Today, we’re happy to announce the 1.0 release of Supertubes, Banzai Cloud’s tool for setting up and operating production-ready Kafka clusters on Kubernetes through the leveraging of a Cloud-Native technology stack.
![]()
In addition to operating production-ready Kafka clusters on Kubernetes, Supertubes comes with features that ease the adoption of Kafka on Kubernetes, such as declarative ACL management, a schema registry, and authentication and authorization of applications through their service accounts. In this post, we’ll be exploring some of the new features added with the release of version 1.0.
Check out Supertubes in action on your own clusters:
Register for an evaluation version and run a simple install command!
As you might know, Cisco has recently acquired Banzai Cloud. Currently we are in a transitional period and are moving our infrastructure. Contact us so we can discuss your needs and requirements, and organize a live demo.
Evaluation downloads are temporarily suspended. Contact us to discuss your needs and requirements, and organize a live demo.
supertubes install -a --no-demo-cluster --kubeconfig <path-to-k8s-cluster-kubeconfig-file>or read the documentation for details.
Take a look at some of the Kafka features that we’ve automated and simplified through Supertubes and the Koperator , which we’ve already blogged about:
- Oh no! Yet another Kafka operator for Kubernetes
- Monitor and operate Kafka based on Prometheus metrics
- Kafka rack awareness on Kubernetes
- Running Apache Kafka over Istio - benchmark
- User authenticated and access controlled clusters with the Koperator
- Kafka rolling upgrade and dynamic configuration on Kubernetes
- Envoy protocol filter for Kafka, meshed
- Right-sizing Kafka clusters on Kubernetes
- Kafka disaster recovery on Kubernetes with CSI
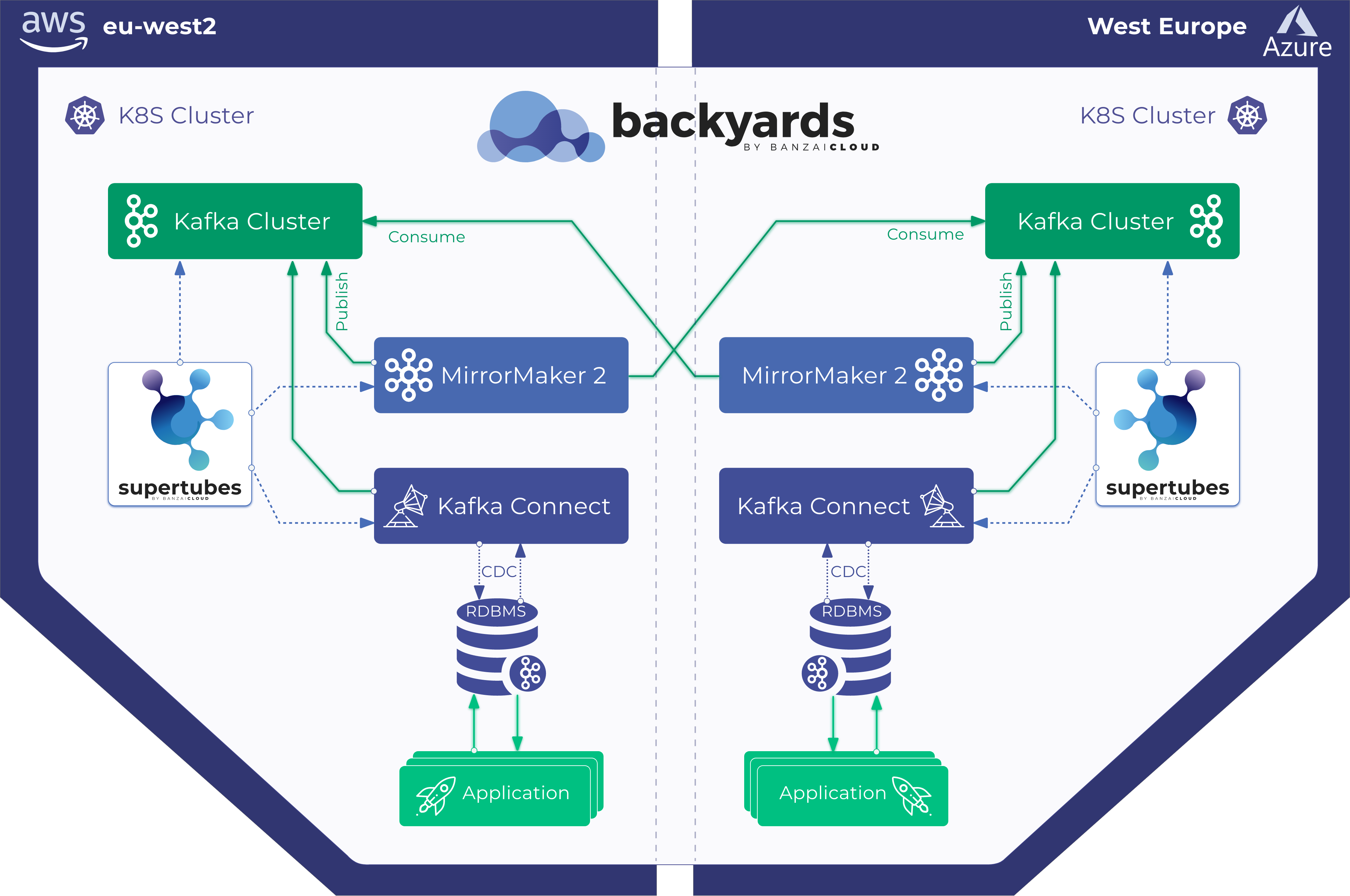
- Kafka disaster recovery on Kubernetes using MirrorMaker2
- The benefits of integrating Apache Kafka with Istio
- Kafka ACLs on Kubernetes over Istio mTLS
- Declarative deployment of Apache Kafka on Kubernetes
- Bringing Kafka ACLs to Kubernetes the declarative way
- Kafka Schema Registry on Kubernetes the declarative way
- Announcing Supertubes 1.0, with Kafka Connect and dashboard
The two major features we’ll be discussing are:
- support for setting up and managing Kafka Connect clusters
- a Dashboard that provides visibility into Kafka clusters managed with Supertubes
Kafka Connect 🔗︎
Kafka Connect is a tool that allows for the scalable and reliable streaming of data between Apache Kafka and other systems. Supertubes deploys Kafka Connect with Confluent’s Community Connectors included, and supports the use of schemas via Schema Registry.
Manage Kafka Connect clusters and Connectors with Supertubes 🔗︎
Supertubes automates the deployment of Kafka Connect clusters and the creation of connectors through KafkaConnect custom resource instances and KafkaConnector custom resource instances, respectively.
Imperative CLI 🔗︎
The Supertubes CLI provides commands that deploy Kafka Connect clusters, and then connectors to these clusters. The easiest way to quickly set up a Kafka Connect cluster is to run the:
supertubes install -a
command which will set up a Kafka Connect cluster with default settings, linked to the provisioned demo Kafka cluster and the deployed Schema Registry instance.
Additional Kafka Connect clusters can be created, or existing ones updated, through the:
supertubes cluster kafka-connect [command]
command.
Connectors running inside Kafka Connect clusters can be managed via:
supertubes cluster kafka-connector [command]
These create and update sub-commands require descriptors that take the form of KafkaConnect and KafkaConnector custom resource specifications. We’ll explore these custom resources in detail, in the next section.
