






About a year ago we published the first release of our popular logging-operator. The initial version of that operator was designed to fit Pipeline, the Banzai Cloud hybrid cloud container management platform. However, since then, all kinds of people have found it to be an extremely useful tool that helps them manage their logs on Kubernetes.
Initially, Fluent ecosystem automation was enough to support the disparate needs of our userbase, but, as the popularity of the logging-operator grew, different setups were put in place by our community that revealed some of its limitations. Over the last few months we’ve been collecting user feedback, wishlists and feature requests, and have decided to redesign the operator from scratch.
Today, we’re happy to announce that we’re releasing the beta version of our brand new logging-operator v2.
Design principles of v2 🔗︎
Tailored to, and driven by, our community, as well as the requirements of the Pipeline platform and those of a new logging product for Kubernetes forthcoming from Banzai Cloud, the main design principles of our operator were:
- Make logging more Kubernetes
nativeand provide namespace isolation - Allow users to filter logs based on Kubernetes labels
- Make it easy to write new plugins by reusing as much code as possible
- Provide multiple outputs for the same logs
- Provide as much help as possible when debugging complex scenarios
- Implement support for multiple log flows
Now let’s dig into these in more detail.
Namespace separation 🔗︎
One of the key problems with logging was separating different namespaces. Because Kubernetes logging solutions tail logs on a per node bases, they arrive in bulk from a variety of namespaces. For that reason, the operator guards the Fluentd configuration and checks permissions before adding new flows. In this way, the logging-operator adheres to namespace boundaries and denies prohibited rules.
Labels vs Fluentd tags 🔗︎
The second problem we faced was identifying logs. Kubernetes distinguishes resources based on their name and labels, while Fluentd handles log sources as flows. The log metadata consists of a timestamp and tag, which becomes attached to a log’s record when it enters the Fluent-bit pipeline. To fix this problem we opensourced a Fluentd plugin called label-router, which is able to route logs via namespaces and labels.
Single log, multiple flows 🔗︎
It’s common practice to archive all your logs in object stores, then send out a filtered version for analytics (e.g. ElasticSearch). Our operator seamlessly multiplies logs for different outputs, so you can set up multiple flows with different filters and different outputs.
Easily extendable and self documented 🔗︎
Several plugins share the same configurable component, similar to an output plugin’s buffer section, and these are now reusable across different plugins. To maintain order and a clear structure, we designed them with their documentation in mind; the operator generates documentation based on docstring comments and attribute tags. You can read more about this in our developers guide.
