






At Banzai Cloud we provision all kinds of applications to Kubernetes and we try to autoscale these clusters with Pipeline and/or properly size application resources as needed. As promised in an earlier blog post, How to correctly size containers for Java 10 applications, we’ll share our findings on the Vertical Pod Autoscaler(VPA) used with Java 10.
VPA sets resource requests on pod containers automatically, based on historical usage, thus ensuring that pods are scheduled onto nodes where appropriate resource amounts are available for each pod.
Kubernetes supports three different kind of autoscalers - cluster, horizontal and vertical. This post is part of our autoscaling series:
Autoscaling Kubernetes clusters
Vertical pod autoscaler
Horizontal pod autoscaler
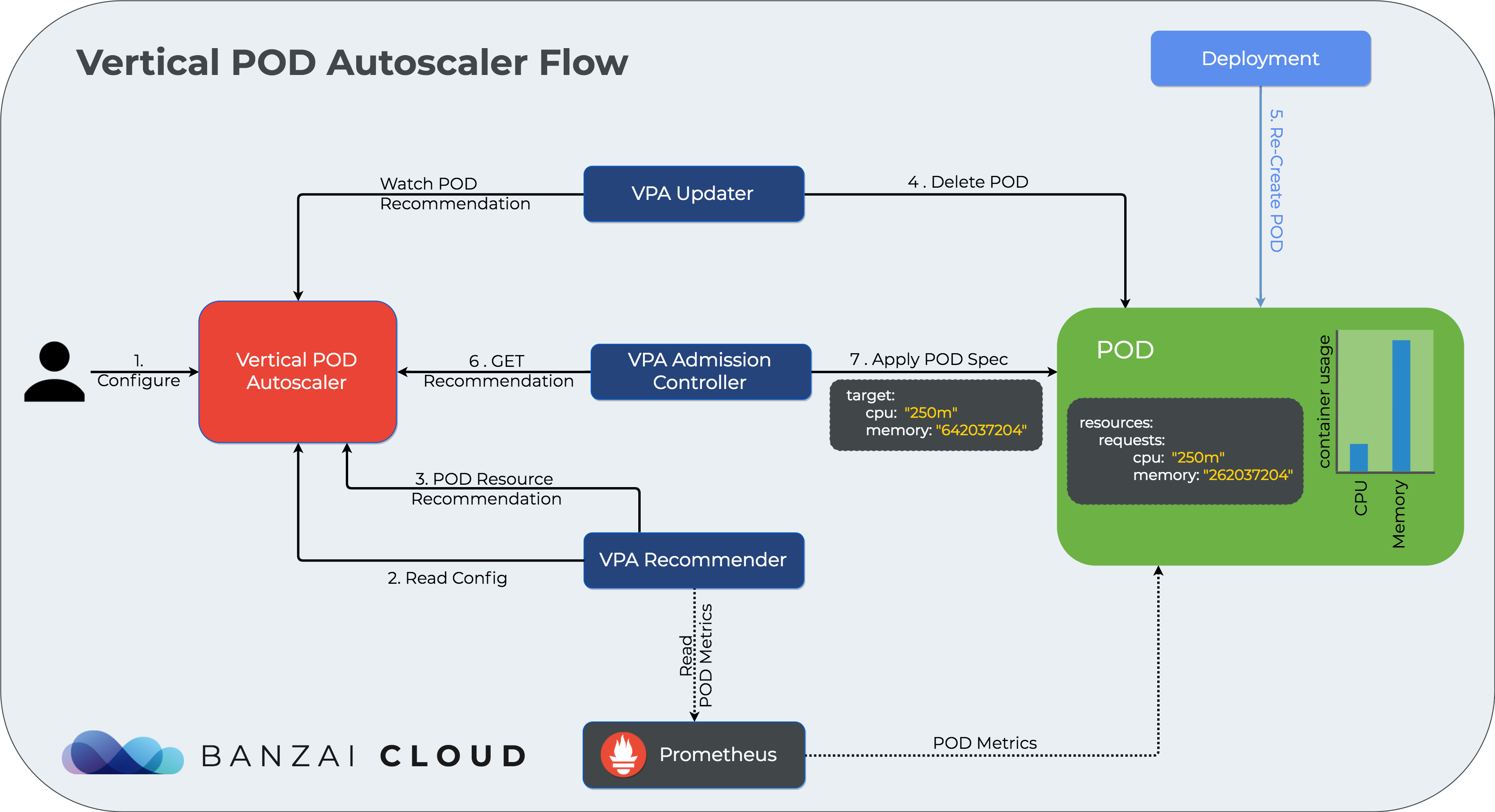
For an overview of autoscaling flow please see this (static) diagram. For further information and a dynamic version of vertical autoscaling flow, read.
