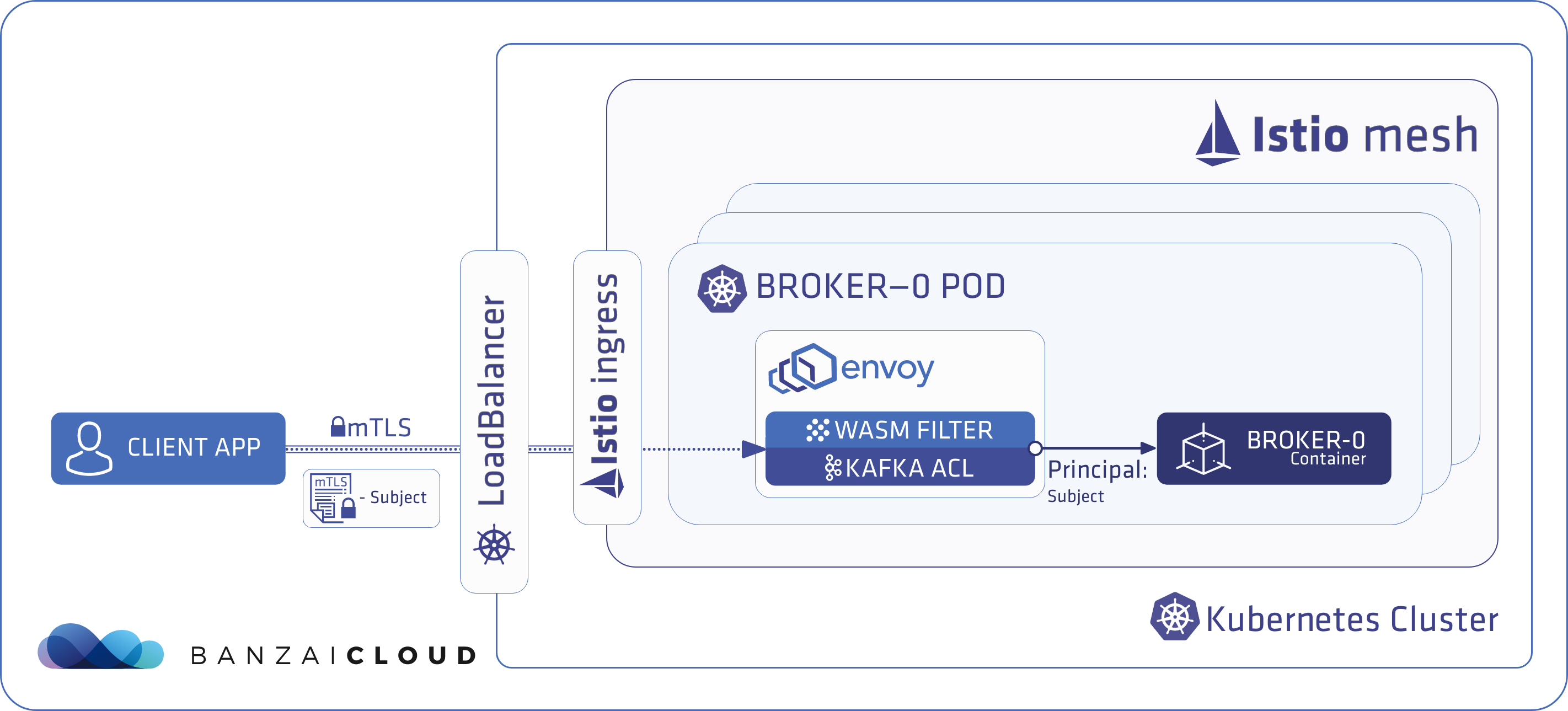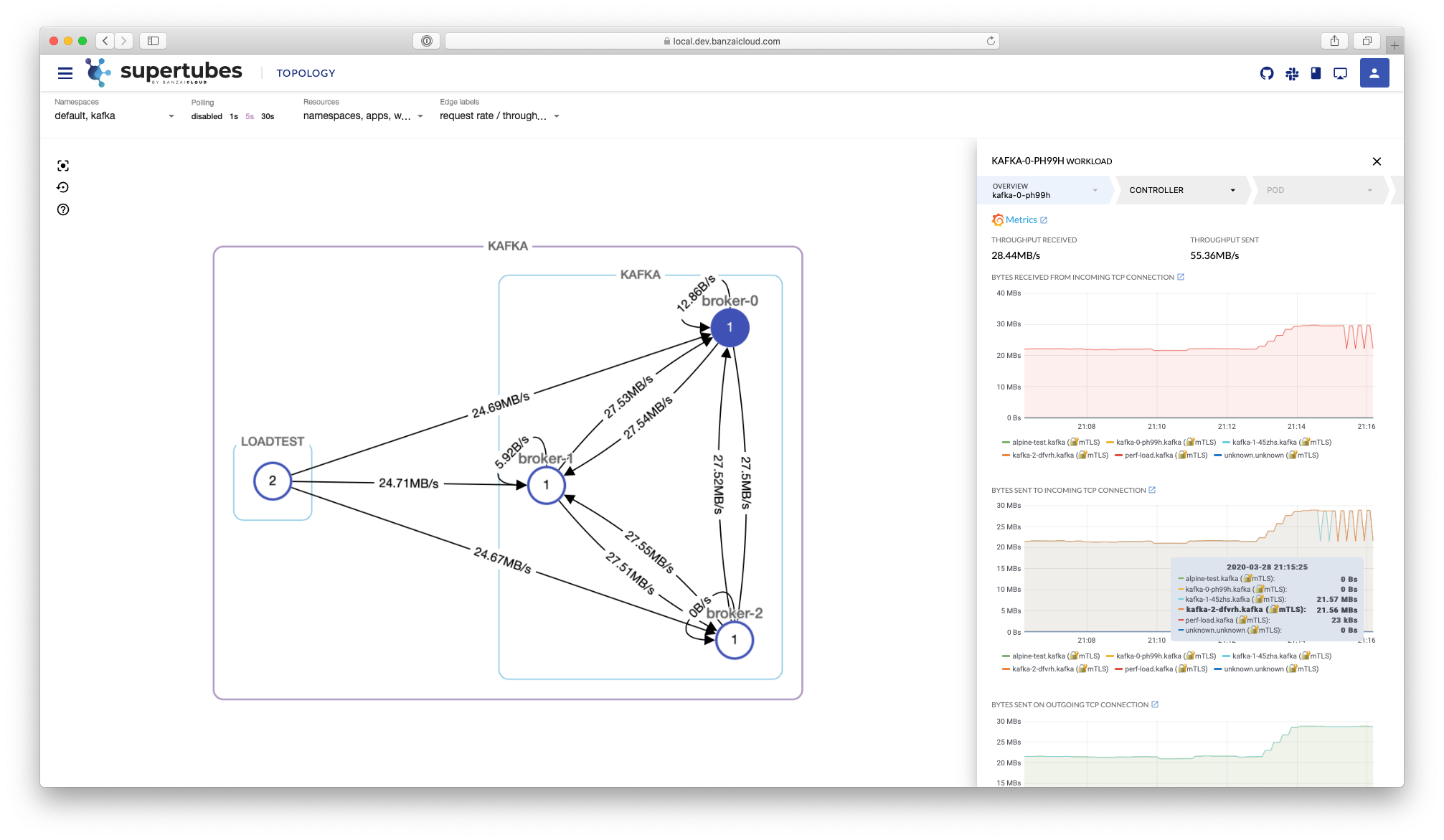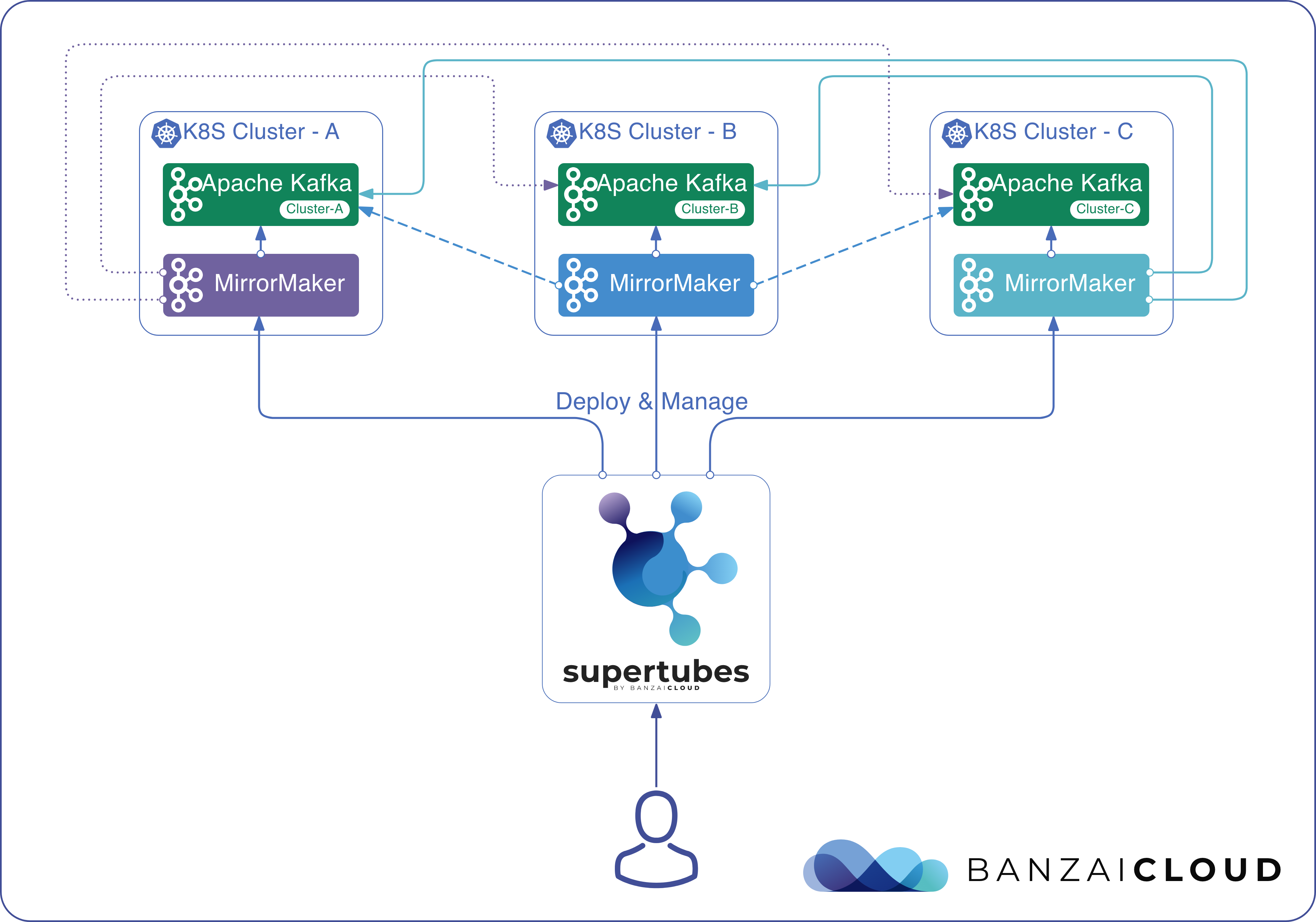