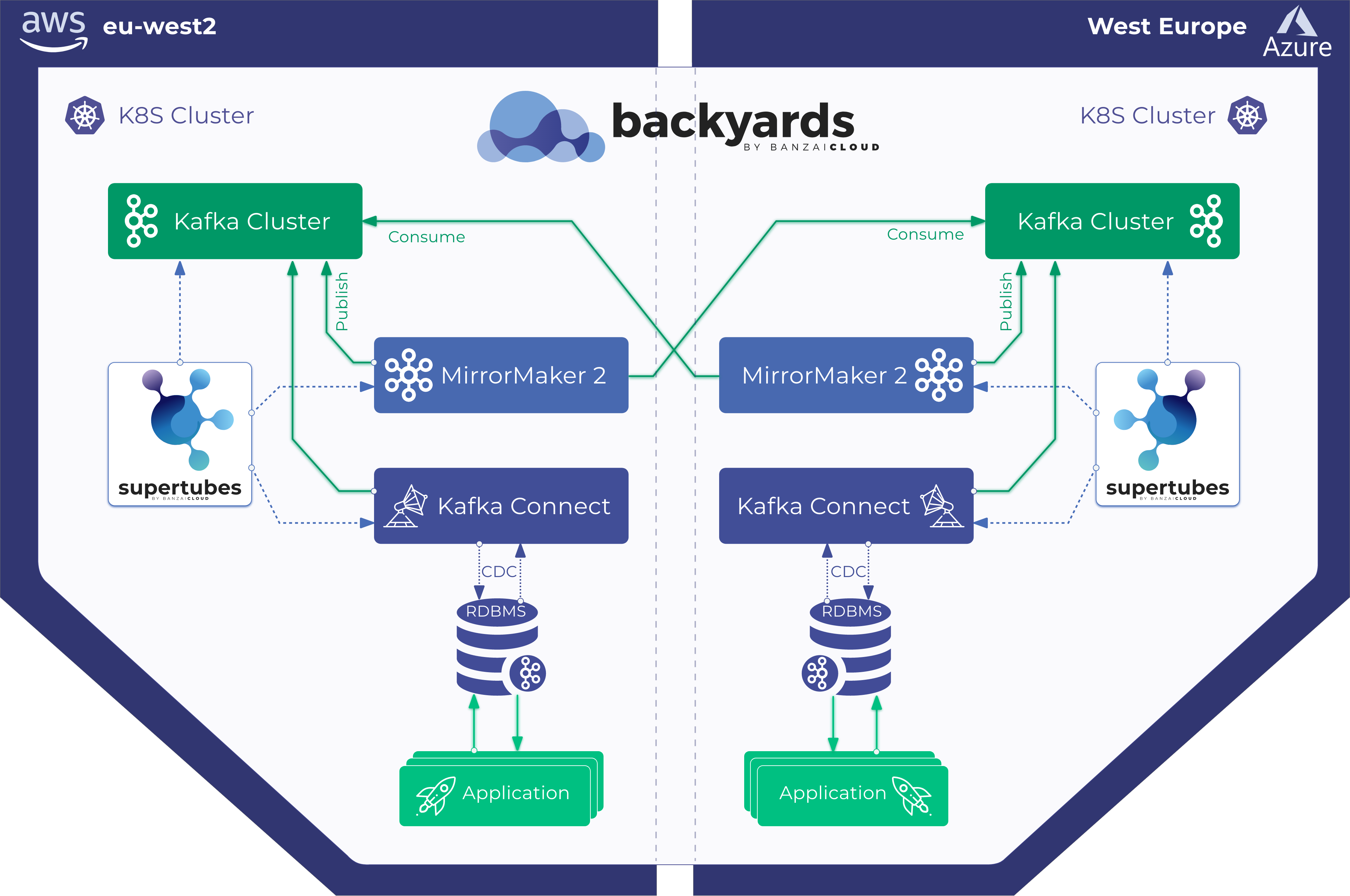
If you’re reading this post, you’re likely already familiar with our container management platform, Pipeline, and our CNCF certified Kubernetes distribution, PKE: you probably already know how we make it possible to spin up clusters across several cloud providers and on-premise, in multi-cloud but also hybrid-cloud environments. But whether these are single or multi-cluster topologies, resilience is key. We at Banzai Cloud believe this is the case not just for infrastructural components but for entire managed application environments, like Apache Kafka.