Prerequisites for using VPA 🔗︎
-
VPA requires MutatingAdmissionWebhooks to be enabled on the Kubernetes cluster. This can be verified quickly via:
$ kubectl api-versions | grep admissionregistration admissionregistration.k8s.io/v1beta1As of Kubernetes version 1.9 MutatingAdmissionWebhooks is enabled by default. If your cluster doesn’t have it enabled follow these instructions.
-
Install the components that comprise VPA by following this installation guide. If the VPA installation has been successful, you should see something like:
$ kubectl get po -n kube-system NAME READY STATUS RESTARTS AGE ... vpa-admission-controller-7b449b69c-rrs5p 1/1 Running 0 1m vpa-recommender-bf6577cdd-zm7rf 1/1 Running 0 1m vpa-updater-5dd9968676-gm28g 1/1 Running 0 1m$ kubectl get crd NAME AGE verticalpodautoscalercheckpoints.poc.autoscaling.k8s.io 1m verticalpodautoscalers.poc.autoscaling.k8s.io 1mAs stated in documentation, VPA pulls resource usage metrics related to pods and containers from Prometheus. VPA Recommender is the component that gathers metrics from Prometheus and makes recommendations for watched pods. In the current implementation, VPA Recommender expects the Prometheus Server to be reachable at a specific location:
http://prometheus.monitoring.svc. For details see the Dockerfile of VPA Recommender. Since this is a work in progress, I expect it to be made configurable in the future.
Note: we do effortless monitoring of Java applications deployed to Kubernetes without code changes
As we can see **Prometheus Server** must be deployed to `monitoring` [namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/) and there must be a [Kubernetes service](https://kubernetes.io/docs/concepts/services-networking/service/) named `prometheus` pointing to it.
$ helm init -c
$ helm repo list
NAME URL
stable https://kubernetes-charts.storage.googleapis.com
$ helm install --name prometheus --namespace monitoring stable/prometheus
kubectl create -f - <<EOF
apiVersion: v1
kind: Service
metadata:
labels:
app: prometheus
chart: prometheus-6.6.1
component: server
heritage: Tiller
release: prometheus
name: prometheus
namespace: monitoring
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9090
selector:
app: prometheus
component: server
release: prometheus
sessionAffinity: None
type: ClusterIP
EOF
Configuring VPA 🔗︎
Once VPA is up and running, we need to configure it. A VPA configuration contains the following settings:
- label selector, through which it identifies the Pods it should handle
- optional update policy, configures how VPA applies resource related changes to Pods. If not specified, the default -
Auto- is used. - optional resource policy, configures how the recommender computes recommended resources for Pods. If not specified, the default is used.
