This post is part of a series that highlight the multi- and hybrid-cloud features of the Banzai Cloud Pipeline platform. Today, we will be focusing specifically on multi-cloud features.
Before we take a deep dive into our technical content, let’s go over some of the key expectations an enterprise has when it embraces a multi-cloud strategy:
-
Multi-cloud infrastructure provisioning: - the Pipeline platform and our CNCF certified Kubernetes distribution runs through a unified interface on 5 different cloud providers as well as on-prem. It provides features like enterprise grade security, centralized logging, federated monitoring, security scans, disaster recovery, workload management and a service mesh, just to name a few.
-
Centralized and unified security: - secrets are stored and managed by Bank-Vaults and injected into environments as needed. Data is encrypted in motion and at rest.
-
Application delivery: - enterprises seek to deliver applications across multiple cloud environments via a unified method, yet they also seek to automatically customize these applications, relying on cloud specific services and features to do so.
-
Multiple network topologies: - with the increase in the number of microservices, enterprise teams often seek to deliver their product closer to data and/or to preferred or less expensive clouds. There has been a huge increase in dynamic services, and east-west traffic, bringing previously unanticipated complexities. The Banzai Cloud Pipeline platform abstracts and automates these by delivering a service mesh approach and simplifying the adoption of microservices, in a secure way.
While we have touched on almost all of these topics in older posts, providing technical reasoning and examples of why and how we approach these in open source, this post will be the first to focus solely on application delivery.
Motivation 🔗︎
While working on integrating Kubernetes Federation v2 into Banzai Cloud Pipeline, we realized it might not fit neatly with all our customers’ use cases. First, most of our customers use Helm charts for deployments, so it would require a significant investment of time and energy for them to create federated versions of those charts. Second, Federation v2 requires a master cluster wherein you can install the Federation Controller, which allows constant monitoring of resources on joined clusters. However, most of our users want simply to distribute their deployments to multiple clusters, regions and the private/public cloud. While we are still in the process of adding Federation support, at this juncture we are also adding support for multi-cluster/cloud deployments and providing full lifecycle management, just like we do for single cluster deployments.
tl;dr 🔗︎
- Banzai Cloud Pipeline users can define cluster groups across any cloud and on-premise
- deployments can be installed on members of a cluster group, with full CRUD lifecycle support
- deployments can be customized for each cluster/cloud, with specific overrides of configuration values
- multi-cluster deployments are stored in the Banzai Cloud Pipeline database
- as a real-world example, we will be deploying CockroachDB to multiple clouds
Introducing Cluster Groups 🔗︎
In order to create multi-cluster deployments, you first have to create a cluster group. Any cluster created with Banzai Cloud Pipeline can join a cluster group (which is just a bunch of clusters associated with a single group name). Clusters can only belong to one group at a time, and once clusters are associated with a group they are called member clusters. A cluster group can have different features associated with it, like multi-cluster deployment, which is turned on by default. Likewise, Service Mesh is another feature that can be turned on in a cluster group, with Federation v2 also slated to become a supported cluster group feature. Features can be turned on and off, and can have different associated states.
The multi-cluster deployment feature 🔗︎
As we mentioned earlier, this is a feature that’s turned on by default, and makes it possible to target a deployment to one or more clusters simultaneously, instead of deploying separately on each. Single cluster deployments in Banzai Cloud Pipeline are usually Helm deployments, the state of a deployment being stored on the cluster itself, by Helm. Multi-cluster deployments differ in the sense that, when a user creates a multi-cluster deployment, it is persisted in the Banzai Cloud Pipeline database as a desired state. The actual state of a deployment is then fetched from each member cluster, and a reconciliation loop moves deployments from their desired state into the actual one. In the simplest most concise terms, multi-cluster deployments are made of several, single-cluster deployments installed on targeted clusters, and are often used as a convenient way of handling several deployments on multiple clouds/clusters at once.
Clusters can be freely deleted from their group, with the multi-cluster feature first being disabled, then the clusters removed (the cluster itself is not deleted). Multi-cluster deployments are deleted from the cluster when it leaves the group. When adding new members to a group, deployments are not installed automatically, you have to either ‘Edit’ or ‘Reconcile’ in order to install a deployment on new members. This is because you might want to specify overrides for each new cluster member.
Note, multi-cluster deployment is about distributing your application to different clouds. However, when the Service Mesh
featureis switched on, you can wire them into multiple topologies as described in this post, “Easy peer-to-peer multicluster service mesh with the Istio operator”.
Multi-cluster deployment operations and the API 🔗︎
The multi-cluster deployment API is very similar to that of a single cluster deployment; you can create, edit, list and delete deployments. Deployment properties are practically the same, with one significant difference being that you can override configuration values for each target cluster. Another difference is that since it’s bounded to a cluster group instead of a cluster it’s available on a new endpoint: clustergroups/:clusterGroupId/deployments.
In the next section we will guide you through the API, which will also be made available in the Banzai Pipeline CLI.
