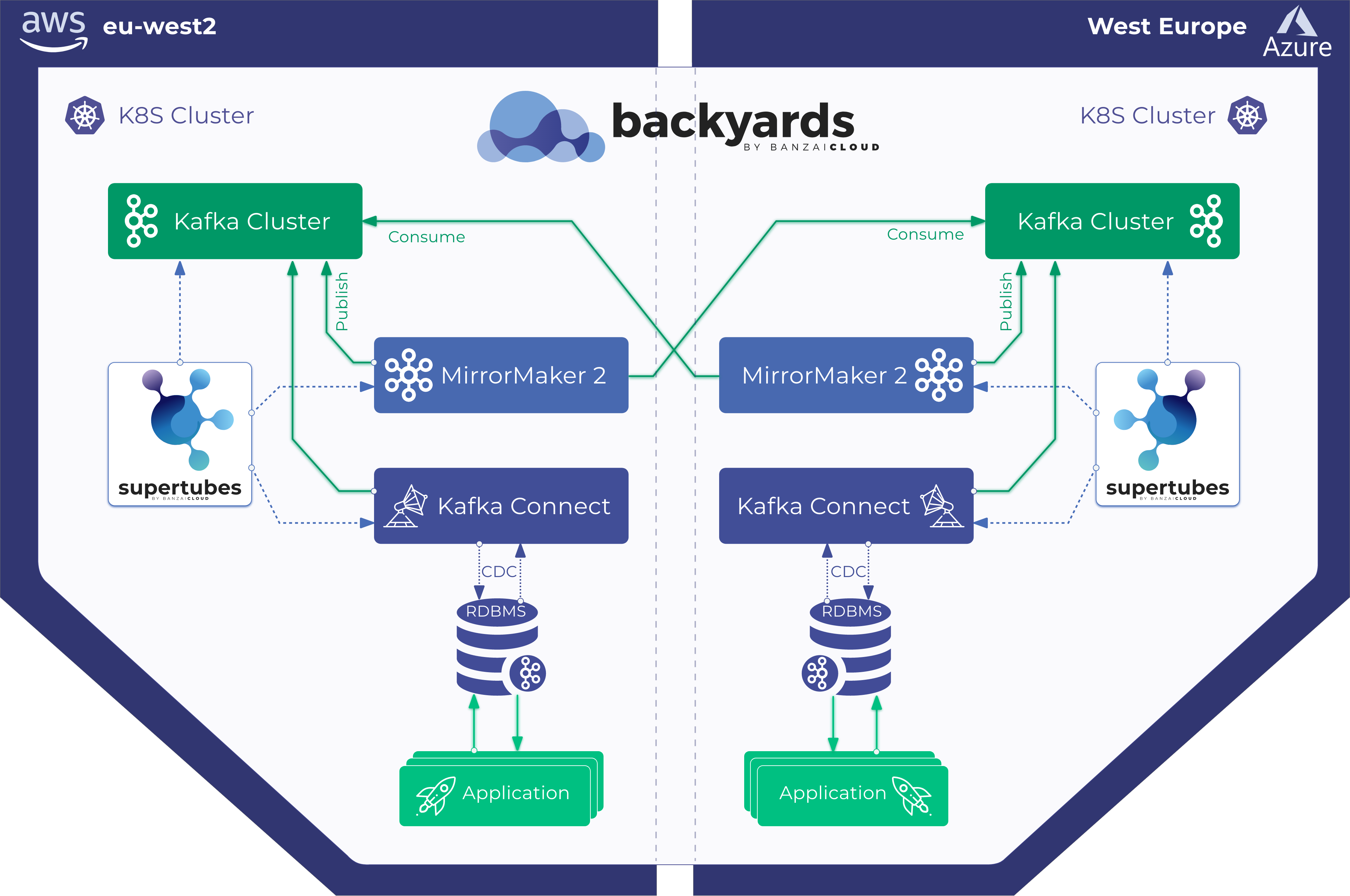
One of the key features of our container management platform, Pipeline, as well as our CNCF certified Kubernetes distribution, PKE, is their ability to form and run seamlessly across multi- and hybrid-cloud environments. While the needs of Pipeline users vary depending on whether they employ a single or multi-cloud approach, they usually build upon one or more of these key features:
- Multi-cloud application management
- An Istio based automated service mesh for multi and hybrid cloud deployments
- Federated resource and application deployments built on Kubernetes federation v2
As Istio operator-based multi-cluster and multi/hybrid-cloud adoption increased, so did the demand for the ability to run distributed or decentralized applications wired into a service mesh. One of the managed applications our customers run at scale on Kubernetes is Apache Kafka. We believe that the easiest way to run Apache Kafka on Kubernetes is to use Banzai Cloud’s Supertubes, built on our Koperator . However, our focus so far has been on automating and operating single cluster Kafka deployments.
tl;dr: 🔗︎
- We’ve added the support necessary to run Apache Kafka over Istio (using our Kafka and Istio operator, and orchestrated by Pipeline).
- Running Kafka over Istio does not add performance overhead (other than what is typical of mTLS, which is the same as running Kafka over SSL/TLS).
- With Pipeline, you can now create Kafka clusters across multi-cloud and hybrid-cloud environments.
- Follow the Right-sizing Kafka clusters on Kubernetes if you are interested in how to properly size your Kafka clusters
- Would you like to run Apache Kafka over Istio the easy way - try Supertubes.
Check out Supertubes in action on your own clusters:
Register for an evaluation version and run a simple install command!
As you might know, Cisco has recently acquired Banzai Cloud. Currently we are in a transitional period and are moving our infrastructure. Contact us so we can discuss your needs and requirements, and organize a live demo.
Evaluation downloads are temporarily suspended. Contact us to discuss your needs and requirements, and organize a live demo.
supertubes install -a --no-demo-cluster --kubeconfig <path-to-k8s-cluster-kubeconfig-file>or read the documentation for details.
Take a look at some of the Kafka features that we’ve automated and simplified through Supertubes and the Koperator , which we’ve already blogged about:
- Oh no! Yet another Kafka operator for Kubernetes
- Monitor and operate Kafka based on Prometheus metrics
- Kafka rack awareness on Kubernetes
- Running Apache Kafka over Istio - benchmark
- User authenticated and access controlled clusters with the Koperator
- Kafka rolling upgrade and dynamic configuration on Kubernetes
- Envoy protocol filter for Kafka, meshed
- Right-sizing Kafka clusters on Kubernetes
- Kafka disaster recovery on Kubernetes with CSI
- Kafka disaster recovery on Kubernetes using MirrorMaker2
- The benefits of integrating Apache Kafka with Istio
- Kafka ACLs on Kubernetes over Istio mTLS
- Declarative deployment of Apache Kafka on Kubernetes
- Bringing Kafka ACLs to Kubernetes the declarative way
- Kafka Schema Registry on Kubernetes the declarative way
- Announcing Supertubes 1.0, with Kafka Connect and dashboard
Metrics preview for a 3 broker 3 partition and 3 replication factor scenario with producer ACK set to all:
Single Cluster Results 🔗︎
| Kafka cluster | Google GKE avg. disk IO / broker |
Amazon EKS avg. disk IO / broker |
|---|---|---|
| Kafka | 417MB/s | 439MB/s |
| Kafka with SSL/TLS | 274MB/s | 306MB/s |
| Kafka with Istio | 417MB/s | 439MB/s |
| Kafka with Istio and mTLS | 323MB/s | 340MB/s |
Multi Cluster Results 🔗︎
| Kafka clusters with Istio mTLS | Avg. disk IO / broker | Avg. latency between clusters |
|---|---|---|
| GKE eu-west1 <-> GKE eu-west4 | 211MB/s | 7 ms |
| EKS eu-north1 <-> EKS eu-west1 | 85MB/s | 24 ms |
| EKS eu-central1 <-> GKE eu-west3 | 115MB/s | 2 ms |
If you want to take a deep dive into the stats involved, all that data is available here.