Let’s see these in action 🔗︎
For a dynamic overview of how the vertical cluster autoscaler works, please see the diagram below:
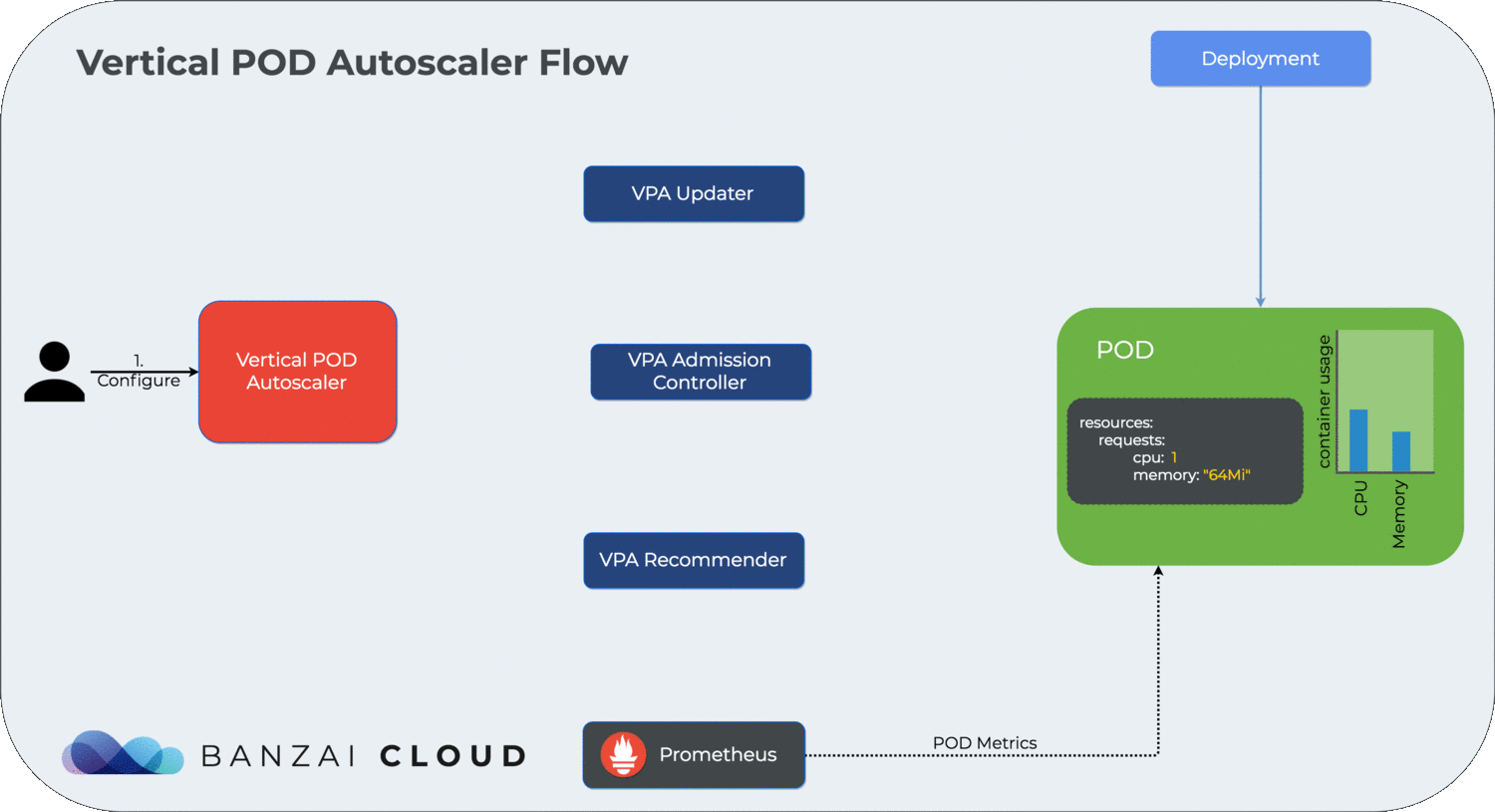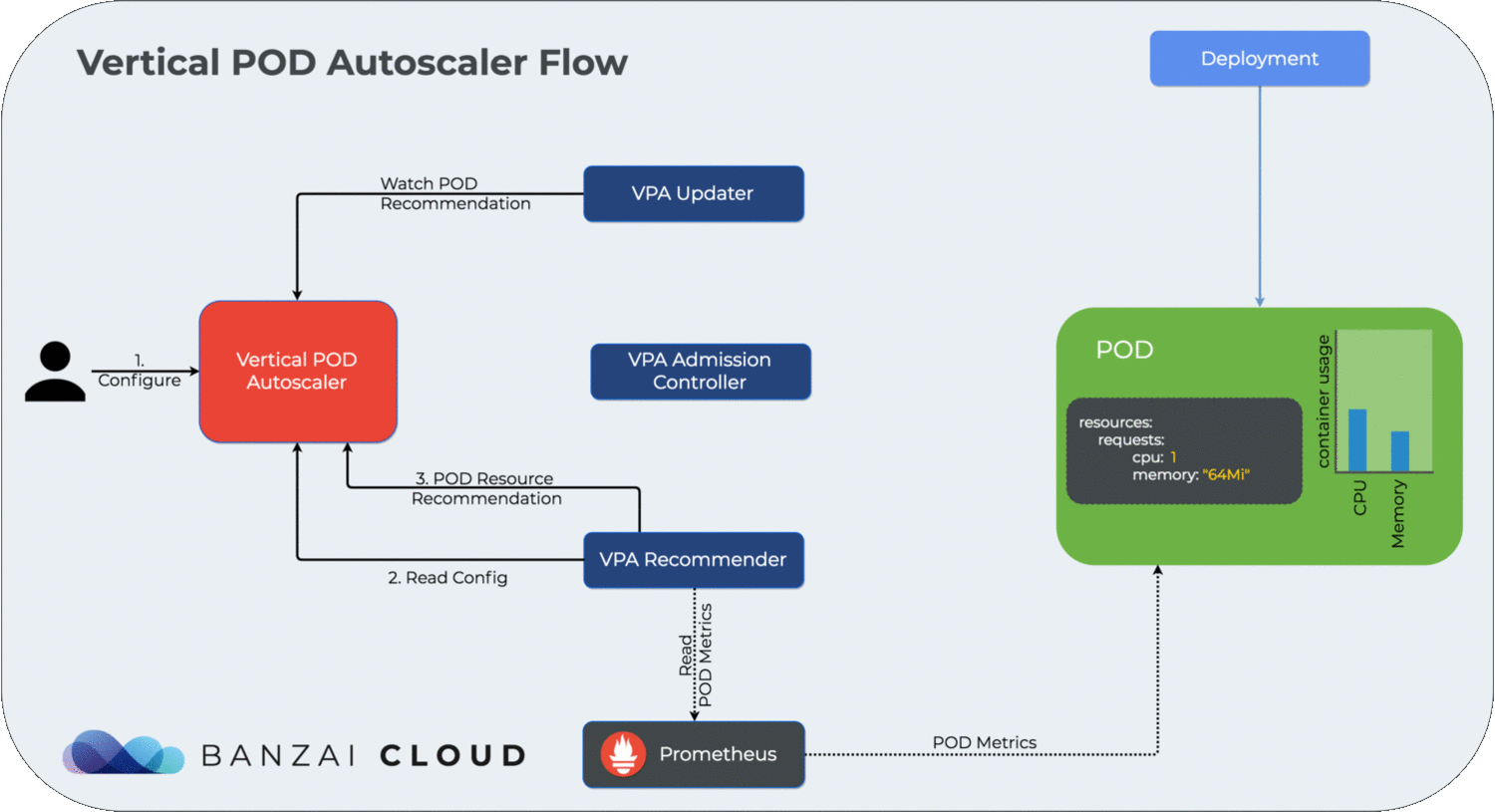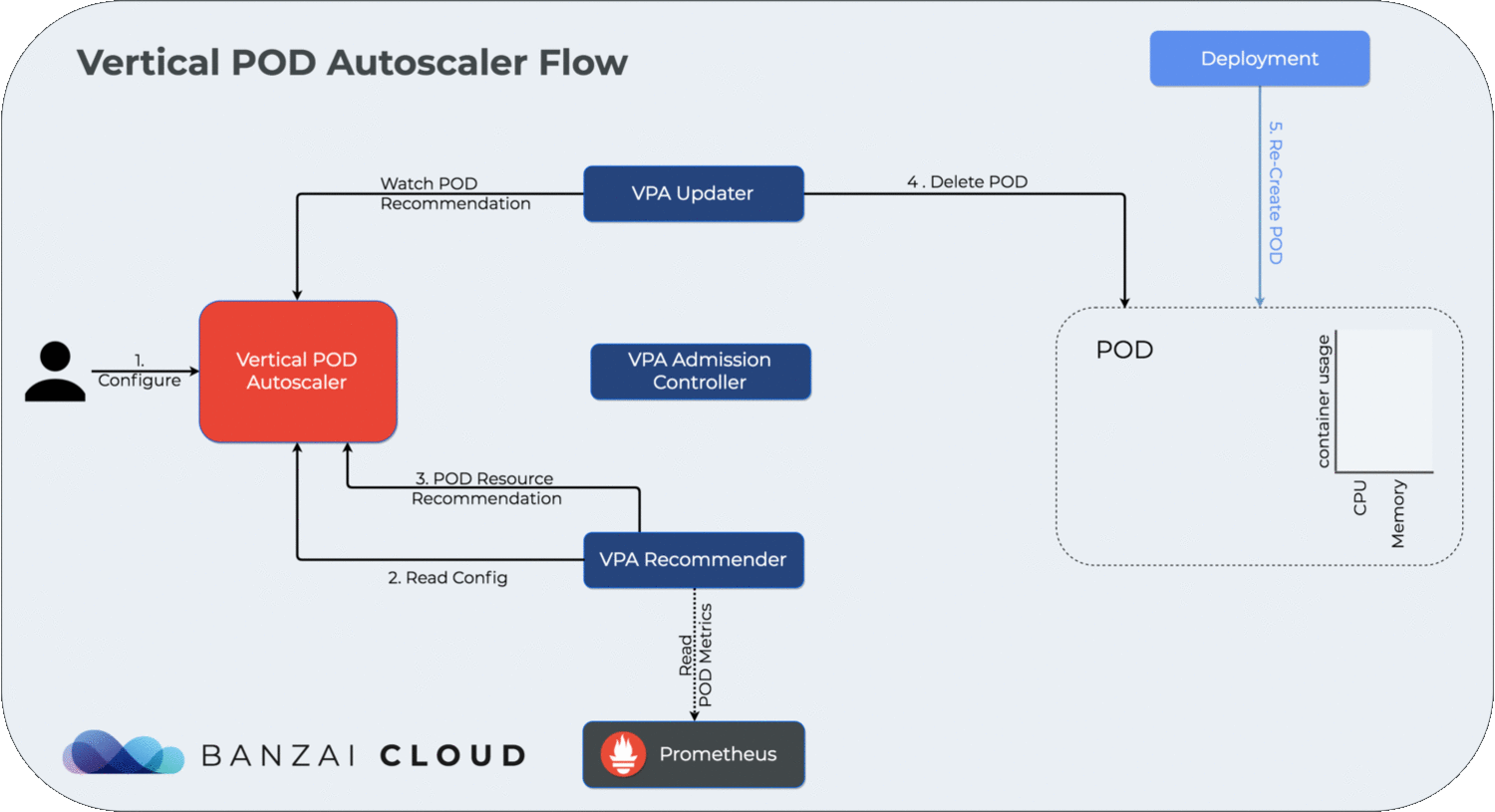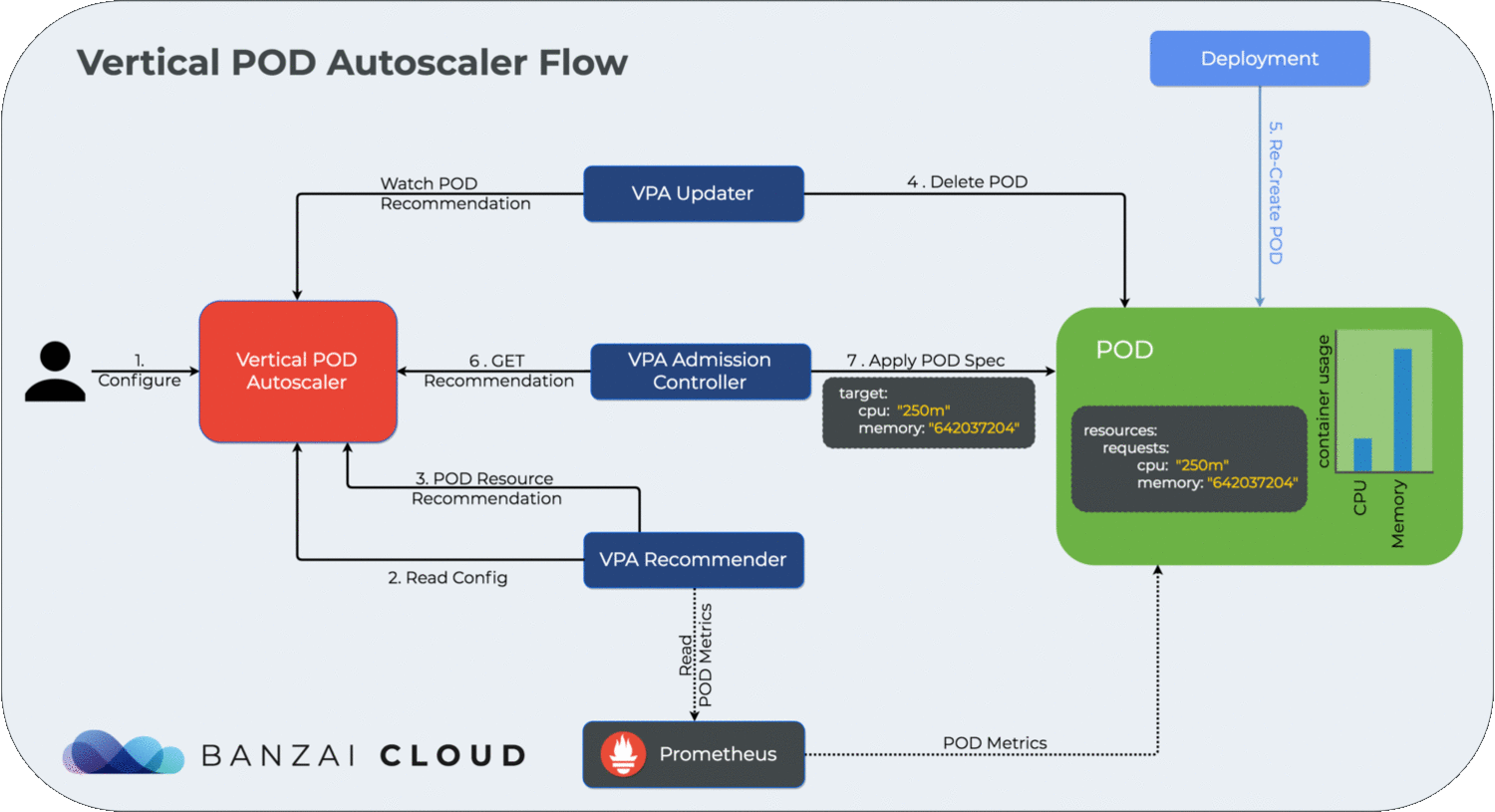
We’re going to use the same test application we did in How to correctly size containers for Java 10 applications. We deploy the test application using:
$ kubectl create -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: dyn-class-gen-deployment
labels:
app: dyn-class-gen
spec:
replicas: 1
selector:
matchLabels:
app: dyn-class-gen
template:
metadata:
labels:
app: dyn-class-gen
spec:
containers:
- name: dyn-class-gen-container
image: banzaicloud/dynclassgen:1.0
env:
- name: DYN_CLASS_COUNT
value: "256"
- name: MEM_USAGE_PER_OBJECT_MB