Configuration checks 🔗︎
When Fluentd aggregates logs, it shares the configurations of different log flows. To prevent a bad configuration from failing the Fluentd process, a configuration check validates these first. The new settings only go live after a successful check.
Component overview 🔗︎
Now that we’re through covering the design principles, let’s do a detailed component overview and take a walk through the new resources we’ve added.
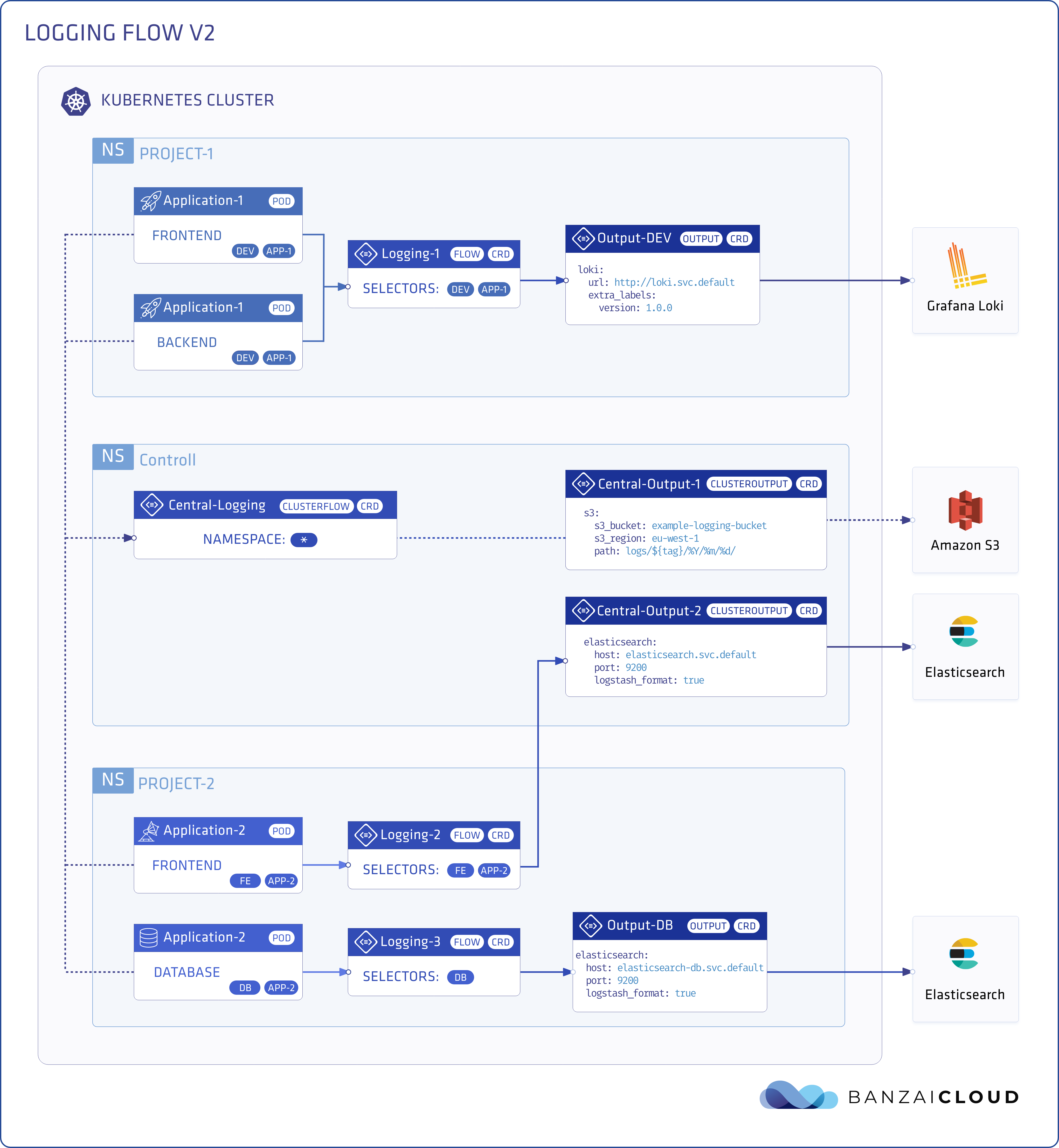
Logging 🔗︎
The Logging resource represents the logging system, and contains configurations for Fluentd and Fluent-bit. It also establishes the controlNamespace, the administrative namespace of the logging-operator. The Fluentd statefulset and Fluent-bit daemonset will be deployed in this namespace, and non namespaced resources like ClusterOutput and ClusterFlow are only effective in this namespace - are ignored in any other namespace. For more detailed information visit the documentation of Logging operator CRDs.
example Logging
apiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
namespace: logging
spec:
fluentd: {}
fluentbit: {}
controlNamespace: loggingOutput 🔗︎
Output defines an output for a logging flow. This is a namespaced resource which means only a Flow within the same namespace can access it. You can use secrets in these definitions, but they must also be in the same namespace. See the list of supported Logging operator plugins for details. We at Banzai Cloud and our open source community members are constantly working on new plugins, so if you can’t find what you need, you should feel free to get in touch with us over the Banzai Cloud Slack channel or through GitHub.
example Output
apiVersion: logging.banzaicloud.io/v1beta1
kind: Output
metadata:
name: gcs-output-sample
spec:
gcs:
credentials_json:
valueFrom:
secretKeyRef:
name: gcs-secret
key: credentials.json
project: logging-example
bucket: banzai-log-test
path: logs/${tag}/%Y/%m/%d/
buffer:
path: /tmp/buffer
timekey: 1m
timekey_wait: 10s
timekey_use_utc: trueFlow 🔗︎
Flow defines a logging flow with filters and outputs. This is a namespaced resource as well, so only logs from the same namespaces are collected. You can specify selectors to filter logs according to Kubernetes labels, and can define one or more filters within a Flow. These filters are applied in the order in the definition. See the list of supported Logging operator filters for details. At the end of the Flow, you can attach one or more outputs, which may also be Output or ClusterOutput resources.
example Flow
apiVersion: logging.banzaicloud.io/v1beta1
kind: Flow
metadata:
name: flow-sample
namespace: default
spec:
filters:
- tag_normaliser:
format: ${namespace_name}.${pod_name}.${container_name}
- parser:
key_name: message
parsers:
- type: nginx
outputRefs:
- gcs-output-sample
- elasticsearch-output
selectors:
app: nginxClusterOutput 🔗︎
ClusterOutput defines an Output without namespace restrictions. It is only effective in the controlNamespace.
ClusterFlow 🔗︎
ClusterFlow defines a Flow without namespace restrictions. It is also only effective in the controlNamespace.
Showtime 🔗︎
Let’s take a look at the new operator at work, as it saves all logs to S3. In the coming weeks, and before launching our new logging product, we will be sharing posts about the operator’s capabilities and our/customer usage patterns, so stay tuned.
Install the logging-operator 🔗︎
Install the logging-operator using the Helm chart. This chart only deploys the CRDs and the operator itself.
First we create the controlNamespace
kubectl create namespace logging-systemNote: If you have auto namespace create enabled in Helm you can skip namespace creation
$ helm repo add banzaicloud-stable https://kubernetes-charts.banzaicloud.com
$ helm repo update
$ helm install banzaicloud-stable/logging-operator --namespace logging-systemCreate default logging 🔗︎
Now we can spin up the logging components. The fluentd statefulset and fluent-bit daemonset will be created as a result of creating the Logging custom resource.
For ease of use, we created a Helm chart to set the Logging resource up with TLS.
helm install banzaicloud-stable/logging-operator-logging --set controlNamespace=logging-systemHowever, if you prefer to use the CR definition, here’s an example without TLS:
kubectl apply -f logging.yamlapiVersion: logging.banzaicloud.io/v1beta1
kind: Logging
metadata:
name: default-logging-simple
spec:
fluentd: {}
fluentbit: {}
controlNamespace: logging-systemNote:
ClusterOutputandClusterFlowresources will only be accepted in thecontrolNamespace
Create an AWS secret 🔗︎
If you have your $AWS_ACCESS_KEY_ID and $AWS_SECRET_ACCESS_KEY set, you can use the following snippet to create a Kubernetes secret from your Amazon credentials.
kubectl create secret generic logging-s3 --namespace logging-system --from-literal "awsAccessKeyId=$AWS_ACCESS_KEY_ID" --from-literal "awsSecretAccesKey=$AWS_SECRET_ACCESS_KEY"Or you can set the secret up manually:
kubectl apply -f secret.yamlapiVersion: v1
kind: Secret
metadata:
name: logging-s3
namespace: logging-system
type: Opaque
data:
awsAccessKeyId: <base64encoded>
awsSecretAccesKey: <base64encoded>It is ESSENTIAL that you install the
secretand theClusterOutputdefinition in the same namespace.
Create an S3 output definition 🔗︎
kubectl apply -f clusteroutput.yamlapiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterOutput
metadata:
name: s3-output
namespace: logging-system
spec:
s3:
aws_key_id:
valueFrom:
secretKeyRef:
name: logging-s3
key: awsAccessKeyId
aws_sec_key:
valueFrom:
secretKeyRef:
name: logging-s3
key: awsSecretAccesKey
s3_bucket: logging-amazon-s3
s3_region: eu-central-1
path: logs/${tag}/%Y/%m/%d/
buffer:
path: /tmp/buffer
timekey: 10m
timekey_wait: 30s
timekey_use_utc: trueNote: For a production setup we recommend using a longer
timekeyinterval to avoid generating too many objects.
Configure a ClusterFlow 🔗︎
The following snippet uses tag_normaliser to re-tag logs and, afterward, push them to S3.
kubectl apply -f clusterflow.yamlapiVersion: logging.banzaicloud.io/v1beta1
kind: ClusterFlow
metadata:
name: all-log-to-s3
namespace: logging-system
spec:
filters:
- tag_normaliser: {}
selectors: {}
outputRefs:
- s3-outputThe logs then become available in the bucket of a path like:
/logs/default.default-logging-simple-fluentbit-lsdp5.fluent-bit/2019/09/11/201909111432_0.gz
And that’s that. By now, we hope you’re as excited as we are about the new version of our logging-operator. We are actively working on more filters and outputs in order to cover all of our and our customers’ use cases. We’ll be releasing more examples, and some of the more advanced situations our customers found themselves in, as part of the operator’s documentation. That way you’ll be able to design your own Kubernetes logging infrastructure based on real life examples and proven working models. If you need help and support utilizing the logging-operator, please be sure you contact us on Slack or subscribe to one of our commercial packages.
Happy logging!







