






tl;dr 🔗︎
On August 25th, one of our customers, who was using Supertubes to operate Kafka clusters on Kubernetes on Amazon, began to experience a service disruption in their Kubernetes cluster.
- Their previously configured Prometheus alerts notified the infra team what services were impacted.
- It turned out that Amazon was having some instance connectivity issues, in one of the London AZs.
- No data loss occurred thanks to the properly configured Kafka and Zookeeper clusters, which had both been distributed across multiple zones.
- As soon as the cluster had enough resources, Supertubes recovered seamlessly.
- By enabling replication through MirrorMaker 2.0, we can also recover from a total, region-wide outage.
The support case 🔗︎
Earlier in August, one of our customers reached out to us with a support case. They had received alerts signaling that there were errors in one of the Kafka brokers managed by Supertubes. A brief investigation ensued. It turned out that there were connectivity issues in one of the availability zones in the London region of AWS, thus pods were affected on nodes located in that AZ. One of their Supertubes managed Kafka broker reported errors. As with most companies today, they were relying on Amazon EC2 instances to run their workloads.
Well, sometimes even Amazon has an outage: they reported some instance connectivity issues for the London region, more specifically in one of the availability zones, euw2-az2. (This is a physical availability zone ID, which maps to a different zone name, like eu-west-2a, for each AWS account. You can check that with aws ec2 describe-availability-zones --region eu-west-2.)


Luckily no data loss and outage occurred thanks to Kubernetes and Supertubes.
The two most beloved Kubernetes features/concepts 🔗︎
Self-healing 🔗︎
I think most of you already know that containers are a good way to bundle your applications. In a production environment, you need to manage the containers that run applications and ensure that there is no downtime. That is to say, if one container goes down, another needs to start. Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. A Pod is a group of one or more containers, with shared storage/network resources, and a specification for how to run the containers. Kubernetes provides self-healing to pods which means it restarts pods that fail, replaces pods, kills pods that don’t respond to your user-defined health check, and doesn’t advertise them to clients until they are ready to serve.
In addition, Kubernetes can dynamically upscale (or downscale) the cluster through the use of their Cluster Autoscaler in environments where dynamic provisioning of nodes is supported. Cluster Autoscaler is capable of automatically adjusting the size of a Kubernetes cluster based on metrics. It requests more resources if, due to insufficient resources, there are pods that failed to run in the cluster. It can also trigger a downscale if the nodes in the cluster are being underutilized.
The Operator pattern 🔗︎
Operators are Kubernetes extensions that use custom resources to manage applications and their components. A resource in Kubernetes is an endpoint in the Kubernetes API, which stores Kubernetes objects (e.g. the Pod instances themselves) of a certain kind (e.g. Pod). A custom resource is essentially a resource that can be added to Kubernetes to extend its basic API. Once a custom resource is installed, users can manage objects of this kind with kubectl, the same way they do for built-in Kubernetes resources, for example, pods. Accordingly, there must be a custom controller which reacts to events as they occur on the custom resource (e.g. induced via kubectl) and carries out the operations necessary to handle the event. To summarize, Kubernetes controllers let you extend the cluster’s behavior without modifying the code of Kubernetes itself.
The best support is no support 🔗︎
Supertubes leverages the same Operator pattern we’ve been discussing. Inside Supertubes there are more than five operators doing their best to maintain a desired state. Banzai Cloud’s deep understanding of how to operate Kafka, Kubernetes and Istio is reflected in the implementation of these Operators. Relying on this knowledge and the Operator pattern, the components are self-reliant. This is what we mean by saying that the best support is when no support is needed, and the customer does not have to do anything to resolve an issue. This is based in our belief that no human can provide support at the same level as a group of Kubernetes Operators, which take care of your workloads in the exact moment an incident is taking place, regardless of the hour.