value: "1"
resources:
requests:
memory: "64Mi"
cpu: 1
limits:
memory: "1Gi"
cpu: 2
EOF
$ deployment "dyn-class-gen-deployment" createdThe container’s upper memory limit is set to 1GB. The max heap size of the application will be automatically set to 1GB / 4 = 256MB. So, 256MB of max heap size is clearly not enough, since the application will try to consume 256 * 1MB of heap space, plus it needs space for internal objects in loaded libraries, etc. Thus we can expect to see the application quit due to java.lang.OutOfMemoryError.
$ kubectl get po
NAME READY STATUS RESTARTS AGE
dyn-class-gen-deployment-5c75c8c555-gzcdq 0/1 Error 2 24skubectl logs dyn-class-gen-deployment-7f4f95b94b-cbrx6
...
DynClassBase243 instance consuming 1MB
DynClassBase244 instance consuming 1MB
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.banzaicloud.dynclassgen.DynClassBase245.consumeSomeMemory(DynClassBase.java:25)
at com.banzaicloud.dynclassgen.DynamicClassGen.main(DynamicClassGen.java:72)Now let’s see how VPA would handle our pod failing due to java.lang.OutOfMemoryError. We have to configure VPA first to find our pod.
$ kubectl create -f - <<EOF
apiVersion: poc.autoscaling.k8s.io/v1alpha1
kind: VerticalPodAutoscaler
metadata:
name: dyn-class-gen-vpa
spec:
selector:
matchLabels:
app: dyn-class-gen
updatePolicy:
updateMode: "Auto"
EOF
verticalpodautoscaler "dyn-class-gen-vpa" createdAfter waiting some time, then checking the logs of VPA Recommender, we can see that it doesn’t provide any recommendations for our dyn-class-gen-vpa pod. My educated guess is that the pod is failing so quickly that Prometheus is unable to collect valuable