Last time we discussed how our Pipeline PaaS deploys and provisions an AWS EFS filesystem on Kubernetes and what the performance benefits are for Spark or TensorFlow. This post is gives:
- An introduction to TensorFlow on Kubernetes
- The benefits of EFS for TensorFlow (image data storage for
TensorFlowjobs)
Pipeline uses the kubeflow framework to deploy:
- A JupyterHub to create & manage interactive Jupyter notebooks
- A TensorFlow Training Controller that can be configured to use CPUs or GPUs
- A TensorFlow Serving container
Note that Pipeline also has default Spotguides for Spark and Zeppelin to help support your datascience experience
Introduction to TensorFlow 🔗︎
TensorFlow is a popular open source software library for numerical computation using data flow graphs. A computational graph is a series of TensorFlow operations arranged into a graph of nodes, where the nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays - tensors - communicated between them. This flexible architecture allows for the deployment of computation to one or more CPUs or GPUs on a desktop, server, or mobile device using a single API.
There are plenty of examples and scripts running TensorFlow workloads, most running on single nodes/machines. In order to run your script on a cluster of TensorFlow servers, you need to modify them, create the ClusterSpec, and explicitly define tasks to run on different devices. A typical TensorFlow cluster consists of workers and parameter servers. Workers run copies of their training, while parameter servers (ps) maintain model parameters. You can find more info about these here: Distributed TensorFlow. Kubeflow is a handy way to deploy workers and parameter servers, allowing us to define TfJob, which makes it easy to define TensorFlow specific deployments.
We’ve selected an example walk-through for provisioning the Pipeline PaaS, inception_distributed_training.py, a distributed training job from the well known Inception model, adapted to run on kubeflow. Inception is a deep convolutional neural network architecture for state of the art classification and detection of images.
Kubeflow passes TensorFlow cluster specs (workers and parameter servers) as a JSON in an environment variable called TF_CONFIG. That’s why we needed to modify the inception_distributed_training.py script a bit.
Ok, now let’s take a look at how to get this started. First, you need to check out two projects on GitHub:
git clone https://github.com/google/kubeflow.git
git clone https://github.com:banzaicloud/tensorflow-models.git
cd tensorflow-models
git checkout master-k8s
Spoiler alert 1: Pipeline automates all these and we’ve made their Helm chart deployments available. The purpose of this detailed walk-through is to understand what’s happening behind the scenes when you choose model training or serving with Pipeline
Create a Kubernetes cluster on AWS and attach EFS storage
This is pretty much the same as described in the previous post about EFS on AWS. To recap:
- you need to provision a Kubernetes cluster on AWS (with or without Pipeline)
- and attach EFS storage (with or without Pipeline)
For this example we’ve provisioned a two node cluster (m4.2xlarge) with EFS available as a PVC with the name efs.
Build Docker images for our Inception training example
You can either use our Docker image or build them yourself:
cd tensorflow-models/research
docker build -t banzaicloud/tensorflow-inception-example:v0.1 -f inception/k8s/docker/Dockerfile .
This image contains the bazel-bin executable versions of the following scripts:
- download_and_preprocess_imagenet - downloads set of images (imagenet) and prepares TfRecord files
- download_and_preprocess_flowers - downloads set of images (flowers) and prepares TfRecord files
- imagenet_train - default training script for imagenet data
- imagenet_distributed_train - distributed training script for imagenet data
- imagenet_eval - evaluates training of imagenet data
Download and preprocess images for training jobs
cd tensorflow-models/research/inception/k8s
kubectl apply -f prepare.yaml
Now we have to launch the download_and_preprocess_flowers script, which downloads the data sets to our EFS volume, unpacks it and creates TfRecord files suitable for training jobs. We used a flowers data set for the purposes of this demo, which is usually used to skip the training process and start from scratch. It’s much smaller than imagenet. To train on imagenet data, all you have to do is change the command in prepare.yaml to download_and_preprocess_imagenet.
Run TensorFlow training
Deploy KubeFlow:
kubectl apply -f [directory_where_you_cloned_kubeflow]/components/ -R
$ kubectl get po
NAME READY STATUS RESTARTS AGE
efs-provisioner-b8dcc9bd7-s6dt4 1/1 Running 0 5h
tf-job-operator-6f7ccdfd4d-mkk9l 1/1 Running 0 18m
As you can see, Kubeflow deploys a tf-job-operator which handles TensorFlow specific deployments like TfJob. It’s really very self-explanatory: you’ll understand once you take a look at training.yaml:
kind: "TfJob"
metadata:
name: "inception-train-job"
spec:
replicaSpecs:
- replicas: 4
tfReplicaType: WORKER
template:
spec:
containers:
- image: banzaicloud/tensorflow-inception-example:v0.1
name: tensorflow
command: ["bazel-bin/inception/imagenet_distributed_train"]
args: ["--batch_size=32", "--num_gpus=0", "--data_dir=/efs/image-data", "--train_dir=/efs/train"]
volumeMounts:
- name: efs-pvc
mountPath: "/efs"
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs
restartPolicy: OnFailure
- replicas: 2
tfReplicaType: PS
tensorboard:
logDir: /efs/train
serviceType: LoadBalancer
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs
volumeMounts:
- name: efs-pvc
mountPath: "/efs"
terminationPolicy:
chief:
replicaName: WORKER
replicaIndex: 0
Ok, let’s deploy the training job:
kubectl apply -f training.yaml
Check running pods on your k8s cluster:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
efs-provisioner-b8dcc9bd7-s6dt4 1/1 Running 0 5h
inception-train-job-ps-b91p-0-256s8 1/1 Running 0 1m
inception-train-job-ps-b91p-1-xwqsr 1/1 Running 0 1m
inception-train-job-tensorboard-b91p-5dfcc88c95-p5r97 1/1 Running 0 1m
inception-train-job-worker-b91p-0-hqbg9 1/1 Running 0 1m
inception-train-job-worker-b91p-1-mqp54 1/1 Running 0 1m
inception-train-job-worker-b91p-2-pmqxn 1/1 Running 0 1m
inception-train-job-worker-b91p-3-lpfls 1/1 Running 0 1m
tf-job-operator-6f7ccdfd4d-mkk9l 1/1 Running 0 18m
You may notice that there’s a pod for Tensorboard which is reachable from outside through a LoadBalancer. You can retrieve its address if you describe the service thusly:
$ kubectl describe svc inception-train-job-tensorboard-b91p
Name: inception-train-job-tensorboard-b91p
Namespace: default
Labels: app=tensorboard
runtime_id=b91p
tensorflow.org=
tf_job_name=inception-train-job
Annotations: <none>
Selector: app=tensorboard,runtime_id=b91p,tensorflow.org=,tf_job_name=inception-train-job
Type: LoadBalancer
IP: 10.98.1.170
LoadBalancer Ingress: ac6299300fb7211e7bc7c06b9c102cd8-1452377798.eu-west-1.elb.amazonaws.com
Port: tb-port 80/TCP
TargetPort: 6006/TCP
NodePort: tb-port 32515/TCP
Endpoints: 10.38.0.6:6006
Session Affinity: None
External Traffic Policy: Cluster
Tensorboard can visualize your graph, making it easier to understand and debug.
+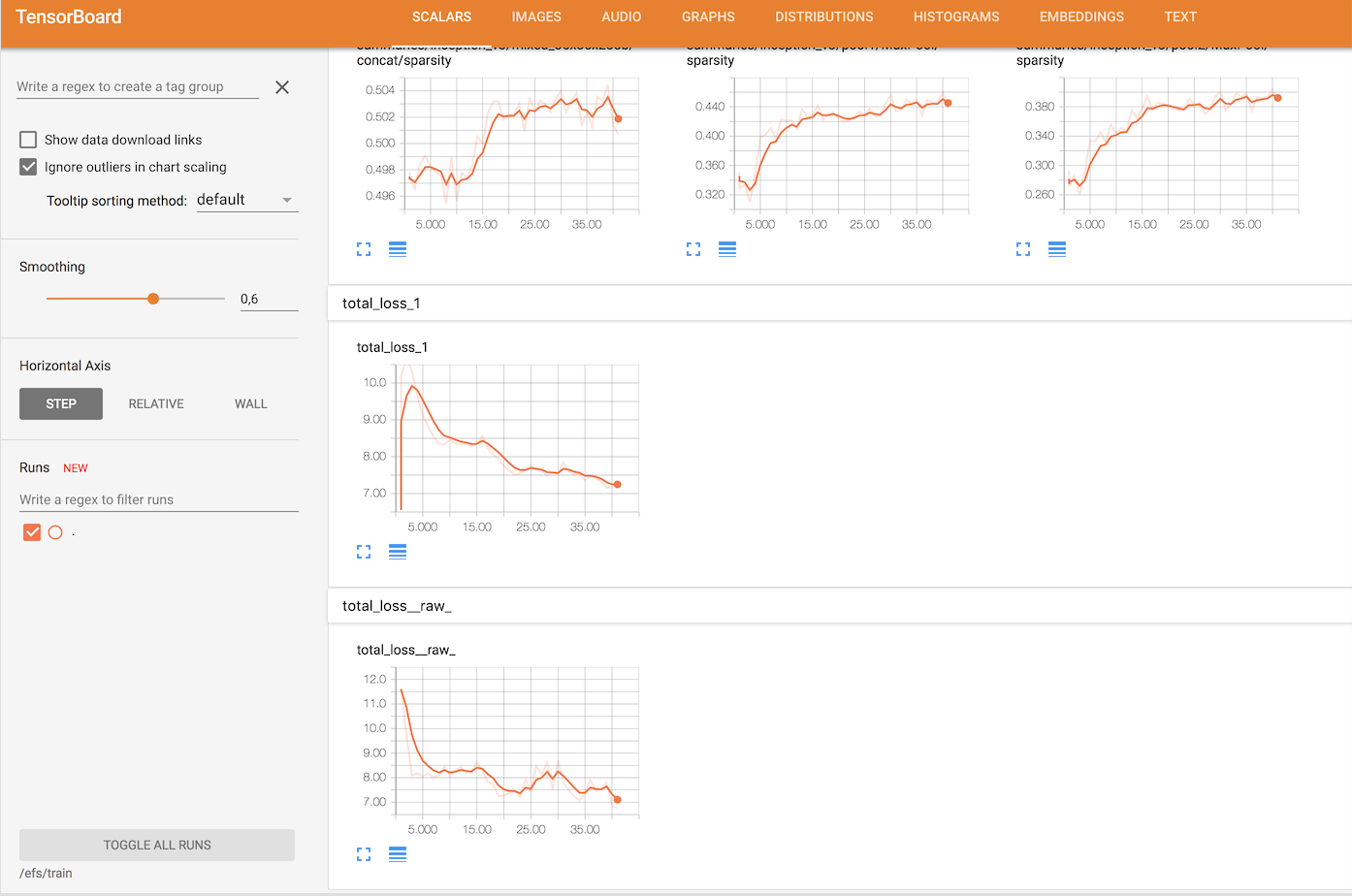
If you look at the logs carefully you’ll notice that our example of a two nodes cluster executes learning steps quite slowly. That’s mostly because we’re using generic compute instances on AWS, not GPU compute instances. Using generic compute instances instead of GPU ones doesn’t makes sense except to illustrate the benefits and the ease of using GPU resources in Kubernetes, which we will do in the next post in this series.
Spoiler alert 2: it’s considerably faster and uses the built-in GPU plugin/scheduling feature of k8s.
Overall, it’s relatively easy to start a training job on k8s once you have the proper definition yaml files. But it’s even easier to push your python scripts to a GitHub repository (like this Spark example) then leave the cluster provisioning (both cloud and k8s), build, deployment, monitoring, scaling and everything else to an automated CI/CD Pipeline.