Accordingly, today we’ll be discussing rack awareness for Kafka on Kubernetes: how we automate it with the Koperator and why we consider it to be so vitally important, especially in multi-region and/or in hybrid-cloud environments.
Kafka’s rack awareness feature spreads replicas of the same partition across different failure groups (rack and availability zones). This extends the guarantees Kafka provides for broker-failure to cover rack and/or AZ failures, limiting the risk of data loss should all the brokers in a rack/AZ fail at once. With Pipeline we are also running some Kafka clusters spread across hybrid and multi-clouds using our Istio operator - we will be posting more details on metrics and network topologies very soon.
tl;dr: 🔗︎
- from version [0.4.1] onwards the Koperator supports rack awareness/failure groups for Kafka brokers
- when well-known labels are available (AZ, node labels, etc) the operator and the Banzai Cloud managed Kafka on Kubernetes strives to make broker resilience the default option
- Koperator allows fine grained broker rack configuration based on pod affinities and anti-affinities
Kafka rack awareness 🔗︎
Rack awareness in Kafka predates Kubernetes. However, due to the dynamic manner in which containerized applications are deployed, it’s changed and evolved a lot. Kafka automatically replicates partitions across brokers, so if a broker dies, the data is safely preserved on another. But what happens if a whole rack of computers running brokers starts to fail? Luckily, Kafka brokers have a configuration option called broker.rack.
When broker.rack is enabled, Kafka spreads replicas of a partition over different racks. This prevents the loss of data even when an entire rack goes offline at once. As the official Kafka documentation puts it, “it uses an algorithm which ensures that the number of leaders per broker will be constant, regardless of how brokers are distributed across racks. This ensures balanced throughput.” So what does this means in practice?
Note: this configuration is a read-only config, so it requires broker restarts whenever it’s updated.
Rack awareness, the cloud and Kubernetes 🔗︎
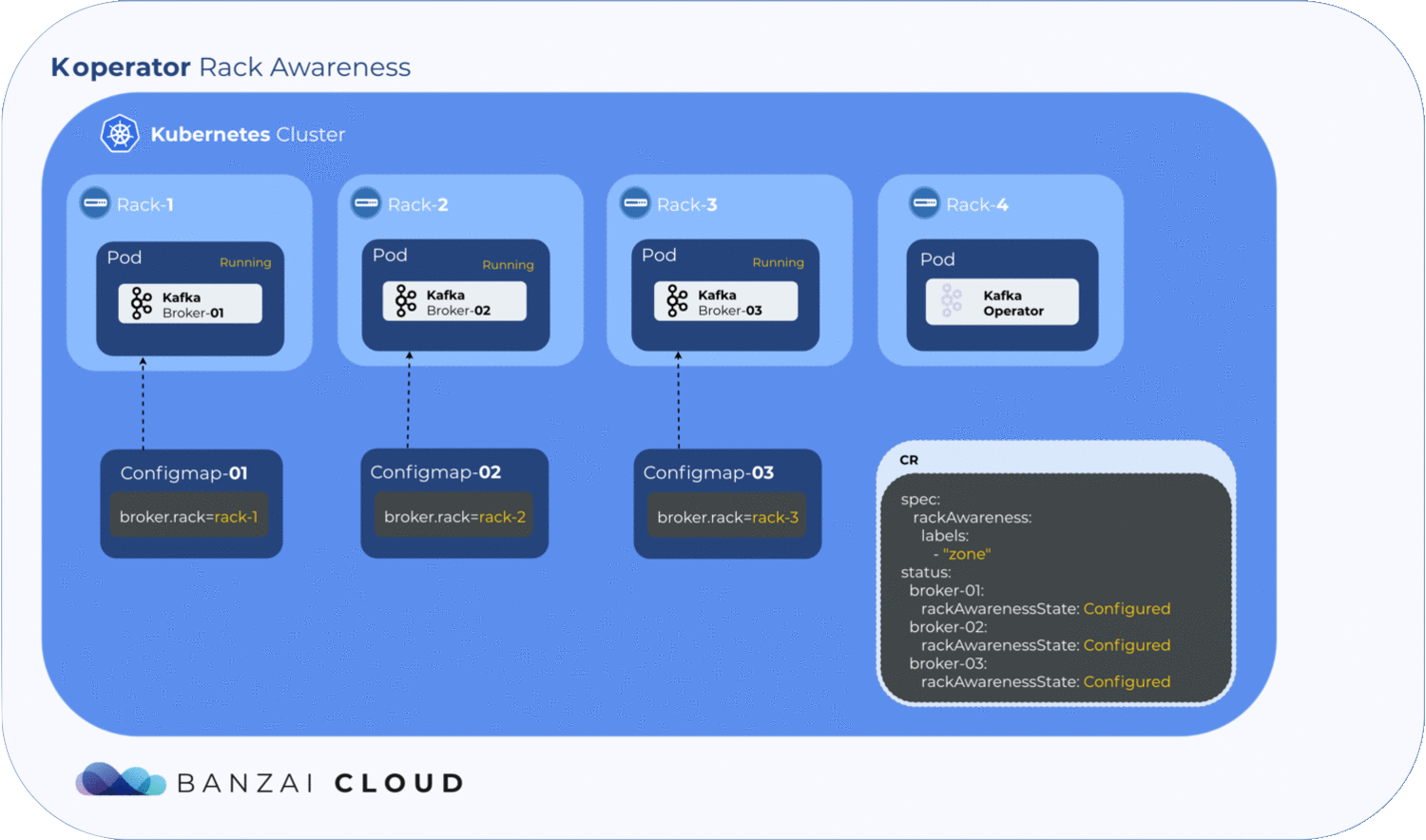
It is essential to use and configure this property in a cloud environment, since regions, nodes and network partitions may vary. Within the Koperator , we have extended the config CRD with the following:
rackAwareness:
labels:
- "failure-domain.beta.kubernetes.io/region"
- "failure-domain.beta.kubernetes.io/zone"
oneBrokerPerNode: false