Create & Edit 🔗︎
Below is a simple example of a create request:
POST {{url}}/api/v1/orgs/:orgId/clustergroups/:clusterGroupId/deployments
{
"name": "repoName/chartName",
"namespace":"yourNamespace",
"values": {
"replicaCount": 1,
"image": {
"tag": "2.1"
}
},
"valueOverrides": {
"clusterName1": {
"replicaCount": 2
},
"clusterName2": {
"replicaCount": 3
}
}
}
We’ve already pointed out the key differences in a Create request like this one - that we have values containing common values for deployments on all target clusters, and that you may specify overrides for each cluster in the event there are any specific differences in deployment values for a cluster/cloud. These cluster-specific values are merged together with the common values, after which the result is sent to the Helm client.
Typically, such differences are, for example, StorageClasses, which may differ from cloud provider to cloud provider. Overrides are also handy if you want to specify different Object Storage credentials for each cloud provider or for any specific cloud or cluster-specific service.
Both the create and edit operations attempt to install or upgrade the deployment on each member cluster of a group, in accordance with whether there’s already a deployment of the same chart with the same release name.
The status of a deployment operation (create, edit, delete) may differ from the actual status of a deployment. The status of a multi-cluster deployment is a list of Helm chart statuses on each targeted cluster - as you will see below - whereas a create or update operation is only successful if all Helm create/update operations are successful. These operations run in parallel, so total deployment time should not exceed that of deploying to whichever cluster has the highest network latency.
Just like in single cluster deployments, there is a dryRun flag, which keeps the deployment from being persisted. This comes in handy for validation checks. Uniqueness of release name is then checked across target clusters, and, if you don’t specify a releaseName, a random release name is generated for you.
The update request is very much the same as it is for create, one important difference being the reuseValues flag.
PUT {{url}}/api/v1/orgs/:orgId/clustergroups/:clusterGroupId/deployments/:releaseName
{
"name": "repoName/chartName",
"namespace":"yourNamespace",
"reuseValues": "true",
"values": {
"replicaCount": 1,
"image": {
"tag": "2.1"
}
},
"valueOverrides": {
"clusterName1": {
"replicaCount": 2
},
"clusterName2": {
"replicaCount": 3
}
}
}
Set the reuseValues flag to true to avoid specifying values again, or set it to false, if you want to completely override the existing values. In other words, if reuseValues = false, values are merged together just as they would be during a Create request, otherwise, common values are merged with cluster-specific values, overriding existing values.
If you are using the Pipeline UI, you can see the actual values in a deployment when you uncheck the reuseValues box.
List & Fetch deployment(s) 🔗︎
Once you have successfully created your multi-cluster deployment, you can fetch its details by referencing it with its release name:
GET {{url}}/api/v1/orgs/:orgId/clustergroups/:clusterGroupId/deployments/:releaseName
{
"releaseName":"sample",
"chart":"stable/tomcat",
"chartName":"tomcat",
"chartVersion":"0.2.0",
"namespace":"default",
"description":"Deploy a basic tomcat application server with sidecar as web archive container",
"createdAt":"2019-06-04T14:17:03Z",
"updatedAt":"2019-06-04T14:17:03Z",
"values":{
...
"replicaCount":1,
"service":{
"externalPort":80,
"internalPort":8080,
"name":"http",
"type":"LoadBalancer"
},
...
},
"valueOverrides":{
"pke-demo":{
"replicaCount":2
},
"gke-demo":{
"replicaCount":3
}
},
"targetClusters":[
{
"clusterId":1681,
"clusterName":"pke-demo",
"cloud":"amazon",
"distribution":"pke",
"status":"DEPLOYED",
"stale":false,
"version":"0.2.0"
},
{
"clusterId":1682,
"clusterName":"gke-demo",
"cloud":"google",
"distribution":"gke",
"status":"DEPLOYED",
"stale":false,
"version":"0.2.0"
}
]
}
Above is a sample of details fetched from a Tomcat deployment, deployed to a PKE on AWS and GKE cluster. As you can see, there’s no single status in a multi-cluster deployment, instead, there are separate statuses for each of the target clusters listed in the targetClusters field. The deployment status of a target cluster can be any one of the following:
UNKOWN- Pipeline cannot reach the targeted clusters (Tiller to be more specific)NOT INSTALLED- the given Helm chart cannot be found on the target clusterSTALE- a Helm chart is installed on the target cluster, however, its existing values are different from desired ones - calculated by merging common and cluster-specific values.- If the Helm chart is installed and its values equal to desired values, then the status returned by the Helm client for a given chart may be:
DEPLOYED,DELETED,SUPERSEDED,FAILED,DELETING,PENDING_INSTALL,PENDING_UPGRADE,PENDING_ROLLBACK
You can also list deployments, which won’t return deployment statuses, since that can be unnecessarily time consuming.
