






Note: The Pipeline CI/CD module mentioned in this post is outdated and not available anymore. You can integrate Pipeline to your CI/CD solution using the Pipeline API. Contact us for details.
Apache Spark on Kubernetes series:
Introduction to Spark on Kubernetes
Scaling Spark made simple on Kubernetes
The anatomy of Spark applications on Kubernetes
Monitoring Apache Spark with Prometheus
Apache Spark CI/CD workflow howto
Spark History Server on Kubernetes
Spark scheduling on Kubernetes demystified
Spark Streaming Checkpointing on Kubernetes
Deep dive into monitoring Spark and Zeppelin with Prometheus
Apache Spark application resilience on Kubernetes
Apache Zeppelin on Kubernetes series:
Running Zeppelin Spark notebooks on Kubernetes
Running Zeppelin Spark notebooks on Kubernetes - deep dive
CI/CD flow for Zeppelin notebooks
Apache Kafka on Kubernetes series:
Kafka on Kubernetes - using etcd
CI/CD series:
CI/CD flow for Zeppelin notebooks CI/CD for Kubernetes, through a Spring Boot example Deploy Node.js applications to Kubernetes
We’ve already published a few posts about how we deploy and use Apache Spark and Zeppelin on Kubernetes. This time, we’ll describe how to set up Pipeline’s CI/CD workflow for a Zeppelin Notebook project. This use case may seem a bit unusual (see the note below), but it has the benefit of removing the burden of managing infrastructure (eg. you can add or remove nodes based on the workload generated by a Notebook), allowing data scientists to focus on a Notebook’s logic; all the heavy lifting necessary to provision and tear down environments is done by Pipeline.
Note: Notebook was developed and tested in a web browser (in the Zeppelin UI) against a persistent cluster, this is as opposed to projects (Java, Go) that are usually stored in various code repositories and have more elaborate build and deployment lifecycles. Check out our other examples to see how plain java / scala projects can be set up for the Banzai Cloud Pipeline CI/CD flow.
A regular Zeppelin Notebook development cycle contains the following steps:
- Set up the infrastructure
- Develop/change the Notebook
- Test/run the Notebook
- Inspect the results (on the Zeppelin UI)
- Eventually stop/destroy the infrastructure
With the Pipeline flow, this cycle is reduced to:
- Edit/modify the Notebook
- Push the changes to a Git repository
- Inspect the results (on the Zeppelin UI, Spark History Server)
- Adjust the cluster to the application’s needs (by modifying the flow descriptor), or destroy the infrastructure
Learn through example - Zeppelin CI/CD 🔗︎
Let’s start with an example Zeppelin project
Note: Please read the following howto for a detailed description of the prerequisites that are necessary for the flow to work!
Fork the repository into your GitHub account. You’ll find a couple of Banzai Cloud Pipeline CI/CD flow descriptor templates for previously released cloud providers (Amazon, Azure, etc.). Make a copy of the template that corresponds to your chosen cloud provider and name it .pipeline.yml. This is the Banzai Cloud Pipeline CI/CD flow descriptor which is one of the spotguides associated with the project.
Enable the build for your fork on the Drone UI on the Banzai Cloud control plane. In the project’s build details section, add the necessary secrets (Pipeline endpoint, credentials). Check the descriptor for any placeholders and substitute them with your corresponding values.
Note: there is a video of Spark CI/CD example available, here, that walks through use of the CI/CD UI
With that, your project should be configured for the Banzai Cloud Pipeline CI/CD flow! The flow will be triggered whenever a new change is pushed to the repository (configurable on the UI).
Understanding the Banzai Cloud CI/CD flow descriptor 🔗︎
The Banzai Cloud Pipeline CI/CD flow descriptor must be named .pipeline.yml. It contains the steps of the flow, executed in sequence. (The Banzai Cloud Pipeline CI/CD flow uses Drone in the background, however, the CI/CD flow descriptor is an abstraction that is not directly tied to any particular product or implementation. It can also be wired to use CircleCI or Travis).
The example descriptor consists of the following steps:
create_cluster- creates or reuses a (managed) Kubernetes cluster supported by Pipeline like EC2, AKS, GKE- install tooling for the cluster (using helm charts):
install_monitoringcluster monitoring (Prometheus)install_spark_history_serverSpark History Serverinstall_zeppelinZeppelin
Note: steps related to the infrastructure are only exectued once, and reused after the first run if the cluster is not deleted as a final step
remote_checkoutchecks out the code from the git repositoryrunruns the Notebook
You can name the steps whatever you want. They’re only use is for delimiting the phases of the flow. Steps are implemented as Docker containers that use configuration items passed in the flow descriptor (step section).
Note that, compared with manually setting up a History Server with event logging, using the Banzai Cloud Pipeline CI/CD flow is much simpler; you only have to change the S3 bucket/Blob container name in install_spark_history_server.logDirectory and install_zeppelin.deployment_values.zeppelin.sparkSubmitOptions.eventLogDirectory properties in .pipeline.yml.