Running Kafka over an Istio service mesh 🔗︎
There is considerable interest within the Kafka community in the possibility of leveraging more Istio features via out-of-the-box tracing, and mTLS through protocol filters, though these features have different requirements as reflected in Envoy, Istio and on a variety of other GitHub repos and discussion boards. While we’ve already covered most of these features with Supertubes in the Pipeline platform - monitoring, dashboards, secure communication, centralized log collection, autoscaling, Prometheus based alerts, automatic failure recoveries, etc - there was one important feature that we and our customers missed: network failures and multiple network topology support. We’ve previously handled these with Backyards (now Cisco Service Mesh Manager) and the Istio operator. Now, the time has arrived to explore running Kafka over Istio, and to automate the creation of Kafka clusters across single-cloud multi AZ, multi-cloud and especially hybrid-cloud environments.
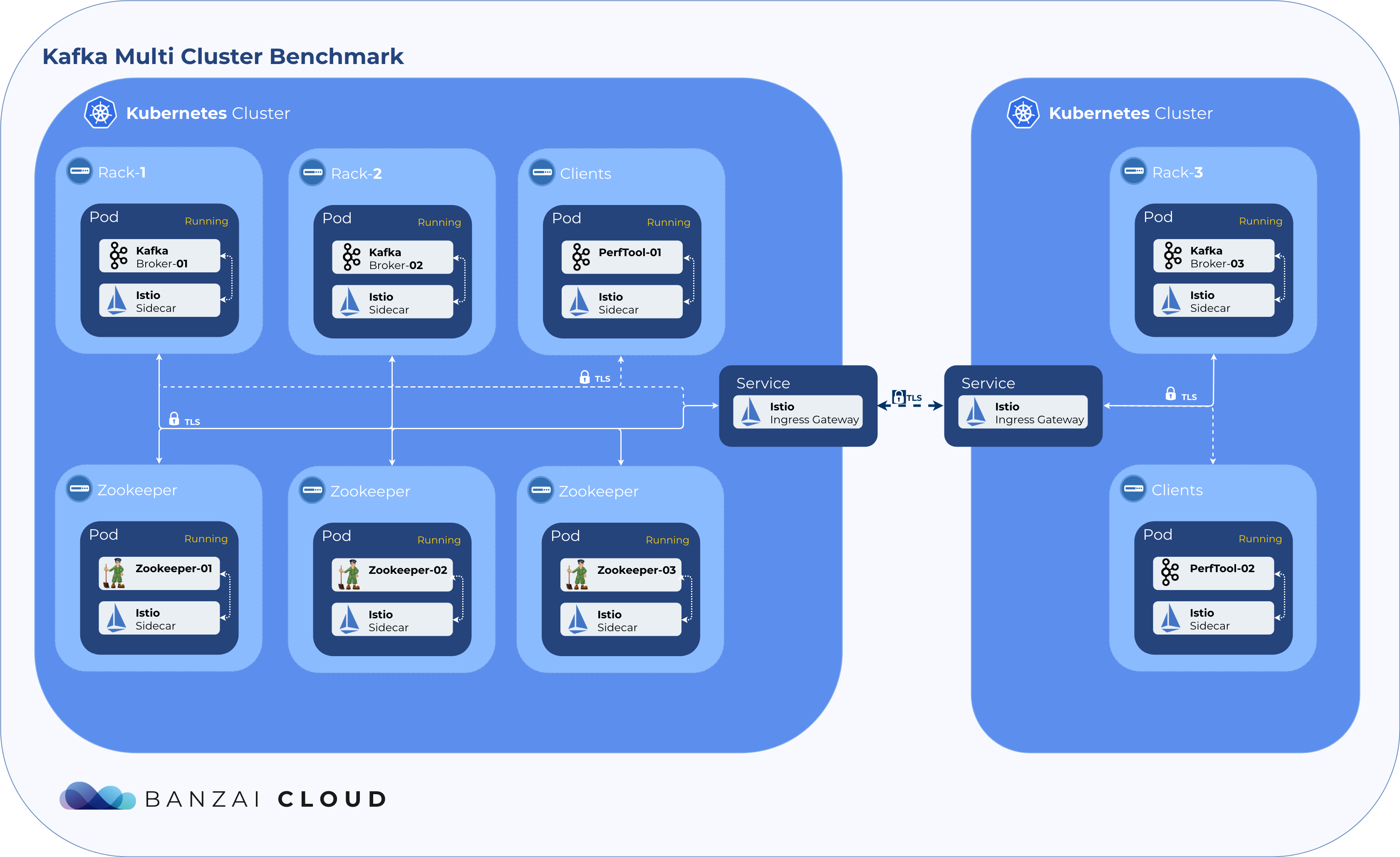
Getting Kafka to run on Istio wasn’t easy; it took time and required heavy expertise in both Kafka and Istio. With more than a little hard work and determination, we accomplished what we set out to do. Then, because that’s how we roll, we automated the whole process to make it as smooth as possible on the Pipeline platform. For those of you who’d like to go through the work and learn the gotchas - the what’s whats, the ins and outs - we’ll be following up with a deep technical dive in another post soon. Meanwhile, feel free to check out the relevant GitHub repositories.
The cognitive bias 🔗︎
Cognitive bias is an umbrella term that refers to the systematic ways in which the context and framing of information influence individuals’ judgment and decision-making. There are many kinds of cognitive biases that influence individuals differently, but their common characteristic is that—in step with human individuality—they lead to judgment and decision-making that deviates from rational objectivity.
Since releasing the Istio operator, we’ve found ourselves in the middle of a heated debate over Istio. We had already witnessed a similar course of events with Helm (and Helm 3), and we rapidly came to realize that many of the most passionate opinions on this subject were not based on first hand experience. While we sympathize with some of the issues people have with the Istio’s complexity - this was exactly our rationale behind open sourcing our Istio operator and the release of our Backyards (now Cisco Service Mesh Manager) product - we don’t really agree with most performance-related arguments. Yes, Istio has lots of convenient features you may or may not need and some of these might come with some added latency, but the question is, as always, is it worth it?
Note: yes, we’ve witnessed Mixer performance degradation and other issues while running a large Istio cluster with lots of microservices, policy enforcements, and raw telemetry data processing, and we share concerns about these; the Istio community is working on a
mixerlessversion - with features mostly pushed down to Envoy.
Be objective, measure first 🔗︎
Before we could reach a consensus about whether or not to release these features to our customers, we decided to conduct a performance test. We did this using several test scenarios for running Kafka over an Istio-based service mesh. As you might be aware, Kafka is a data intensive application, so we wanted to test it with and without Istio, in order to measure its added overhead. Additionally, we’ve been interested in how Istio handles data intensive applications, where there is a constant high I/O throughput and all its components are maxed out.
We used a new version of our Koperator , which provides native support for Istio-based service meshes (version >=0.5.0).
Benchmark Setup 🔗︎
To validate our multi cloud setup we decided to benchmark Kafka first with various single Kubernetes cluster scenarios:
- Single Cluster 3 broker 3 topic with 3 partition and replication-factor set to 3 TLS disabled
- Single Cluster 3 broker 3 topic with 3 partition and replication-factor set to 3 TLS enabled
These setups were necessary to check Kafka’s actual performance in a chosen environment, without potential Istio overhead.
To benchmark Kafka we decided to use the two most popular cloud provider managed Kubernetes solutions, Amazon EKS and Google GKE. We wanted to minimize the configuration surface and any potential CNI configuration missmatches, so we decided to use cloud provider-managed K8s distributions.
In another post we’ll be releasing benchmarks for hybrid-cloud Kafka clusters, wherein we use our own Kubernetes distribution, PKE.
We wanted to simulate a use case we often seen on our Pipeline platform, so we distributed nodes across availability zones, with Zookeeper and clients in different nodes as well.
The following instance types were used:
Amazon EKS 🔗︎
| Broker | Zookeeper | Client |
|---|---|---|
| 3x r5.4xlarge | 3x c5.xlarge | 3x c5.2xlarge |
Just FYI, Amazon throttles small instance type disks IO after 30 minutes for the rest of the day. You can read more about that, here.