Declarative Kafka Connect cluster management 🔗︎
As we’ve already touched on briefly, a Kafka Connect cluster is represented by a KafkaConnect custom resource. Supertubes deploys the Kubernetes resources necessary to set up Kafka Connect clusters in accordance with the specifications of these custom resources. As a result, any Kafka Connect configuration changes made in a custom resource are automatically propagated to the corresponding Kafka Connect cluster.
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaConnect
metadata:
name: my-kafka-connect
spec:
clusterRef:
# Name of the KafkaCluster custom resource that signifies the Kafka cluster this Kafka Connect instance will connect to
name: kafka
schemaRegistryRef:
# (optional) Name of the SchemaRegistry custom resource that represents the Schema Registry to be made available for connectors
name: kafka
# The port Kafka Connect listens at for API requests (default: 8083)
servicePort:
# (optional) Annotations to be applied to Kafka Connect pods
podAnnotations:
# (optional) Annotations to be applied to the service that exposes Kafka Connect API on port `servicePort`
serviceAnnotations:
# (optional) Labels to be applied to Kafka Connect pods
podLabels:
# (optional) Labels to be applied to the service that exposes the Kafka Connect API on port `servicePort`
serviceLabels:
# (optional) Affinity settings for Kafka Connect pods https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity
affinity:
# Service account for Kafka Connect pods (default: default)
serviceAccountName:
# The compute resource requirements
# requests:
# cpu: 1
# memory: 2.2Gi
# limits:
# cpu: 2
# memory: 2.5Gi
resources:
# (optional) Node selector setting for Kafka Connect pods https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#nodeselector
nodeSelector:
# (optional) Tolerations setting for Kafka Connect pods (https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/)
tolerations:
# (optional) Volume mounts for Kafka Connect pods (https://kubernetes.io/docs/concepts/storage/volumes/)
volumeMounts:
# (optional): Volumes for Kafka Connect pods (https://kubernetes.io/docs/concepts/storage/volumes/)
volumes:
# (optional): Jmx Exporter configuration
jmxExporter:
# Heap settings for Kafka Connect (default: -Xms512M -Xmx2048M)
heapOpts:
# Minimum number of replicas (default: 1)
minReplicas:
# Maximum number of replicas (default: 5)
maxReplicas:
# Controls whether mTLS is enforced between Kafka Connect and client applications (default: true)
MTLS:
# Defines the config values for Kafka Connect in key - value pairs format
kafkaConnectConfig:
# Additional environment variables to launch Kafka Connect with. The following list of environment variables CAN NOT be
# set through this field as these are either set through a specific field (e.g. `HeapOpts`) or are dynamically computed: KAFKA_HEAP_OPTS, KAFKA_OPTS, CONNECT_REST_ADVERTISED_HOST_NAME,
# CONNECT_BOOTSTRAP_SERVERS, CONNECT_GROUP_ID, CONNECT_CONFIG_STORAGE_TOPIC, CONNECT_OFFSET_STORAGE_TOPIC, CONNECT_STATUS_STORAGE_TOPIC,
# CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL, CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL
envVars:
There are several KafkaConnect configurations that are computed and maintained by Supertubes, and thus cannot be overridden by end users:
- bootstrap.servers
- group.id
- config.storage.topic
- offset.storage.topic
- status.storage.topic
- key.converter.schema.registry.url
- value.converter.schema.registry.url
Managing Kafka Connect connectors declaratively 🔗︎
The pattern for managing connectors is similar to that of Kafka Connect. There is a KafkaConnector custom resource that represents a connector type which is used by Supertubes to instantiate connectors on Kafka Connect clusters.