Let’s get into the specifics. If oneBrokerPerNode is set to true, each broker starts on a new node (that is, literally, one broker per node); if there are not enough nodes to go around, it remains in pending. If it’s set to false, the operator similarly tries to schedule the brokers to unique nodes, with the added caveat that, if there is an insufficient number of nodes, brokers are scheduled to nodes on which a broker is already running. We use pod antiAffinity for this feature. You can learn more about affinities and anti-affinities from our previous post, Taints and tolerations, pod and node affinities demystified.
To understand how the rackAwareness field works in the custom resource definition, let’s talk briefly about Kubernetes nodes. A K8s node is a Kubernetes worker machine that, like every other Kubernetes resource, is capable of holding labels. Most cloud provider-managed Kubernetes clusters, including those managed with the Banzai Cloud Kubernetes distribution, PKE, have something called well-known labels. One well known label is failure-domain.beta.kubernetes.io/zone.
Kubernetes populates this label with zone information from the cloud provider. If the node is in an on-prem cluster, the operator can also set this label, but it’s not strictly mandatory. With that in mind, let’s look at how a user can set his own labels in the CR, in order to achieve rack awareness on clusters which lack well-known labels.
Rack awareness and Koperator
Enough minutiae, let’s take a look at how the Koperator configures rack awareness.
As mentioned earlier, broker.rack is a read-only broker config, so is set whenever the broker starts or restarts. Unlike other operators, the
Koperator
holds all its configs within a ConfigMap in each broker. In order to maintain this behavior, we can’t use scripts that overwrite the configuration during runtime, so we opted for a different approach.
Getting label values from nodes and using them to generate a ConfigMap is relatively easy, but to determine where the exact broker/pod is scheduled, the operator has to to wait until the pod is actually scheduled to a node. Luckily, Kubernetes schedules pods even when a given ConfigMap is unavailable. However, the corresponding pod will remain in a pending state as long as the ConfigMap is not available to mount. The operator makes use of this pending state to gather all the necessary node labels and initialize a ConfigMap with the fetched data. To take advantage of this, we introduced a status field called RackAwarenessState in our CRD. The operator populates this status field with two values, WaitingForRackAwareness and Configured.