For storage we requested Amazon’s provisioned IOPS SSD(io1), which on the instances listed above can reach 437MB/s throughput, continuously.
Google GKE 🔗︎
| Broker | Zookeeper | Client |
|---|---|---|
| 3x n1-standard-16 | 3x n1-standard-2 | 4x n1-standard-8 |
For storage we requested Google’s pd-ssd, which can reach 400MB/s according to Google’s documentation.
Kafka and the Load Tool 🔗︎
For Kafka, we used 3 topics, with partition count and replication factor set to 3. For the purpose of testing we used default config values, except broker.rack,min.insync.replicas.
In the benchmark we used our custom built Kafka Docker image banzaicloud/kafka:2.12-2.1.1. It uses Java 11, Debian and contains Kafka version 2.1.1. The Kafka containers were configured to use 4 CPU cores and 12GB RAM, with a Java heap size of 10GB.
banzaicloud/kafka:2.12-2.1.1 image is based on the wurstmeister/kafka:2.12-2.1.1 image, but we wanted to use java 11 instead of 8, for SSL library improvements.
The load was generated using sangrenel, a small Go-based Kafka performance tool, configurated as follows:
- message size of 512 bytes
- no compression
- required-acks set to all
- workers set to 20
To get accurate results, we monitored the entire infrastructure using NodeExporter metrics visualized by Grafana dashboard 1860. We kept increasing the number of producing clients until we reached the infrastructure’s limit, or Kafka’s.
Creating the infrastructure for the benchmark is beyond the scope of this blog, but if you’re interested in reproducing it, we suggest using Pipeline and visiting the Koperator GitHub repo for more details.
Benchmarking the environment 🔗︎
Before getting into Kafka’s benchmark results, we also benchmarked our environments. As Kafka is an extremely data intensive application, we gave special focus to measuring disk speed and network performance; based on our experience, these are the metrics that most affect Kafka. For network performance, we used a tool called iperf. Two identical Ubuntu based Pods were created: one, a server, the other, a client.
- On Amazon EKS we measured
3.01 Gbits/secof throughput. - On Google GKE we measured
7.60 Gbits/secof throughput.
To determine the disk speed we used a tool called dd on our Ubuntu based containers.
- We measured
437MB/son Amazon EKS (this is exactly inline with what Amazon offers for that instance and ssd type). - We measured
400MB/son Google GKE (this is also inline with what Google offers for its instance and ssd type).
Now that we have a better understanding of our environments, let’s move on to Kafka clusters deployed to Kubernetes.
Single Cluster 🔗︎
Google GKE 🔗︎
Kafka on Kubernetes - without Istio 🔗︎
After the results we got on EKS, we were not surprised that Kafka maxed disk throughput and hit 417MB/s on GKE. That performce was limited by the instance’s disk IO.
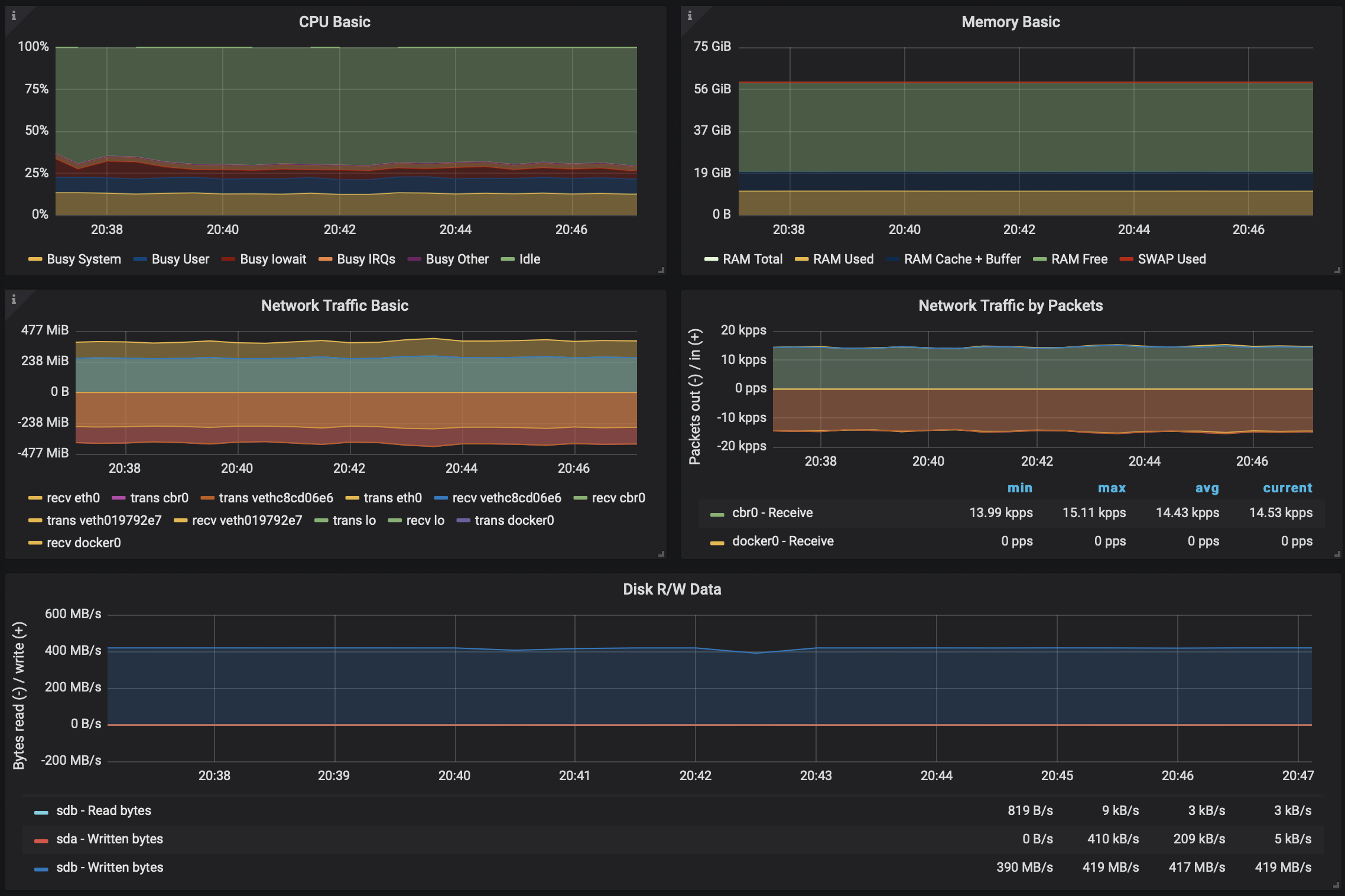
Kafka on Kubernetes with TLS - still without Istio 🔗︎
Once we switch on SSL/TLS for Kafka, as expected and as has been benchmarked many times, a performance loss occured. Java’s well known for the poor performance of its SSL/TLS (otherwise pluggable) implementatation, and for the performace issues it causes in Kafka. However, there have been improvements in recent implementations (9+), accordingly, we upgraded to Java 11. Still, the results were as follows:
274MB/sthroughput ~30% throughput loss- an increase of ~2x in the packet rate, compared to non TLS
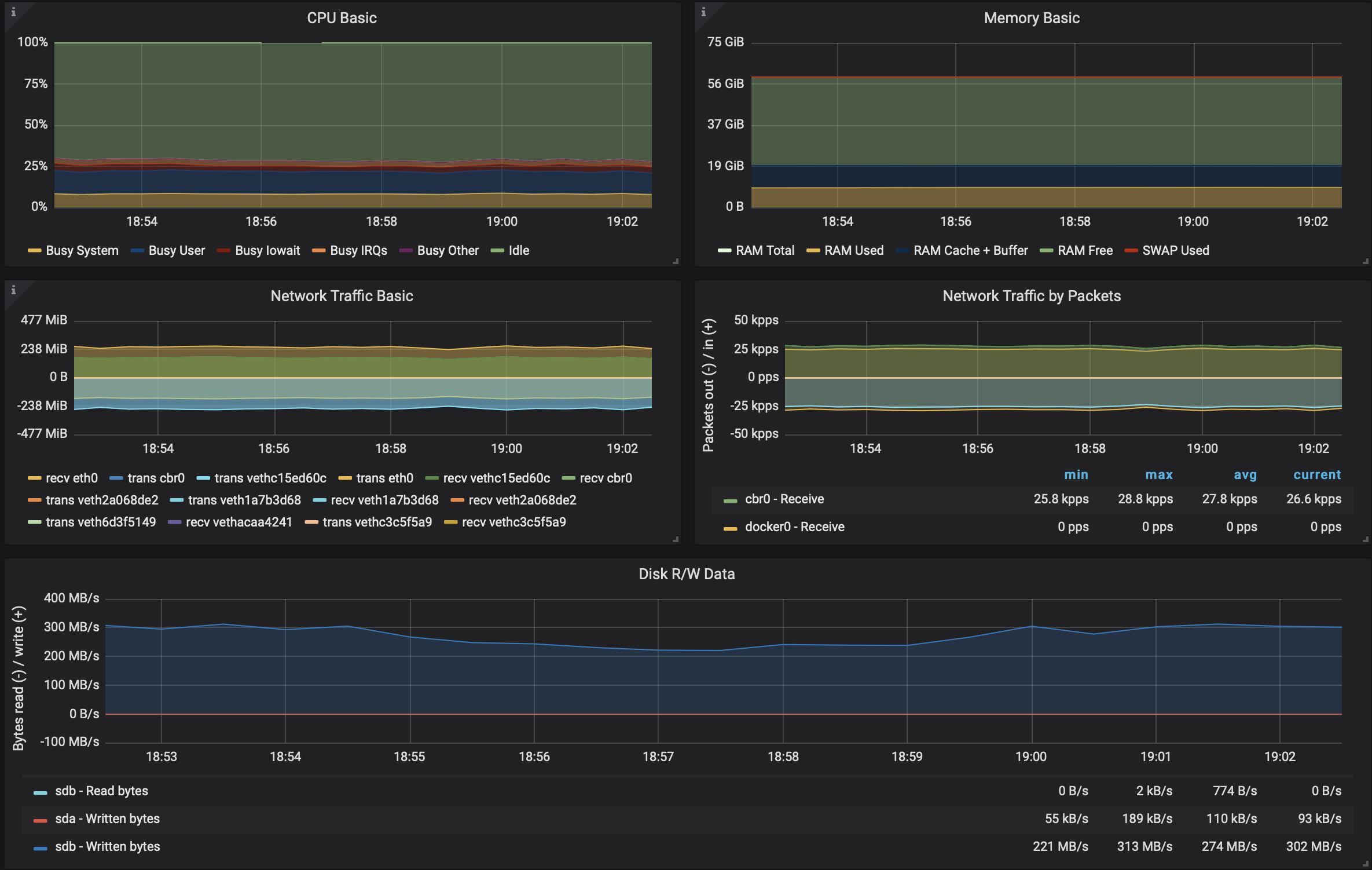
Kafka on Kubernetes - with Istio 🔗︎
We were eager to see whether there was any added overhead and performance loss when we deployed and used Kafka in Istio. The results were promising:
- No performance loss
- Again slight increase on the CPU side
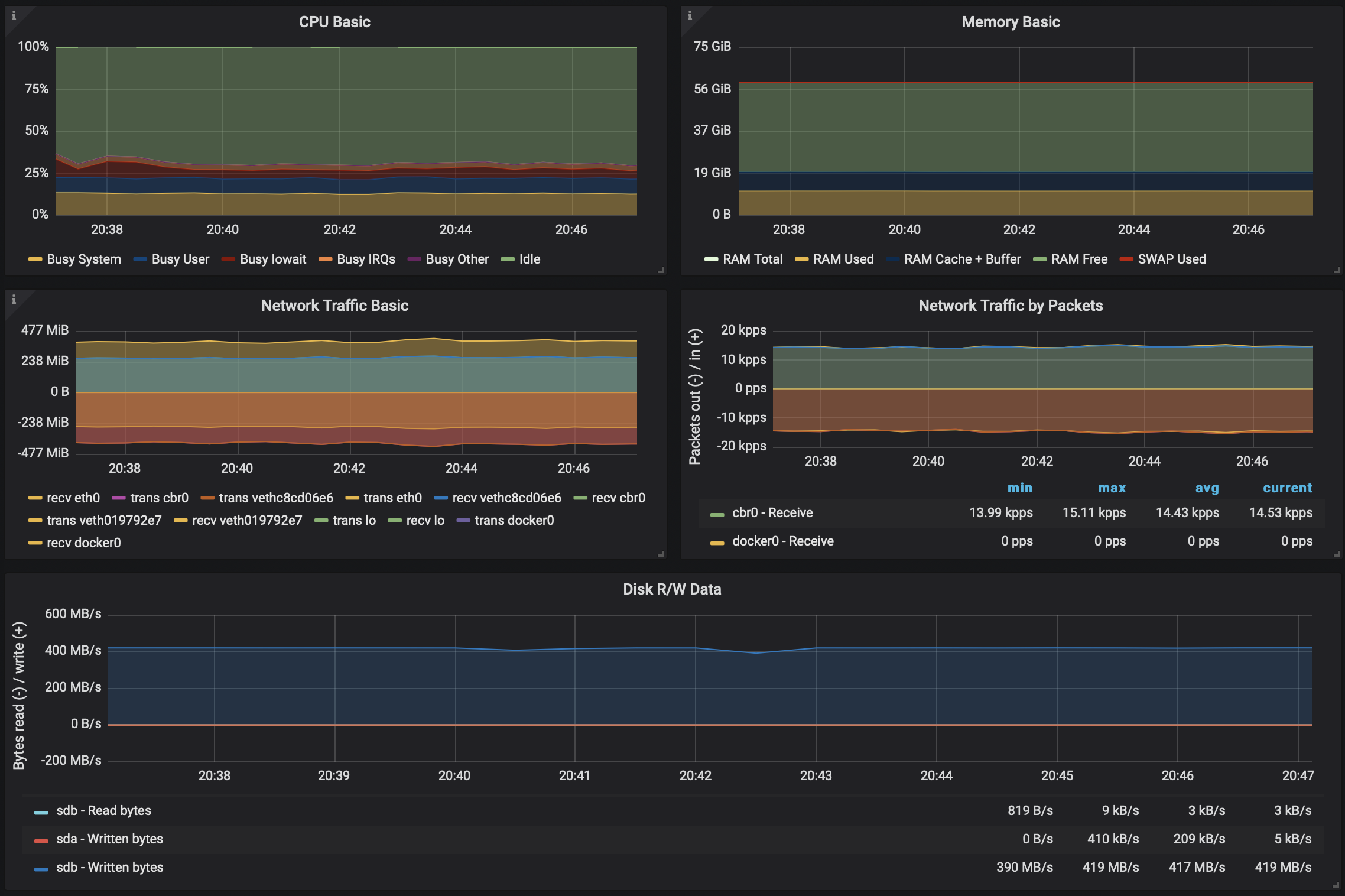
Kafka on Kubernetes - with Istio and mTLS enabled 🔗︎
Next we enabled mTLS on Istio and reused the same Kafka deployment. The results are better than they were for the Kafka on Kubernetes with SSL/TLS scenario.
323MB/sthroughput ~20% throughput loss- ~2x packet rate increase compared to non TLS

Amazon EKS 🔗︎
Kafka on Kubernetes - without Istio 🔗︎
With this setup we achieved a considerble write rate of 439MB/s, which, if messages are 512 bytes, is 892928 Messages/second. In point of fact, we maxed out the disk throughput provided by AWS for the r5.4xlarge instance type.