GET {{url}}/api/v1/orgs/:orgId/clustergroups/:clusterGroupId/deployments
Reconcile 🔗︎
PUT {{url}}/api/v1/orgs/:orgId/clustergroups/:clusterGroupId/deployments/:releaseName/sync
Should a multi-cluster deployment status on any target cluster differ from DEPLOYED, i.e. NOT_INSTALLED or STALE, your first and last stop should be the Reconcile operation, which will attempt to enforce the desired state of each cluster. Reconcile tries to install or upgrade deployments to clusters originally targeted in Create and Edit requests. There’s no automatic installation of a deployment to newly added members of a group after a deployment is created. This is mainly because we don’t know what values we want specifically overriden in a cluster, which is the same reason Reconcile doesn’t automatically install to each new member as it is added. If you want to install the deployment on a new member, use Edit. Reconcile also deletes stale deployments - deployments installed on clusters which are no longer members of a group. These are normally deleted when their cluster is removed from a group, but, in the event they remain, Reconcile should resolve the situation.
Delete 🔗︎
DELETE {{url}}/api/v1/orgs/:orgId/clustergroups/:clusterGroupId/deployments/:releaseName
The delete operation will attempt to delete deployments from all the members of a cluster group, as long as they exist. There’s also a force flag which is useful whenever problems arise within the delete operation: if, for instance, the cluster is not available anymore or cannot connect to a cluster.
For a complete API description, check out the Pipeline Open API spec
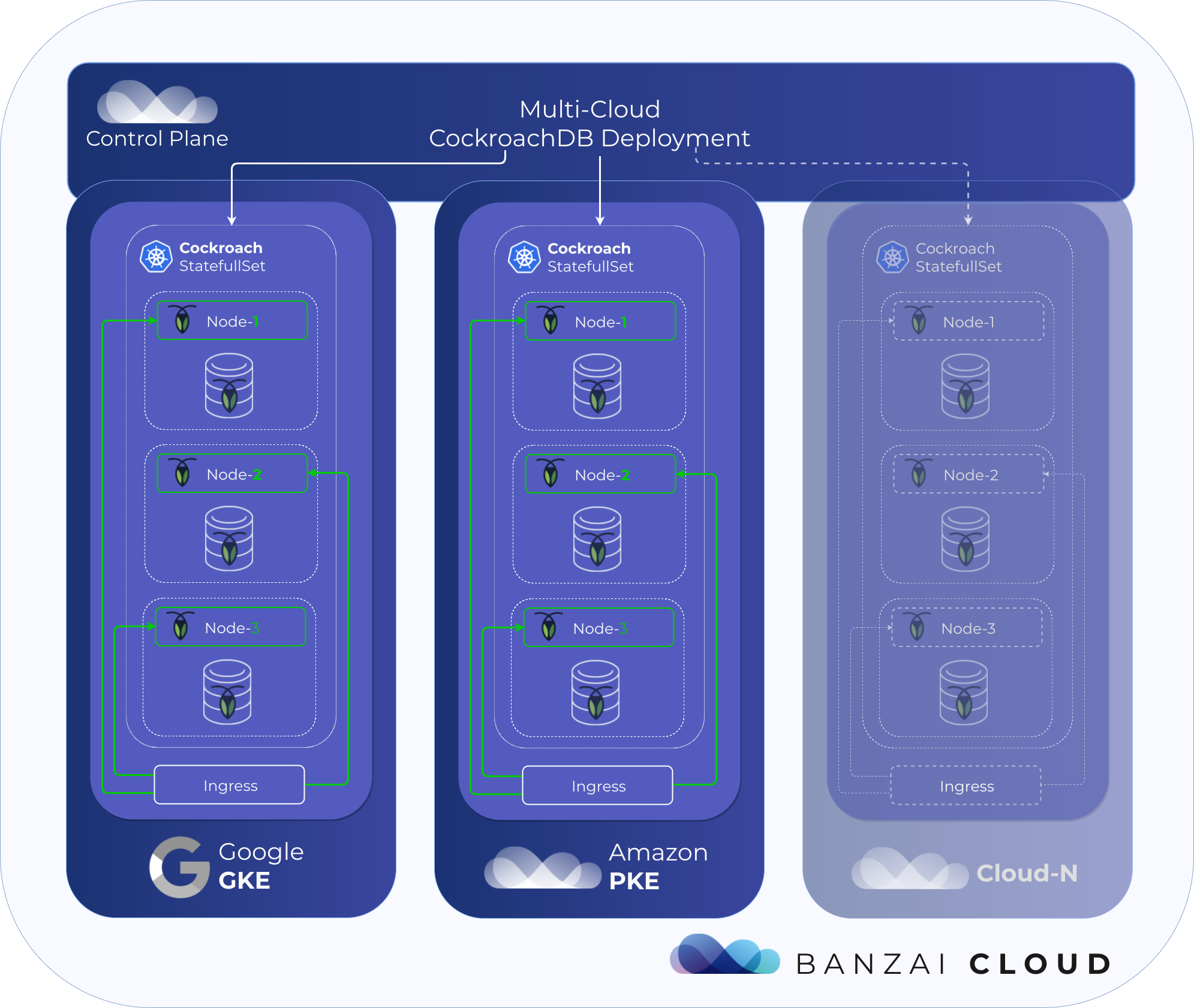
Practical exercise: deploy CockroachDB to PKE on AWS & GKE 🔗︎
As an example, we’ll take a slightly modified experimental version of the official CockroachDB chart and will use the multi-cluster deployment feature from the Pipeline UI to achieve what has been previously described in greater detail, here: Deploying CockroachDB to multiple Kubernetes clusters.
