






Update: Logging operator v3 (released March, 2020) 🔗︎
We’re constantly improving the logging-operator based on feature requests of our ops team and our customers. The main features of version 3.0 are:
- Log routing based on namespaces
- Excluding logs
- Select (or exclude) logs based on hosts and container names
- Logging operator documentation is now available on the Banzai Cloud site.
Check The Kubernetes logging operator reloaded post for details.
At Banzai Cloud we put a lot of emphasis on observability, so we automatically provide centralized monitoring and log collection for all clusters and deployments done through Pipeline. Over the last few months we’ve been experimenting with different approaches - tailored and driven by our customers’ individual needs - the best of which are now coded into our open source Logging-Operator.
Just to recap, here are our earlier posts about logging using the
fluentecosystem Centralized log collection on Kubernetes. Secure logging on Kubernetes. Advanced logging on Kubernetes
In a nutshell, the aim of the Logging-Operator is to automate all infrastructural components and also seamlessly and securely move logs from all deployments (and K8s) into a centralized place.
Logging Operator 🔗︎
The operator uses Fluentd and Fluent-bit to deal with logging and the Kubernetes Operator SDK to interact with dynamic deployments.
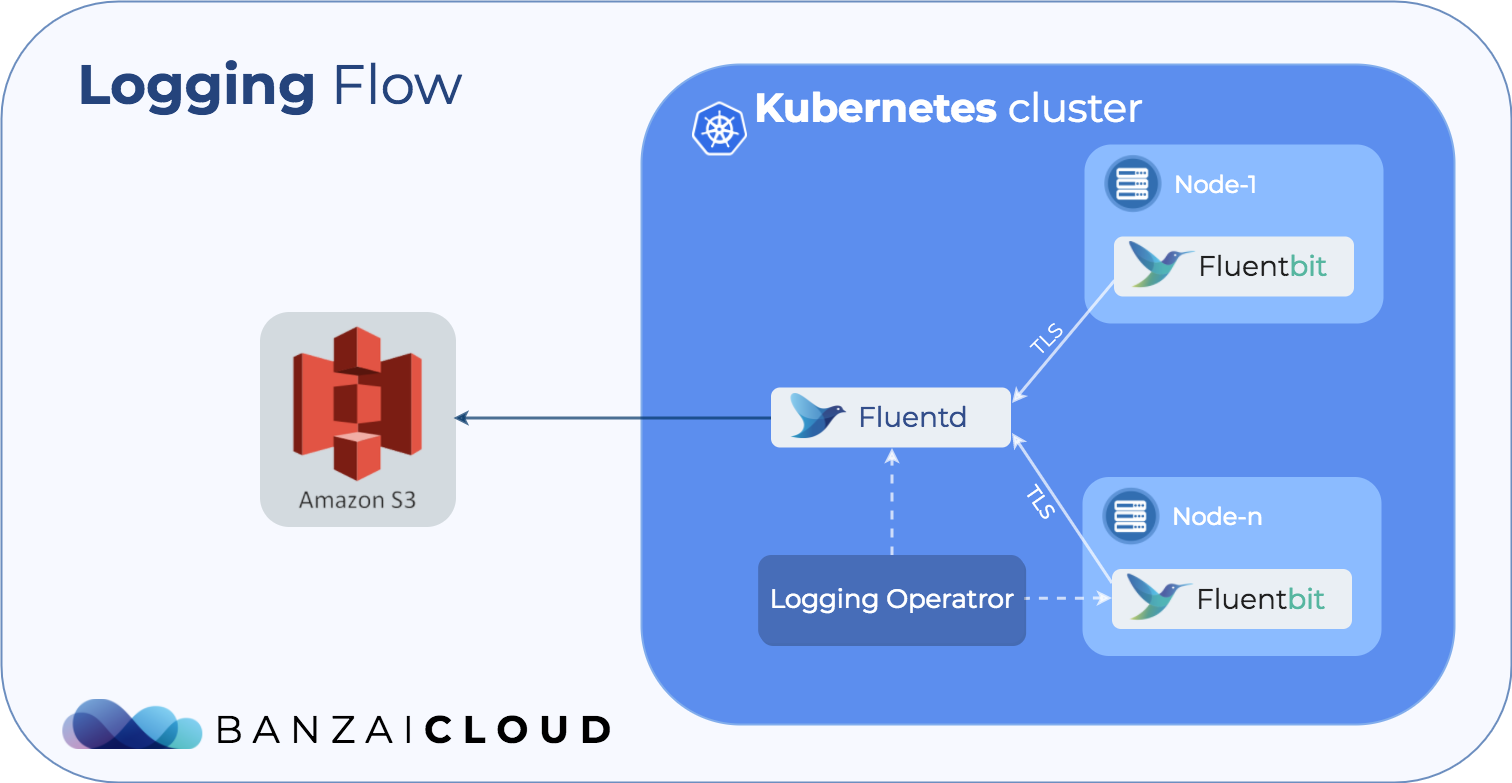
Fluent-bit collects logs from containers and enriches them with information from the Kubernetes API server. To do that we use the Docker parser to collect data from Kubernetes. Then we forward it to Fluentd. The architecture is designed in a way to allow the reuse of existing components. We have anticipated the possibility that customers may already have a Fluentd ecosystem installed and configured. In that case, the Operator is simply configuring the Fluent-bit part to forward it to the logs.
The second piece of the puzzle is Fluentd. It parses and filters the logs from Fluent-bit, then outputs them to a configured place for further analysis.
You may have considered that all of these things can be done without an operator, basically with Fluentd and Fluent-bit (we’ve been doing it for months). In that case, why do we need a Logging-Operator?
To answer this question let’s first list the main features of the Operator:
-
Deploys Fluent-bit and Fluentd to the Kubernetes cluster
- Logging-Operator creates a
DaemonSetfor Fluent-bit so every node has its own log collector. Fluentd will be created as aDeploymentwith one replica. Remember that with Pipeline the Horizontal and Vertical autoscaler can be used and enforced.
- Logging-Operator creates a
-
Provides a default config
- Here, the difficulty lies in providing the proper config for various components. Logging-Operator gives a default config, which is more than good enough in most cases. Config is stored in a
ConfigMap. It configures the Fluent ecosystem to process Kubernetes related logs in an easy way. Also, the operator gives us the ability to overwrite this config by modifying the relatedConfigMap.
- Here, the difficulty lies in providing the proper config for various components. Logging-Operator gives a default config, which is more than good enough in most cases. Config is stored in a
-
Uses TLS to secure connection between Fluentd and Fluent-bit.
- When Pipeline is used to create a Kubernetes cluster the creation of the required Certs and Keys are automated.(Behind the scenes we use Vault to store all our secrets, utilizing Bank-Vaults). The operator looks for a specific secret which contains all the required elements for TLS.
-
CustomResourceDefinitionallows us to process new application logs- This is is the main reason why we chose the operator to handle logging. This feature enables developers to ship applications with logging configurations. It helps them to specify which logs go where and how. Moreover it provides a great interface via the
kubectlcommand line tool, making it is possible to create/delete/list log configurations like pods.
- This is is the main reason why we chose the operator to handle logging. This feature enables developers to ship applications with logging configurations. It helps them to specify which logs go where and how. Moreover it provides a great interface via the
The following config values are supported for the operator
| Name | Description | Default value |
|---|---|---|
| RBAC | It needs to be set to true if the Kubernetes cluster uses RBAC | false |
| Namespace | the namespace where the operator will be installed | default |
The following config values are supported for Fluent-bit
| Name | Description | Default value |
|---|---|---|
| Enabled | Deploy fluent-bit on the cluster | true |
| Namespace | the namespace where the operator will be installed | default |
| TLS_Enabled | the namespace where the operator will be installed | false |
The following config values are supported for Fluentd:
| Name | Description | Default value |
|---|---|---|
| Enabled | Deploy fluentd on the cluster | true |
| Namespace | the namespace where the operator will be installed | default |
| TLS_Enabled | the namespace where the operator will be installed | false |
CustomResourceDefinition 🔗︎
The operator parses the following definition to generate the appropriate config file. If we take a closer look, we will find that the definition has three major parts:
- input
- filter
- output
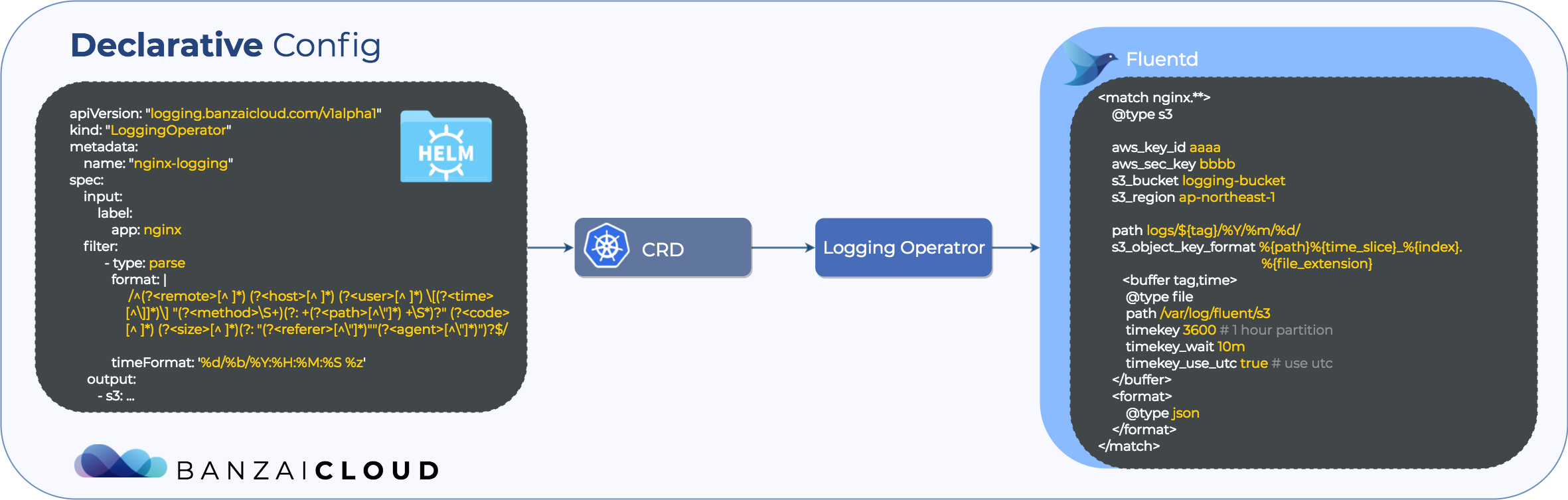
These keywords may sound familiar to Fluentd users. These are the main plugin types supported by Fluentd.
Fluentd also supports Parser, Formatter, Buffer, and Storage plugins, for which support will be added later.
In terms of input, most of the work is done by our default config, but the application name must be specified. This is essential, because the operator uses this value to differentiate between related logs.
apiVersion: "logging.banzaicloud.com/v1alpha1"
kind: "LoggingOperator"
metadata:
name: "nginx-logging"
spec:
input:
label:
app: nginx
filter:
- type: parser
format: |
/^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$/
timeFormat: '%d/%b/%Y:%H:%M:%S %z'
output:
- s3:
parameters:
- name: aws_key_id
valueFrom:
secretKeyRef:
name: loggings3
key: awsAccessKeyId
- name: aws_sec_key
valueFrom:
secretKeyRef:
name: loggings3
key: awsSecretAccesKey
- name: s3_bucket
value: logging-bucket
- name: s3_region
value: eu-west-1In our case, the filter requires a type of parser. Specifically, the filter parser plugin, which requires a format and timeFormat, inside which the Regexp may be tailored to the application.
If you are not familiar with fluentd, timeFormat is the Regexp used to parse the time field that creates timestamps from raw text.
The last section is output. As an example we chose to use the S3 plugin. It requires AWS credentials to store the filtered logs to an S3 bucket. These values come from a Kubernetes secret, referenced as loggings3 in our example. If you are using Pipeline, this secret will be stored in Vault and securely transported inside the Kubernetes cluster. Two more parameters must be set, one which describes your bucket name, and one that gives the region it’s in, then you’re all set.
Only the S3 output format can be used in the first public version of the operator, but we are planning to add other object store providers in private beta/testing.
Example Nginx App 🔗︎
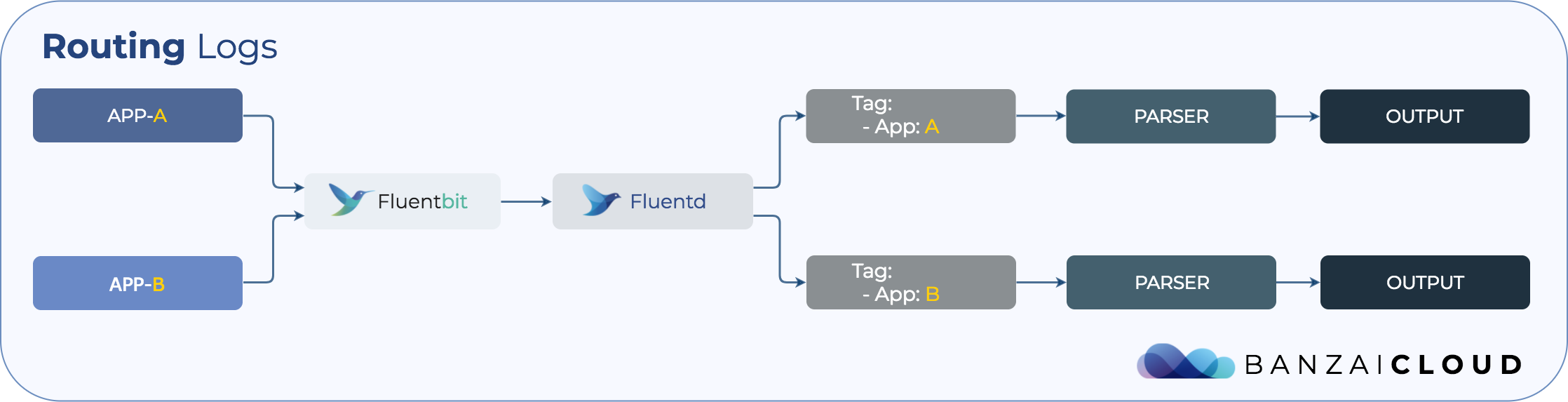
To demonstrate how the Logging-Operator works we have created a simple example Nginx Helm chart which contains a CustomResourceDefinition as described above. The Logging-Operator will process Nginx logs and output them to a specific Amazon S3 bucket.
To generate Nginx logs a small busybox container handles various requests.
Install the logging operator via the Helm chart using the following command:
helm install banzaicloud-stable/logging-operator
kubectl get pods
NAME READY STATUS RESTARTS AGE
fluent-bit-wv9dm 1/1 Running 0 17m
fluentd-668f7ddb5d-bk8vg 2/2 Running 0 17m
warped-possum-logging-operator-6cc57b68f5-lmdkv 1/1 Running 0 17m
kubectl get configmap
NAME DATA AGE
fluent-bit-config 1 17m
fluentd-app-config 0 17m
fluentd-config 3 17m
warped-possum-logging-operator-config 1 17mThe Logging-Operator has created fluent-bit, fluentd and operator pods with the required ConfigMaps. fluentd-app-config ConfigMap is special because now it’s empty. This will hold the app related configuration for Fluentd.
In order to upload files to an S3 bucket we need to create a Kubernetes secret which in our case is called loggings3.
kubectl create -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: loggings3
type: Opaque
data:
awsAccessKeyId: ABCDEFGHIKL
awsSecretAccesKey: SOMEAMAZONSECRET
EOFNext install the Nginx example App:
helm install deploy/helm/nginx-test/
kubectl get pods
NAME READY STATUS RESTARTS AGE
exhaling-anaconda-nginx-test-54f8fbd5f4-nt5wt 2/2 Running 0 16m
fluent-bit-wv9dm 1/1 Running 0 17m
fluentd-668f7ddb5d-bk8vg 2/2 Running 0 17m
warped-possum-logging-operator-6cc57b68f5-lmdkv 1/1 Running 0 17m
kubectl get configmap
NAME DATA AGE
fluent-bit-config 1 17m
fluentd-app-config 1 17m
fluentd-config 3 17m
nginx-config 1 18m
script 1 18m
warped-possum-logging-operator-config 1 17mNow, fluentd-app-config contains the generated config for Nginx. This config is created by the operator itself.
Just like that, all your app related logs can be found in the specified S3 bucket.
Remember if you are using Pipeline to deploy the Logging-Operator all the secrets are generated/transported to your Kubernetes Cluster using Vault.
Future of the project 🔗︎
This project was started to validate the logging operator concept. As we experience different scenarios we will continue to add more and more features, plugins and use-cases - slowly adding the features supported by our static logging. Stay tuned.







