






At Banzai Cloud we are building a managed Cloud Native application and devops platform called Pipeline. Pipeline supercharges the development, deployment and scaling of container-based applications with native support for multi and hybrid-cloud environments.
The Pipeline platform provides support for advanced scheduling that enables enterprises to run their workflows in an efficient way by scheduling workflows to nodes that meet the needs of the workflow (e.g.: CPU, memory, network, IO, spot price, etc).
Pipeline sources infrastructure and price attributes from CloudInfo and automatically labels corresponding nodes with this information. Beside these automatically set labels, users can supply their own labels to be placed onto nodes. With the use of these node labels, in conjunction with node selectors or node affinity/anti-affinity, Kubernetes can be instructed to schedule workflows to the appropriate nodes for optimal resource utilization, stability and performance.
If you’d like to see an example of how node affinity/anti-affinity works, check out our Taints and tolerations, pod and node affinities demystified post. If you are interested in learning how we schedule workloads to spot instances, you should consider reading our Controlling the scheduling of pods on spot instance clusters post.
In this post, we’ll describe how users can provide their own labels for nodes via Pipeline, as well as what goes on behind the scenes during this process.
Users can set node labels at the node pool level; each node in a node pool may have both user-provided labels and the labels automatically set by Pipeline and Kubernetes.
Terminology 🔗︎
A node pool is a subset of node instances within a cluster with the same configuration. However, a cluster can contain multiple node pools, as well as heterogeneous nodes/configurations. The Pipeline platform is capable of managing any number of node pools in a Kubernetes cluster, each with different configurations - e.g. node pool 1 is local SSD, node pool 2 is spot or preemptible-based, node pool 3 contains GPUs - these configurations are turned into actual cloud-specific instances.
tl;dr 🔗︎
-
We apply the concept of node pools across all of the cloud providers we support, in order to create heterogeneous clusters, even to those providers which do not support heterogeneous clusters by default (e.g Azure).
-
We have open-sourced a Nodepool Labels operator to ease labeling multiple Kubernetes nodes within a pool/cluster.
Users are not allowed to specify labels which conflict with the node labels used by Kubernetes and Pipeline. This is enforced by validating user-provided labels against a set of configured reserved label prefixes such as k8s.io/, kubernetes.io/, banzaicloud.io/, etc. We encourage users to follow the convention of omitting prefixes, since those labels are presumed to be private to the user, as stated in the Kubernetes documentation.
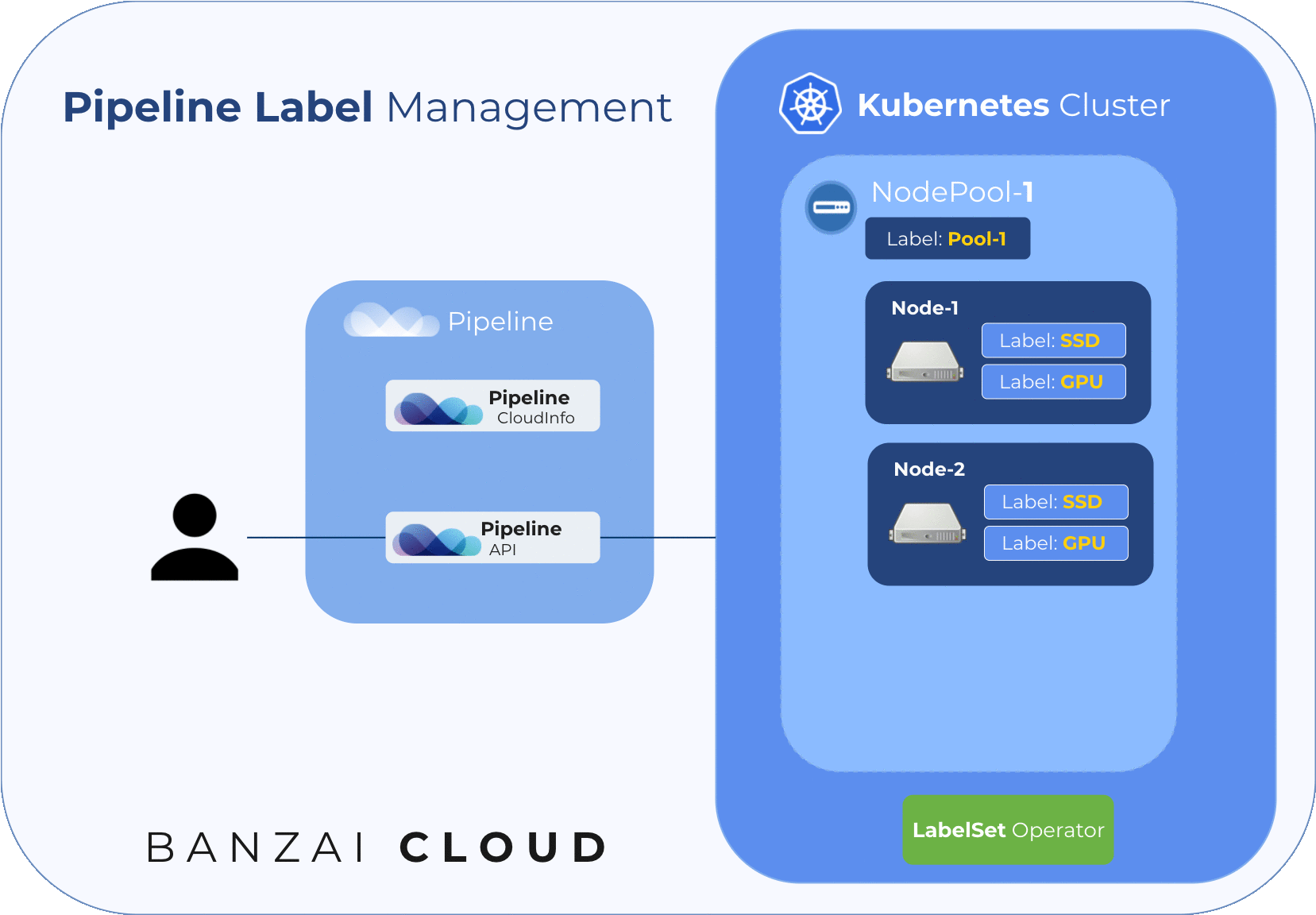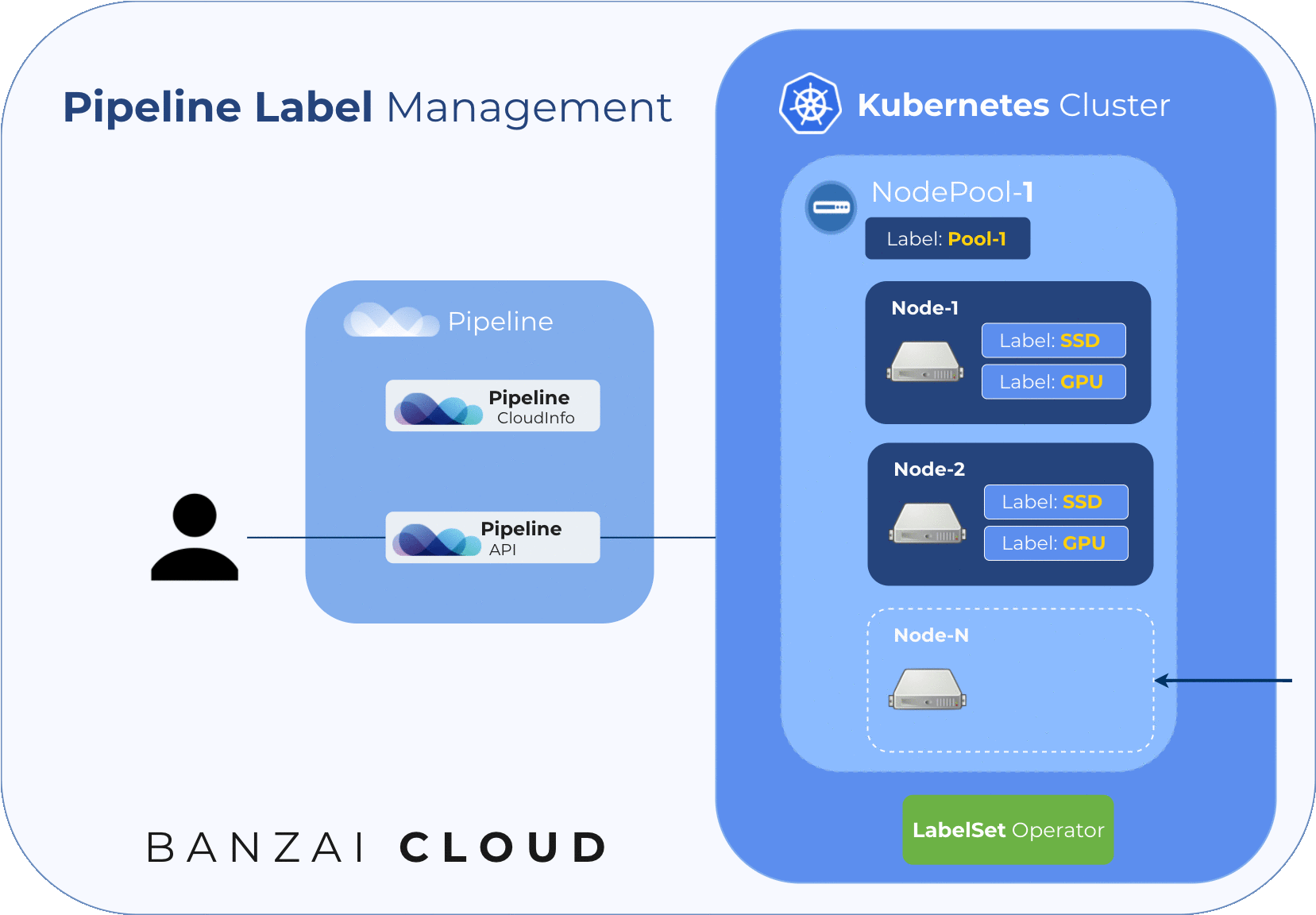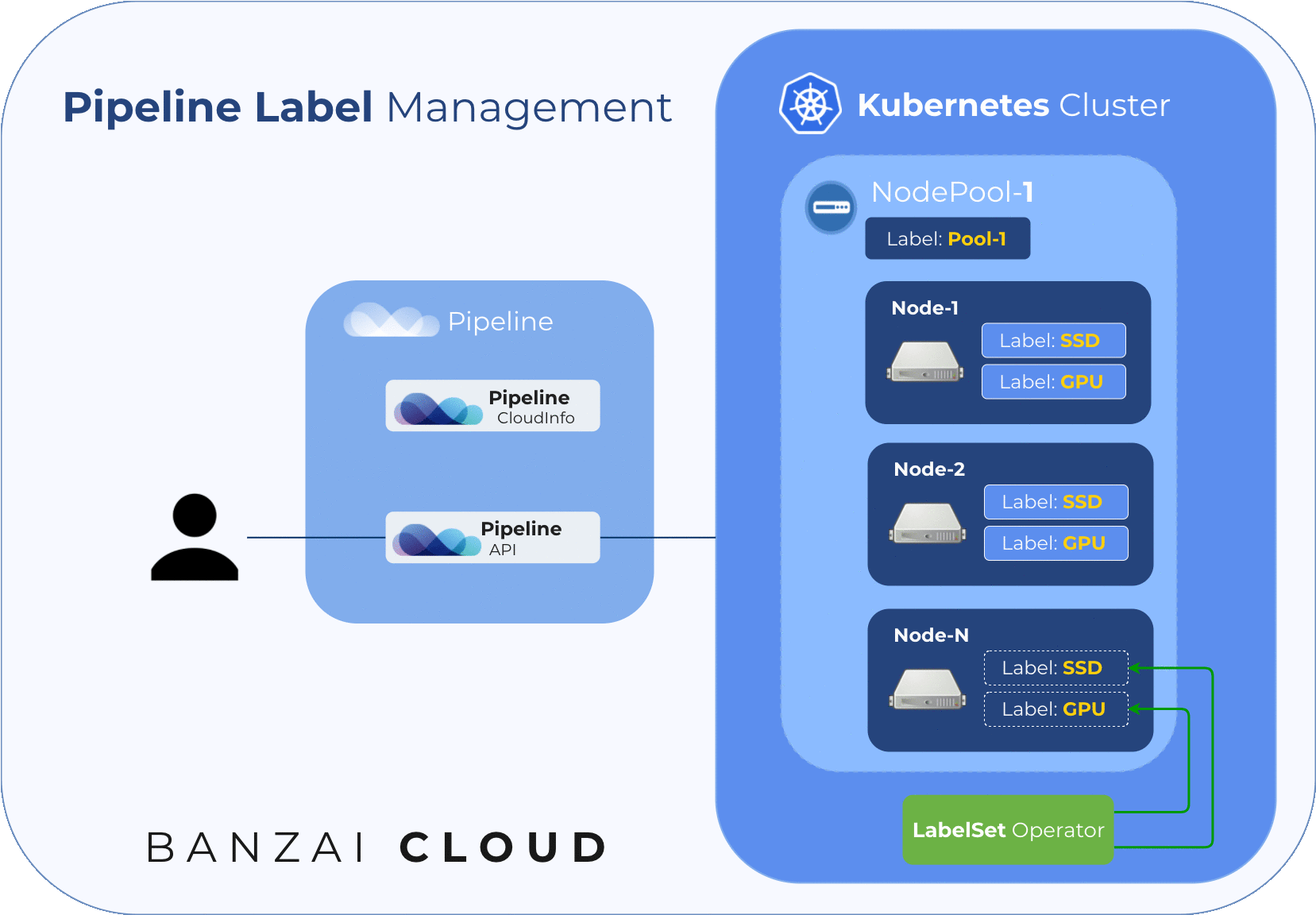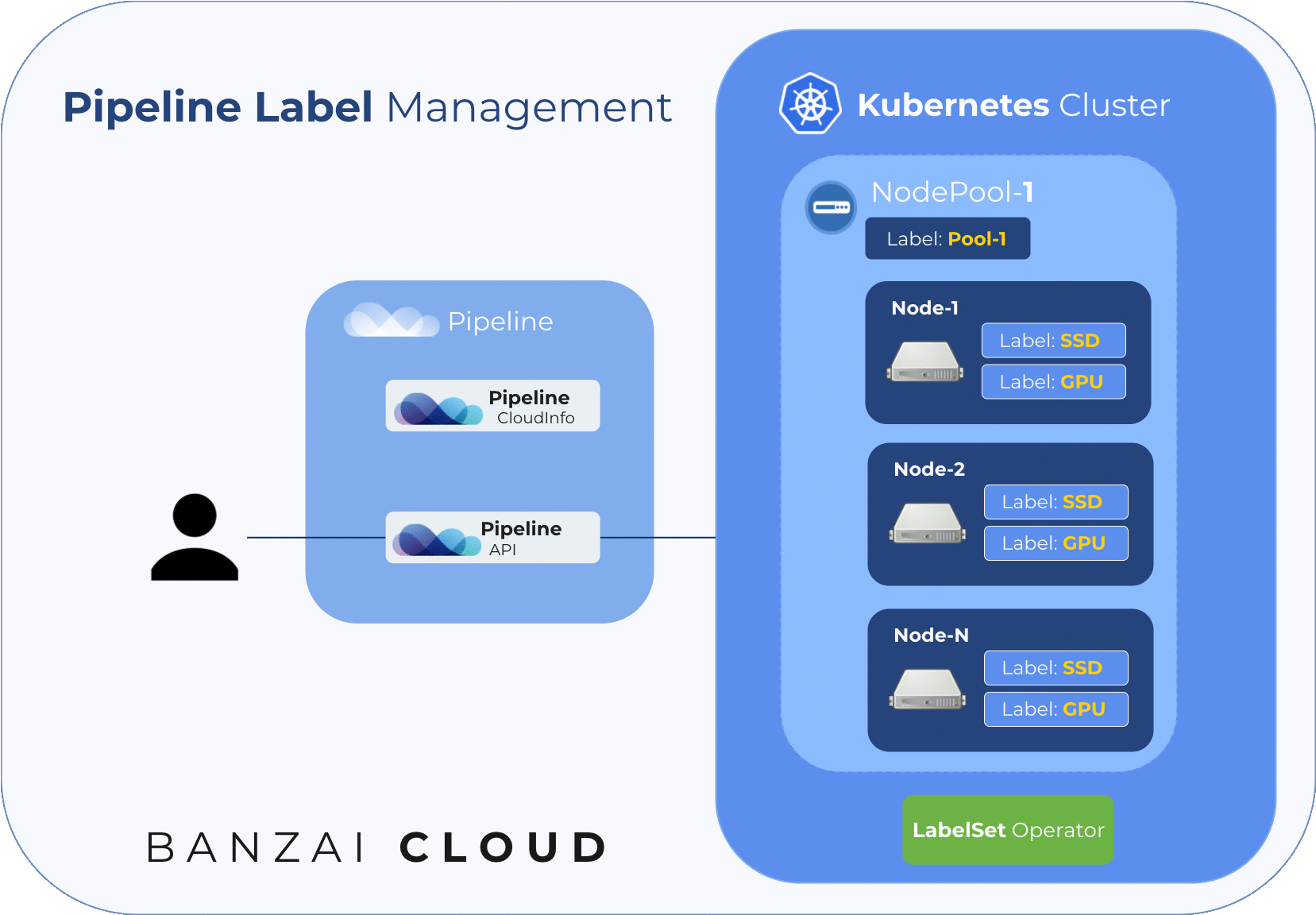
The following diagram illustrates node labelling flow during cluster creation:

Aspects that need to be considered when setting labels on nodes 🔗︎
Labels must be set prior to workloads being scheduled 🔗︎
As of writing, Kubernetes (1.13) supports only two types of node affinity, called requiredDuringSchedulingIgnoredDuringExecution and preferredDuringSchedulingIgnoredDuringExecution. The IgnoredDuringExecution part of these names refers to whether or not labels on a node change at runtime, so that if affinity rules pertaining to the pod are not met the pod will continue to run on the node. This is a problem. Imagine using node anti-affinity to avoid certain pods that are to be scheduled to nodes with specific labels. Such a pod might be scheduled to undesired nodes, if those nodes are not labelled prior to scheduling.
If we have full control over how nodes are provisioned and configured, we can pass labels into the kubelet config. This ensures that labels will already be on the node at time of scheduling. Also, some cloud providers (e.g. Google) allow supplying nodes with labels during cluster creation. Let’s call these pre-configured labels. When this option is not available, we must resort to using Kubernetes to set labels on nodes. In such cases, we have to ensure that no deployment occurs to the cluster until node labels are set.
Unfortunately, we’re not out of the woods yet. There are other potentially serious scenarios worth anticipating.
New nodes join an existing cluster 🔗︎
Pipeline allows users to resize their clusters manually, by adding or removing or resizing node pools. This results in one or more nodes joining a cluster. Let’s distinguish between a few scenarios, here:
- a new node pool is added to the cluster - with pre-configured labels it’s guaranteed that labels are set before any workload is scheduled to newly joined nodes. If only the Kubernetes API can be used to set labels, then there’s a chance a new workload will be deployed and scheduled just before the labels are applied.
- an existing node pool is scaled up - all nodes in a node pool share the same config, thus new nodes will inherit any pre-configured node labels. The new node will only be labelled before a workload can be scheduled to it if the node pool was originally created with pre-configured labels, and they have not been updated during the interim. Most of the time, updating pre-configured labels is not possible (see the below Updating node labels), thus the only option that remains to us is to update our existing node labels using the Kubernetes API, which means that label changes can be propagated to a new node exclusively through a Kubernetes API call.
- a cluster is auto-scaled - The cluster autoscaler handles the scaling up of (the provisioning of new nodes in) a Kubernetes cluster as needed. With respect to labelling, the scaling of nodes that belong to the node pool works fine with pre-configured labels, however, this is not the case when labels are set using Kubernetes.
Updating node labels 🔗︎
In most cases, updating node labels by modifying the kubelet config is not an option, as it is too intrusive and requires kubelet to be restarted. Thus, our only option is to use Kubernetes to update node labels. And now we’re back again at our original problem - the modified user label set is not propagated to the nodes being provisioned by the cluster autoscaler.
Node Pool Label Set Operator 🔗︎
Our solution for how best to label the nodes in a node pool (taking into consideration the issues listed above) is to use an operator that watches node events and catches nodes when they join a cluster. It uses a Custom Resource to keep a list of desired node labels for the nodes in a node pool. There is one such CR per node pool.
Pipeline creates these CRs and the lists of desired labels for each node pool, and updates both whenever a user updates their node pool labels. The operator handles the placing of those labels listed in the CR to all the nodes that belong to the corresponding node pool.
Since the node pool labels described in the CR should only be set to their corresponding nodes, the operator uses an annotation (nodepool.banzaicloud.io/managed-labels) on each node to keep track of their managed labels and will remove those labels which are not also present in the desired state.
apiVersion: labels.banzaicloud.io/v1alpha1
kind: NodePoolLabelSet
metadata:
clusterName: ""
creationTimestamp: 2019-02-12T17:23:49Z
generation: 1
name: pool1
namespace: pipeline-system
resourceVersion: "587"
selfLink: /apis/labels.banzaicloud.io/v1alpha1/namespaces/pipeline-system/nodepoollabelsets/pool1
uid: f5b6168f-2eea-11e9-bef0-42010a9c007d
spec:
labels:
node.banzaicloud.io/NetworkPerfCategory: low
node.banzaicloud.io/cpu: "1"
node.banzaicloud.io/memory: "3.75"
node.banzaicloud.io/ondemand: "false"
nodepool.banzaicloud.io/name: pool1apiVersion: v1
kind: Node
metadata:
annotations:
node.alpha.kubernetes.io/ttl: "0"
nodepool.banzaicloud.io/managed-labels: '["node.banzaicloud.io/cpu","node.banzaicloud.io/memory","node.banzaicloud.io/ondemand","nodepool.banzaicloud.io/name","node.banzaicloud.io/NetworkPerfCategory"]'
volumes.kubernetes.io/controller-managed-attach-detach: "true"
creationTimestamp: 2019-02-12T17:22:49Z
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/fluentd-ds-ready: "true"
beta.kubernetes.io/instance-type: n1-standard-1
beta.kubernetes.io/os: linux
cloud.google.com/gke-nodepool: pool1
cloud.google.com/gke-os-distribution: cos
cloud.google.com/gke-preemptible: "true"
failure-domain.beta.kubernetes.io/region: europe-west3
failure-domain.beta.kubernetes.io/zone: europe-west3-a
kubernetes.io/hostname: gke-stoadergt73-pool1-aeadb72d-mlg7
node.banzaicloud.io/NetworkPerfCategory: low
node.banzaicloud.io/cpu: "1"
node.banzaicloud.io/memory: "3.75"
node.banzaicloud.io/ondemand: "false"
nodepool.banzaicloud.io/name: pool1This solution has one chief limitation; since the concept of a node pool doesn’t exist in Kubernetes, it requires a label to be present on the node that can be used for identifying which node pool the node belongs to. Pipeline tracks what node pool a node belongs to via the node.banzaicloud.io/nodepool: <node pool name> node label. The operator relies on this label to identify the nodes of a pool. If the node.banzaicloud.io/nodepool label is not available then it falls back on cloud-specific node labels to identify the correct node pool:
- AKS:
agent: <node pool name> - GKE:
cloud.google.com/gke-nodepool: <node pool name>
If Pipeline cannot set this label as a pre-configured label, or if the cloud provider doesn’t provide any other means by which to identify what node pool a node belongs to, in certain edgecases, a workflow will be scheduled to nodes before nodes are linked to node pools.
The following diagram illustrates node labelling flow during cluster creation:
As mentioned previously, Pipeline autoscales clusters and deployments based on multiple metrics, thus the size of a nodepool can increase or decrease during the lifecycle of a cluster.
The following diagram illustrates node labelling flow while upscaling an existing node pool:
Conclusion 🔗︎
We can conclude that while it’s convenient to use the high-level APIs provided by cloud providers for Managed Kubernetes, they come with some considerable limitations, and may not allow for full control over a cluster. This was one of the motivations behind our decision to begin work on our own Kubernetes distribution. We are through our CNCF certifications, so stay tuned for an offical release.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.