In short, this experiment will create two clusters: one on Amazon with our own CNCF certified Kubernetes distribution, PKE, and one GKE cluster on Google Cloud, deploying CockroachDB to both. To form a single cluster, CockroachDB nodes should be reachable from outside and the addresses of the PKE nodes correctly configured in the GKE deployment, so the nodes running in the GKE cluster are able to discover those nodes running on the PKE cluster.
The main difference between these two deployments is:
cockroachdb:
JoinExisting:
- "cockroachdb-cockroachdb-0-node-demo-pke-1.sancyx.try.pipeline.banzai.cloud:26257"
- "cockroachdb-cockroachdb-1-node-demo-pke-1.sancyx.try.pipeline.banzai.cloud:26257"
- "cockroachdb-cockroachdb-2-node-demo-pke-1.sancyx.try.pipeline.banzai.cloud:26257"
Comparing these deployments:
- When comparing gke-deployment.json and pke-deployment.json we first had to identify the parts they had in common that were entered in the main config values box.
- Along with
JoinExisting, there were a few other properties that contained the cluster name as well as cluster-specific overrides at the moment we had to enter them. However, we plan to introduce a degree of templating facility to support such scenarios.
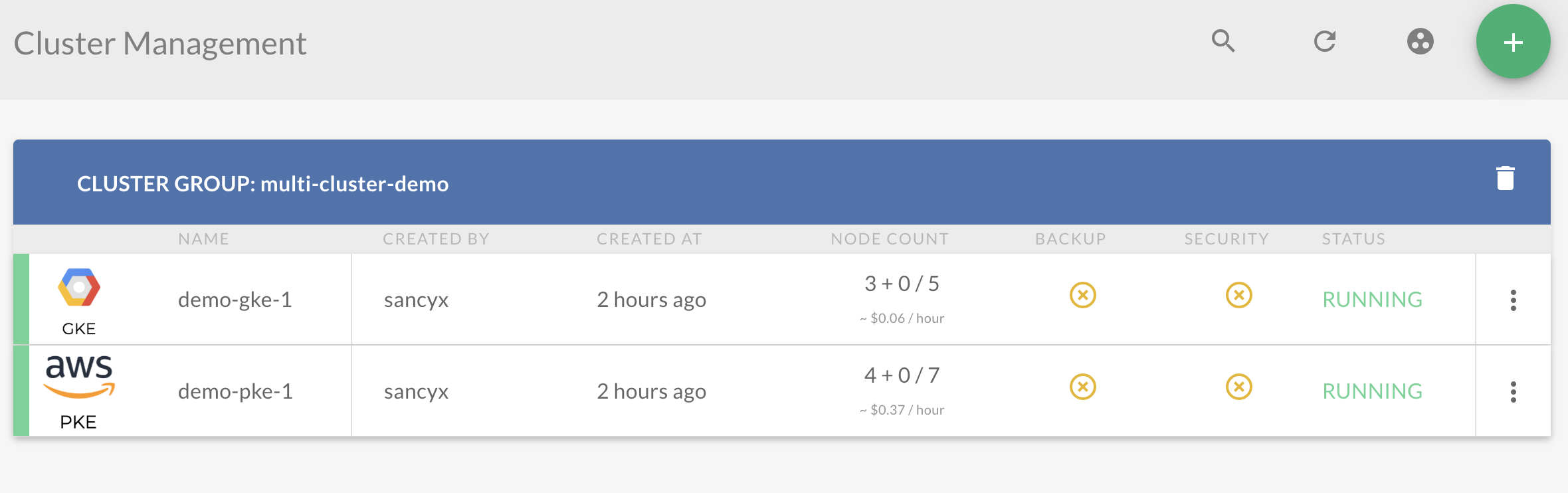
First, create two clusters: demo-pke-1 & demo-gke-1, which you can do with a few clicks or CLI commands using Pipeline. Once you have the clusters up and RUNNING you can assign them to a cluster group:
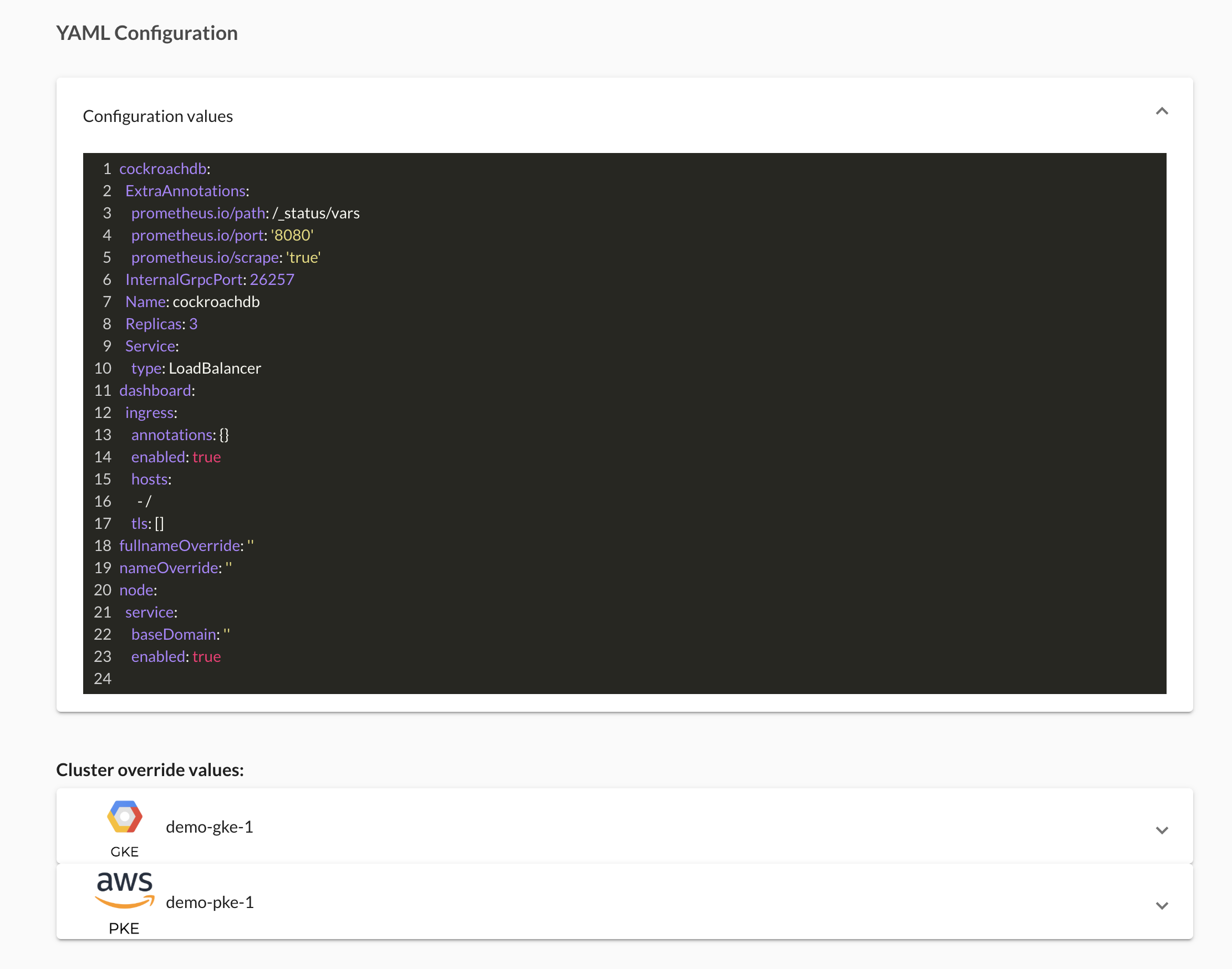
Now create a multi-cluster deployment, with the release name cockroachdb, and enter global common configuration values. In order to be able to install directly from the UI, we have uploaded our experimental chart to our chart repository.