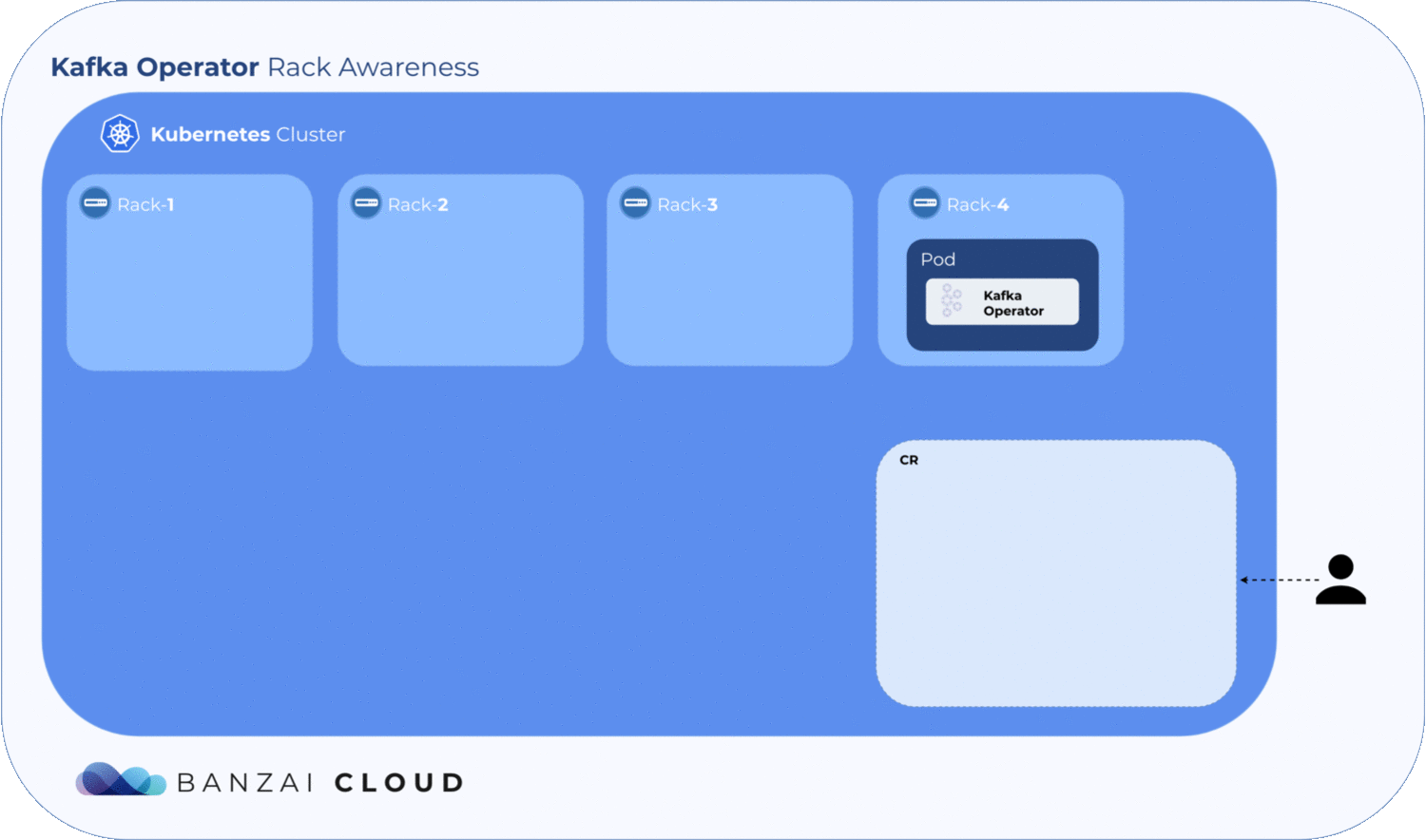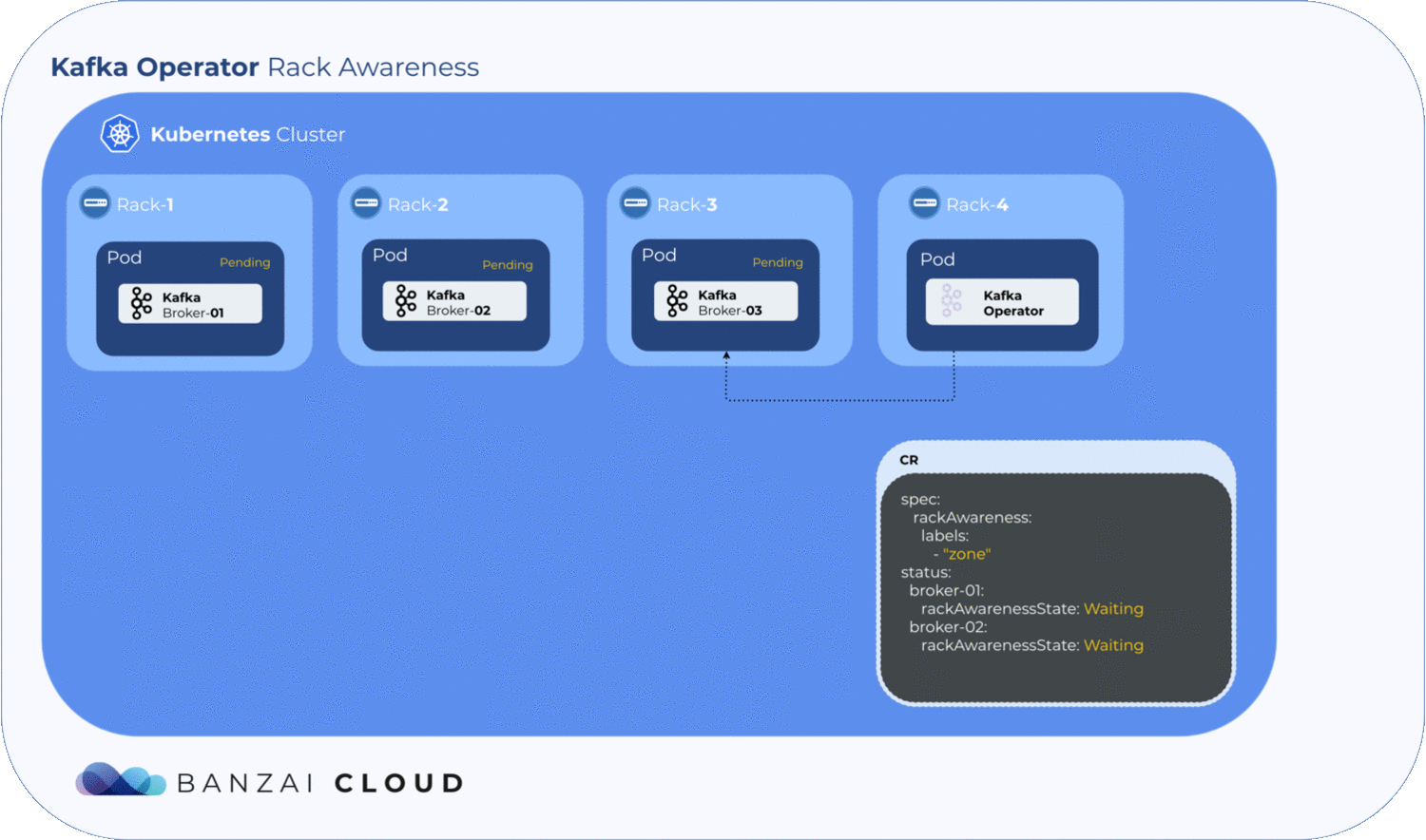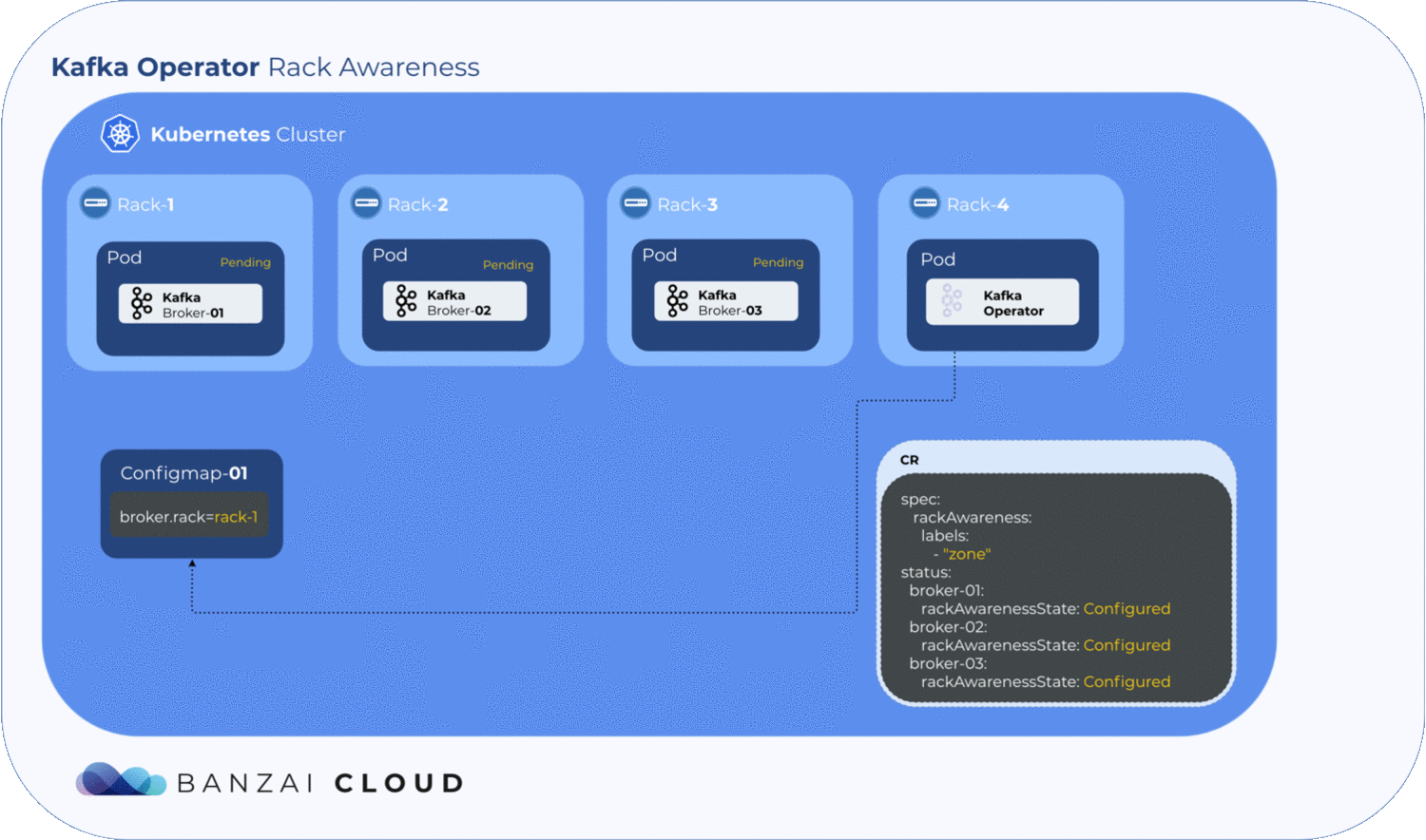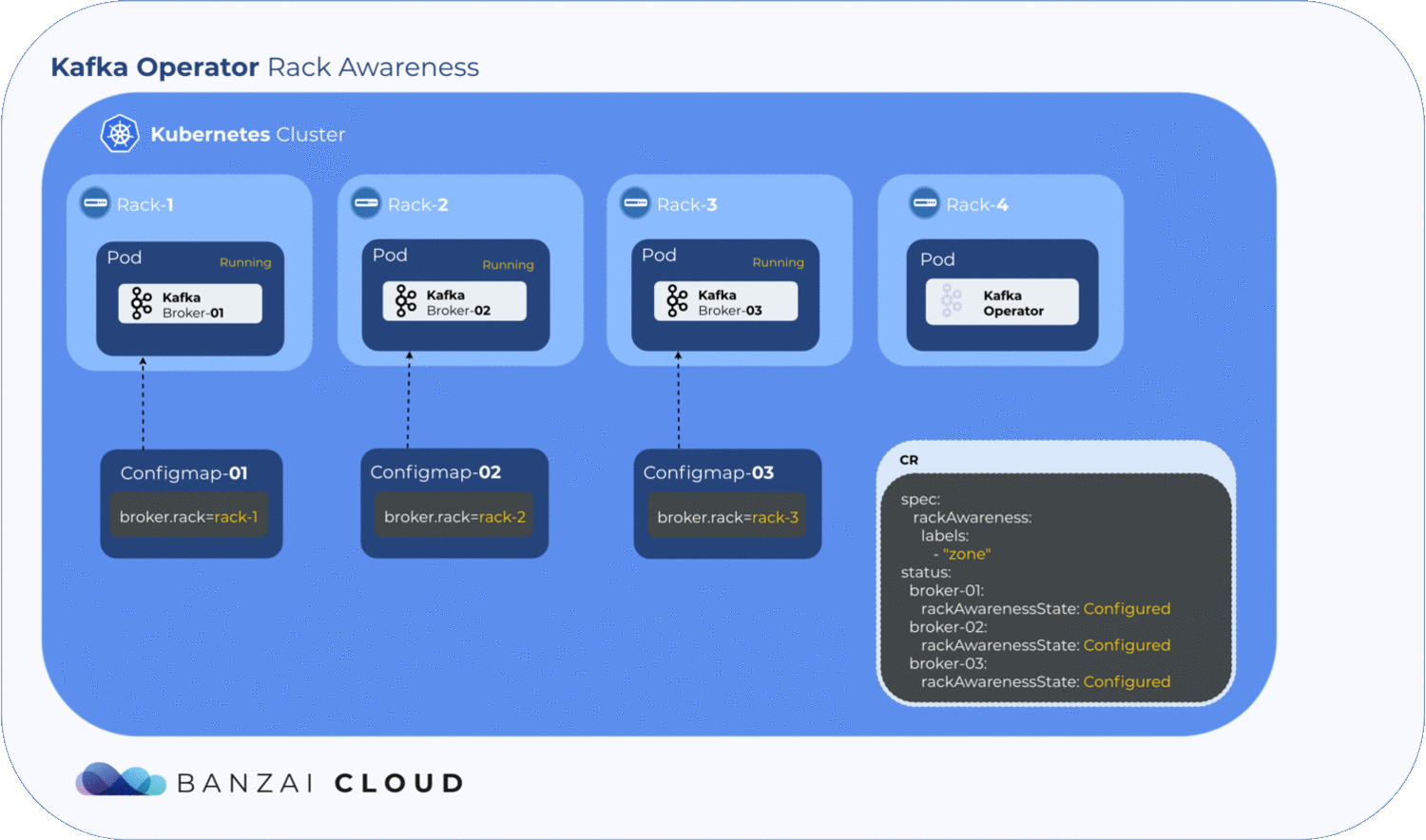
Now that we’ve configured Kafka on Kubernetes to be rack aware, the question remains: what happens if a broker fails? Will Kubernetes schedule it to a different zone? Well, this is why we use NodeSelectors. When a pod fails, the operator fetches all the available information from the node(s) - including zone and region - and tries to place it back in the zone it was previously in. If it can’t, the pods will remain pending. This is where the manual config override comes in handy; using the operator’s unique, fine-grained broker config support, the user can set the broker.rack config by hand to specify the exact location of the broker node.
Why all the fuss? 🔗︎
So, besides the added resilience, that it’s important and you almost get it for free, what’s with all the fuss and work in the operator around this feature? As mentioned at the beginning of the blog, the Pipeline platform is a multi and hybrid-cloud platform where our customers deploy their applications and microservices using multiple network topologies into a service mesh, using our Istio operator and automated service mesh product. How does this relate to Kafka? Well, many of our customers use Kafka as a communication layer for their internal microservices, and those microservices are deployed onto an Istio-based service mesh.
This means that we need Kafka to work seamlessly with Istio and our automated service mesh, wherein microservices and Kafka brokers are spread across on-premise Kubernetes clusters, multi-cloud and hybrid-cloud environments and in which data partitioning and, often, edge cases are very important. If you are interested in this topic stay tuned. We’ll be talking about some of these features, benchmarks, latencies and why we went down this road in particular, instead of, for instance, using MirrorMaker.
About Banzai Cloud 🔗︎
Banzai Cloud is changing how private clouds are built in order to simplify the development, deployment, and scaling of complex applications, putting the power of Kubernetes and Cloud Native technologies in the hands of developers and enterprises, everywhere.