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaConnector
metadata:
name: my-connector
spec:
# The connector class name (e.g. io.confluent.connect.s3.S3SinkConnector)
class:
# The maximum number of tasks the Kafka Connector can create
tasksMax:
# References the Kafka Connect cluster where this connector is to run
clusterRef:
name: my-kafka-connect
# Defines the config values for Kafka Connector in key - value pairs format
config:
# Whether to pause or resume the connector execution
pause:
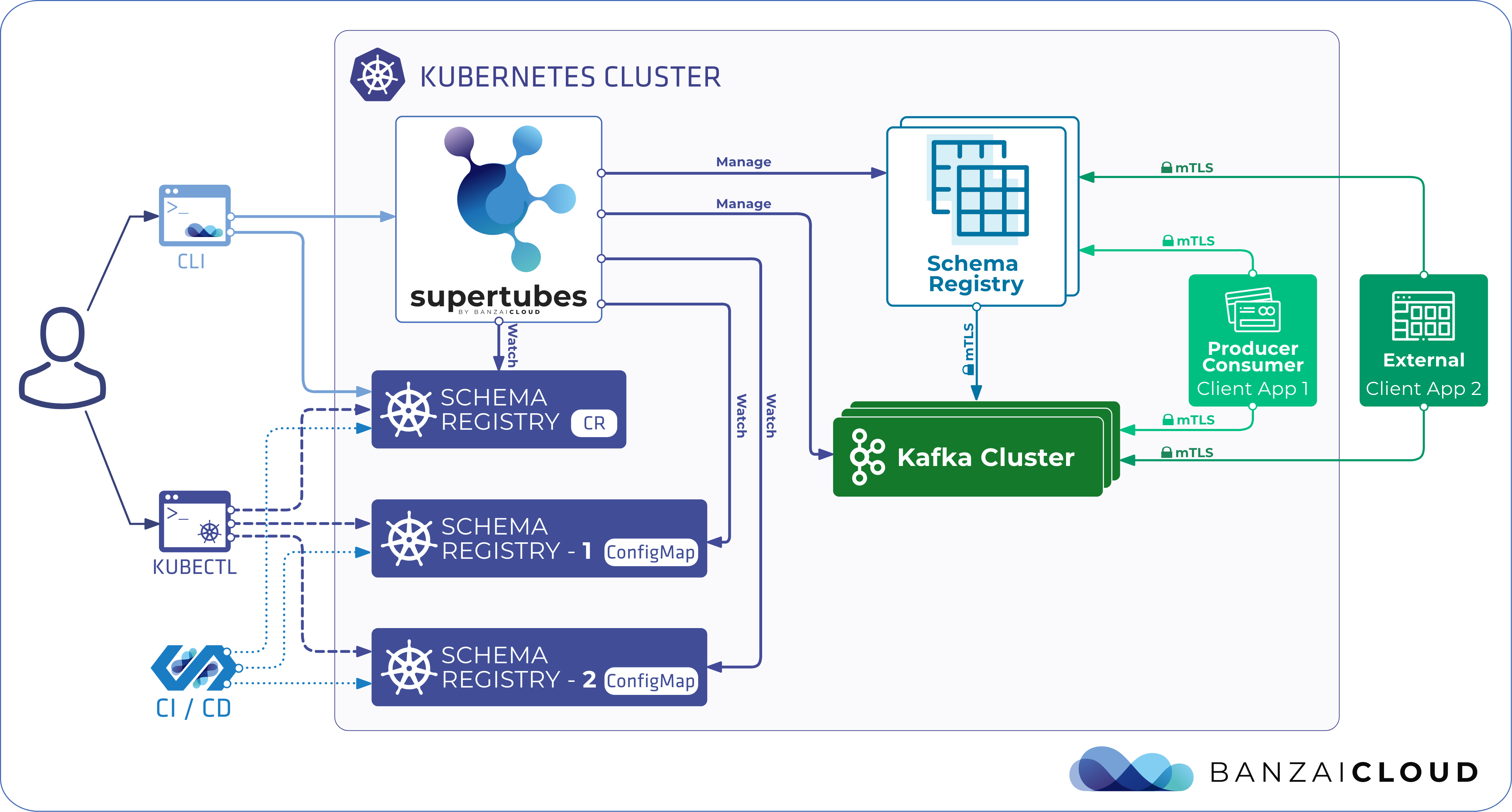
Kafka Connect API endpoints 🔗︎
The deployed Kafka Connect clusters are reachable at the kafka-connect-svc-<kafka-connect-name>.<namespace>.svc:<servicePort> endpoint from within the Kubernetes cluster.
Security 🔗︎
Users that connect to Kafka Connect are authenticated using mTLS by default. This can be disabled via the MTLS field in the KafkaConnect custom resource.
Kafka Connect and connector ACLs 🔗︎
Supertubes takes care of setting up all the ACLs necessary for Kafka Connect itself. The ACLs for the connectors, on the other hand, have to be set up separately, by the user. Typically, a connector of the sink type requires READ access to the topics it reads and to the consumer group named connect-{connector-name}, while a connector of the source type requires WRITE access to the topics it writes to. A Kafka Connect cluster and the connectors it hosts are authenticated by the service account. The Kafka Connect deployment runs with this account, and the connector specific ACLs must be configured with that in mind.
Try out Kafka Connect 🔗︎
Let’s take a look at how we can deploy Amazon’s S3 Sink Connector, using an example.
Setup 🔗︎
-
Register for an evaluation version of Supertubes.
As you might know, Cisco has recently acquired Banzai Cloud. Currently we are in a transitional period and are moving our infrastructure. Contact us so we can discuss your needs and requirements, and organize a live demo.
-
Create a Kubernetes cluster.
-
Point
KUBECONFIGto your cluster. -
Install Supertubes:
Evaluation downloads are temporarily suspended. Contact us to discuss your needs and requirements, and organize a live demo.
Note: You can test Supertubes and evaluate it in non-production environments. Contact us if you’re interested in using Supertubes in production.
This step usually takes a few minutes, and installs a 2 broker demo Kafka cluster and a Kafka Connect cluster.
S3 credentials 🔗︎
The S3 Sink Connector needs AWS credentials to be able to write messages from a topic to an S3 bucket. The AWS credentials can be passed to the connector through a file that is mounted into the hosting Kafka Connect cluster.
Create a Kubernetes secret by storing the AWS credentials 🔗︎
echo "aws_access_key_id=<my-aws-access-key-id>" >> aws_creds.txt
echo "aws_secret_access_key=<my-aws-access-key" >> aws_creds.txt
cat aws_creds.txt | base64
apiVersion: v1
kind: Secret
metadata:
name: aws-s3-secret
namespace: kafka
data:
aws-s3-creds.properties: # base64 encoded AWS credentials (creds.txt)
Mount the secret into Kafka Connect 🔗︎
Modify the KafkaConnect custom resource, as follows, to mount AWS secrets into the Kafka Connect pods:
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaConnect
metadata:
name: kafka
namespace: kafka
...
spec:
...
volumeMounts:
- name: aws-s3-creds
readOnly: true
mountPath: /etc/secrets
volumes:
- name: aws-s3-creds
secret:
secretName: aws-s3-secret
Create the S3 Sink Connector 🔗︎
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaConnector
metadata:
name: my-s3-sink
spec:
class: "io.confluent.connect.s3.S3SinkConnector"
tasksMax: 6
clusterRef:
name: kafka
config:
aws.access.key.id: ${file:/etc/secrets/aws-s3-creds.properties:aws_access_key_id}
aws.secret.access.key: ${file:/etc/secrets/aws-s3-creds.properties:aws_secret_access_key}
flush.size: "10000"
format.class: io.confluent.connect.s3.format.bytearray.ByteArrayFormat
key.converter: org.apache.kafka.connect.converters.ByteArrayConverter
locale: en-US
partition.duration.ms: "30000"
partitioner.class: io.confluent.connect.storage.partitioner.TimeBasedPartitioner
path.format: "'year'=YYYY/'month'=MM/'day'=dd/'hour'=HH"
rotate.schedule.interval.ms: "180000"
s3.bucket.name: my-test-s3-bucket
s3.region: eu-central-1
schema.compatibility: NONE
schema.generator.class: io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator
storage.class: io.confluent.connect.s3.storage.S3Storage
timezone: UTC
topics: my-example-topic
value.converter: org.apache.kafka.connect.converters.ByteArrayConverter
If Kafka ACLs are enabled, in addition to the ACLs created by Supertubes for Kafka Connect, the following ACLs must be created for the S3 Sink Connector:
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaACL
metadata:
name: my-s3-sink-kafkaacl
namespace: kafka
spec:
kind: User
name: CN=kafka-kafka-kafka-connect
clusterRef:
name: kafka
namespace: kafka
roles:
- name: consumer
resourceSelectors:
- name: my-example-topic
namespace: kafka
- name: connector-groups
namespace: kakfa
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaResourceSelector
metadata:
name: my-example-topic
namespace: kafka
spec:
type: topic
name: example-topic
pattern: literal
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaResourceSelector
metadata:
name: connector-groups
namespace: kafka
spec:
type: group
name: connect-
pattern: prefixed
Supertubes dashboard 🔗︎
The next, logical step has been to provide a dashboard component for Supertubes alongside Kafka Connect support. Now its initial version is finally here.
As Supertubes became more and more feature rich, it also became more inherently complex, and, while using the Supertubes CLI or kubectl for interactions gave us a simple and precise method of managing kafka clusters, there was the possibility of it becoming cumbersome, error prone and counter-productive in the long term. Using multiple Kafka clusters on the same Kubernetes cluster multiplies this problem by making you repeat the same commands on different clusters, even if all you want is an overview of their state. Kafka itself also has many components, so checking on your broker log sizes, topic offsets, or consumer group logs means additional complexity.
Our point is that doing all this straight from the command line is difficult, error-prone and slow. This slowness scales to your clusters and applications as they continue to grow, meaning more things have to be kept track of and kept in mind. These problems are not something you can afford to ignore when disaster strikes. During a production environment outage, time is precious, and the last thing you’ll want to deal with is a set of tools that are working against you.
We also wrote about this in our recent blog post about how we believe operators are key to creating Kubernetes environments that are error prone but always ready to self-heal if an issue should arise (and at any time of the day). Remember, the best kind of support is when you don’t even have to pick up the phone, so that, by the time’s you’ve noticed an issue, it’s already fixed itself.
Fortunately, as developers, we use IDEs every day to help hide pointless complexity and automate some of the most common tasks during work. Recently, even Kubernetes benefited from some community driven solutions to this exact problem - increasing complexity and repetition when using kubectl - so we thought that now might be the time to create something that helps our customers to tackle it.
Try it out by running the following simple command on a cluster that already contains Supertubes:
supertubes dashboard show
It should open right in your browser.
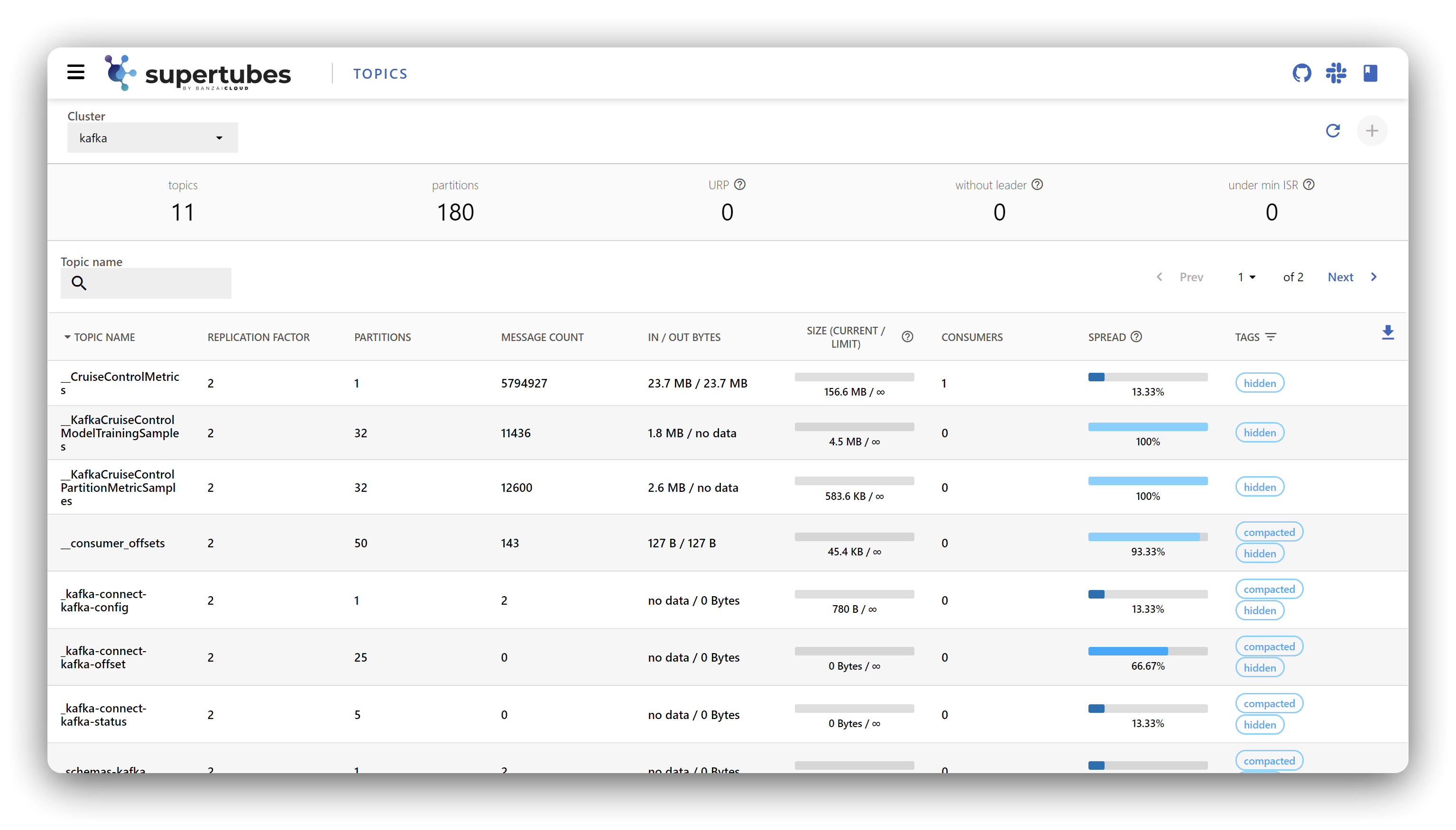
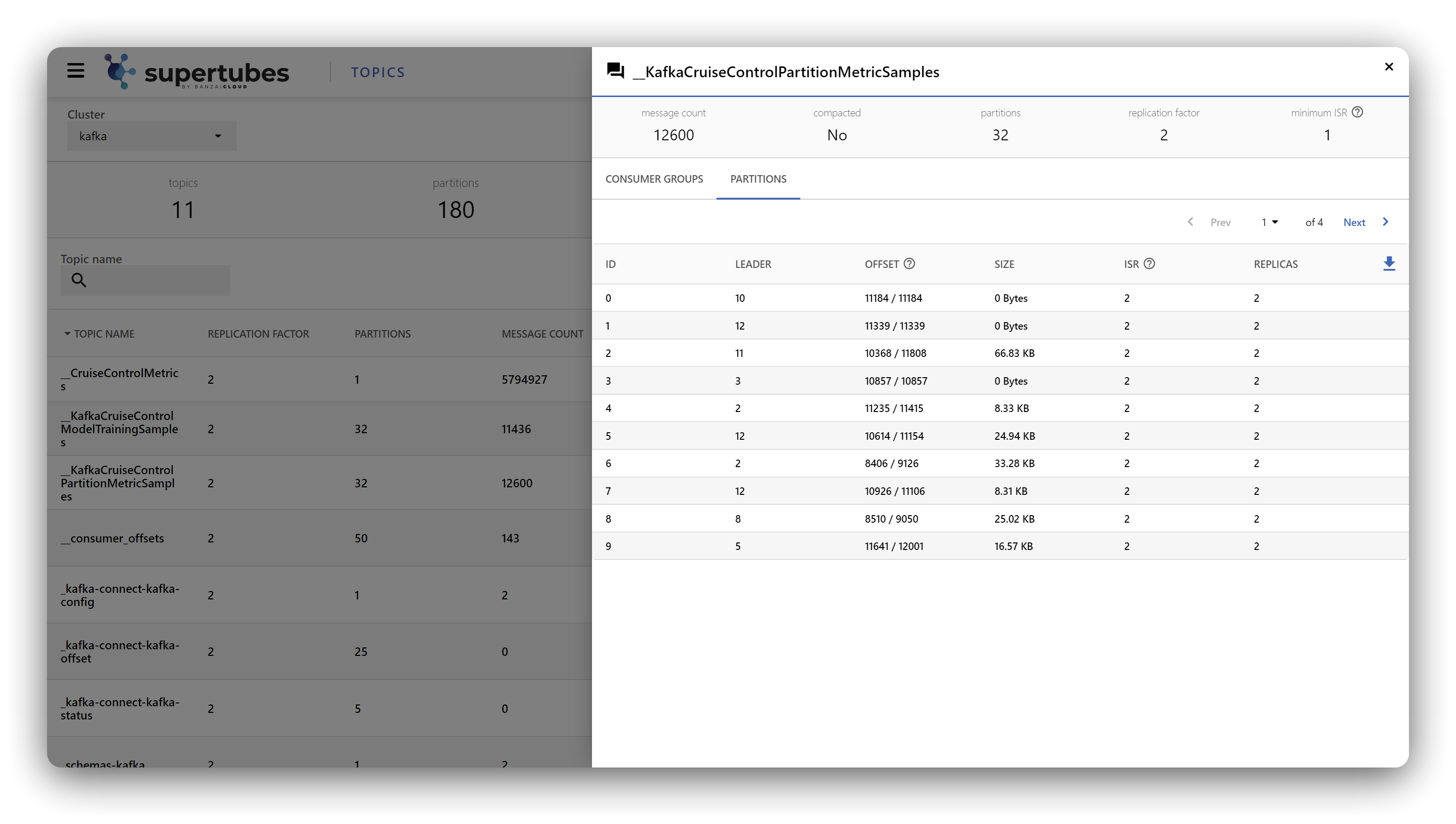
The dashboard helps you monitor all the key metrics of your Kafka cluster at a glance and in a single place. Colors indicate potential issues and what you should keep an eye on, so you can prepare for anomalies and then act accordingly. You can observe the core components of your cluster under the labels of Topics, Brokers and Consumer Groups, and dig deeper into each of these for further information - like number of messages, partition sizes, low and high watermark offsets, in-sync replicas, etc.
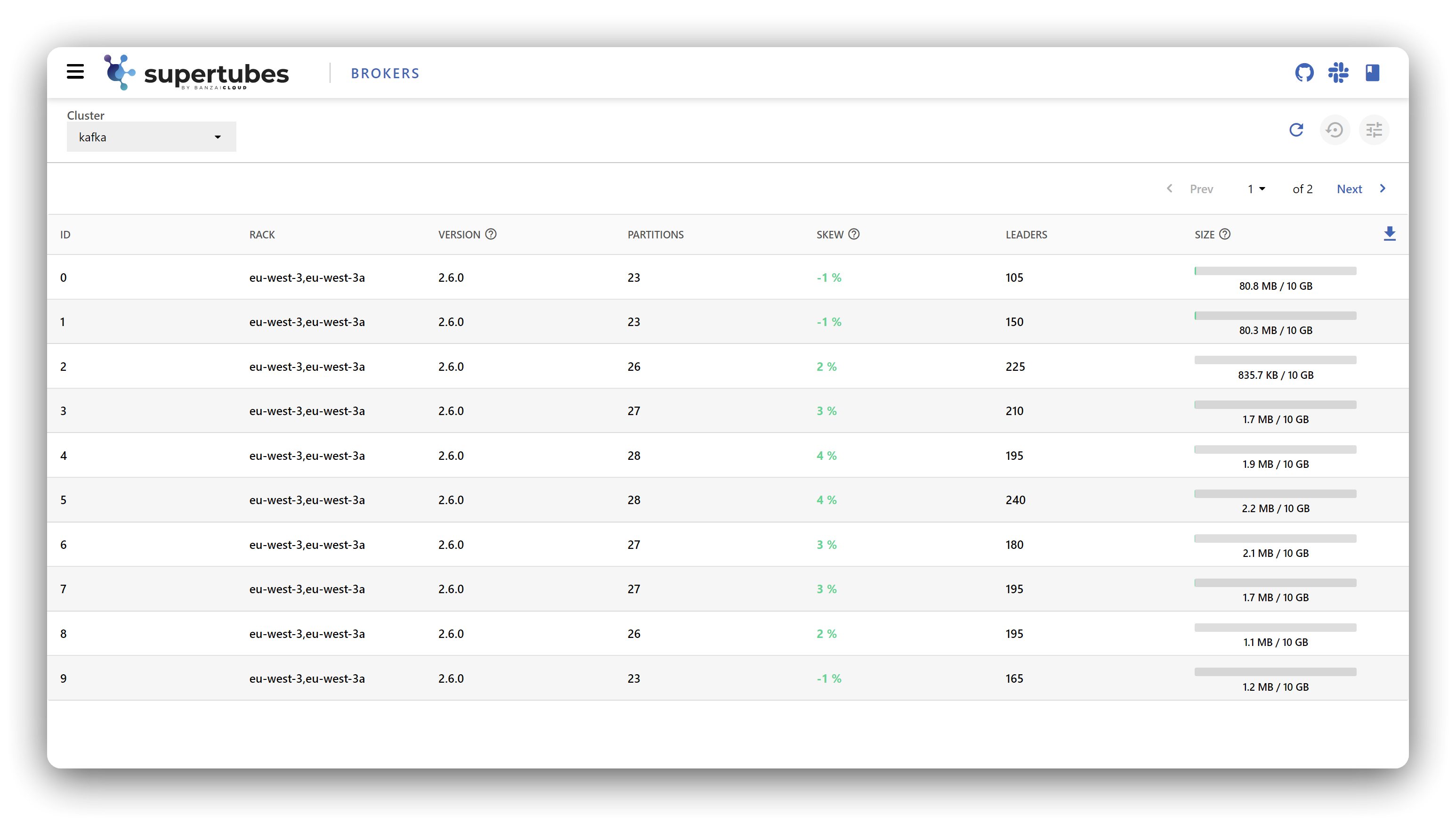
In the case of brokers, it’s a good idea to check how much space is left in the underlying Persistent Volume Claim - so you don’t get any nasty surprises when it reaches its limit - or to see which offset each member of a specific Consumer Group is currently at, or how much lag they are operating under. Oh, and we also added a dark mode!