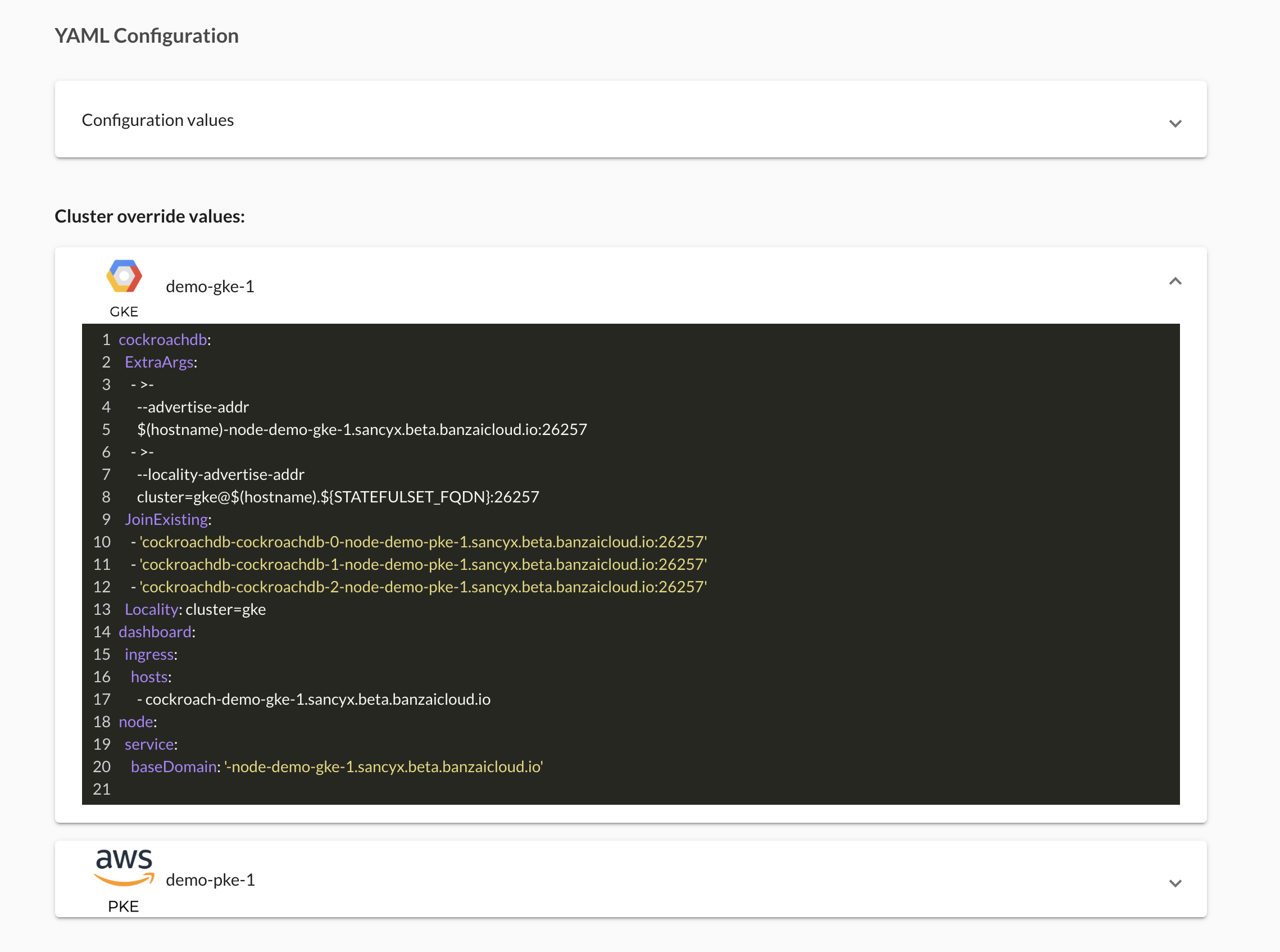
Enter the overrides for the GKE cluster:
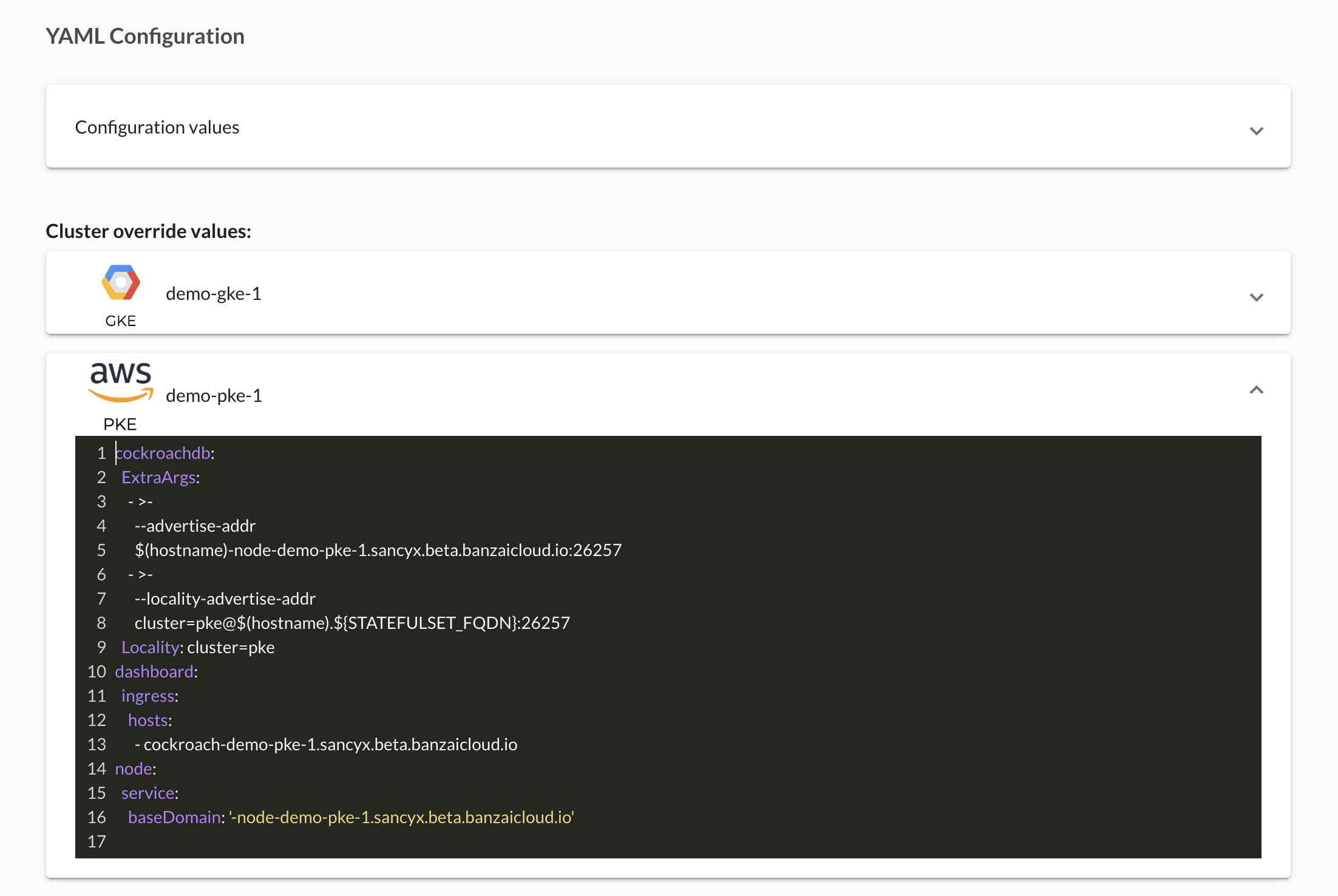
Enter the overrides for the PKE cluster:
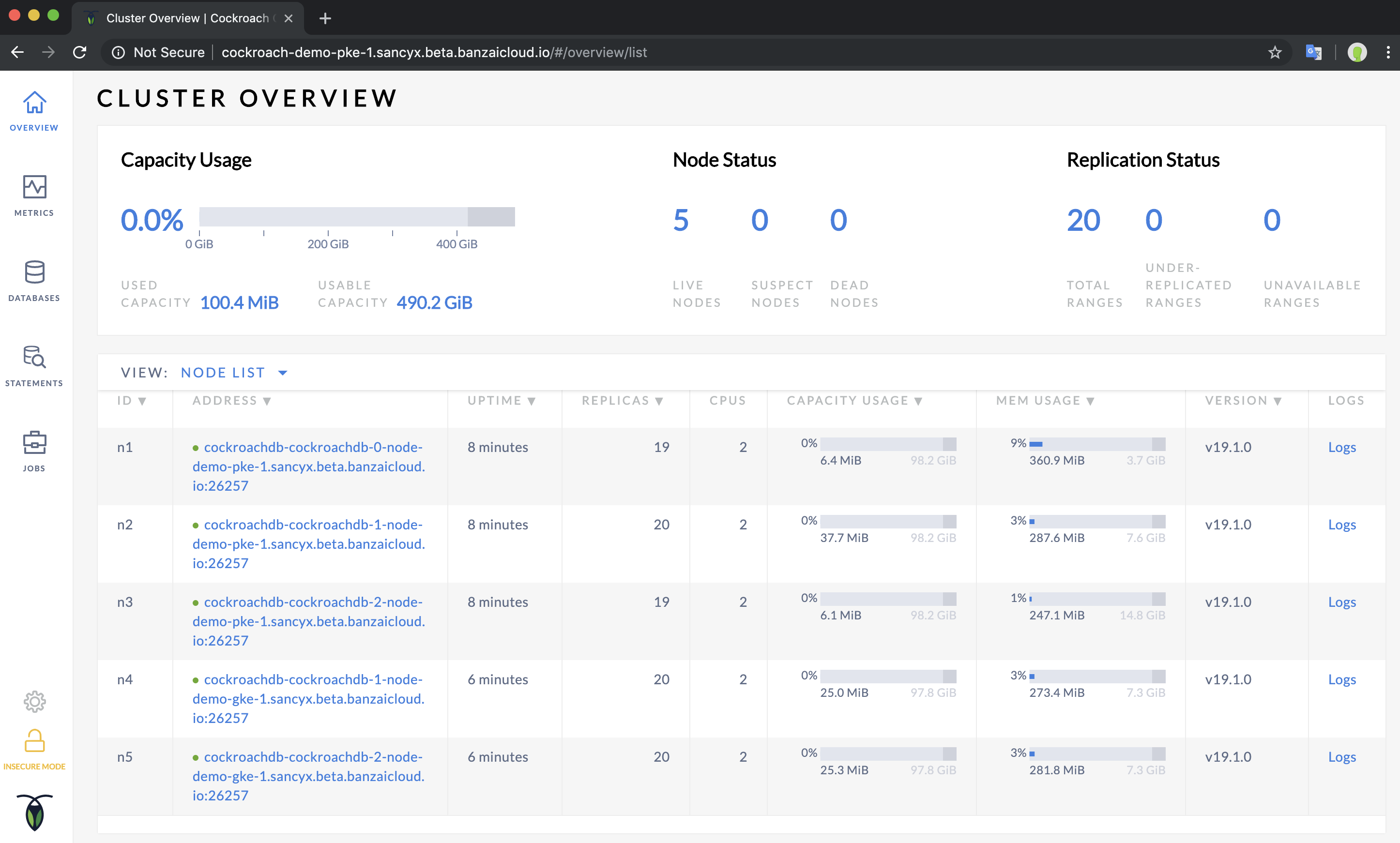
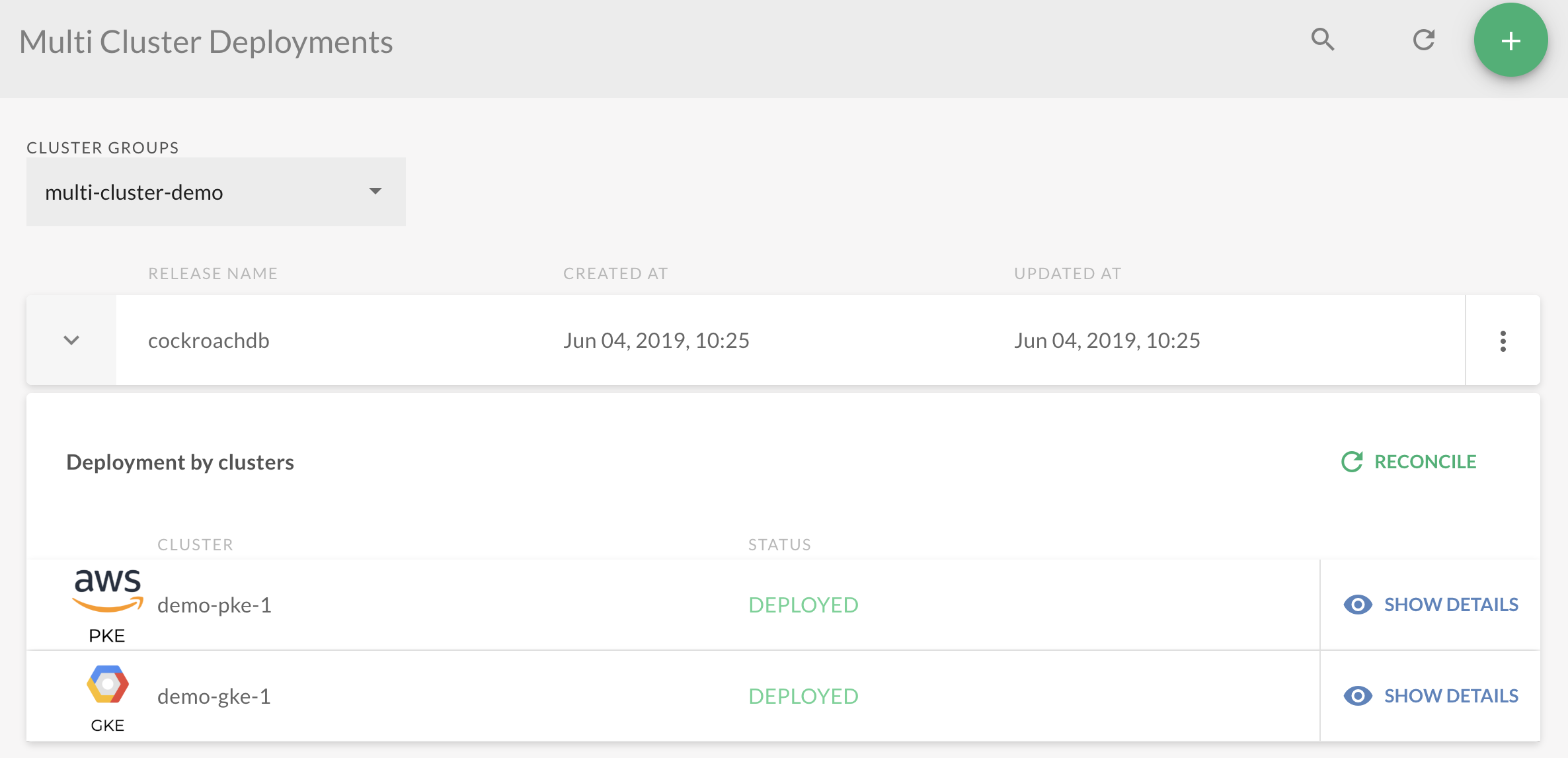
Now you should have CockroachDB deployed on two clusters! Since multi-cluster deployments are normal single-cluster deployments, you can check their details using Reconcile.
Finally, you can open the CockroachDB Dashboard, where you should see all the nodes that have joined: