At Banzai Cloud we provision different frameworks and tools like Spark, Zeppelin and, most recently, Tensorflow, all of which run on our Pipeline PaaS (built on Kubernetes).
One of Pipeline’s early adopters runs a Tensorflow Training Controller using GPUs on AWS EC2, wired into our CI/CD pipeline, which needs significant parallelization for reading training data. We’ve introduced support for Amazon Elastic File System and made it publicly available in the forthcoming release of Pipeline. Beside Tensorflow, they also use EFS for Spark Streaming checkpointing instead of S3 (note that we don’t use HDFS at all).
Note: The Pipeline CI/CD module mentioned in this post is outdated and not available anymore. You can integrate Pipeline to your CI/CD solution using the Pipeline API. Contact us for details.
This post would like to walk you through some problems with EFS on Kubernetes and provide a clearer picture of its benefits, before digging into the Tensorflow and Spark Streaming examples in the next post in this series. So, by the end of this blog:
- You will understand how EFS works on k8s
- You will be able to provision and use EFS with or without Pipeline
- You will appreciate the simplicity and scale of automation inherent in Pipeline
Notes on EFS 🔗︎
- One app, multiple nodes, same file(s) - EFS is your best friend
- But wait, I’d rather use S3. No, S3 is neither an alternative to using an NFS nor a replacement for EFS. S3 is not a file system.
- This
smellslike a cloud lockin’ to me - not really, Pipeline/Kubernetes can use minio to unlock you, which we’ll discuss in another post. - It can cost a heck of a lot - it’s SSD based: storage capacity and pricing scale accordingly, though it’s still like 10x more than EBS
- It’s based on NFSv4.x and can be used with AWS Direct Connect (yes, a colleague has already come up with some unconventional ideas about the federation work we’re doing with Pipeline for hybrid-deployments)
- You can use GlusterFS, instead, if you’re one of those special few for whom it’s a feasible option
Create and attach EFS storage manually to a k8s cluster - the hard way 🔗︎
tl;dr1: Who cares? Pipeline automates all this; maybe you’ll get a GitHub star once you’re done reading.
tl;dr2: I know all this already, I’ll just use the EFS provisioner deployment you guys open sourced. Done. Maybe I’ll give you a GitHub star as well.
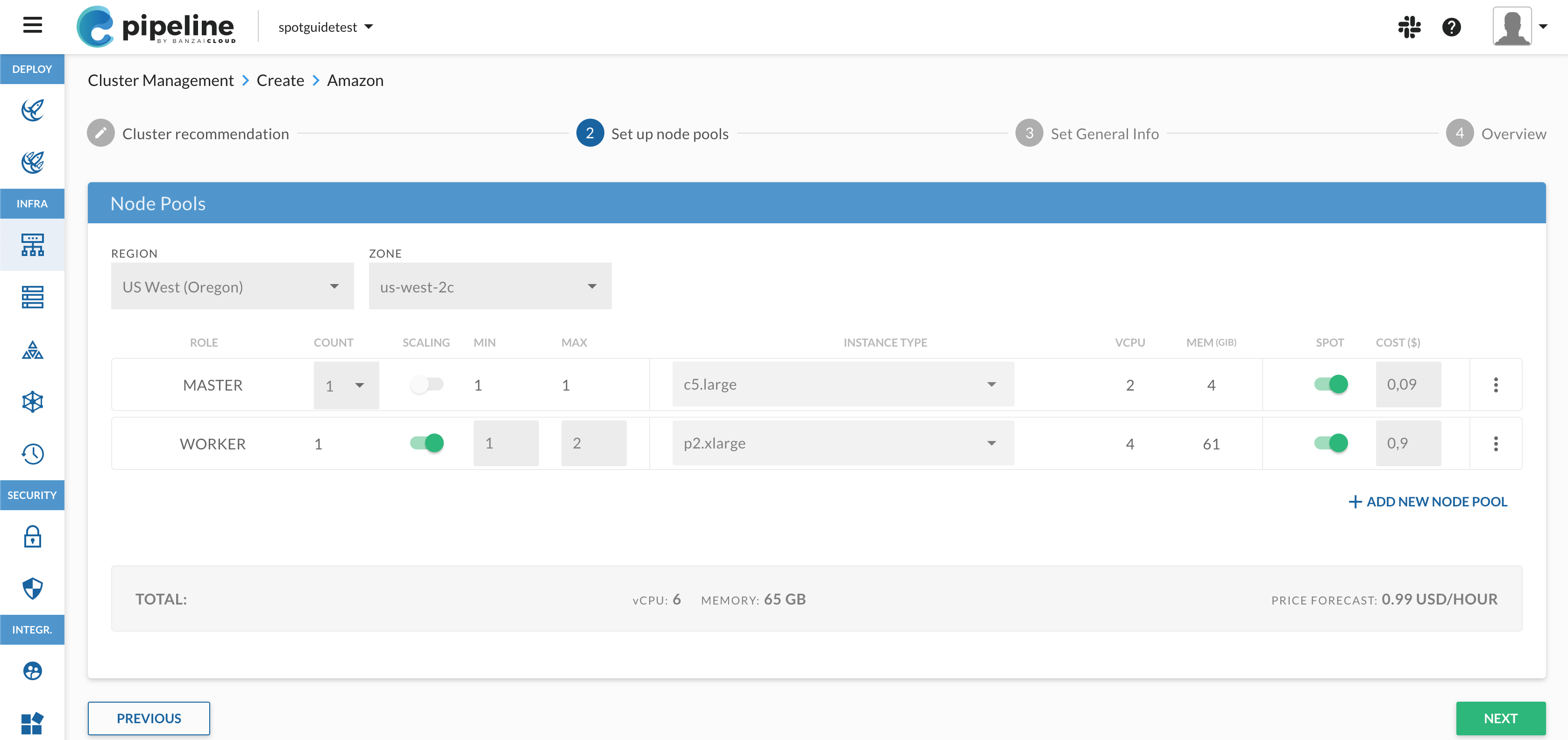
Create a Kubernetes cluster on AWS 🔗︎
OK, this first step is not hard. You can provision a Kubernetes cluster with Pipeline with one single REST API call - see the Postman collection we created for that reason or follow this post or install & launch Pipeline, either by yourself or by launching a Pipeline control plane on AWS with the following Cloudformation template. Easy isn’t it? What’s that, there’s plenty of options? Just wait until we get to the hosted service.
Once the cluster is up and running you can use the Cluster Info request from Pipeline’s Postman collection to get the necessary info about a cluster. You’ll need the following:
- The IP address for all
nodesexcept master VPC id,Subnet idandSecurity Group idfor the node cluster’s network (VpcId, SubnetId, SecurityGroupId)
The following steps require AWS CLI. The easiest way to get what we need is to ssh into one of the nodes, since an AWS CLI will already be installed and ready to be use. You’ll need the same SSH key you provided for Pipeline.
ssh -i yourPrivateKey ubuntu@[Node-Public-Ip]
If you’re using the Pipeline control plane, you need to ssh to the control plane instance first. There, you’ll find the ssh key for rest of the nodes at: /opt/pipeline/.ssh/id_rsa.
Configure the AWS client with aws configure specifying AWS region and credentials.
Create the EFS FileSystem 🔗︎
You’ll need a unique ID for the file system; install uuid if necessary:
sudo apt install uuid
Create the FileSystem:
aws efs create-file-system --creation-token $(uuid)
{
"SizeInBytes": {
"Value": 0
},
"CreationToken": "dfa3efaa-e2f7-11e7-b6r3-1b3492c170e5",
"Encrypted": false,
"CreationTime": 1515793944.0,
"PerformanceMode": "generalPurpose",
"FileSystemId": "fs-c1f34a18",
"NumberOfMountTargets": 0,
"LifeCycleState": "creating",
"OwnerId": "1234567890"
}
Make sure to note the FileSystemId and OwnerId, as you will need them later.
Create the mount target 🔗︎
aws efs create-mount-target \
--file-system-id {FileSystemId} \
--subnet-id {SubnetId} \
--security-groups {SecurityGroupId}
{
"MountTargetId": "fsmt-5dfa3054",
"NetworkInterfaceId": "eni-5cfa2372",
"FileSystemId": "fs-c1f65a08",
"LifeCycleState": "creating",
"SubnetId": "subnet-1d11267a",
"OwnerId": "1234567890",
"IpAddress": "10.0.100.195"
}
Poll the status of mount targets until status LifeCycleState = “available”:
aws efs describe-mount-targets --file-system-id fs-c1f24a08
Create an inbound rule for NFS in the security group 🔗︎
aws ec2 authorize-security-group-ingress --group-id {SecurityGroupId} --protocol tcp \
--port 2049 --source-group {SecurityGroupId} --group-owner {OwnerId}
Deploy the EFS provisioner 🔗︎
In order to mount EFS storage as PersistentVolumes in Kubernetes, deploy the EFS provisioner. The EFS provisioner consists of a container that has access to an AWS EFS resource.
To deploy to the Kubernetes cluster directly from your machine, you need to download the Kubernetes cluster config (aka kubeconfig), using the Cluster Config request from our Postman collection. The easiest way to do this is to save it to a local file in your home directory and set the KUBECONFIG env variable:
export KUBECONFIG=~/.kube/config
Make sure your Amazon images contain the nfs-common package. If not, ssh to all the nodes and install nfs-common with
sudo apt-get install nfs-common
wget https://raw.githubusercontent.com/banzaicloud/banzai-charts/master/efs-provisioner/efs-provisioner.yaml
Edit efs-provisioner.yaml and replace the values in brackets: {FILE_SYSTEM_ID}, {AWS_REGION}, {AWS_ACCESS_KEY_ID}, {AWS_SECRET_ACCESS_KEY} with yours.
Alternatively, instead of specifying ASW credentials, you can set up instance profile roles that allow EFS access. Apply with kubectl.
kubectl apply -f efs-provisioner.yaml
The resulting output should be something like this:
configmap "efs-provisioner" created
clusterrole "efs-provisioner-runner" created
clusterrolebinding "run-efs-provisioner" created
serviceaccount "efs-provisioner" created
deployment "efs-provisioner" created
storageclass "aws-efs" created
persistentvolumeclaim "efs" created
At this point your EFS PVC should be ready to use:
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
efs Bound pvc-e7f86c81-f7ea-11e7-9914-0223c9890f2a 1Gi RWX aws-efs 29s
Mount the PVC to a container 🔗︎
Finally, let’s see how you can use the PVC you just claimed and mount it to a container.
apiVersion: v1
kind: Pod
metadata:
name: example-app
spec:
containers:
- name: example-app
image: example_image:v0.1
volumeMounts:
- name: efs-pvc
mountPath: "/efs-volume"
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs
At this stage you should be a happy, functional user of EFS - a bit of work has to be done to get to this stage but worry not, the next post in this series will be about how you can do it with Pipeline. That process is so simple it’s short enough to tweet. Also, we will walk through the benefits of using EFS with Tensorflow and the performance improvements EFS provides to streaming Spark applications when checkpointing (and the reasons we have for switching to EFS instead of S3 or HDFS).