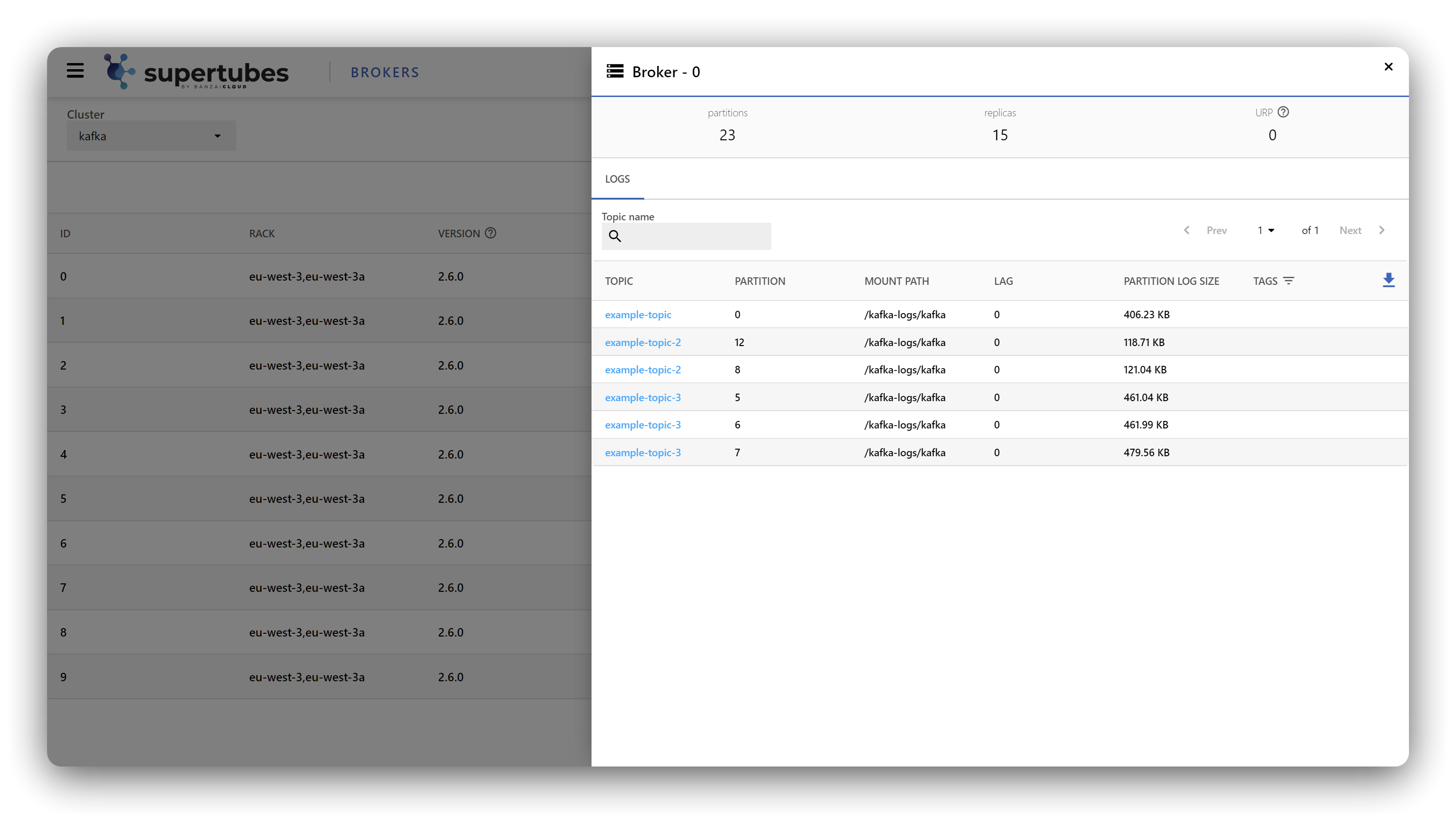
We’re very eager to show you how much more we’re planning for the dashboard in terms of features, like Kafka ACL handling, advanced anomaly prediction and detection, Kafka Connect and Schema Registry support, and features that are only available thanks to Istio, so that we can provide data and telemetry about the state of the Kafka cluster that wasn’t previously possible.
Wrap up 🔗︎
It’s been a long journey since we launched the first version of Supertubes. Our initial idea, to move Kafka inside an Istio mesh, turned out to be an excellent one that’s opened us up to many dovetailing possibilities. Using Istio with Kafka has a lot of benefits, and, if you want to read more about them, check out our post on the subject. We would like to thank every single one of you who has tried Supertubes or even just read our blogposts over this past year. We can say with certainty that this is just the first milestone in a longer journey, and we are planning to provide various new features meant to make life easier for Supertubes’ users, and to reach the next level in operating Kafka on Kubernetes, so stay tuned.