Checking the results 🔗︎
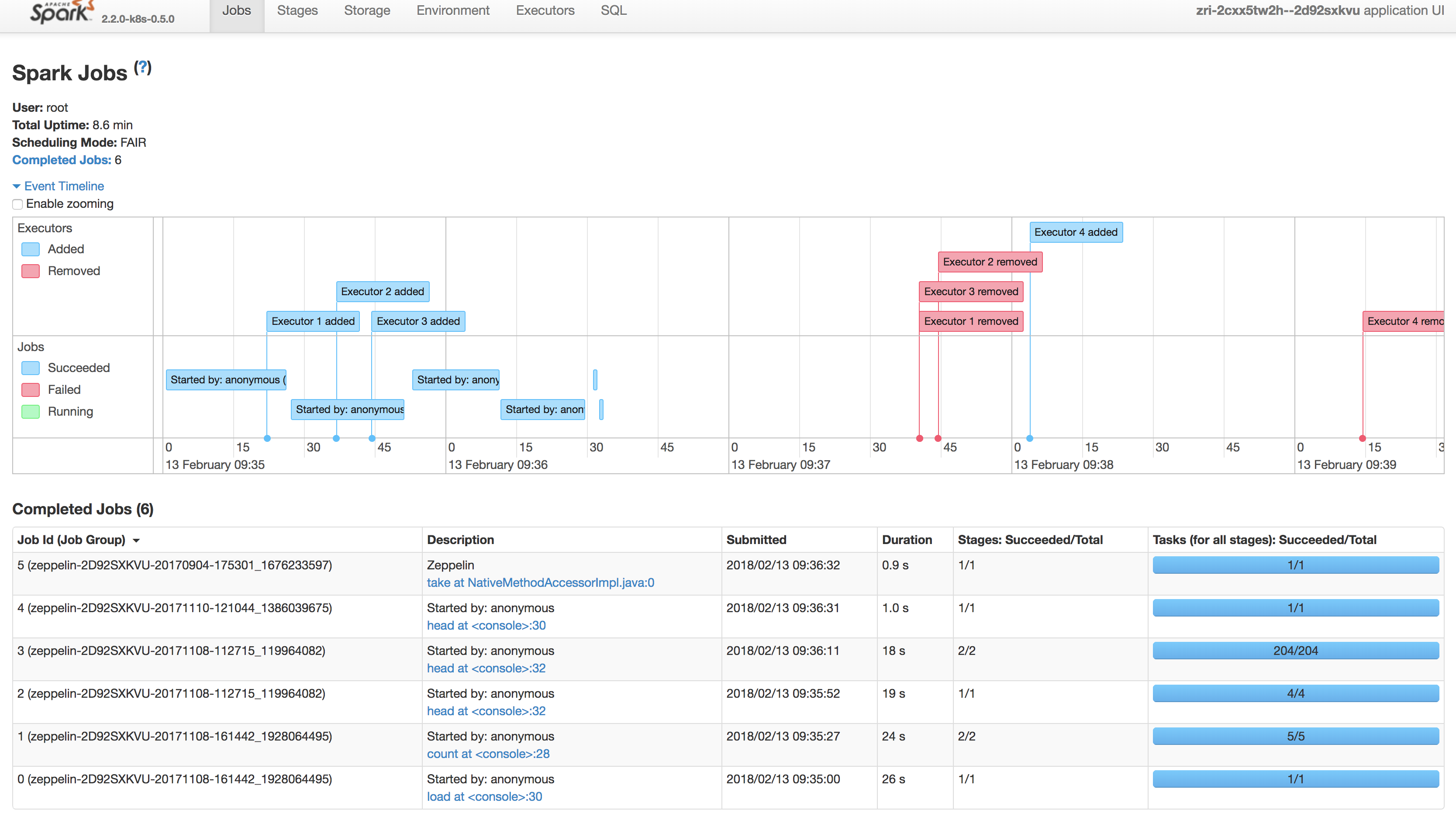
As of version 0.2.0 of Banzai Cloud, Pipeline supports the deployment and use of the Spark History Server. The details of Spark jobs can be checked, as usual, through the History Server UI. Information provided by Spark jobs is saved to a persistent storage (s3, wasb) and the Spark History Server reads and displays it. In this way, the details of the execution can be kept even after the Kubernetes cluster has been destroyed.
If you don’t destroy your infrastructure as part of the Banzai Cloud Pipeline CI/CD flow, you can query the available endpoints (zeppelin, monitoring, spark history server) by issuing a GET request:
curl --request GET --url 'http://[control-plane]/pipeline/api/v1/clusters/{{cluster_id}}/endpoints'
Warning! Be aware that clusters created with the flow on a cloud provider will cost you money. It’s advised that you destroy your environment when your development is finished (or at the end of the day). If you are running on AWS, you might consider using spot instances and our watchguard to safely run spot clusters in production with Hollowtrees
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.