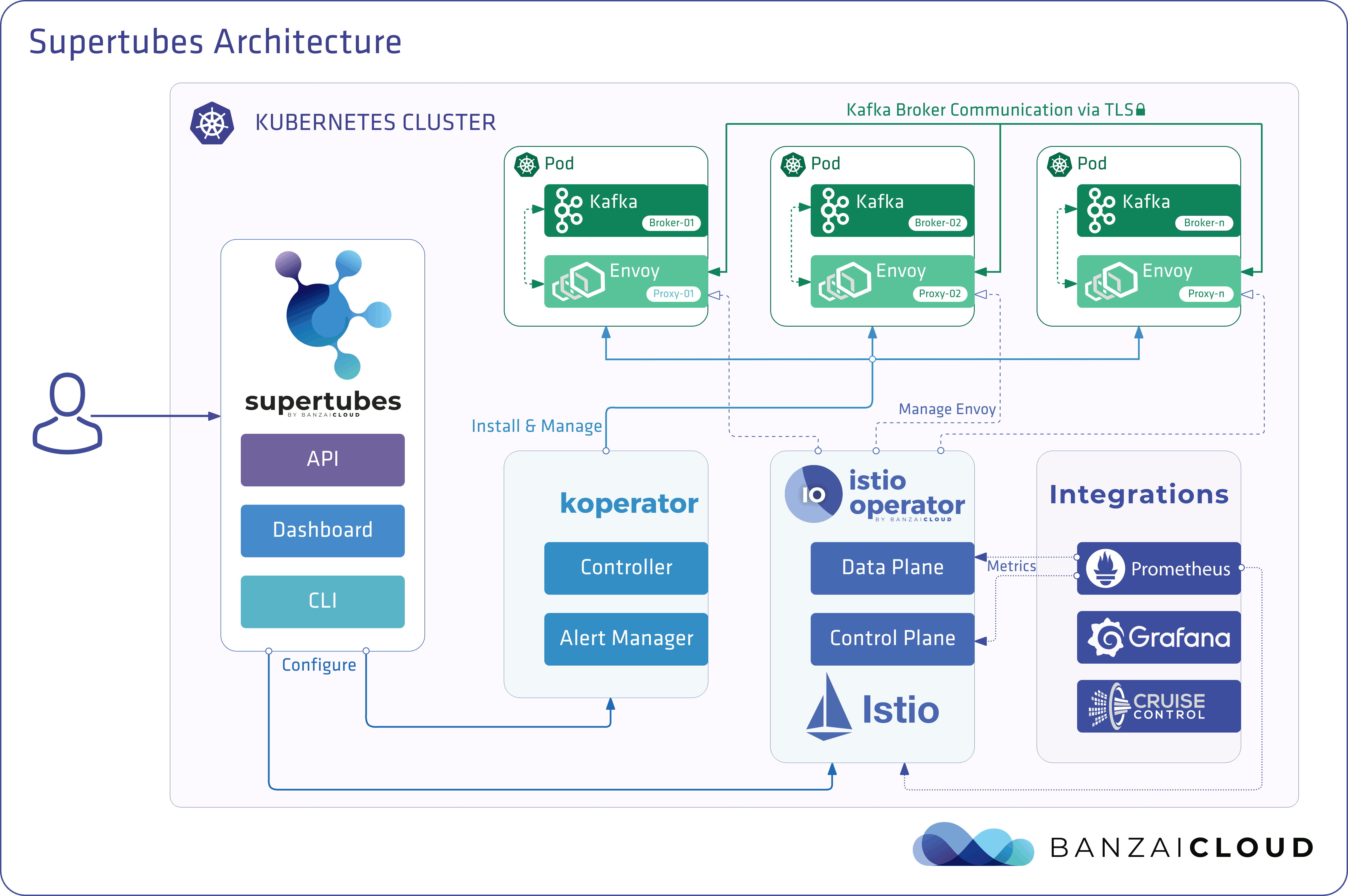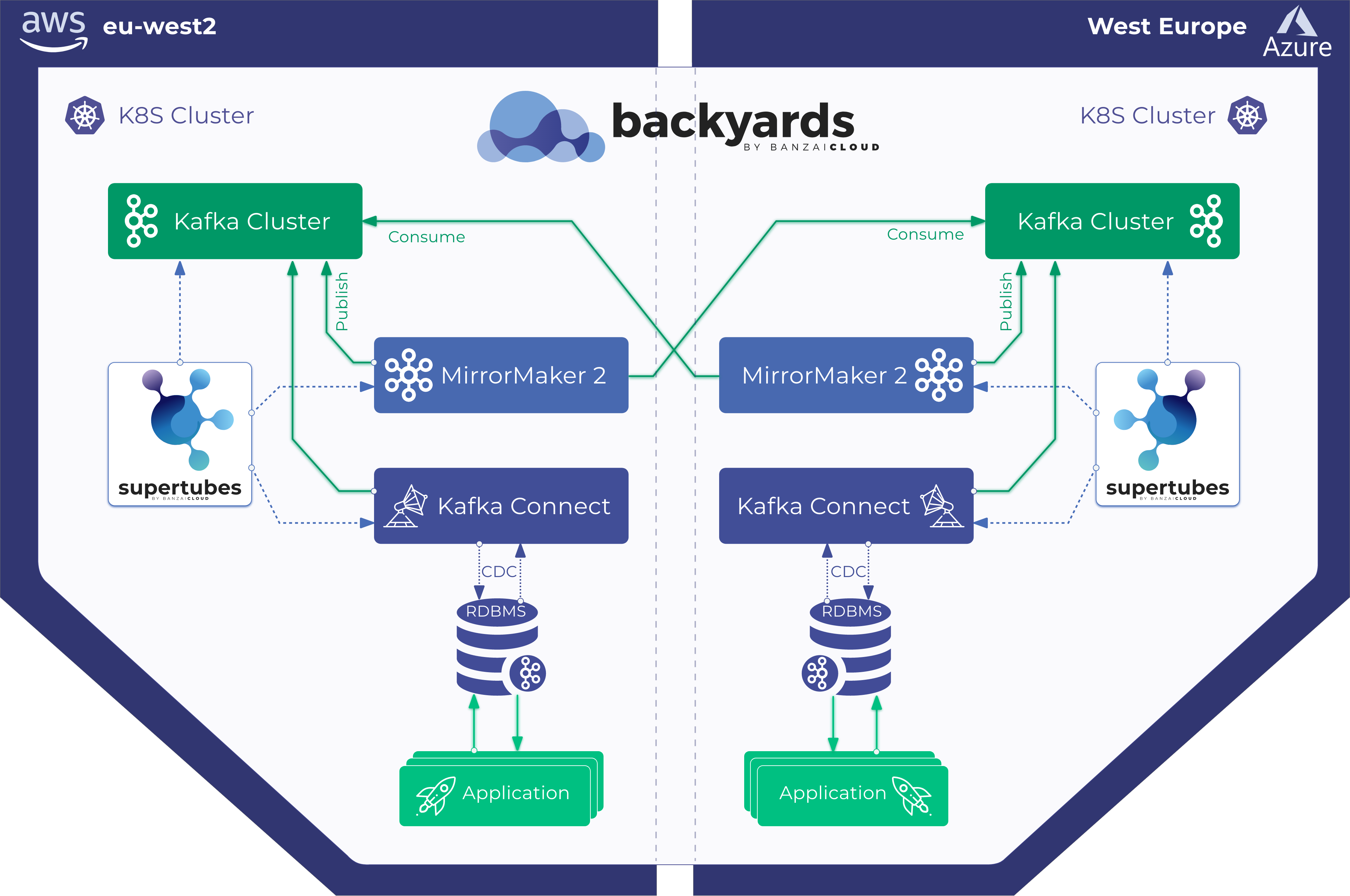
Today, we’re happy to announce the 1.0 release of Supertubes, Banzai Cloud’s tool for setting up and operating production-ready Kafka clusters on Kubernetes through the leveraging of a Cloud-Native technology stack.
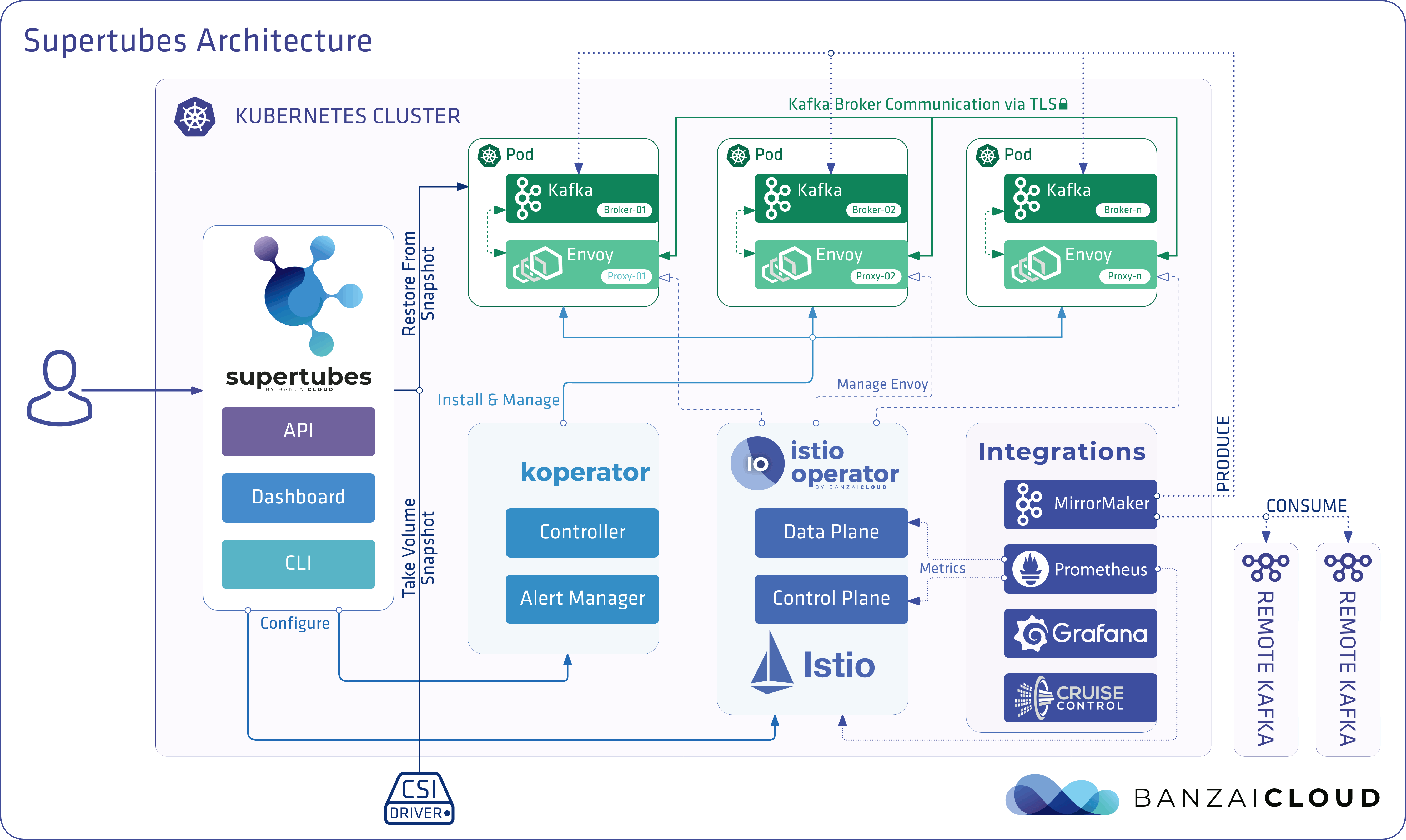
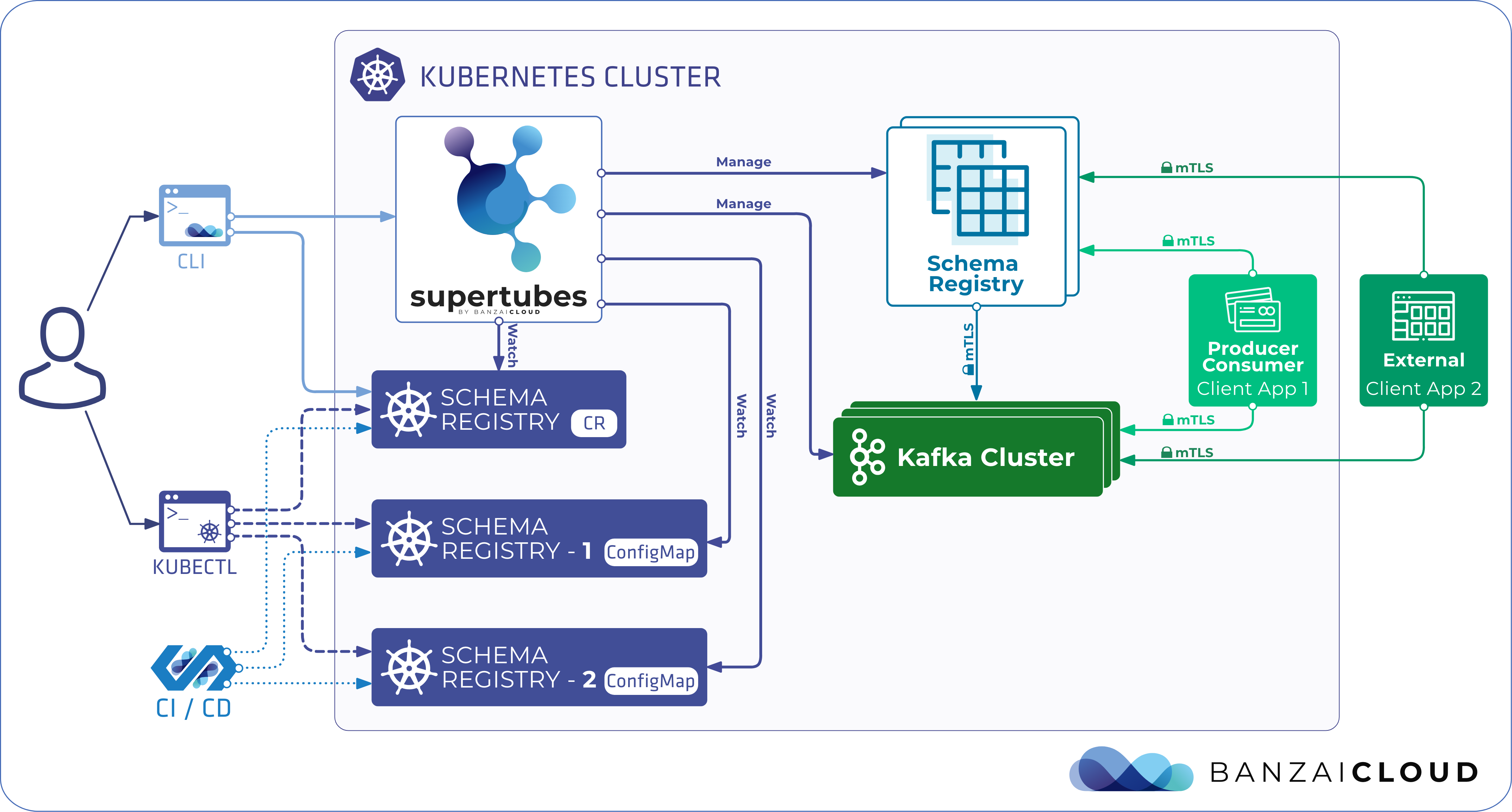
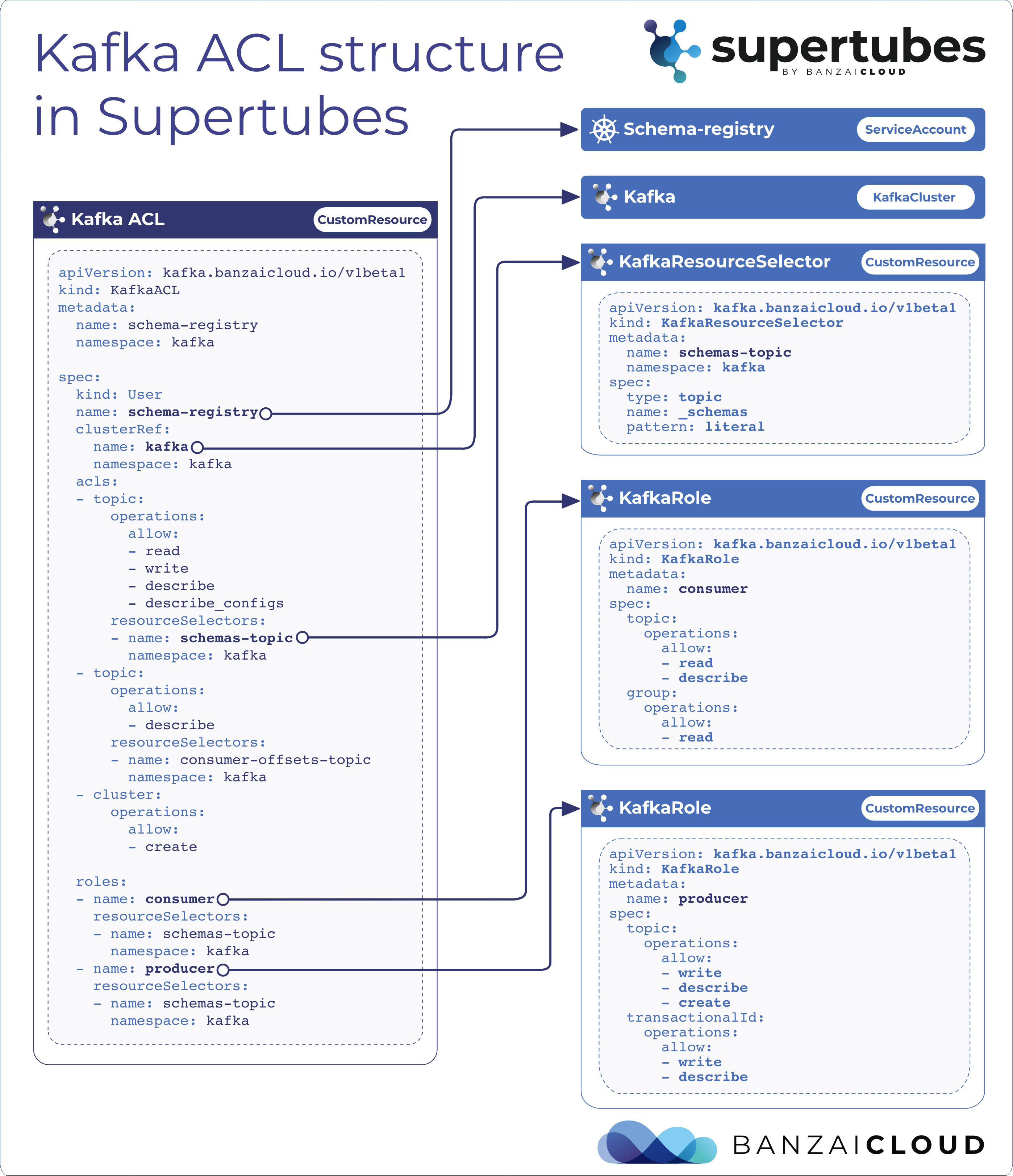
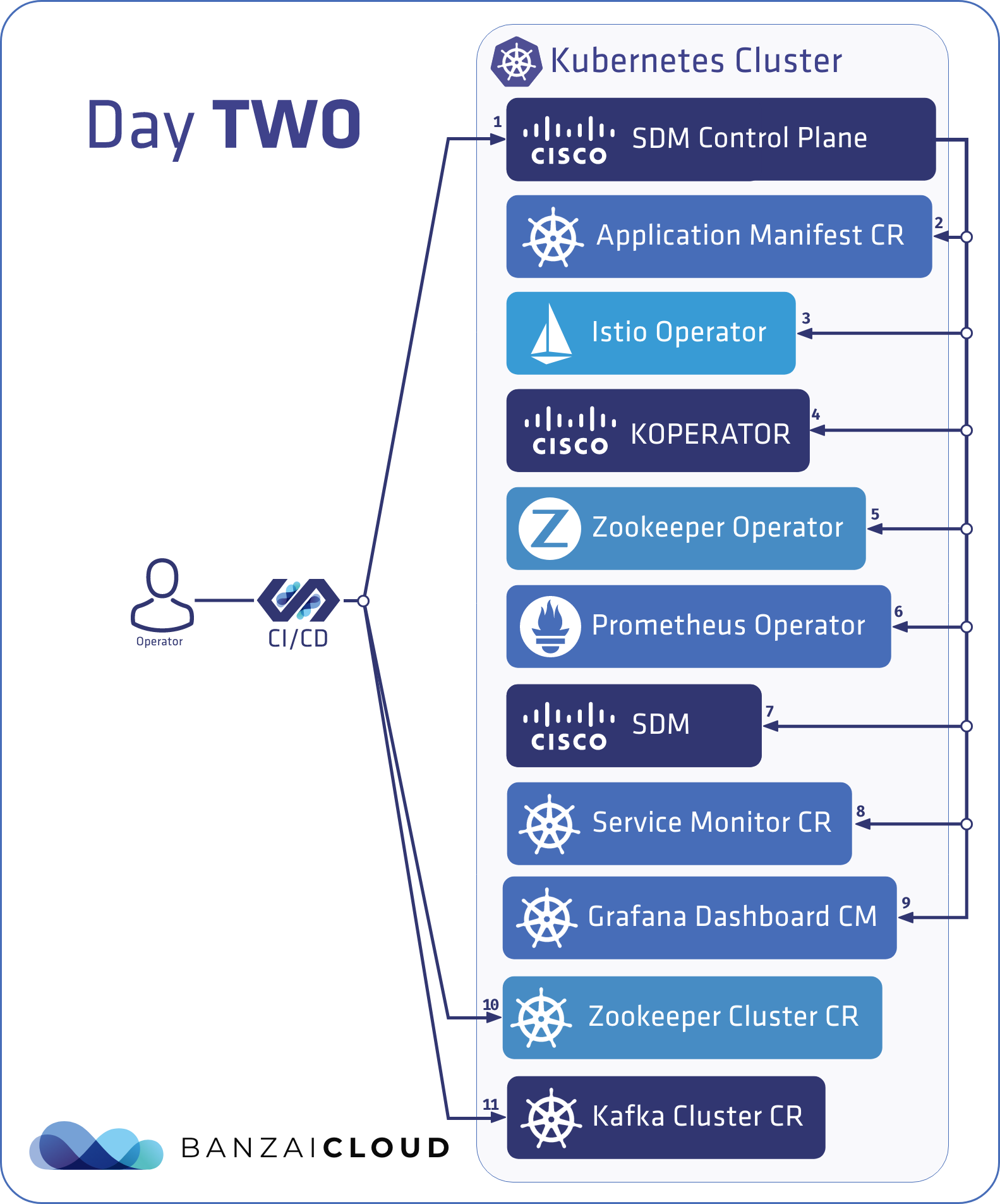
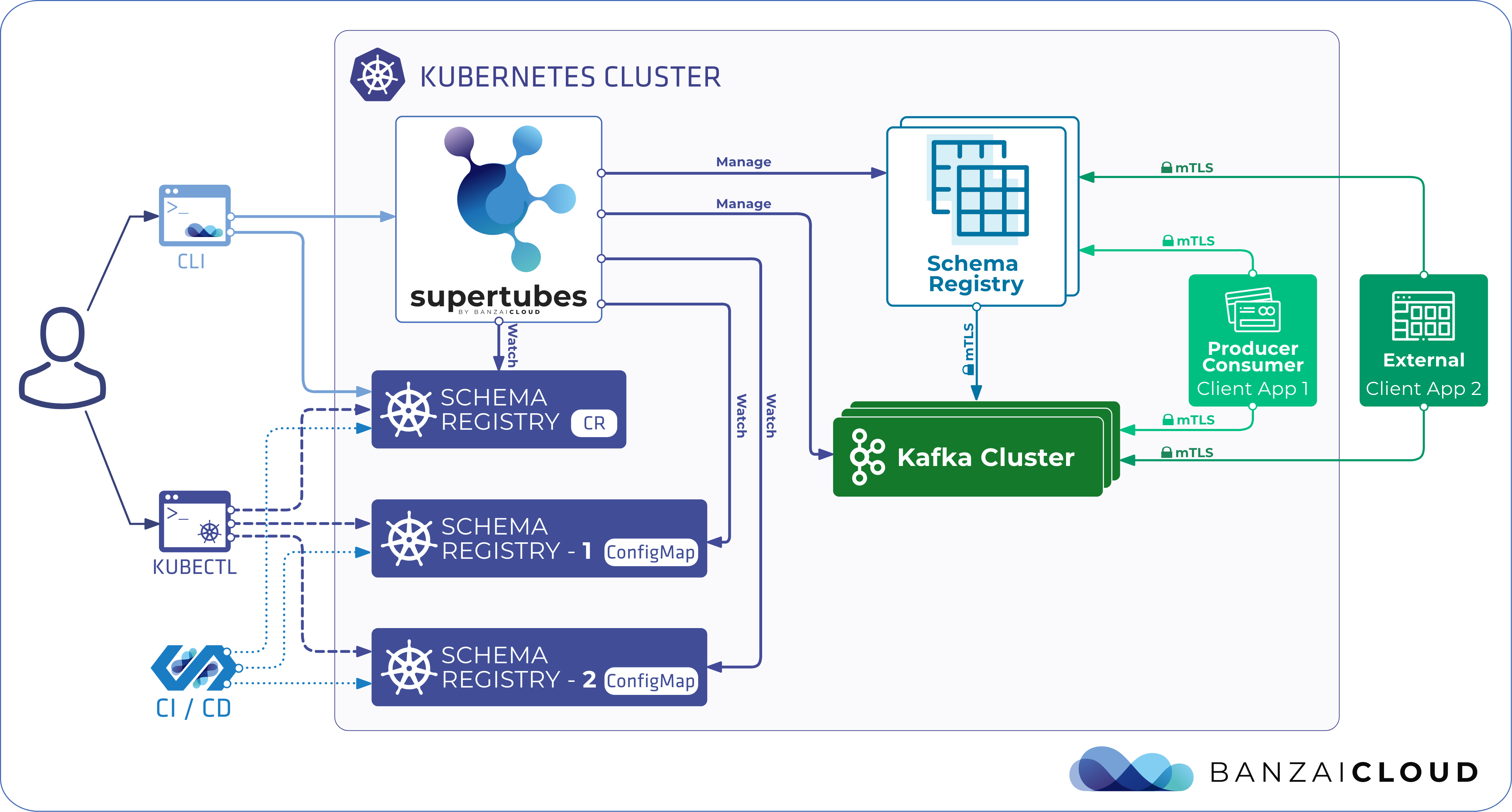
If you are a frequent reader of our blog, or if you’ve been using the open source Koperator , you might already be familiar with Supertubes, our product that delivers Apache Kafka as a service on Kubernetes.