






Note: The Spotguides feature mentioned in this post is outdated and not available anymore. In case you are interested in a similar feature, contact us for details.
If you’re a Node.js developer, it’s very likely that you are building microservices and have already come across Kubernetes. Kubernetes is a solid foundation for scalable container deployments but is also infamous for it’s steep learning curve. This post will explain how to containerize your Node.js applications and what it will take to make them production-ready on Kubernetes. While this post can be used as a tutorial for DIY jobs, we have also automated this entire process, allowing developers to kickstart their code to production experience with a few clicks.
Application components 🔗︎
Throughout this post, we’ll be using our Node.js with MongoDB Spotguide for reference. In one of our previous posts, we introduced the concept of Spotguides, our managed CI/CD-driven cloud-native application templates. To make the adoption of Kubernetes as easy as possible for application developers, we have created ready to use, managed solutions for a variety of application stacks, including Node.js.
Note: The Pipeline CI/CD module mentioned in this post is outdated and not available anymore. You can integrate Pipeline to your CI/CD solution using the Pipeline API. Contact us for details.
Spotguides are one of the key features of the Banzai Cloud Pipeline platform. Even better, they’re free to use!
git clone git@github.com:spotguides/nodejs-mongodb.git
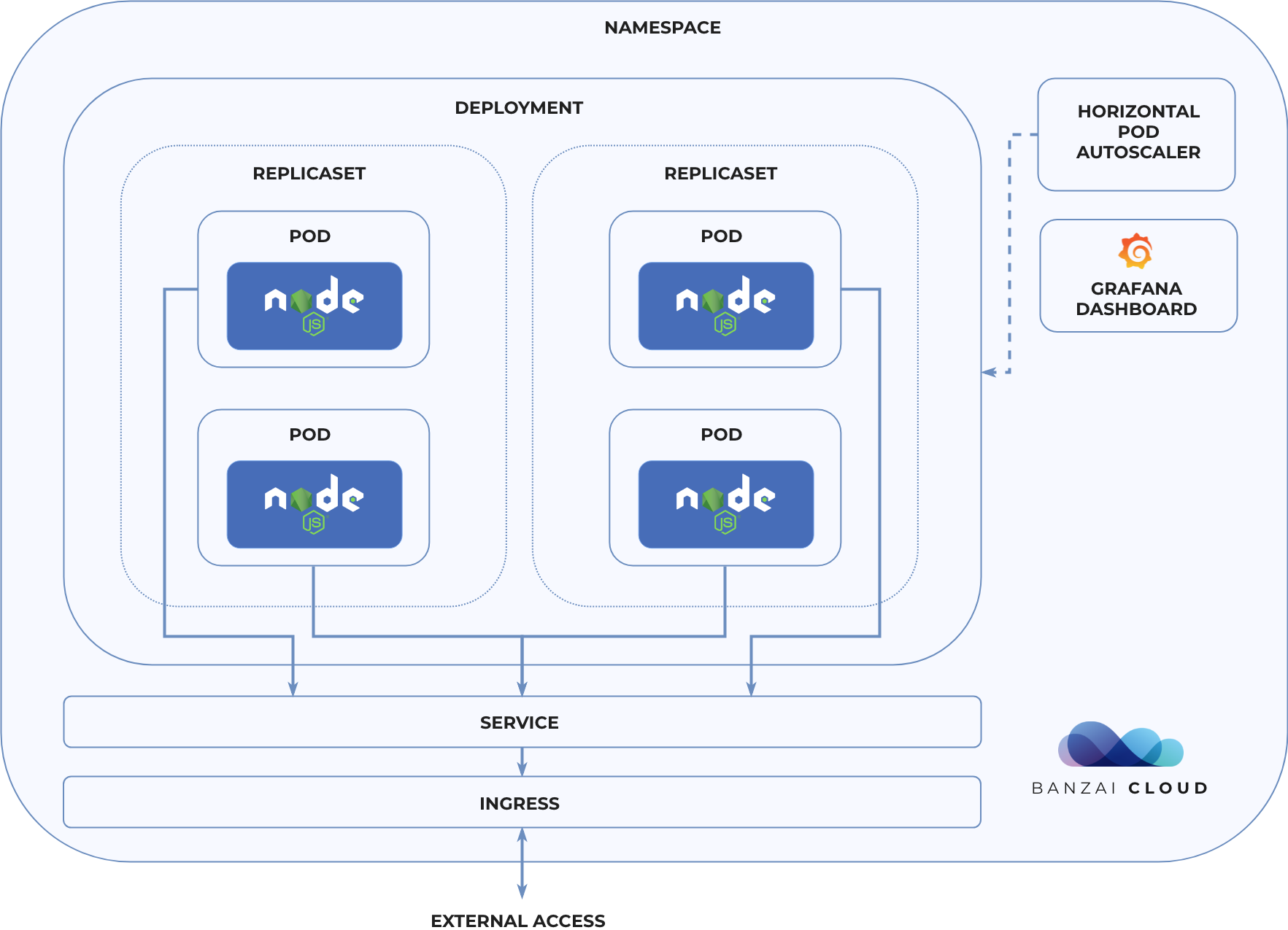
Production requirements 🔗︎
In order to utilize all the features of Kubernetes, we need to prepare our application for a “containerized world”. So let’s take a look at what we need to run a Node.js application properly on Kubernetes.
- We need to be stateless: the application can only store its state externally, in places like databases, queues, and memory caches. This ensures our ability to run multiple instances at the same time and scale them out horizontally, as needed.
- We need to get our config from environmental variables: environment-dependent variables (like credentials) should not be hardcoded.
- We need to expose its statuses: when healthy, the application should be ready to accept requests or handle other kinds of loads. Kubernetes is capable of detecting failures automatically and of trying to fix them (by restarting failing pods, for example).
- We should be able to shutdown gracefully when there’s a termination signal: to archieve zero-downtime, the application has to finish all its in-progress work, like responding to in-flight requests, before exiting.
- We need to handle errors gracefully: perfect software doesn’t exist, so we need to make sure that any errors are caught, and log them before termination.
- We need a structured logger: it’s easier to query and process structured data.
- We need to expose application metrics: this will help us monitor the state of the application while it’s running.
To make these requirements easier to implement, we published an npm @banzaicloud/service-tools library, which contains everything you need to make your app Kubernetes ready.
Now let’s begin to explore the steps involved in setting up a DIY Node.js on Kubernetes - and maybe then you’ll understand the heavy lifting the Node.js Spotguide does for us.
Containerizing a Node.js application 🔗︎
Our first step is to specify our build instructions in a Dockerfile.
By leveraging multi-stage builds, we can make it so our final image is smaller, and that private npm packages are installed without leaking NPM_TOKEN.
In the first stage, we’ll install all the build tools needed for various npm dependencies.
In the second stage, we’ll include the source code and copy the node_modules folder from the first stage.
ARG NODE_VERSION=11
###
# 1. Dependencies
###
FROM node:${NODE_VERSION}-slim as dependencies
WORKDIR /home/node/
RUN apt-get update
RUN apt-get install -y build-essential python
RUN npm install --global npm node-gyp
COPY package.json *package-lock.json *.npmrc ./
ARG NODE_ENV=production
ENV NODE_ENV ${NODE_ENV}
RUN npm ci
###
# 2. Application
###
FROM node:${NODE_VERSION}-slim
WORKDIR /home/node/
COPY --from=dependencies /home/node/node_modules node_modules
COPY . .
ENV PATH="$PATH:/home/node/node_modules/.bin"
ENV NODE_ENV production
ENV PORT 3000
EXPOSE 3000
CMD ["node", "."]
We have a source file copy step COPY . ., therefore it’s important to have a .dockerignore file in place. The file syntax, here, is similar to .gitignore, and will help us exclude certain files and directories from our build context (like the .git history folder or any files that might contain sensitive information).
# exclude dot-files (.env, .git, ...)
.*
# logs
logs
*.log
# dependency directory
node_modules
Finally, we can go ahead and execute the build command:
docker build . -t spotguide-nodejs-mongodb
Application lifecycle 🔗︎
So far so good! We’ve managed to build our application image, but we’re not done yet. In this section we’ll discuss the steps involved in getting our containerized application to run locally, as well as how to set up a CI/CD flow to automate the deployment process from commit to Kubernetes.
Develop locally 🔗︎
First, let’s try to run a container using the image built in the previous section the naive way:
docker run -it --rm spotguide-nodejs-mongodb
It’s failed to start. If we take a look at the logs, we’ll see the following error message:
failed to connect to MongoDB
This error makes sense: our application has MongoDB as a dependency, so we need to make sure that it’s available to our running container. There are multiple ways we can run bother MongoDB, and our application at the same time:
Using Docker Compose, we can define and run multi-container Docker applications.
# docker-compose.yaml
version: "3.7"
services:
app:
build:
context: .
args:
NODE_ENV: development
command: ["nodemon", "."]
depends_on:
- db
environment:
- NODE_ENV=development
- PORT=3000
- MONGODB_HOST=db
- MONGODB_USERNAME=username
- MONGODB_PASSWORD=password
- MONGODB_DATABASE=spotguide-nodejs-mongodb
- MONGODB_AUTH_SOURCE=admin
ports:
- 3000:3000
volumes:
- type: bind
source: ./web
target: /home/node/web
db:
image: mongo
restart: always
ports:
- 27017:27017
healthcheck:
test: ["CMD", "mongo", "--eval", "{ ping: 1 }"]
interval: 10s
timeout: 10s
retries: 5
start_period: 30s
environment:
- MONGO_INITDB_ROOT_USERNAME=username
- MONGO_INITDB_ROOT_PASSWORD=password
- MONGO_INITDB_DATABASE=spotguide-nodejs-mongodb
We’ve defined two services, one is a MongoDB database and the other is our Node.js application.
As you might have noticed, the process is started with a nodemon command instead of node. It is a utility that monitors changes in the source and automatically restarts the process when a file changes. The source code is mounted to the container, so it is invoked whenever we make a change on our local file system.
Our other option is to use a local Kubernetes cluster. It’s always better to use an environment that is as similar to production as possible. There are many ways to run a Kubernetes cluster locally. Some of the most common methods are by using Minikube, Docker for Desktop or kind.
Once we have a local cluster running, we can use skaffold to deploy our application.
Skaffold is a command line tool that facilitates continuous development for Kubernetes applications. You can iterate on your application source code locally then deploy to local or remote Kubernetes clusters. Skaffold handles the workflow for building, pushing and deploying your application.
Let’s have a look at the skaffold definition:
# .banzaicloud/skaffold.yaml
apiVersion: skaffold/v1beta5
kind: Config
build:
# tagPolicy determines how skaffold is going to tag your images.
# The policy can be `gitCommit`, `sha256` or `envTemplate`.
tagPolicy:
# Tag the image with the git commit of your current repository.
sha256: {}
# artifacts is a list of the actual images you'll be building
# you can include as many as you want here.
artifacts:
# The name of the image to be built.
- image: spotguide-nodejs-mongodb
# The path to your dockerfile context.
context: ../
# This deploy section has all the information you need to deploy. Along with build:
# it is a required section.
deploy:
helm:
# helm releases to deploy.
releases:
- name: spotguide-nodejs-mongodb
namespace: default
chartPath: charts/spotguide-nodejs-mongodb
valuesFiles:
- helm-skaffold-values.yaml
values:
deployment.image: spotguide-nodejs-mongodb
wait: true
imageStrategy:
helm: {}
When we execute skaffold, it will build the Docker image and install all the components of our application using Helm.
# verify the Kubernetes context
$ kubectl config get-contexts
# expected output
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* docker-for-desktop docker-for-desktop-cluster docker-for-desktop
# build the Docker image and deploy via helm
$ cd .banzaicloud
$ skaffold config set --global local-cluster true
$ skaffold run
Helm is a very popular package manager for Kubernetes. A Helm Chart is similar to an npm package, but for Kubernetes applications. We have one Chart for the Node.js app and another one for MongoDB. A Chart can hold several template files, which are rendered with their values passed in at install time. In the application’s Helm chart we have templates for each of the Kubernetes resources we’ve previously discussed:
CI/CD 🔗︎
We’ve covered how to work with containers locally. Now it’s time to automate the deployment process.
Our goal is to set up a CI/CD flow with the following steps:
- Create a Kubernetes cluster (or ensure that a suitable one already exists)*
- Run linters and tests
- Build and push docker images to Docker Hub
- Package our application
- Install secrets to the cluster*
- Deploy our application using Helm
* steps specific to Pipeline
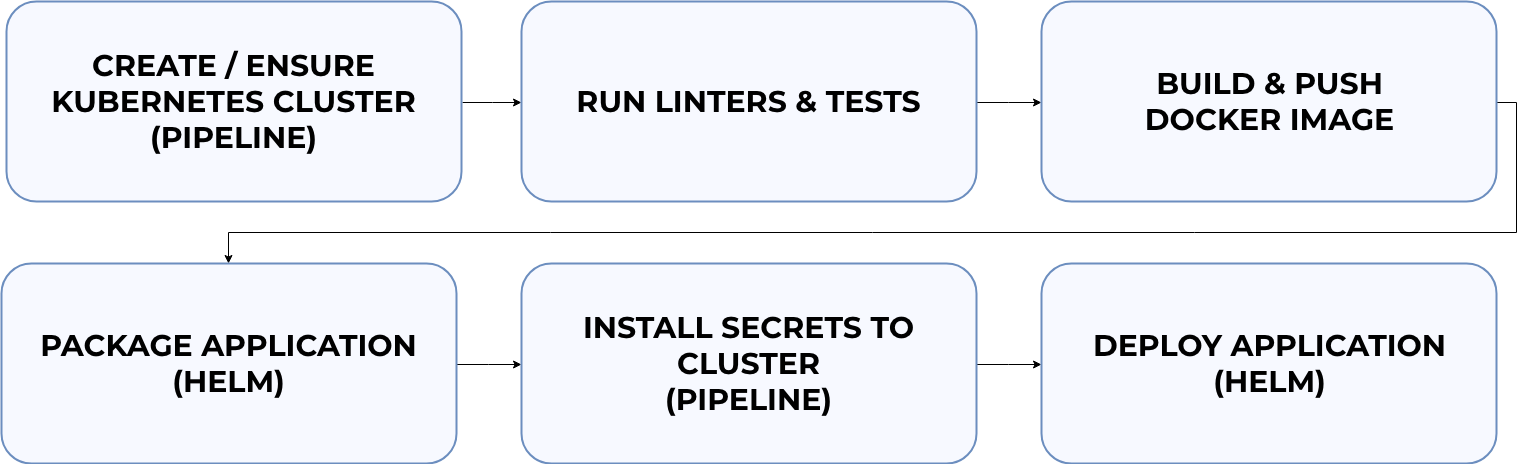
You can check out CI/CD specifications in the repository.
Every time a new commit is pushed to the master branch, the CI/CD pipeline will be triggered to test, validate and update the deployment of the application.
Monitoring 🔗︎
At this point our application is deployed to Kubernetes. We can observe its state using any one of three different methods.
Structured logs 🔗︎
When things go wrong, application logs are a developer’s best friend. However, these logs need to be structured, and, since Kubernetes is a distributed system, securely carried over to a central location. The format of a log is better defined and easier to parse with structured logging (giving us the ability to filter and to search for certain lines).
{"level":30,"time":"<ts>","msg":"log message","pid":0,"hostname":"local","v":1}
For more on how to produce these kinds of well formatted logs, check out our previous post.
Metrics 🔗︎
Our application example already includes some default metrics, which can be monitored using the Grafana dashboard:
<video
Metrics are a very important source of insight into the load and stability of running applications, and are easy to add. Metrics give us the ability to observe the overall state of an application, so that we can act on issues as they arise.
Distributed tracing 🔗︎
Traces show you how a request propagates throughout an application or set of services. Viewing graphs of your traces can help you understand the bottlenecks in your architecture by visualizing how data flows between all of your services.
The unit of work, here, is called a span, which contains information (latency, status, user-defined events and attributes, etc.) pertaining to the work a component is doing. Spans are collected into pieces of trace information, giving us a complete picture of what happens during a request.
To collect traces we use the OpenCensus Node.js library and Jaeger. The core features of OpenCensus are the collection of metrics and trace information from applications, and the ability to expose them to the storage or analysis tool of your choice.
Summary 🔗︎
Hopefully, at this point, you have a better understanding of the steps and building blocks involved in managing and operating a Kubernetes-ready Node.js application. There are still a lot of things that we couldn’t cover in a single blog post. If you have any questions, let us know in the comment section. Nothing is more descriptive than the source code itself, and I encourage you to look at the Node.js with MongoDB Spotguide repository.
Both the service-tools npm library and the Node.js Spotguide are open source and contributions are welcome!