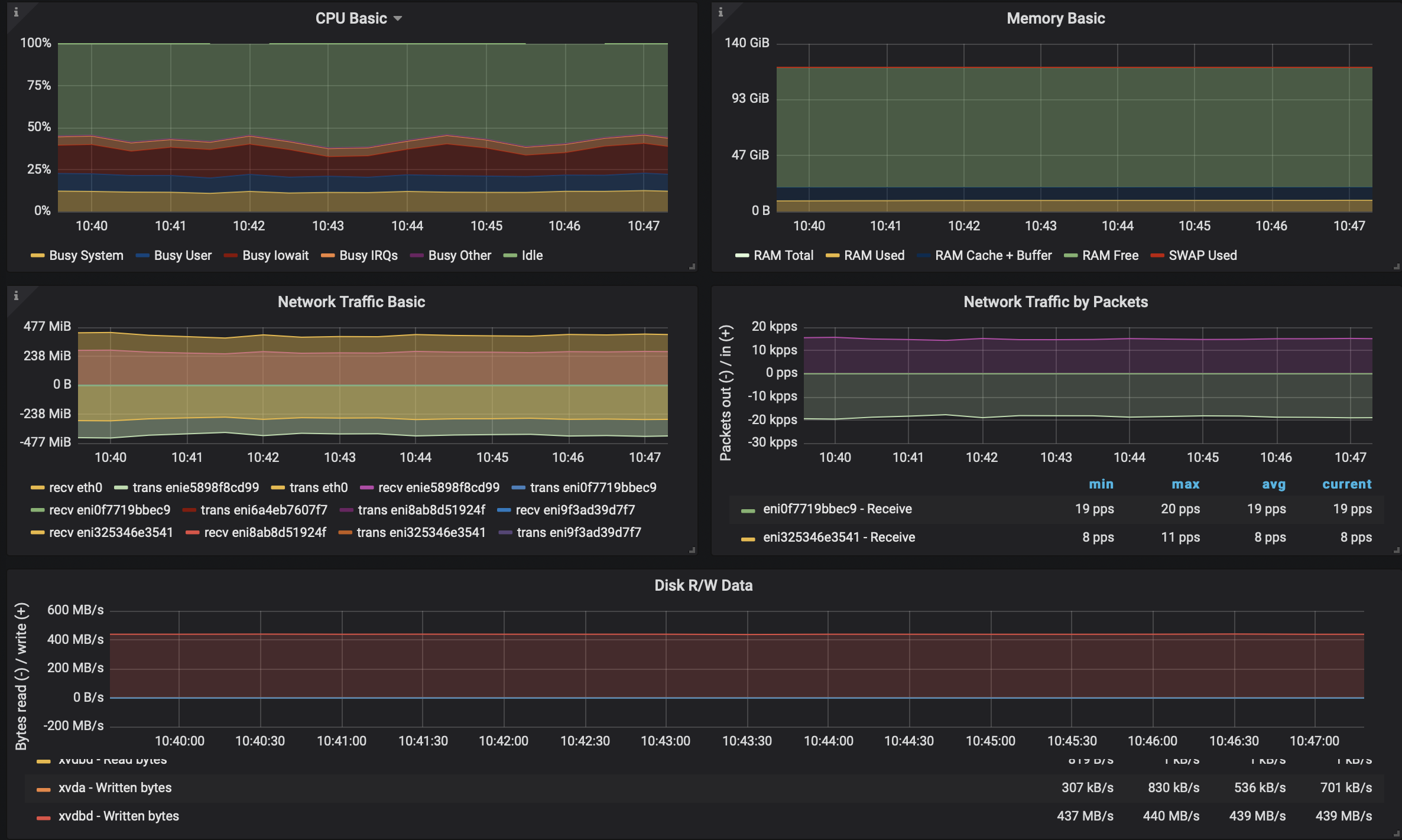
Kafka on Kubernetes with TLS - still without Istio 🔗︎
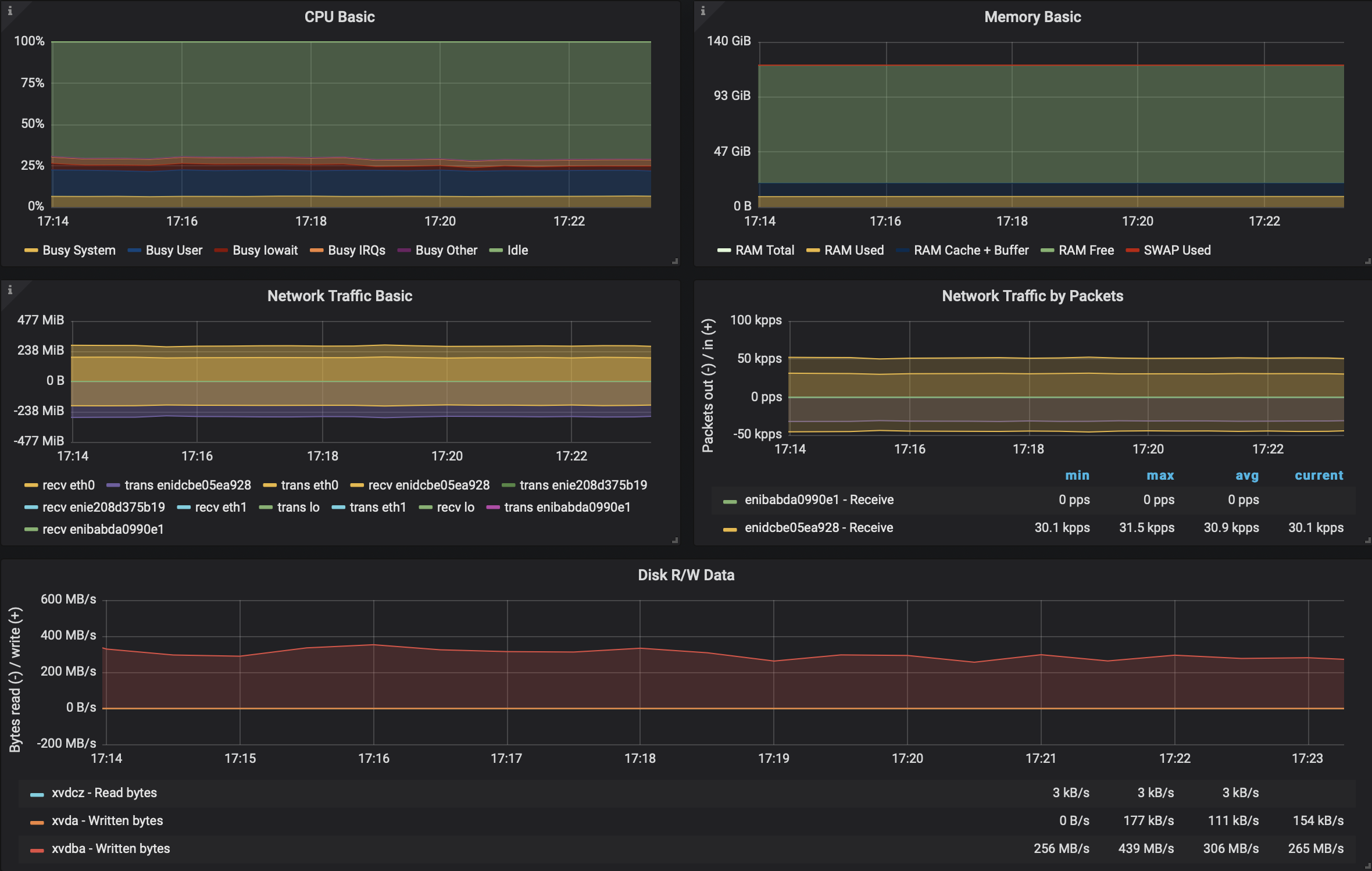
Once we switched on SSL/TLS for Kafka, again, as was expected and has been benchmarked many times, a performance loss occured. Java’s SSL/TLS implementatation performance issues are just as relevant on EKS as on GKE. However, like we said, there have been improvements in recent implementations. Accordingly, we upgraded to Java 11 but the results were as follows:
306MB/sthroughput, which is a ~30% throughput loss- an increase in ~2x packet rate, compared to non TLS scenarios
Kafka on Kubernetes - with Istio 🔗︎
Again, just as before, the results were promising:
- no performance loss occured
- there was a slight increase on the CPU side
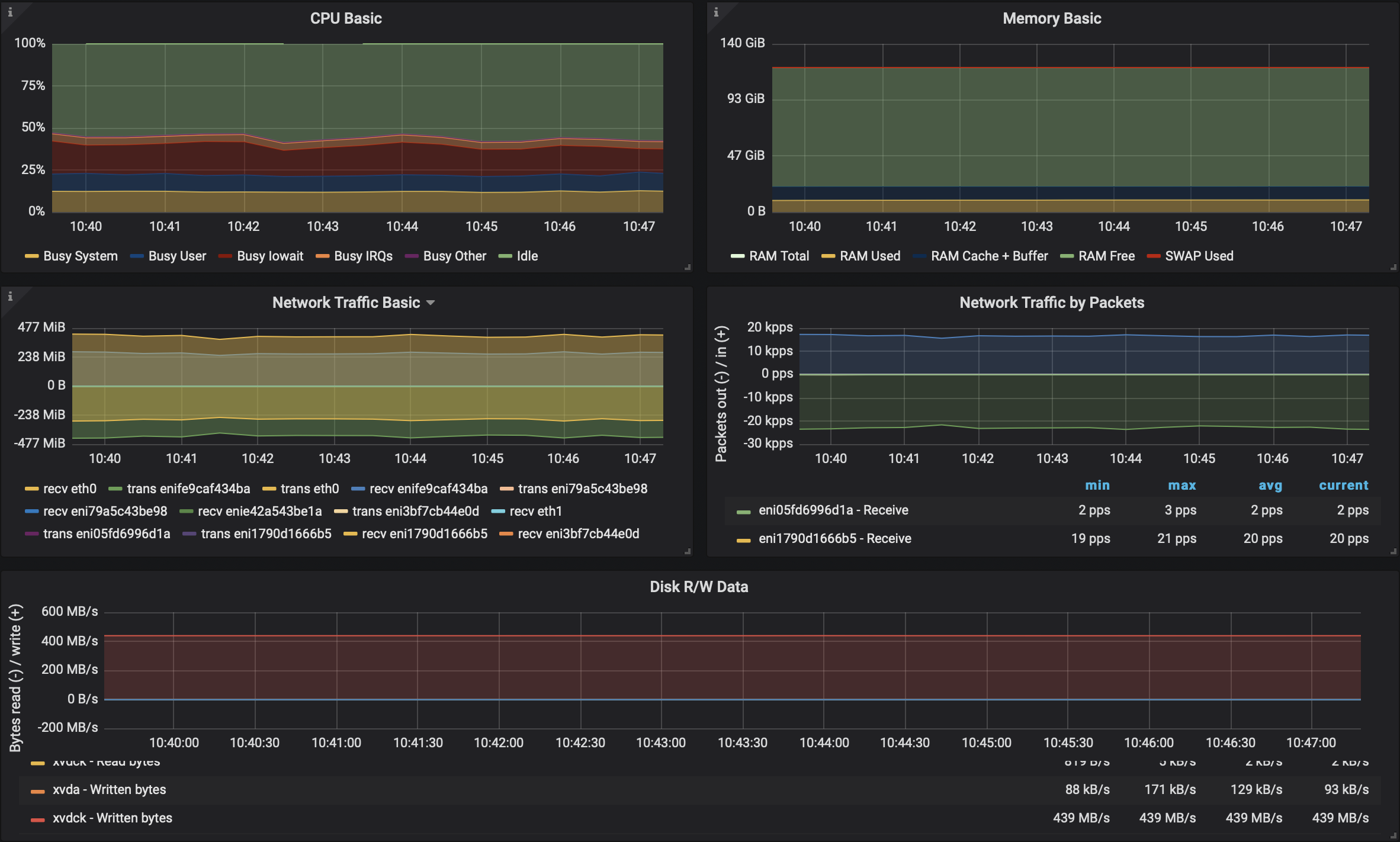
Kafka on Kubernetes - with Istio and mTLS enabled 🔗︎
Next we enabled mTLS on Istio and reused the same Kafka deployment. The results, again, are better than for Kafka on Kubernetes with SSL/TLS.
340MB/sthroughput, which is a throughput loss of around 20%- increased packet rate, but lower than a factor of ~2x
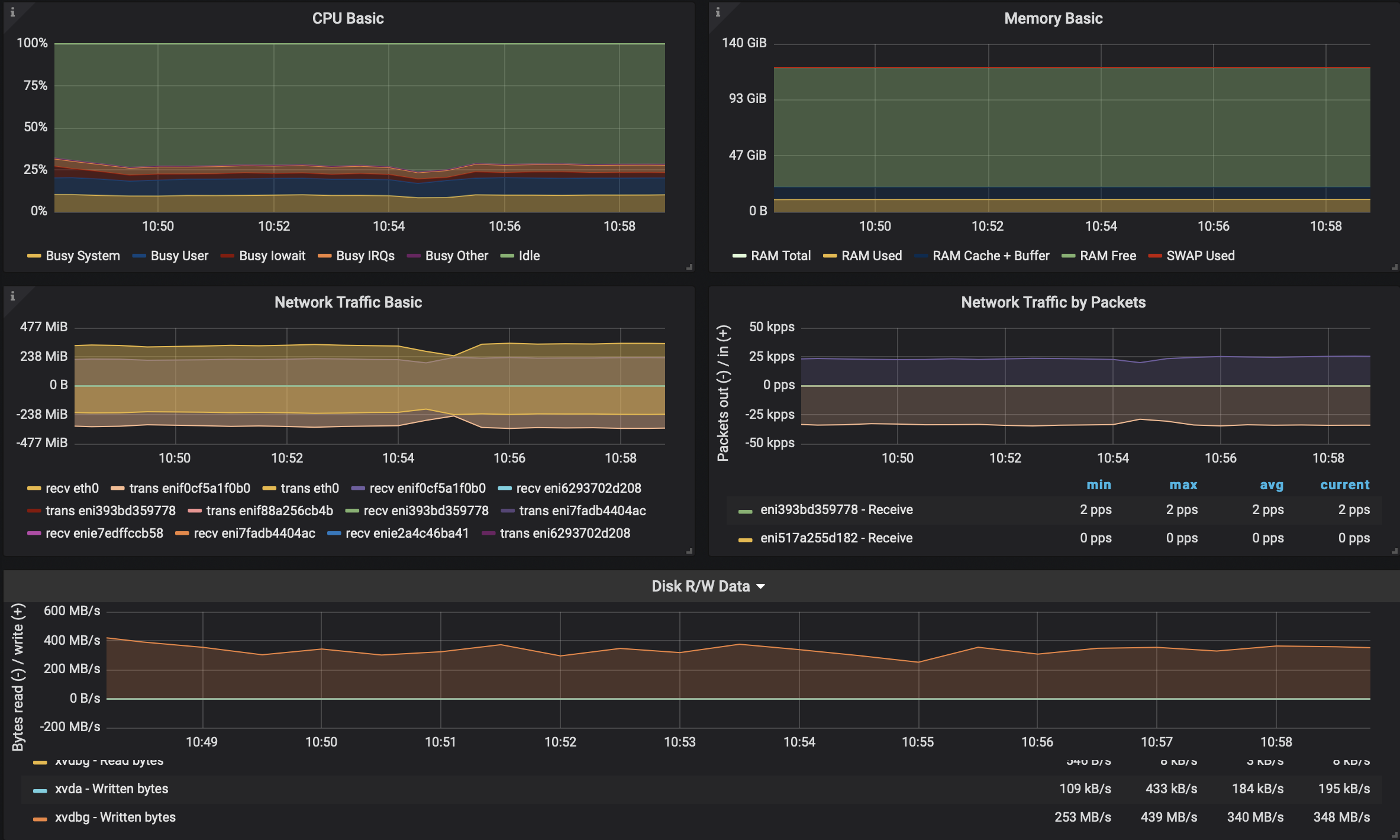
Bonus track - Kafka on Linkerd (without mTLS) 🔗︎
We always test all our available options, so we wanted to give this a try with Linkerd. Why? Because we could. While we know that Linkerd can’t meet our customers’ expectations in terms of available features, we still wanted to give it a try. Our expectations were high, but the numbers produced gave us a hard lesson and a helpful reminder in what, exactly, cognitive bias is.