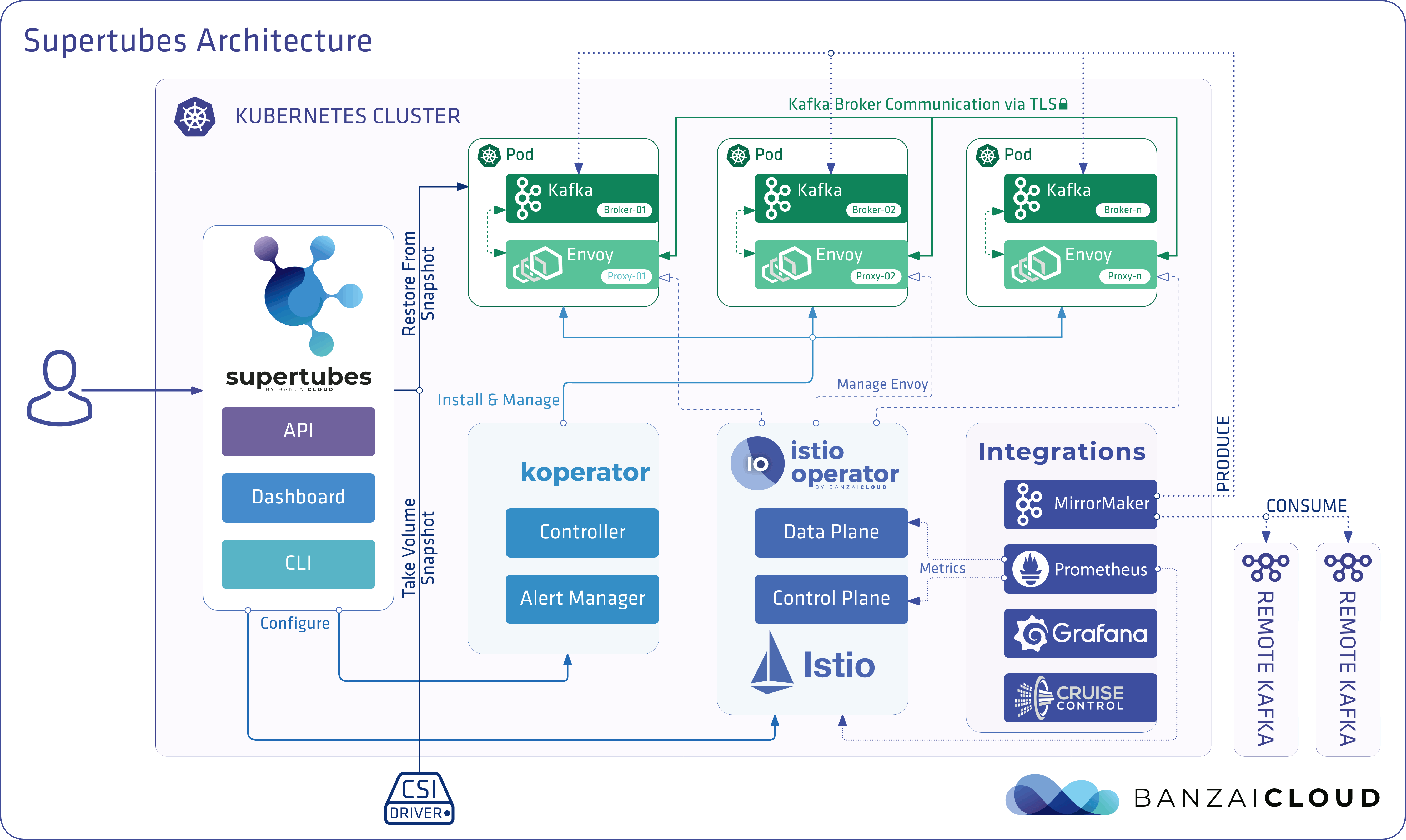
This specific case is no different. Supertubes identified the problem and initiated actions immediately.
After Amazon EC2 instances in the London’s zone2 had some connectivity issues, the Prometheus alerts configured by Supertubes notified the infra team that one of the Kafka brokers was down.
Thanks to the broker configuration, which had included setting broker.rack, no data loss occurred.
broker.rackis a broker config. When you set it, Kafka will try to place replicas in as many different racks as possible, so that the partition can continue to function if a rack goes down. It also makes the maintenance of a Kafka cluster easier, since you can take down whole racks at once. In the case of cloud providers, racks are usually mapped to the concept of availability zones.
Supertubes is designed in this way to save the volumes that are bound to brokers, no matter what. Because one of the brokers went down, it was immediately re-created in the same availability zone so the volume could be saved. Unfortunately, that zone still had some issues, so recreating the pods did not heal the cluster immediately.
To maintain the desired state, two things had to be done:
- The user had to create a new broker with an affinity pointed at an unaffected zone.
- And, since Supertubes handles broker addition gracefully, this triggered a reconcile operation, which, in turn, rebalanced the cluster and made it fully operational again.
Another option would have been to configure a Prometheus alert that would have automatically triggered an upscale. During upscale a new broker is created in a different zone. This is necessary since the volume bound to the failed pod is available in the affected zone and cannot be moved until that zone becomes operational again. When the broker becomes operational, Supertubes initiates a partition rebalance to heal the cluster. Once the unavailable zone becomes operational, a downscale is initiated to remove the underutilized broker.
In this second approach, the steps are performed automatically, without any kind of human interaction.
We would like to highlight a key design decision, which allowed Supertubes to perform the steps we just described. Kafka is a stateful application but our solution does not rely on Kubernetes StatefulSets. Just a quick recap from the K8s docs:
StatefulSet manages the deployment and scaling of a set of Pods, and provides guarantees about their ordering and uniqueness. Like a Deployment, a StatefulSet manages Pods that are based on an identical container spec. Unlike a Deployment, a StatefulSet maintains sticky identities for each of its Pods. These pods are created from the same spec, but are not interchangeable: each has a persistent identifier that is maintained across any rescheduling.
In this case using StatefulSet would have meant that Supertubes couldn’t initiate an upscale. StatefulSet controller would fail to create a new instance until there is one which is in a failed state. Meaning the cluster would have stayed in an unhealthy state until the zone issue was resolved.
As you may know, Kafka relies on Zookeeper, and Supertubes uses an open source Zookeeper Operator with some enhancements. In the circumstances we’re discussing, the Zookeeper cluster is affected and, because of StatefulSet, it cannot recover cleanly. But thanks to the configuration, this did not affect the health of the Kafka cluster in question. Kafka’s reliance on Zookeeper will be coming to an end soon, hopefully in version 3.0.0.
If you are interested in this issue and its progress, please follow KIP-500
Evolve, evolve, evolve 🔗︎
You may ask, “If this is ‘just’ one zone outage, how do we know that this system can recover from an interruption that affects a whole region or a whole cloud provider?” Well, with the use of Mirror Maker 2, the second part is also feasible. We are working closely with the customer to enable Mirror Maker 2 in their environment to ensure that there is no data loss in the event of an entire cluster being affected by a regional outage.
If you are interested in MirrorMaker 2 and how Supertubes eases interaction and configuration, check out our earlier blog post about Kafka disaster recovery on Kubernetes using MirrorMaker2.
Apache Kafka was designed to include a top of the line resiliency feature. Supertubes completes this with additional enhancements. See the latest Supertubes announcement for details. Together, they allow for the maintenance of Kafka infrastructure across different cloud providers, without any overhead.







