One Eye, the observability tool for Kubernetes
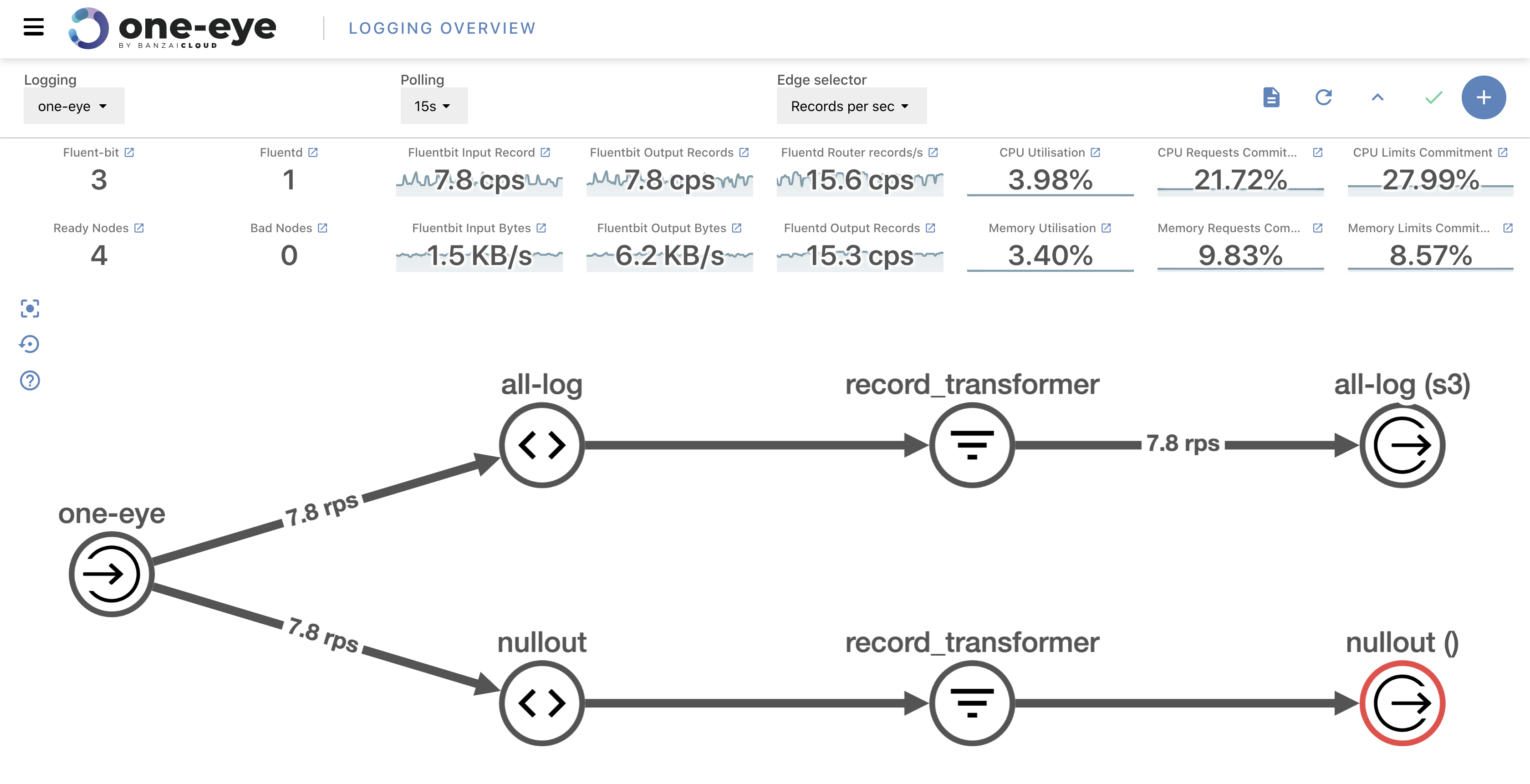
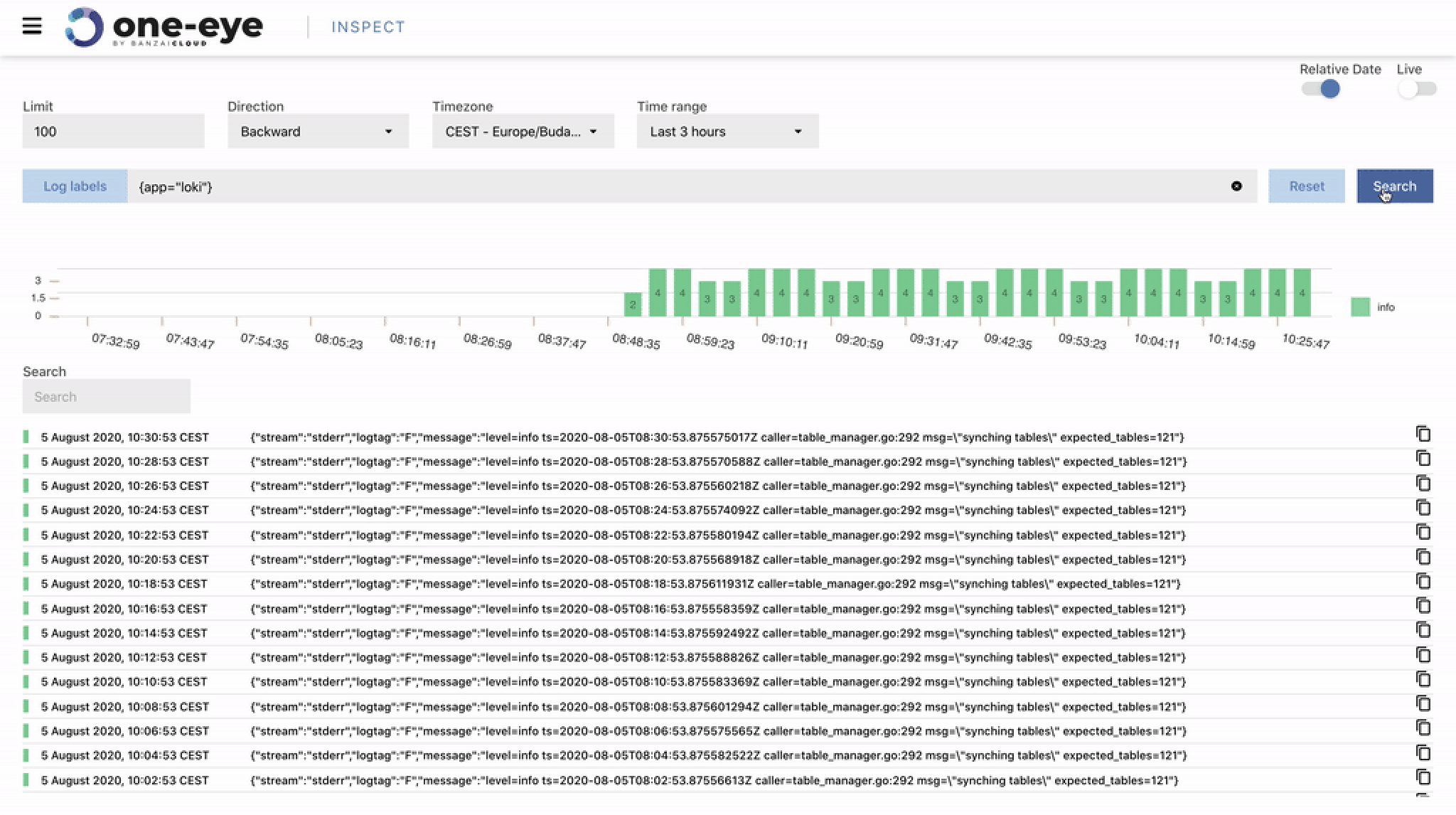
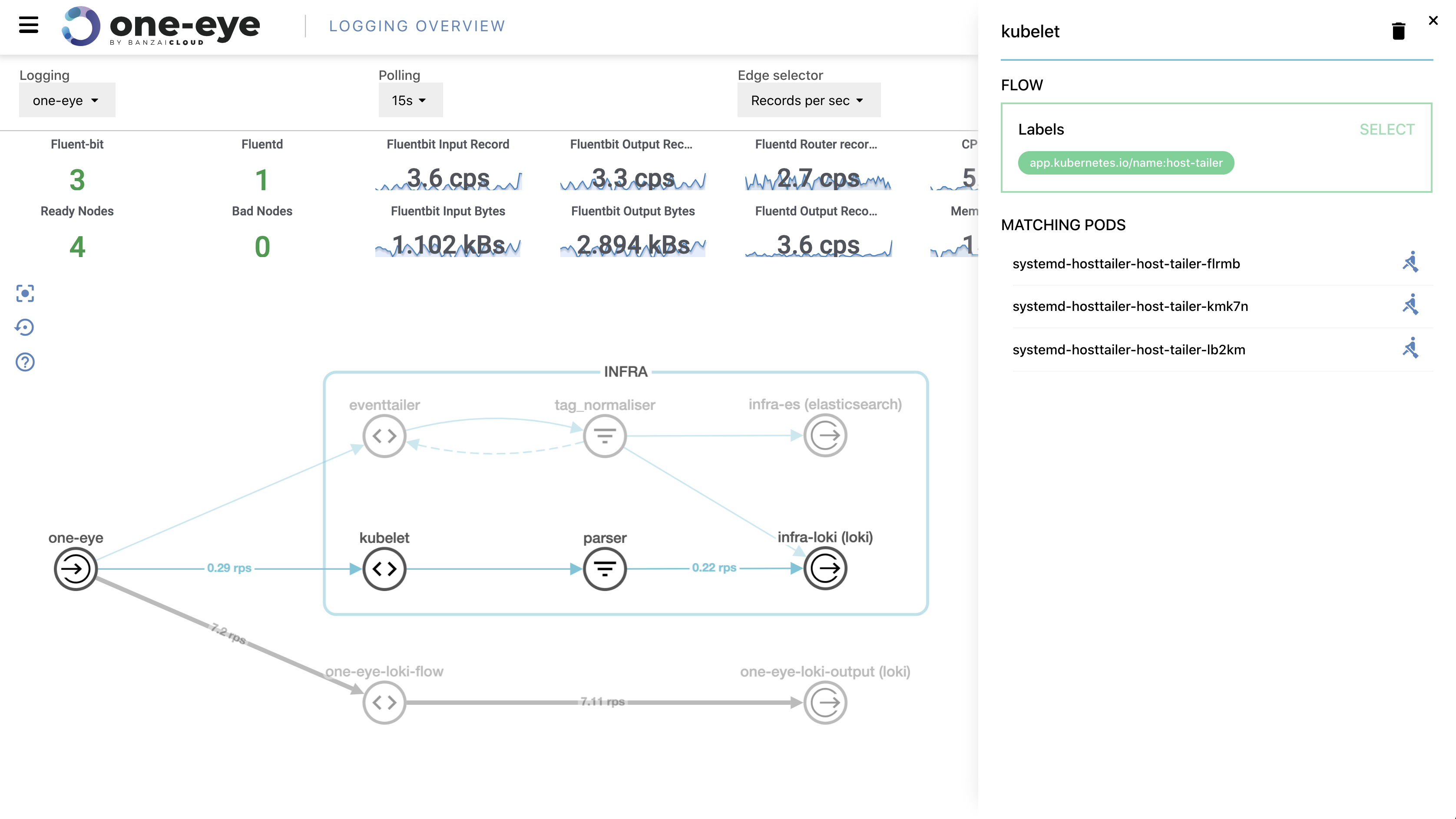
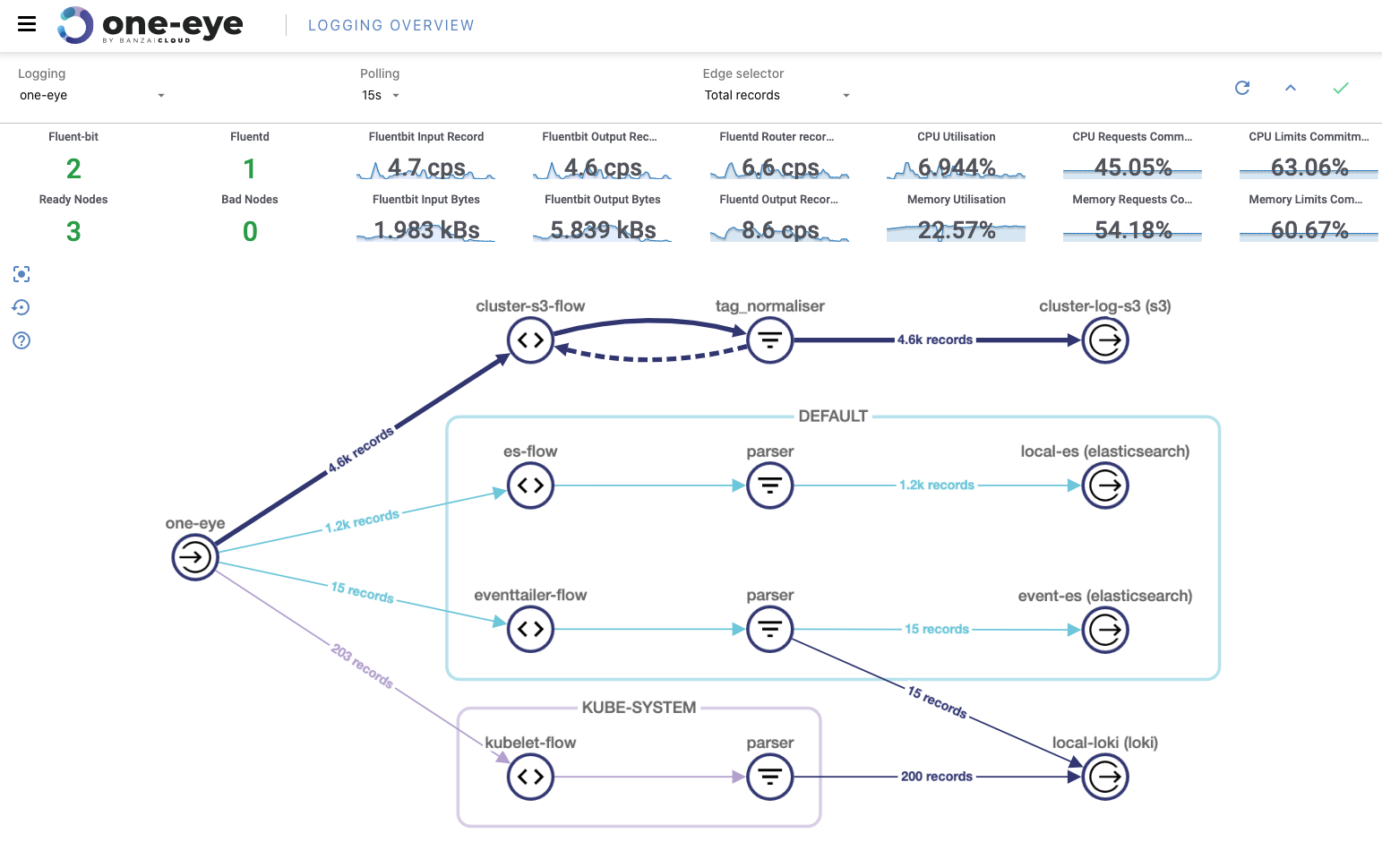
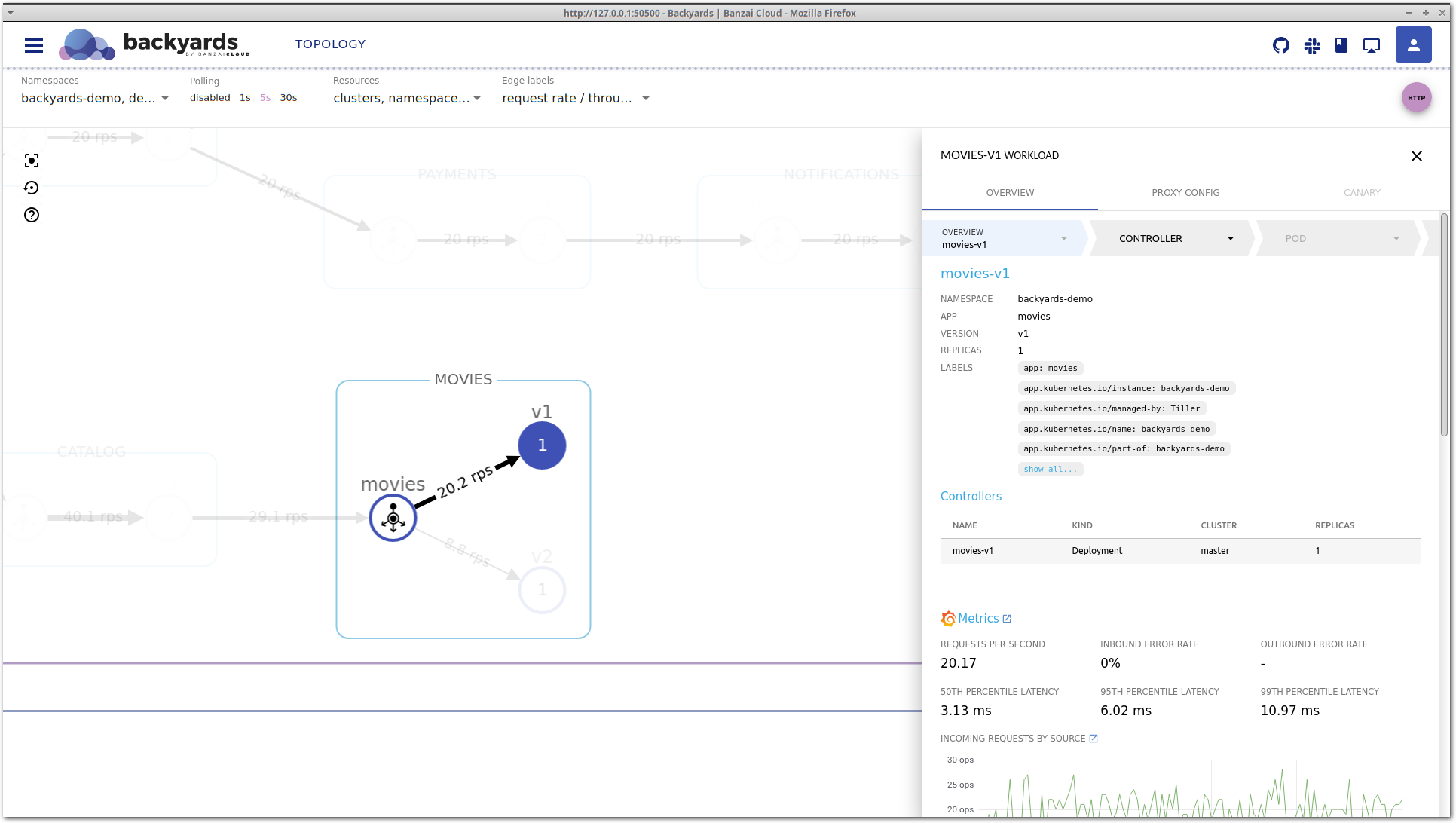
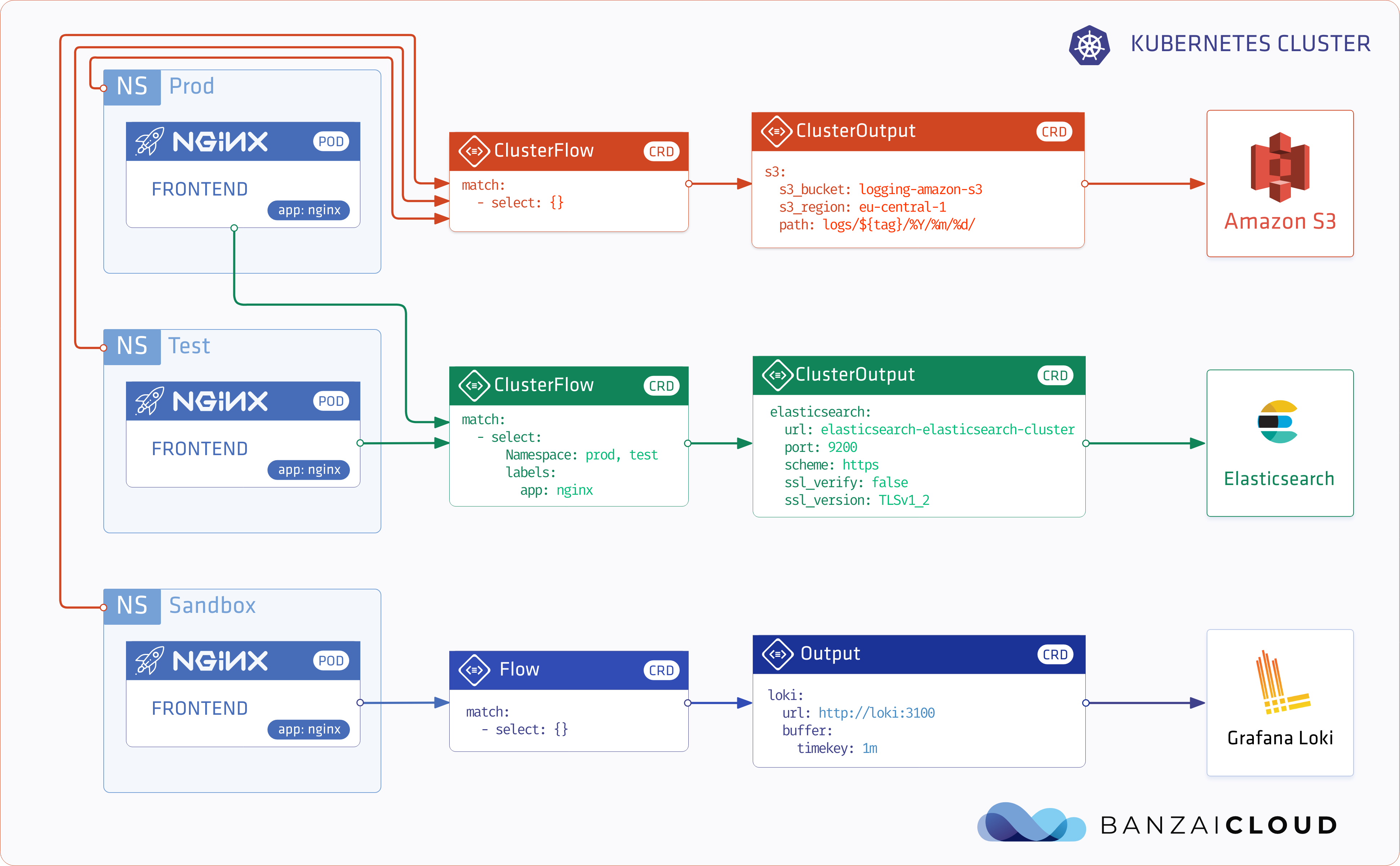
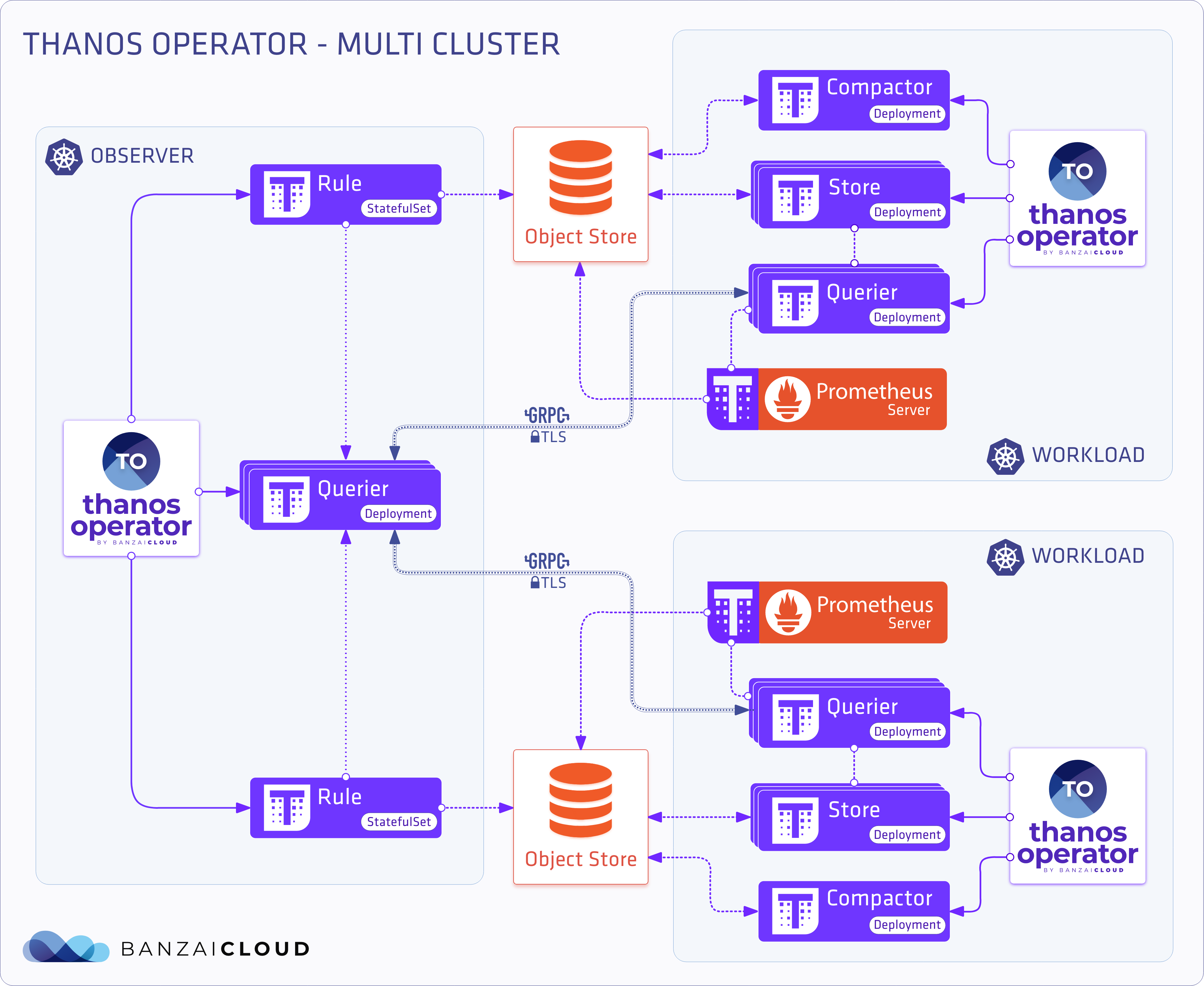
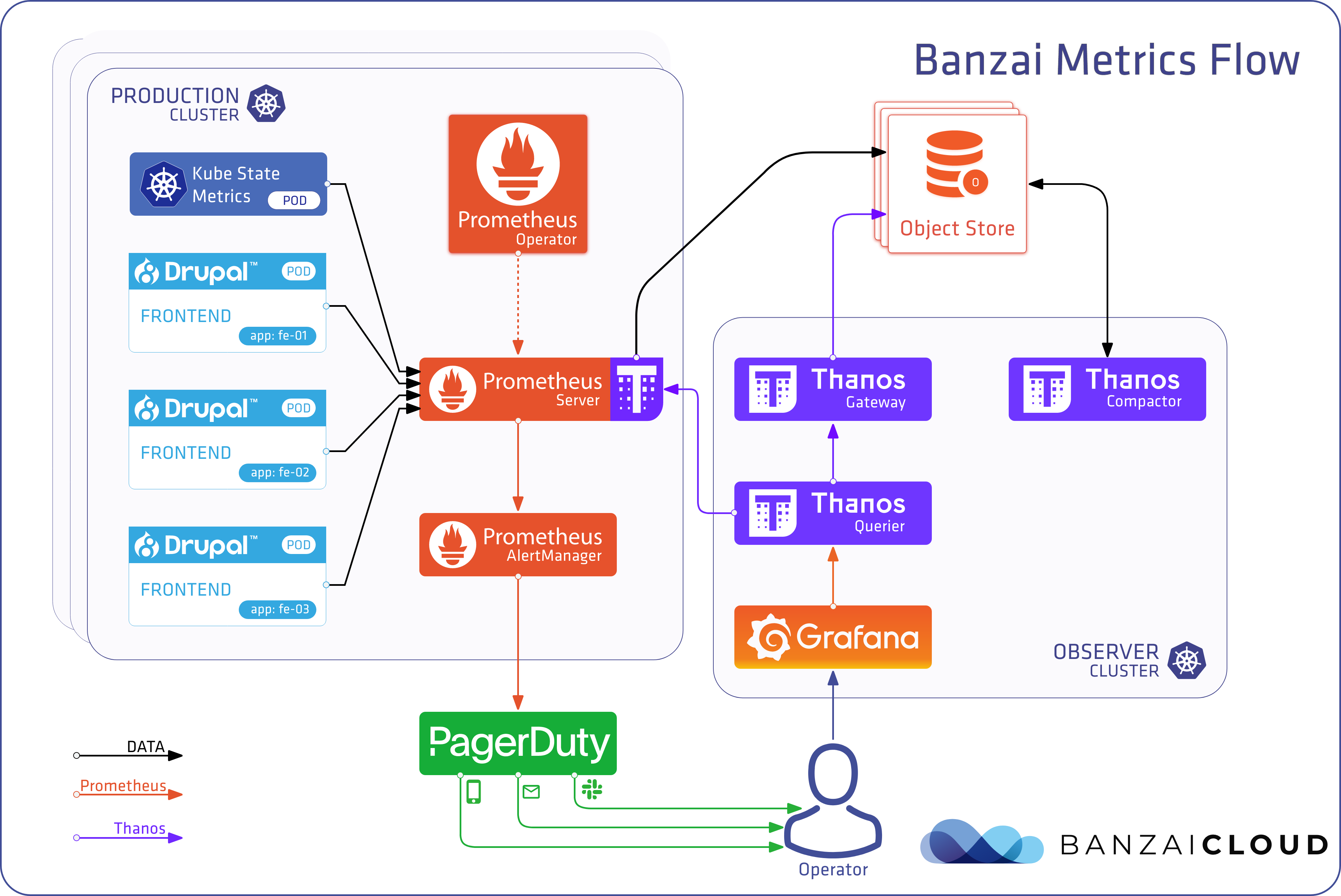
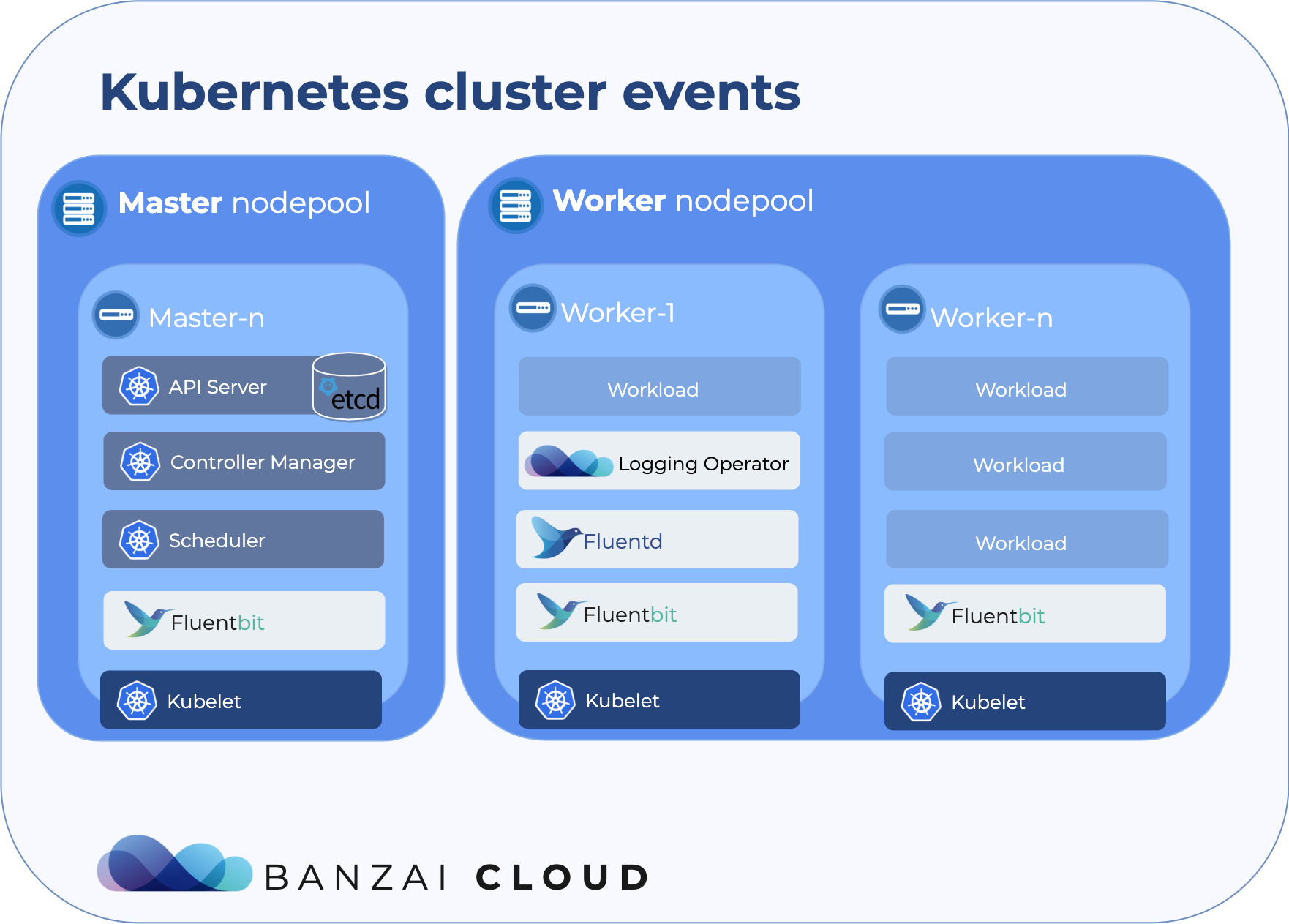
If you’ve been reading our blog you already know that we’re passionate about observability. We are convinced that the key to operating a reliable system is to know what happens where, and the correlated ability to rapidly dissect issues as they emerge. In previous posts we’ve gone over the base components of our suggested stack, which includes Prometheus, Thanos, Fluentd, Fluentbit, and many others. We’ve created several tools and operators to ease the management of these components, like the Istio operator, Logging operator, Thanos operator as well as using some other very popular operators, like the Prometheus one.
READ ARTICLE


Sun, May 10, 2020