data on resource usage from the pod, which means there is not enough input data for VPA Recommender to be able to come up with a recommendation.
Let’s modify the pod such as it’s not failing with java.lang.OutOfMemoryError by increasing the upper limit of the heap to 300MB :
$ kubectl edit deployment dyn-class-gen-deployment
...
spec:
containers:
- env:
- name: DYN_CLASS_COUNT
value: "256"
- name: JVM_OPTS
value: -Xmx300M
- name: MEM_USAGE_PER_OBJECT_MB
value: "1"After letting our pod run a little longer, let’s see what VPA Recommender tells us:
$ kubectl get VerticalPodAutoscaler dyn-class-gen-vpa -o yaml
apiVersion: poc.autoscaling.k8s.io/v1alpha1
kind: VerticalPodAutoscaler
metadata:
clusterName: ""
creationTimestamp: 2018-06-05T19:36:09Z
generation: 0
name: dyn-class-gen-vpa
namespace: default
resourceVersion: "48550"
selfLink: /apis/poc.autoscaling.k8s.io/v1alpha1/namespaces/default/verticalpodautoscalers/dyn-class-gen-vpa
uid: b238081d-68f7-11e8-973e-42010a800fe7
spec:
selector:
matchLabels:
app: dyn-class-gen
updatePolicy:
updateMode: Auto
status:
conditions:
- lastTransitionTime: 2018-06-05T19:36:22Z
status: "True"
type: Configured
- lastTransitionTime: 2018-06-05T19:36:22Z
status: "True"
type: RecommendationProvided
lastUpdateTime: 2018-06-06T06:26:43Z
recommendation:
containerRecommendations:
- maxRecommended:
cpu: 4806m
memory: "12344993833"
minRecommended:
cpu: 241m
memory: "619256043"
name: dyn-class-gen-container
target:
cpu: 250m
memory: "642037204"The VPA recommender recommends:
cpu: 250mmemory: "642037204"- aprox. 642Mi
for resource requests versus
cpu: 1memory: "64Mi"
what we gave in the original deployment.
