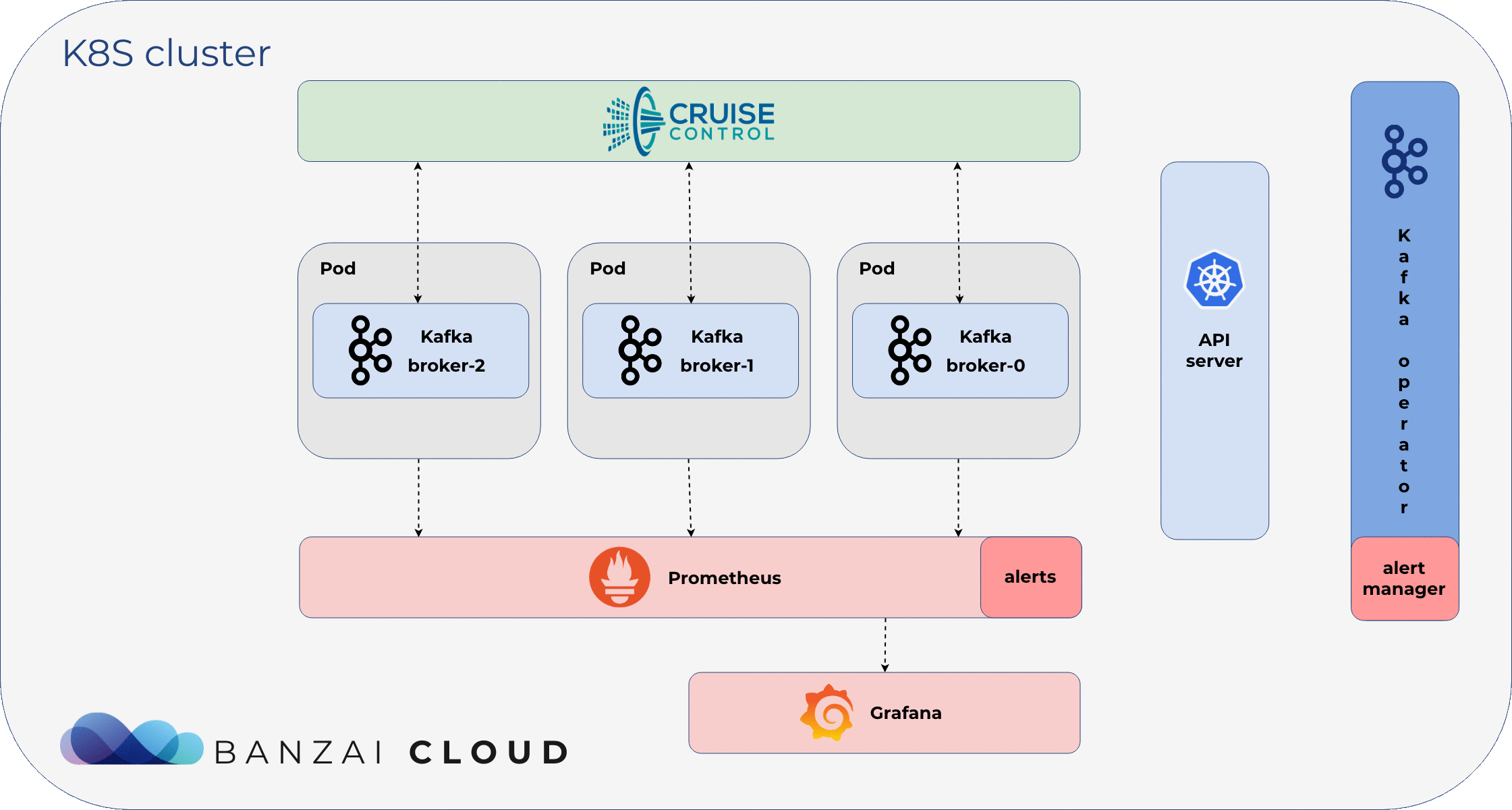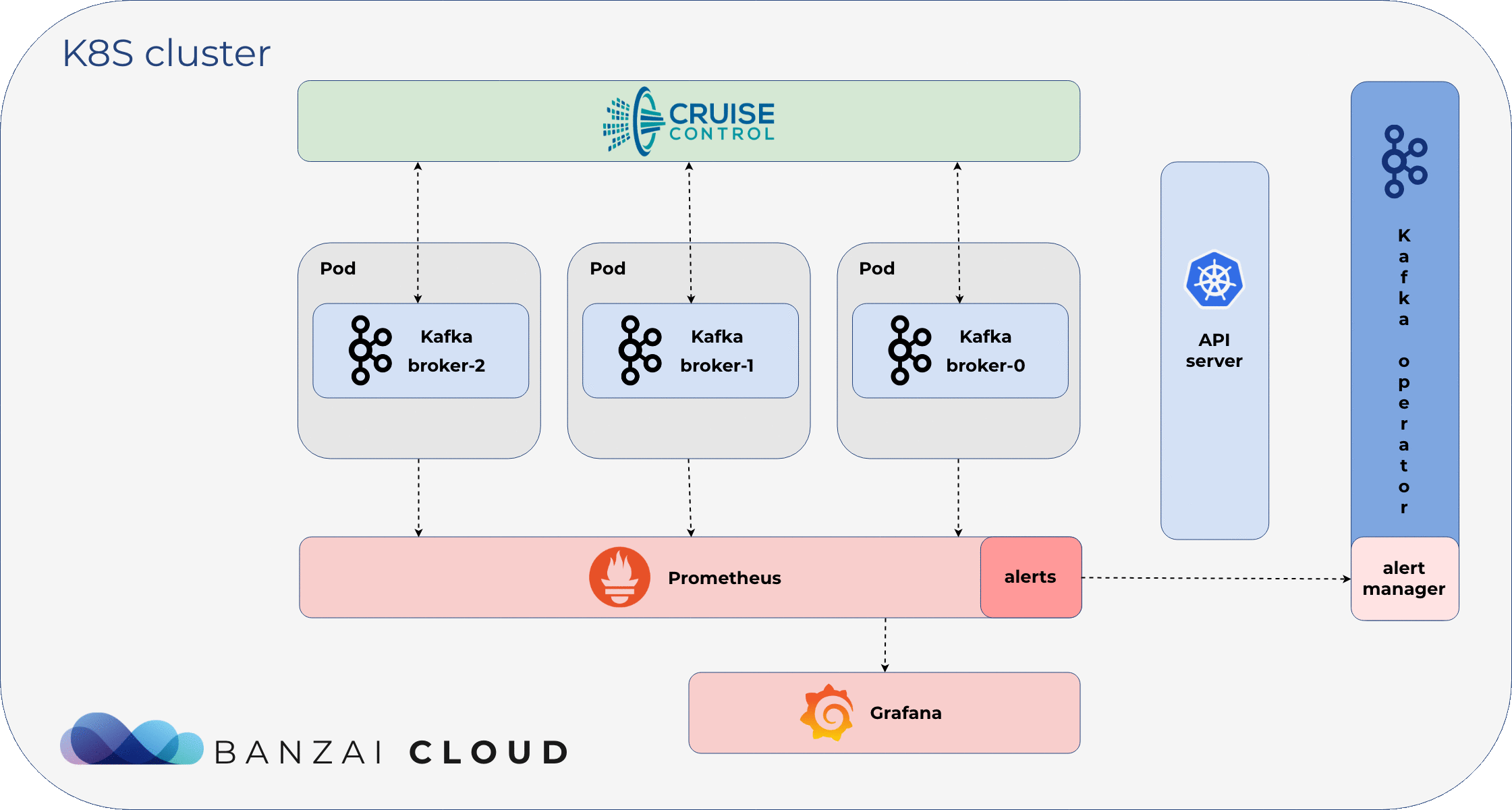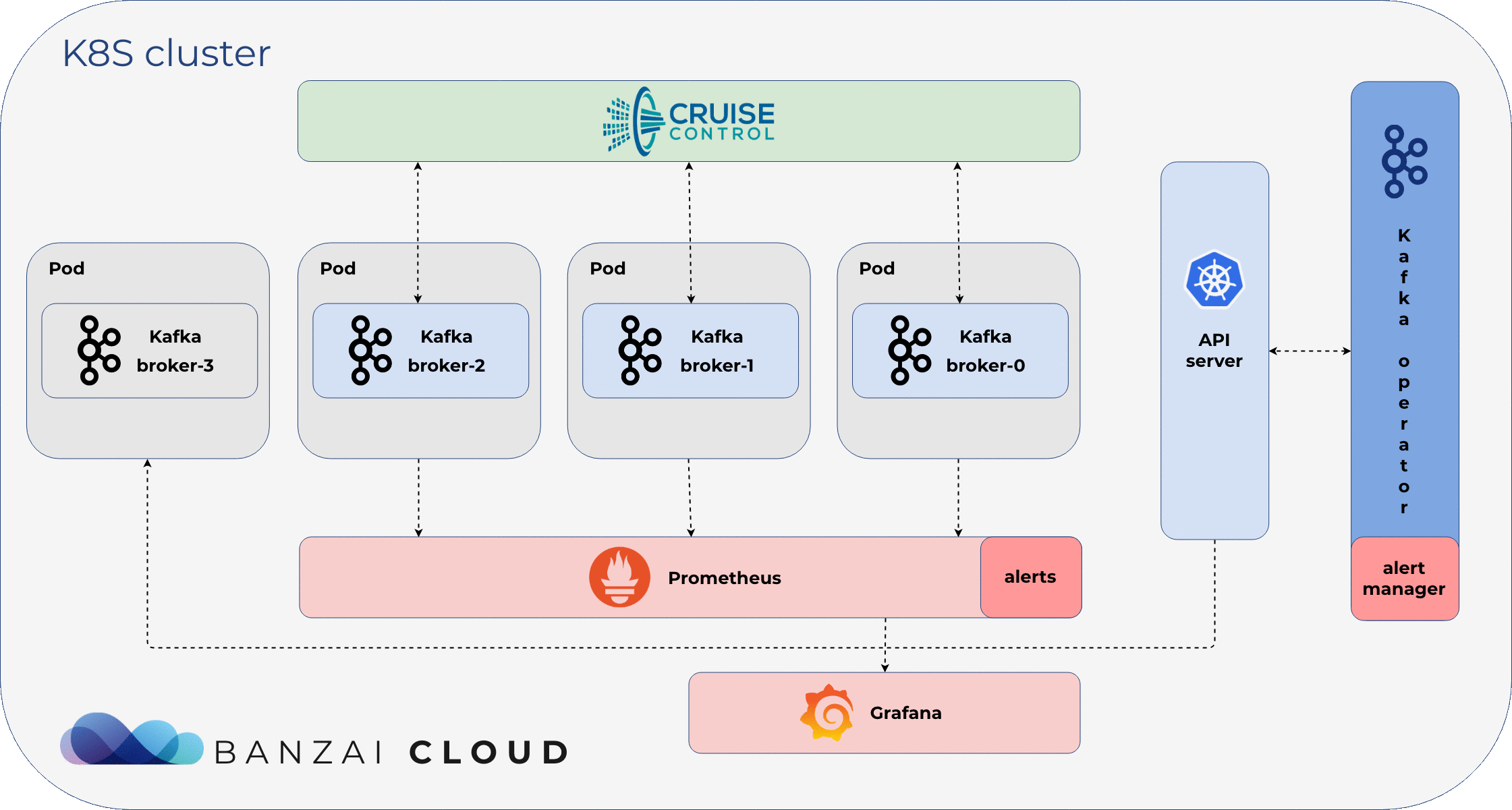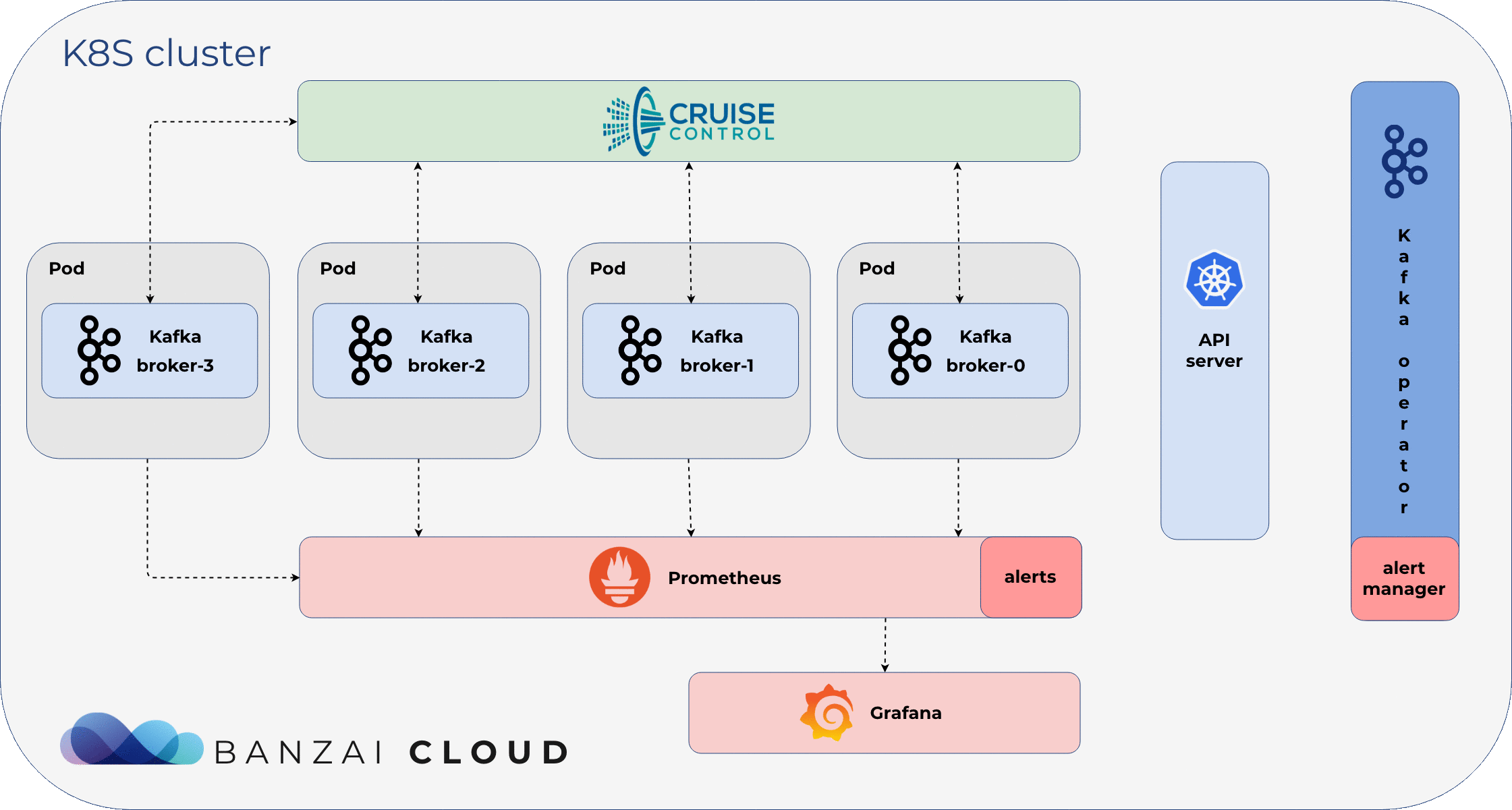
Monitoring via Prometheus 🔗︎
Koperator exposes Cruise-Control and Kafka JMX metrics to Prometheus.
Reacting on Alerts 🔗︎
Koperator acts as a Prometheus Alert Manager. It receives alerts defined in Prometheus, and creates actions based on Prometheus alert annotations.
Currently, there are three default actions (which can be extended):
- upscale cluster (add a new Broker)
- downscale cluster (remove a Broker)
- add additional disk to a Broker
Scenarios 🔗︎
As highlighted in the features section, we removed the reliance on StatefulSet, we dig deep and write bunch of code for the operator to allow scenarios as the following ones (this is by far not a complete list, get in touch if you have a requirement, question or would like to talk about the operator).
Vertical capacity scaling 🔗︎
We’ve encountered many situations in which the horizontal scaling of a cluster is impossible. When only one Broker is throttling and needs more CPU or requires additional disks (because it handles the most partitions), a StatefulSet-based solution is useless, since it does not distinguish between replicas’ specifications. The handling of such a case requires unique Broker configurations. If we need to add a new disk to a unique Broker, with a StatefulSet-based solution, we waste a lot of disk space (and money). Since it can’t add a disk to a specific Broker, the StatefulSet adds one to each replica.
With the Koperator , adding a new disk to any Broker is as easy as changing a CR configuration. Similarly, any Broker-specific configuration can be done on a Broker by Broker basis.
An unhandled error with Broker #1 in a three Broker cluster 🔗︎
In the event of an error with Broker #1, we want to handle it without disrupting the other Brokers. Maybe we would like to temporarily remove this Broker from the cluster, and fix its state, reconciling the node that serves the node, or maybe reconfigure the Broker using a new configuration. Again, when using StatefulSet, we lose the ability to remove specific Brokers from the cluster. StatefulSet only supports a field name replica that determines how many replicas an application should use. If there’s a downscale/removal, this number can be lowered, however, this means that Kubernetes will remove the most recently added Pod (Broker #3) from the cluster - which, in this case, happens to suit our purposes quite well. To remove the #1 Broker from the cluster, we need to lower the number of brokers in the cluster from three to one. This will cause a state in which only one Broker is live, while we kill the brokers that handle traffic; the Koperator supports removing specific brokers without disrupting traffic in the cluster.
Fine grained Broker config support 🔗︎
Apache Kafka is a stateful application, where Brokers create/form a cluster with other Brokers. Every Broker is uniquely configurable (we support heterogenous environments, in which no nodes are the same, act the same or have the same specifications - from the infrastructure up through the Brokers’ Envoy configuration). Kafka has lots of Broker configs, which can be used to fine tune specific brokers, and we did not want to limit these to ALL Brokers in a StatefulSet. We support unique Broker configs.
In each of the three scenarios listed above, we decided to not use StatefulSet in our Koperator , relying instead on Pods, PVCs, and ConfigMaps. We believe StatefulSet is very convenient starting point, as it handles roughly 80% of scenarios but introduces huge limitations when running Kafka on Kubernetes in production.
Monitoring based control 🔗︎
Use of monitoring is essential for any application, and all relevant information about Apache Kafka should be published to a monitoring solution. When using Kubernetes, the de facto solution is Prometheus, which supports configuring alerts based on previously consumed metrics. We wanted to build a standards-based solution (Prometheus and Alert Manager) that could handle and react to alerts automatically, so human operators wouldn’t have to. Koperator supports alert-based Kafka cluster management.
LinkedIn’s Cruise Control 🔗︎
We have a lot of experience in operating both Kafka and Kubernetes at scale. However, we believe that LinkedIn knows how to operate Kafka even better than we do. They built a tool, called Cruise Control, to operate their Kafka infrastructure, and we wanted to build an operator which handled the infrastructure but did not reinvent the wheel insofar as operating Kafka. We didn’t want to redevelop proven concepts, but wanted to create an operator which leveraged our deep Kubernetes expertise (after all, we’ve already built a CNCF certified Kubernetes distribution, PKE and a hybrid cloud container management platform, Pipeline) by handling all Kafka infrastructure related issues in the way we thought best. We believe managing Kafka is a separate issue, for which there already exist some unique tools and solutions that are standard across the industry, so we took LinkedIn’s Cruise Control and integrated it with the operator.
This post has grown pretty long, pretty quickly, so I’ll wrap things up here. Give our operator a try and let us know what you think, and please star the Kafka GitHub repo. Should you need help, or if you have any questions, get in touch with us by joining our #kafka-operator channel on Slack.
About Banzai Cloud 🔗︎
Banzai Cloud changing how private clouds get built to simplify the development, deployment, and scaling of complex applications, bringing the full power of Kubernetes and Cloud Native technologies to developers and enterprises everywhere. #multicloud #hybridcloud #BanzaiCloud, visit banzaicloud.com