246MB/sthroughput
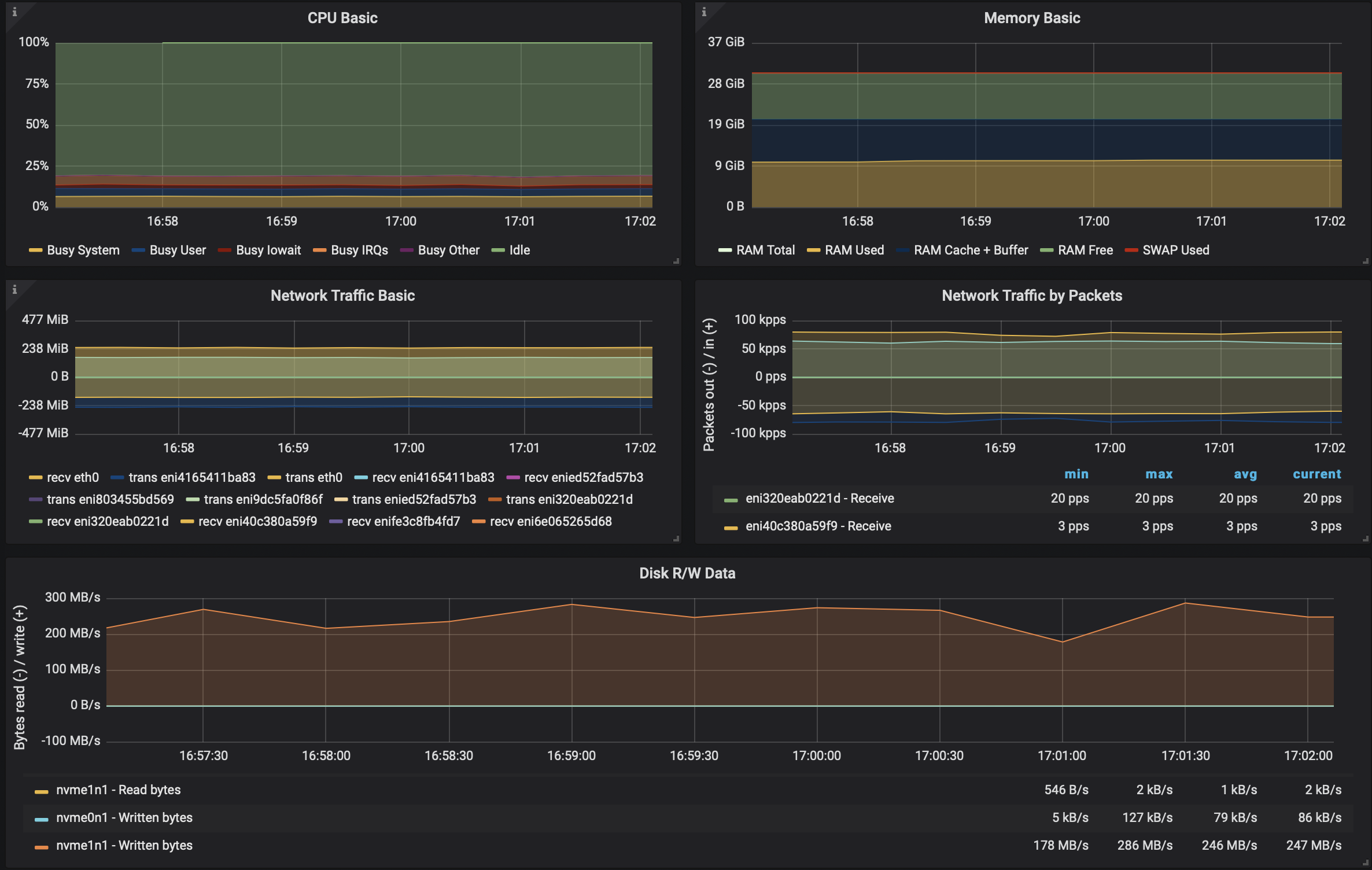
Single Cluster conclusion 🔗︎
Before we move on to our multi-cluster benchmark, let’s evaluate the numbers we have already. We can tell that, in these environments and scenarios, using service mesh without mTLS does not affect Kafka’s performance. The throughput of the underlying disk limits the performance before Kafka hits network, memory or cpu limits.
Using TLS creates a ~20% throughput degradation in Kafka’s performance, whether using Istio or Kafka’s own SSL/TLS lib. It slightly increases the CPU load and roughly doubles the number of packets transmitted over the network.
Note that just enabling the mTLS on the network caused a ~20% degredation during the infrastructure test with
iperfas well
Multi-cluster scenario with topics replicated across “racks” (cloud regions) 🔗︎
In this setup we are emulating something closer to production, wherein, for the sake of reusing environmental benchmarks, we stick with the same AWS or Google instances types, but set up multiple clusters on different regions (with topics replicated across cloud regions). Note that the process should be the same, whether we use these multiple clusters across a single cloud provider or across multiple or hybrid clouds. From the perspective of Backyards (now Cisco Service Mesh Manager) and the Istio operator there is no difference; we support 3 different network topologies.
One of the clusters is larger than the other, as it consists of 2 brokers and 2 Zookeeper nodes, whereas the other will have one of each. Note, in a single mesh multi-cluster environment enabling mTLS is an absolute must. Also, we set min.insync.replicas to 3 again and the producer ACK requirement to all for durability.
The mesh is automated and provided by the Istio operator.
Google GKE <-> GKE 🔗︎
In this scenario we created a single mesh/single Kakfa cluster that spanned two Google Cloud regions: eu-west1 and eu-west4
211MB/sthroughput
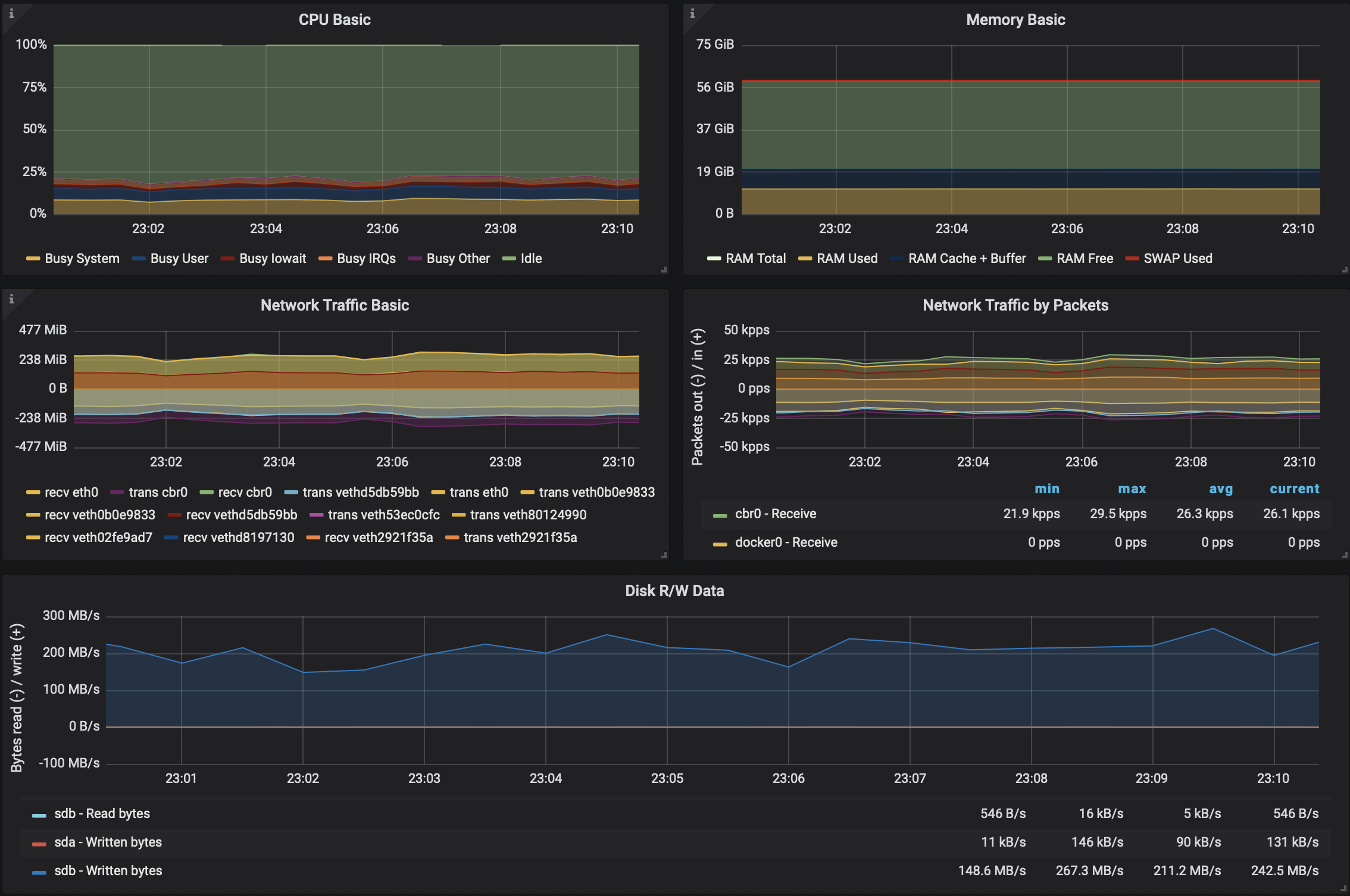
Amazon EKS <-> EKS 🔗︎
In this scenario we created a single mesh/single Kakfa cluster that spanned two AWS regions: eu-north1 and eu-west1
85MB/sthroughput
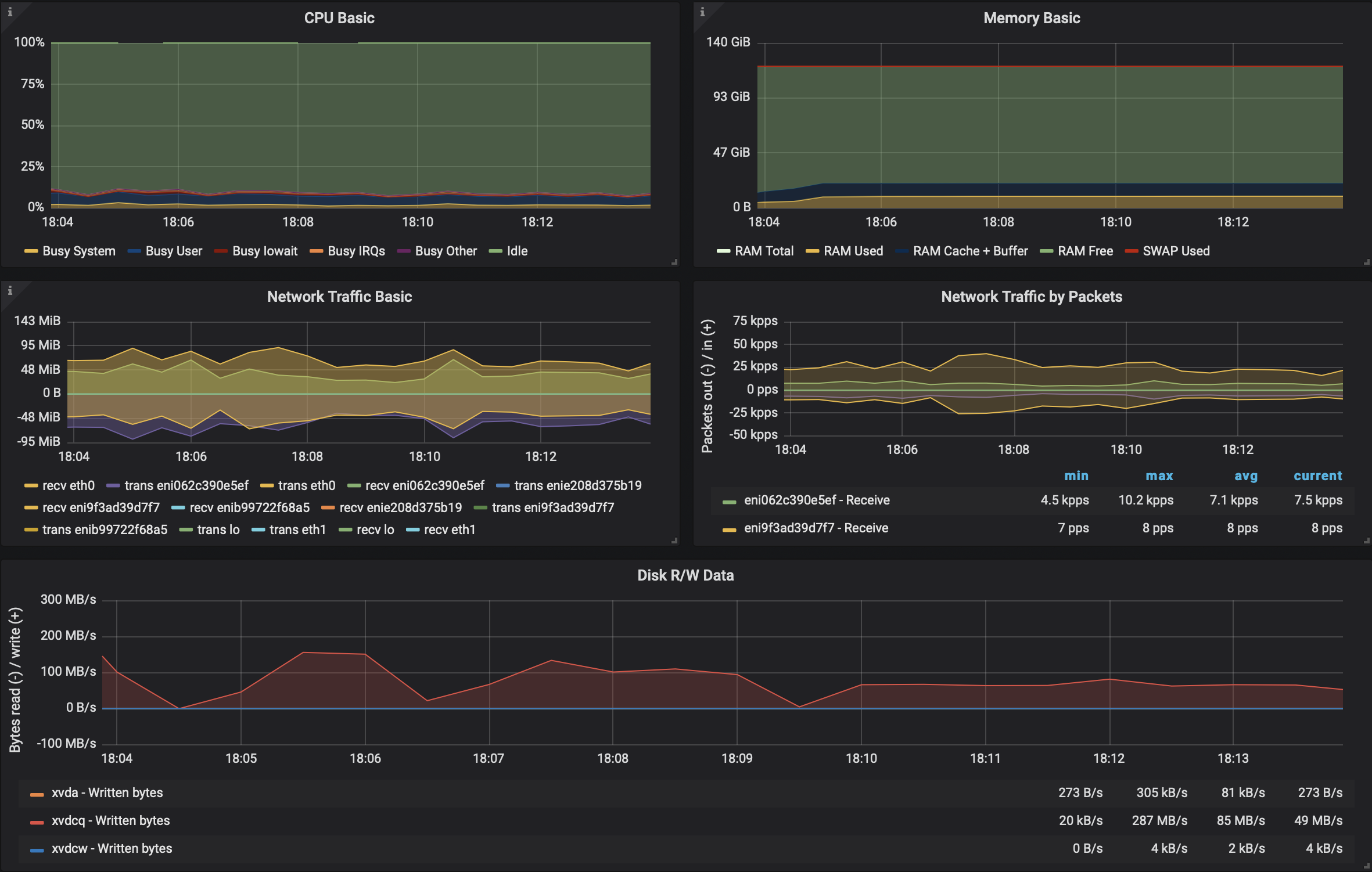
Google GKE <-> EKS 🔗︎
In this scenario we created a single Istio mesh, across multiple clusters that spanned multiple clouds, forming one single Kafka cluster (Google Cloud region is europe-west-3 and AWS region is eu-central-1). As expected, the results were considerably poorer.
115MB/sthroughput
Multi Cluster conclusion 🔗︎
From our benchmarks, we can safely say that it’s worth it to give using Kafka in a multi-cloud single-mesh environment a shot. People have different reasons for choosing an environment like Kafka over Istio, but the ease of setup with Pipeline, the additional security benefits, scalability and durability, locality based load balancing and lots more makes it a perfect choice.
As already mentioned, one of the next posts in this series will be be about benchmarking/operating an autoscaling hybrid-cloud Kafka cluster, wherein alerts and scaling events are based on Prometheus metrics (we do something similar for autoscaling based on Istio metrics for multiple applications, which we deploy and observe through the mesh - read this older post for details: Horizontal Pod Autoscaling based on custom Istio metrics.)
About Backyards 🔗︎
Banzai Cloud’s Backyards (now Cisco Service Mesh Manager) is a multi and hybrid-cloud enabled service mesh platform for constructing modern applications. Built on Kubernetes, our Istio operator and the Banzai Cloud Pipeline platform gives you flexibility, portability, and consistency across on-premise datacenters and on five cloud environments. Use our simple, yet extremely powerful UI and CLI, and experience automated canary releases, traffic shifting, routing, secure service communication, in-depth observability and more, for yourself.
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.
About Banzai Cloud 🔗︎
Banzai Cloud is changing how private clouds are built: simplifying the development, deployment, and scaling of complex applications, and putting the power of Kubernetes and Cloud Native technologies in the hands of developers and enterprises, everywhere.
#multicloud #hybridcloud #BanzaiCloud