In accordance with the official documentation, the values recommended by VPA Recommender will be applied to the pod by VPA Admission Controller upon the pod’s creation. Thus, if we delete our pod, the Deployment will take care of spinning up a new one. The new one will have resources requests set by VPA Admission Controller, instead of inheriting values from the Deployment.
$ kubectl delete po dyn-class-gen-deployment-7db4f5c557-l97w9$ kubectl describe po dyn-class-gen-deployment-7db4f5c557-pd9bc
Name: dyn-class-gen-deployment-7db4f5c557-pd9bc
Namespace: default
Node: gke-gkecluster-seba-636-pool1-f8f0d428-6n1f/10.128.0.2
Start Time: Wed, 06 Jun 2018 08:38:01 +0200
Labels: app=dyn-class-gen
pod-template-hash=3860917113
Annotations: vpaUpdates=Pod resources updated by dyn-class-gen-vpa: container 0: cpu request, memory request
Status: Running
IP: 10.52.0.27
Controlled By: ReplicaSet/dyn-class-gen-deployment-7db4f5c557
Containers:
dyn-class-gen-container:
Container ID: docker://688d6088efdc2045d56c4f187211e43f09f4654779bdaa3e50f6e378718cb976
Image: banzaicloud/dynclassgen:1.0
Image ID: docker-pullable://banzaicloud/dynclassgen@sha256:134835da5696f3f56b3cc68c13421512868133bcf5aa9cd196867920f813e785
Port: <none>
State: Running
Started: Wed, 06 Jun 2018 08:38:03 +0200
Ready: True
Restart Count: 0
Limits:
cpu: 2
memory: 1Gi
Requests:
cpu: 250m
memory: 642037204
Environment:
DYN_CLASS_COUNT: 256
JVM_OPTS: -Xmx300M
MEM_USAGE_PER_OBJECT_MB: 1
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-v7z2l (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
default-token-v7z2l:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-v7z2l
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 31m default-scheduler Successfully assigned dyn-class-gen-deployment-7db4f5c557-pd9bc to gke-gkecluster-seba-636-po
ol1-f8f0d428-6n1f
Normal SuccessfulMountVolume 31m kubelet, gke-gkecluster-seba-636-pool1-f8f0d428-6n1f MountVolume.SetUp succeeded for volume "default-token-v7z2l"
Normal Pulled 31m kubelet, gke-gkecluster-seba-636-pool1-f8f0d428-6n1f Container image "banzaicloud/dynclassgen:1.0" already present on machine
Normal Created 31m kubelet, gke-gkecluster-seba-636-pool1-f8f0d428-6n1f Created container
Normal Started 31m kubelet, gke-gkecluster-seba-636-pool1-f8f0d428-6n1f Started containerOpinionated conclusions 🔗︎
- VPA is in it’s early stages and is expected to change its shape many times, so early adopters should be prepared for that. Details on known limitations can be found here and on future work here
- VPA only adjusts the
resources requestsof containers based on observed past and current resource usage. It doesn’t setresources limits. This can be problematic with misbehaving applications that begin using more and more resources, leading to pods being killed by Kubernetes.
Learn more about the different types of autoscaling features supported and automated by the Banzai Cloud Pipeline platform platform:




